1.一个万用的hash function
在之前的课程中,我们知道以Hash Table为底层的容器过程(如unordered_map),在使用过程中,必须要有一个hash function来为每一个元素生成一个hash code作为元素在哈希表中的key, 也就是元素在哈希表中的具体位置。 对于一些build-in类型(比如字符串),标准库自带hash function,但是对于自定义类型来说,这个函数该如何定义? 我们能否找到一个通用的方法,实现hash code的计算呢?
自定义类型,都是由基本类型组成,我们可以将它其中的各个基本数据类型分开计算出,然后将其相加(当然这是比较天真的方法)。 先看看这种方法的实现代码:
class CustomerHash
{
public:
std::size_t operator()(const Customer& c) const{
return std::hash()(c.fname)
+ std::hash()(c.Iname)
+ std::hash
}
}
这个方法可以实现出计算Hash code,但是因为这个方法只是简单的相加hash code,因此hash code的重复概率比较高进而会导致篮子中的元素过多,影响查询的效率。
在了解其他方法之前,先介绍一下hash function的三种定义型式:
型式1:
#include
class Customer{
//........
};
class CustomerHash
{
public:
std::size_t operator()(const Customer& c) const{
return /*........*/;
}
};
unordered_set customers;
型式2:
size_t customer_hash_func(const Customer& c)
{
return /*......*/;
}
unorder_set customers(20, customer_hash_func);
型式3:
通过偏特化来实现
class MyString
{
private:
char* _data;
size_t _len;
};
namespace std;
{
template<>
struct hash
{
size_t operatoe()(const MyString& s) const noexcept{
return hash()(string(s.get()));
}
}
}
通过以上三种型式可以指定我们需要的hash function,但是能否能有一个万用的hash function来实现自定义类型的hash code的计算?
在C++ TR1版本及以后,STL为我们提供了一个万用的hash function,它是如何实现的呢?
具体调用代码如下:
class CustomerHash
{
public:
std::size_t operator()(const Cunstomer& c) const {
return hash_val(c.fname, c,Iname, c.no);
}
}
接下来看看它的实现代码,具体如下:
//auxiliary generic funtions
template
inline size_t hash_val(const Types&... args){
size_t seed = 0;
hash_val(seed, args...);
return seed;
}
template
inline void hash_val(size_t& seed, const T& val, const Type&... args){
hash_combine(seed, val);
hash_val(seed, args...);
}
#include
template
inline void hash_combine(size_t& seed, const T& val){
seed = std::hash(val) + 0x9e3779b9
+ (seed << 6) + (seed >> 2);
}
//auxiliary generic funtions
template
inline void hash_val(size_t& seed, const T& val){
hash_combine(seed, val);
}
这种方法和之前提到的简单相加的方法相比,更加的巧妙,它使用了C++11中的variadic templates,可以传入多个模板,传入函数中的每个参数都有一个模板,对不同类型的参数会有不同的解决方案,也就是会传入不同的函数。

由上图可知,在①中加入了seed(最终被视为hash code),从而使得模板变成1+n的形式,通过递归调用②中的hash_val函数,不断调用④中的hash_combine函数来改变seed,同时减少接收的参数, 最终递归结束时变成1+1的形式,调用③中的hash_val函数,也会调用④中的hash_combine函数,最终确认seed值,也就是算出最后的hash code。
其中④中的hash_combine函数中的0x9e3779b9属于黄金比例中的一部分:

2.tuple
tuple是元之组合,数之组合的意思,它是C++2.0之后引进的一种存放各种不同类型元素的集合。
tuple的使用方法如下:

tuple实现的原理,以Gnu4.8为例:

它是通过继承的方法来不断地剔除第一个参数,最终来实现对每一个元素的操作。
3.type traits
type traits(类型萃取机)能有效地分辨类是否具有某种类型,通过调用它我们可以实现对不同的类型指定不同的操作。
在Gnu2.9中的实现代码如下:
struct __true_type{};
struct __false_type{};
//泛化
template
struct __type_traits{
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type; //POD = Plain Old Data,代表旧式的class 也就是struct
};
//int的特化
template<>
struct __type_traits{
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
}
//double的特化
template<>
struct __type_traits{
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
}
上面的type traits是依靠模板的泛化和特化的版本来实现。
从C++11开始,type traits的特性变得更为强大和复杂。


type traits的实现
万变不离其宗,通过模板的泛化和特化,我们可以实现各种操作。
(1)is_void

(2)is_integral

(3)is_class,is_union,is_enum,is_pod

(4)is_move_assignable

4.cout
Gnu2.9:

Gnu4.9:

5.moveable元素对容器的影响
5.1对vctor影响

5.2对list影响

5.3对deque影响

5.4对multiset影响
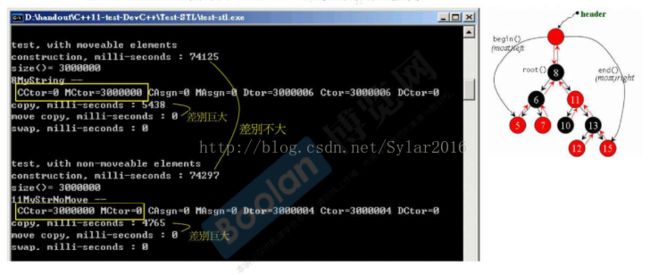
5.5对unordered_multiset影响

5.6写一个moveable class

