导读,前面哆嗦了好几篇,其实只是讲了微服务的一些概念,以及服务的注册与发现。但好像还在望其冰山一角。没错,接下来我们将望其另一角...
这里我们注意到有几个问题:
1 我们之前模拟注册到 Eureka Server 上的 Eureka Client 服务是空白的... 也就是一句业务代码都没有???
2 之前我们提到微服务就是把庞大的杂糅在一起的各个业务模块拆分成多个服务独立开发、运行、维护,以降低耦合度。可是,如何拆分?
3 拆分完了之后,服务 A 如何调用服务 B?
一、服务拆分
微服务拆分(或者服务拆分)并不是一个新鲜的名词,在软件工程领域已经有不少年头,而且还有专门针对服务拆分的研究与职位。
这里展开有很多个话题可以研究和讨论。当然,此文中服务拆分不是重点。这里,我只是简要分享一些微服务拆分上的一些原则,而这些也是结合微服务的特点来拆分,比如从不同的业务功能模块、业务数据的相关性、不同服务的负载情况等等...
具体的拆分细则很多,如果对服务拆分感兴趣,可以从网上找到很多优秀的作者文章,比如
伯乐在线的服务拆分与架构演进的文章: http://blog.jobbole.com/109902/
二、服务示例
基于服务拆分原则,这里举一个简单的拆分实例。比如,企业的内部用户管理就可以拆分为一个单独的服务。用户的数据可以对于其他系统独立,而用户的业务又可以对应到人力资源管理里。并且,用户的操作又是企业内部各业务部门和各系统都需要用到的,如果每个业务部门都维护一套自己的用户管理模块,不仅大量重复工作,而且各部门之间的数据还可能不一致而造成某些冲突...
将用户的数据独立出去,其他系统只需要来调用对应接口就能进行用户的相关操作,而用户的管理则统一由某一业务部门进行,比如人力资源部门。
此处,我们模拟一个非常简单的用户服务,包含简单的添加用户,获取一个用户,获取所有用户的接口。
1 创建一个 Eureka Client 项目
根据前面第六篇中的 Eureka Client 项目的创建与注册先创建一个 Eureka Client 的空白项目 user-service
2 准备项目配置
本示例项目使用了 mysql 存储用户数据,使用 spring data jpa (如果对 jpa 不太熟,可自行搜索引擎,它非常简单,因为它就是方便数据库操作而开发的)来进行持久层操作。因此,需要添加 MySQL 的依赖,spring-boot-starter-data-jpa 的依赖。另外,spring-boot-starter-web 依赖则是确保本项目能够作为一个后台 web 项目运行。
(1) pom.xml
pom.xml 中添加如下依赖
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
(2) application.yml
本配置文件中主要添加了 mysql 的连接信息的配置,jpa 相关的
# application name
spring:
application:
name: user-service
# mysql jpa config
datasource:
url: jdbc:mysql://192.168.174.200:3306/microservice?characterEncoding=UTF-8&autoReconnect=true&useSSL=false
username: ms
password: ms123
dbcp:
validation-query: SELECT 1
test-while-idle: true
jpa:
generate-ddl: true
show-sql: true
hibernate:
ddl-auto: update
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
# server monitor port
server:
port: 8080
# eureka server cluster
eureka:
client:
service-url:
defaultZone: http://hadoop1:8000/eureka/,http://hadoop2:8000/eureka/,http://hadoop3:8000/eureka/
注:
- 数据库连接配置 spring.datasource.url 的配置请确保你有一台装有 MySQL 的数据库并且能够连接,且已经有一个可用的数据库及能够访问的数据库账号
