基于深度学习的视觉里程计算法
基于深度学习的视觉里程计算法
介绍
近年来,视觉里程计广泛应用于机器人和自动驾驶等领域,传统方法求解视觉里程计需基于特征提取、特征
匹配和相机校准等复杂过程,同时各个模块之间要耦合在一起才能达到较好的效果,且算法的复杂度较高。环境
噪声的干扰以及传感器的精度会影响传统算法的特征提取精度,进而影响视觉里程计的估算精度。鉴于此,提出
一种基于深度学习并融合注意力机制的视觉里程计算法,该算法可以舍弃传统算法复杂的操作过程。实验结果表
明,所提算法可以实时地估计相机里程计,并具有较高的精度和稳定性以及较低的网络复杂度。
关键词 机器视觉;深度学习;视觉里程计;注意力机制;多任务学习。
目前,深度学习技术广泛应用在目标检测[1]和目标追踪等诸多计算机视觉领域,以及同步定位与建图(SLAM)领域。视觉里程计(VO)算法是通过视觉技术来获取相机位姿,而SLAM 的思想是构建整个环境的地图,但 VO 算法对于位姿的估计精度直接影响最终地图的构建效果。近年来,通过一系列有着时间先后顺序的图像来推算相机位姿的方法受到了越来越多研究者的关注,而且该方法广泛应用在各类机器人导航 定位以及自动驾驶的领域。早期,VO 算法是针对火星探索计划进行研究的。2004年,Nister等[2]提出了 VO 算法并搭建了最早的 VO 系统,为后续研究提供了优秀的范例和参考。传统 VO 系统的工作过程主要包括:首先校准相机,然后对输入图像进行特征提取及检测并对相邻序列的图像进行特征匹配,接着剔除图像中的异常值,将匹配好的特征进行运动估计和比例估计,最后对其进行局部优化并输出位姿。由此可见,传统 VO 系统的处理过程相对复杂,涉及模块较多。一些基于传统算法的变体在准确性和鲁棒性方面虽然表现较为出色,但通常需要很大的工程量,并且每个模块都需要精准细调才能确保其在特定环境下正常工作。对于单目 VO 系统来说,由于其缺少绝对的信息尺度,所以必须使用一些额外的信息(如相机的高度)才能更好地抑制漂移,从而进行姿态估计。随着深度学习技术的飞速发展以及卷积神经网络(CNN)在图像识别
(本人博客在之前已经讲解了CNN。以下是本文链接https://blog.csdn.net/weixin_46931877/article/details/115940612)
和分割领域的巨大成功,使得研究者使用CNN来处理VO问题成为了可能。CNN可以自动对图像进行不同尺度的特征提取,省去了传统机器学习中繁琐的特征提取过程。但是由于 VO 算法考虑了连续图像序列的相关信息,需要处理和发现图像之间更多的低层几何变换信息,因此在处理 VO 问题仅仅使用 CNN 是不够的。基于以上问题,本文提出一种基于深度学习的VO 算法。首先将 RGB(Red,Green,Blue)图像序列输入网络中,对图像数据使用多层 CNN 进行由局部底层几何变换信息到全局高层几何变换信息的提取,同时使用融合注意力机制进一步提取图像中的几何变换信息。然后将提取的特征通过 CNN 降维后连接两个单独的全连接网络再进行多任务学习。最后网络输出模块分别回归位置信息以及角度信息。所提算法构建的网络可进行端到端的训练,从而舍弃传统方法中的特征提取及匹配等复杂过程。网络在降低复杂度的同时可以提高 VO 算法的定位精度,说明所提算法具有较高的稳定性。
1、相关原理
单目 VO 是机器人和自动驾驶领域的重要研究问题之一,实现单目 VO 的方法主要分为基于几何特征的方法和基于学习的方法两类。
1.1、基于几何特征的方法
基于几何特征的方法可进一步划分为稀疏特征法和直接法。稀疏特征法的代表性方法为LIBVISO2(LibraryforVisualOdometry2)法[4],采用该方法对连续图像帧之间的特征点进行提取和匹配,得到显著的特征点后进行运动估计,稀疏特征法的基本框架如图1所示。随着时间的推移,图像帧之间的误差就会产生累积,从而造成一定的漂移,导致 VO 算法的准确度下降。为了进一步解决这个问题,科研学者提出了视觉SLAM 优化连续特征图的方法。早期,单目视觉SLAM 是借助于卡尔曼滤波器(EKF)来实现位姿估计[5],但EKF的计算复杂度和线性变化具有不确定性,所以实时性难以得到保证。文 献 [6]通 过 滤 除 动 态 物 体 的 方 法 来 提 高VO 精度,但计算复杂度很高,同时具有特征点法的弊端。总的来说,基于特征点的方法对于特征点的提取和匹配十分耗时而且计算复杂度很高,同时提取到的特征点不具有全局性,也会丢失一部分信息。当图像不具备明显的纹理信息时,基于特征点的方法很难提取到特征点。虽然直接法的提取速度更快,但其依赖于像素的变化,而且在光照强度发生变化等情形下,VO 精度很容易受到影响。