- Eureka server 的地址是前面我搭建的运行在虚拟机上的集群
(3) 创建实体类
创建一个用户的实体类,此类对应于我们的数据库中的数据表 user,并且表的创建由 spring data jpa 框架进行。
package com.jiangzhuolin.userservice.bean;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Date;
@Entity
@Table(name="user")
@EntityListeners(AuditingEntityListener.class)
public class User implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String username;
private String password;
private String phone;
private String email;
private String address;
@CreatedDate
@Column(name = "create_time")
private Date createTime;
@LastModifiedDate
@Column(name = "update_time")
private Date updateTime;
... 省略 getter 与 setter 方法
(4) 创建 repository 接口
repository 接口类似于我们的 dao 层的接口,它直接继承 JpaRepository,好处是我们多数情况下的简单的数据库操作完全不用我们自己实现,由 jpa 自动帮我们生成对应的数据库操作。当然,我们也可以自己实现更多的自定义的数据库操作,在此不赘述。
package com.jiangzhuolin.userservice.repository;
import com.jiangzhuolin.userservice.bean.User;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository {
User save(User user);
User findUserById(long id);
@Override
Page findAll(Pageable pageable);
}
(5) 创建对外服务响应类 controller
直接可以对我们的 repository 进行注入从而方便的使用其中的数据操作方法。
package com.jiangzhuolin.userservice.controller;
import com.jiangzhuolin.userservice.bean.User;
import com.jiangzhuolin.userservice.repository.UserRepository;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.List;
@RestController
@RequestMapping(value = "/user")
public class UserController {
@Resource
private UserRepository userRepository;
@RequestMapping(value = "/save", method = RequestMethod.POST)
@ResponseBody
public User save(User user) {
User savedUser = userRepository.save(user);
savedUser.setPassword("");
return savedUser;
}
@RequestMapping(value = "/{id}", method = RequestMethod.GET)
@ResponseBody
public User getOne(@PathVariable("id") long id) {
User user = userRepository.findUserById(id);
user.setPassword("");
return user;
}
@RequestMapping(value = "/all")
@ResponseBody