1.2、基于学习的方法
基于几何特征的方法主要是从图像中提取特征信息以进行运动估计,而基于学习的方法是从数据中推断运动情况。Roberts等[7]首先基于学习的方法将每帧图像划分为网格单元并计算每个单元的光流,然后采用k 最近邻(KNN)算法来估计当前位姿变化情况,虽然该方法不如几何方法准确,但其具有可行性。随后,一些研究人员使用 CNN 从光流图像帧序列中估计运动位姿,采用的方法有 P-CNNVO 方 法、Flowdometry 方 法和 LS-VO 方法等。由于计算 RGB 图像的光流十分耗时,而且对系统整体的实时性有一 定影响。DeepVO 和GCN(GeometricCorrespondenceNetwork)等是将 CNN 与循环神经网络(RNN)组合,用于从图像序列中提取运动信息,但训练 RNN 需要很大的计算成本,同时网络的复杂度也会很高。综合以上分析,传统的基于几何特征的方法在图片特征不明显以及光照突变的情况下会导致准确度下降,同时会出现误差累积的现象。基于学习的方法是最近几年发展起来的,由于传统机器学习算法处理数据的能力有限,所以使用基本 CNN 从图像序列中提取特征成为了趋势,然而仅仅使用 CNN 提取表层特征是不够的,通过 RNN 进一步提取特征尽管在效果上有所提高,但这会增加很大的计算压力,复杂度较高。鉴于此,提出一种新型轻量级端到端的网络架构来处理 VO问题,同时使用融合注意力机制来提取图像序列中的几何变换信息,可以弥补仅使用 CNN存在的不足。下面简单讲解,所提网络增加多任务输出位姿的层,分别回归位置信息和角度信息。所提网络的框架如图2所示,其中FC为全连接。

2、所提算法
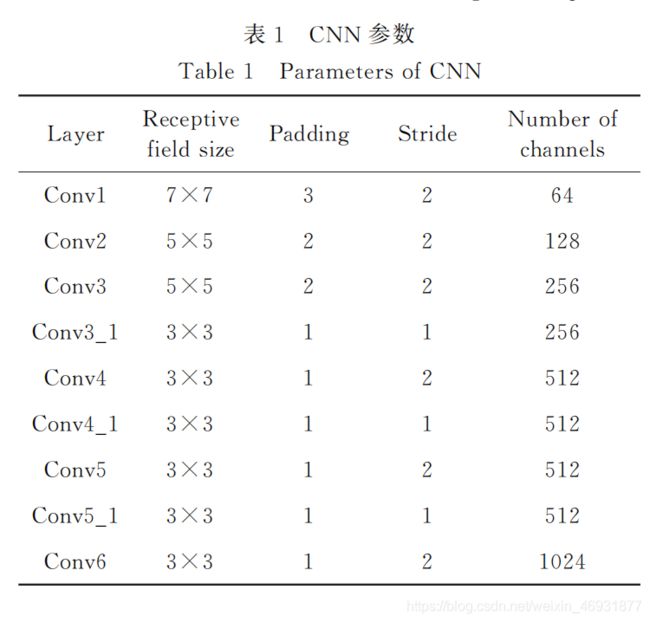
所提的网络架构可以进行端到端的训练并且可以输出相机位姿,主要过程包括 CNN 特征的提取、基于注意力机制对层级的图像几何关系特征进行提取,以及使用连接两个分离的全连接网络对多任务特征进行降维和浓缩处理。
2.1、网络框架

所提的神经网络结构如图3所示。虽然已有很多有用的 CNN 架构用于处理计算机视觉任务,如VGGNet、GoogLeNet、ResNet和 DenseNet等,但均主要用于分类或者目标检测等。通过图像来计算相机的位姿,但位姿依赖于图像的几何特征信息,这是深度学习中的回归问题之一,因此使用诸如VGGNet结构解决 VO 问题的效果较差。综上所述,提出一种能够更好地学习图像几何特征表达的网络架构,该架构可以解决 VO 问题以及其他的图像几何问题。在网络中输入相邻两帧的图像,两张图像均为数据集中的原始 RGB 图像。为了适应所提的网络架构,将图像尺寸修改为1280pixel×384pixel,并对两张图像进行第三维度上的串联,组成第三维度为6的数据并输入网络中,通过 CNN 以及注意力模块对其进行特征提取,再经过两个分离的 FC 层进行单独的降维及特征浓缩处理,最后网络输出这两张图像之间的相对位姿。由于 VO 问题更依赖于从图像中提取的几何特征信息,因此为了更综合地学习两张图像之间的几何变换关系,网络架构来设计CNN 以提取图像特征,并在 CNN 的最后连接两个单独的 FC层进行多任务的位姿回归。所设计的 CNN 共有9层卷积层,网络内部参数如表1所示,对 CNN 中每一层的输出图像使用ReLU 激活函数进行非线性处理。卷积核的由大变小且通道数的由少变多,可以使网络更能关注图像的局部特征和多种融合特征。经过所有卷积层后再通过最大池化操作可以获得10×3×1024的特征图,其中通道数为1024,特征图的尺寸为10pixel×3pixel,并将其转换为一维的特征向量后先输入到一层共享的FC层,再输入各自的FC层后进行位姿
回归,最终网络输出得到6自由度的位姿数据。
2.2、注意力模块
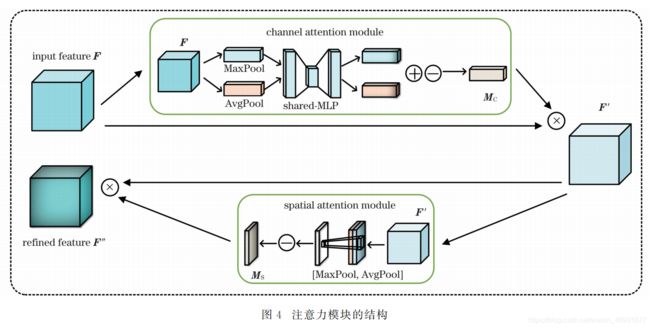
注意力模块可嵌入 CNN 中并进行一种简单而又有效的注意力机制部署,其主要包含通道注意力模块和空间注意力模块。使用注意力机制来增强网络架构的表达能力,可以进一步表征图像之间的几何变换关系,从而使网络可以更智能化地学习更重要的特征并同时关注那些特征区域,从而减少学习一些不重要的特征,这也是注意力机制的本质。由于卷积运算是通过融合各个通道以及空间平面特征图的信息来分离特征,故卷积注意力模块也围绕着通道维度以及特征图的空间维度分别设置注意力机制,这可以使神经网络能够学习更重要的特征信息,将基于卷积的注意力模块集成到所提的 CNN 架构中并进行端到端的训练,其基本结构如图4所示,其中 F∈RC×H ×W 为输特征图,为逐个元素相乘的符号,F’为注意力模
块内部优化的特征图,F″为注意力模块优化后输出的特征图,MC ∈RC×1×1 为 一 维 的 通 道 注 意 力 图,MS∈R1×H ×W 为二维的空间注意力图,MLP为多层感知器,C、H 和 W 分别为特征图的通道数、高和宽,为逐个元素相加的符号,为Sigmoid函数。输入一张图像,假设这张图像为神经网络内部的某个特征图F∈RC×H ×W ,使用注意力机制先后生成一个 MC∈RC×1×1 以及一个 MS∈R1×H ×W 。总的注意力机制处理过程可以表示为:

使用通道注意力模块对输入的特征图分别进行空间维度的全局最大池化操作和全局平均池化操作,得到两个维度为C×1×1的特征图并将其送入MLP网络中,得到两个优化后的特征图并对其进行元素级别的加和操作,再通过 Sigmoid激活函数对其进行激活从而得到 MC。使用空间注意力模块对输入的特征图分别进行
通道维度的全局最大池化操作和全局平均池化操作,得到两个维度为1×H ×W 的特征图并对其进行通道维度的拼接处理,得到维度为2×H×W 的特征图并通过一层卷积网络降维为1个通道,再通过Sigmoid函数得到维度为1×H×W 的 MS。将注意力机制与所提的 CNN 结合,并在卷积运算的基础上融合注意力机制,使网络能够自主地关注具有信息量的特征以及特征区域,并且可以学习不同通道以及空间特征图之间的相互关联性,从而在不增加太多网络复杂度的同时可以使神经网络输出的相机位姿更准确。
2.3、多任务学习机制
使用 CNN 以及注意力机制对图像的几何特征进行浓缩处理,后连接两个单独的 FC 层对特征进行进一步的降维,并分别执行回归相机的位移以及转角两个不同的监督任务,从而使模型具有更好的泛化能力。两个单独的 FC层分别输出相机的位移 x,y,z 以及转角 α,β,γ ,其中α 为俯仰角,β 为航向角,γ 为滚动角。通过多任务学习机制可以使神经网络更专注于各自的回归任务,从而获得更丰富的特征信息。两个 FC层的网络结构均采用相同的参数,两个网络输出的自由度均为3,然后对其进行拼接以组成6自由度的位姿数据,从而进行后续误差的计算以及反向传播优化神经网络参数。
2.4、损失函数及优化
所提的网络架构是通过计算条件概率来实现对相机位姿的准确预测。假设Yt=( y1,y2,…,yt )为网络预测输出的位姿,Xt =( x1,x2,…,xt )为单目图像序列,t为时刻,t时刻的条件概率P( Yt|Xt =P y1,y2,…,yt|x1,x2,…,xt) ,通 过最大化概率P(Yt|Xt )来得到最优的参数,表达式为::

式中:θ* 为网络的最优参数;θ 为网络参数。为了得到最优的参数,假设网络输出的相机位移为pki,相机转角为φki,地面真值位姿为( pki,φki) ,并计算N 对样本图像的均方误差(MSE),其中pki 为地面真值位姿的相机位移,φki 为地面真值位姿的相机转角。总的损失函数可以表示为:

式中:‖·‖2 为二范数;κ 为一个尺度因子,用来平衡位移以及转角之间的差异。通过对神经网络进行梯度下降处理,可以获得网络模型的最优参数。相机的转角可以通过欧拉角来描述,这可以使神经网络求解起来简单方便。
3、实验验证与分析
3.1 、数据集
KITTIVisualOdometry 是 由 Geiger等[4]构建的汽车驾驶数据集,广泛用于评估各种 VO 算法或 V-SLAM(VisualSLAM)算 法 的 性 能。KITTIVObenchmark共包含22个场景图像,每个场景都包含由双目摄像机拍摄的一系列图像,实验只使用双目数据集中的单目图像数据。其中前11个场景不仅包含双目图像数据,还包含汽车行驶轨迹的真值,其他 11 个 场 景 仅 包 含 原 始 的 传 感 器 数 据。KITTI数据集中的图像采集频率约为10Hz,部分场景中包含动态移动物体以及明暗显著变换的图像。当汽车起步时,相邻两帧图像之间的变化较小,当汽车行驶速度较快或者转弯时,相邻两帧图像之间的变化较大,部分场景中汽车 的行驶速度高达90km/h。因此上述情况对 VO 的估计精度有相对较大的影响,这对相机的位姿估计更具有挑战性。
3.2、实验环境及参数配置
实验采用的显卡为 NvidiaGeforceTitan XpPascal,用来训练和测试网络,CPU 为Intel志 强E5-2673-V3,在深度学习框架 PyTorch中进行相关算 法 的 设 计。 使 用 Adam (Adaptive MomentEstimation)优化器进行100个周期的训练,并将学习率设为10-4,网络权重初始化方式采用 Xavier的方式,同时引入防止过拟合和提前停止的方法以防止模型过拟合。神经网络输入的预处理图像尺寸为1280pixel×384pixel,训 练 过 程中同时采用两块GPU 进行训练,训练一个周期的时间约为0.15h。
3.3 实验结果与分析
训练后的 VO 模型采用 KITTIVO/SLAM 官方的 评价方式来评测。测试的路径长度范围为100~800m,在汽车速度不同(不同场景中汽车的行驶速度不同)的所有子场景中计算平移和旋转误差的方均根误差(RMSE)。网络模型在场景00、01、02、08和09中进行训练,在场景03、04、05、06、07 和10中进行测 试。VISO2_S 与 VISO2_M 均采用传统方式求解 VO精度,两者不同之处在于 VISO2_M 为单目算法,

图5 不同情况下的平均平移误差和平均旋转误差。(a)不同路径长度下的平均平移误差;(b)不同路径长度下的平均旋转误差;©不同速度下的平均平移误差;(d)不同速度下的平均旋转误差。

旋转 RMSE。从表2可以看到,DeepVO 算法在不包括两层 LSTM(LongShort-Term Memory)乘加运算的情况下,所需的计算量与所提算法相当,但所提算法所需的参数量仅为其一半;在精度下降较小的情况下,所提算法的计算量和参数量显著下降,这有利于进一步使用硬件来实现;所提算法的平移误差比 VISO2_M 算法减少49.37%,这可以提升传统算法的效果,不过在旋转误差上有待进一步减小。为了验证所提算法的有效性,在实际的室外场景下进行实验,首先使用相机录制一段视频,为了尽可能地构造与训练场景符合的原始数据,对视频进行跳帧处理并将得到的连续图像送入神经网络模型中。使用 模 型 预 测 相 机 轨 迹,得 到 的 实 际 场 景 如图7所示,实际的地面真值数据需要专业设备来获取,所以将实际的地图作为参考。从图7可以看到,与地图数据相比,所提算法的结果较为准确,通过对比分析可以证明所提算法的有效性。由于手持相机的波动性较大,跳帧后图像反映的实际运动速度比训练集低很多,因为相机在运动过程中难免会受到一些因素的影响,如车辆的快速流动,而且其未行走于路中等。这在一定程度上会影响网络预测的结果,造成结果存在误差。

对于单目相机获取的RGB图像,采用深度学习的算法并融入注意力模块可以直接端到端地输出相机位姿,而且复杂度较低,无需 VISO2中的特征提取和匹配以及相机标定等复杂步骤。在场景中含有动态物体的情况下,特征匹配会造成较大的误差,而所提算法能够提取更深的特征信息,使其对动态对象不敏感。如果能够扩充训练集的样本数据,并且数据集中含有不同情况下的数据,将会使网络模型具有更强的泛化能力,并获得更好的效果。