public List findAll() {
List userList = userRepository.findAll();
for (User user : userList) {
user.setPassword("");
}
return userList;
}
}
(6) 打包程序
打包方法请参考之前的文章,此处不赘述。
(7) 运行 client 并注册
将打包后的程序上传到服务器,此处我上传的我的两台虚拟机环境 192.168.174.200/201,并执行如下命令运行。
[root@hadoop1 user-service]# pwd
/data/user-service
[root@hadoop2 user-service]# nohup java -jar user-service-0.0.1-SNAPSHOT.jar &
注:
- 确保之前的 Eureka Server 集群是正常运行的
(8) 测试验证
- 查看数据库
当我们服务正常启动以后查看我们的数据库 microservice,发现已经自动生成了 user,与 hibernate_sequence 两张表。其中 user 对应项目中创建的实体类 User,此表现在为空,另一个表 hibernate_sequence 是用来控制自动生成主键的 ID 的序号用的,初始状态为 1。
mysql> show tables;
+------------------------+
| Tables_in_microservice |
+------------------------+
| hibernate_sequence |
| user |
+------------------------+
2 rows in set (0.03 sec)
mysql> select * from user;
Empty set
mysql> select * from hibernate_sequence;
+----------+
| next_val |
+----------+
| 1 |
+----------+
1 row in set (0.02 sec)
- 调用接口
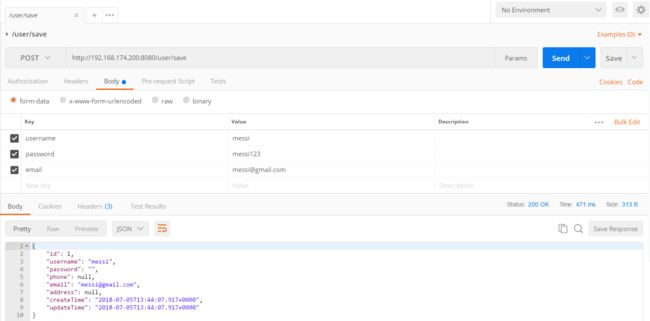
使用 postman 调用 http://192.168.174.200:8080/user/save 接口,向数据库中写入一个用户。
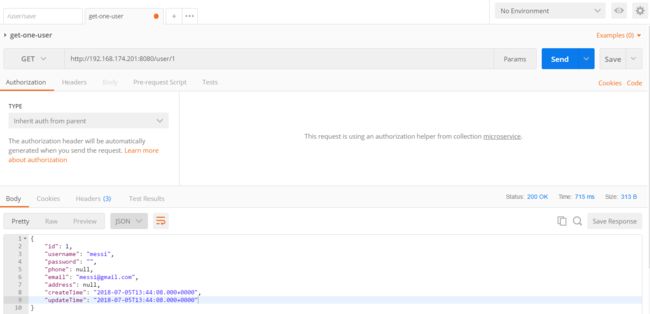
使用 postman 调用 http://192.168.174.201:8080/user/1 接口,从数据库中读取刚才写入的用户。
使用 postman 调用 http://192.168.174.200:8080/user/all 接口,从数据库中读取所有用户数据。
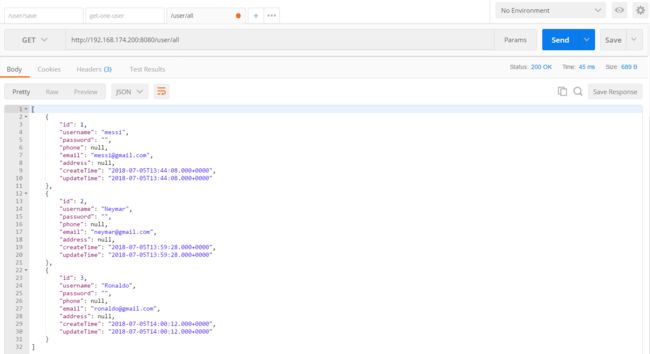
可以看到,之前在 192.168.174.200/201 上运行的两个 user-service 服务都已经正常运行并能够正常调用接口。
- 查看 Eureka Server 上的注册情况
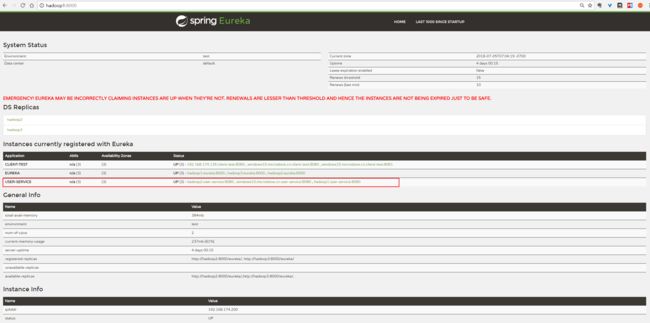
可以看到 user-service 的两个服务都已经被注册到 Eureka Server 集群中。
- 可以看到 user-service 里有一个 windows 的服务,这是我本地的服务,实际上我已经停掉了。另外之前运行过的 client-test 的服务也都停止了,可是为什么这些应用还在 Eureka 后台显示呢,上方还有一行红字,这代表什么呢?
其实,这就是与上篇中提到的 Eureka 的自我保护机制有关,这个参数默认为 true 表示打开: eureka.server.enable-self-preservation: true. 至于自我保护的详情,此处不赘述,可参考上篇文章或在网上搜索。
三、服务消费之 Ribbon
3.1 Ribbon 是干嘛的
从上面的服务调用可能发现,我们服务调用不就是使用接口的 URL 地址调用就行了吗 (比如使用 http client)?最多就是需要参数的再传点参数?为什么还要把服务调用单独拎出来说一说?是吃饱了没事干吗?是的,我吃饱了,但事还是挺多的。
从上面我们的服务调用来看,好像确实没什么问题,比如我们的物流系统需要我们的用户信息了,那我们在物流系统中使用 URL 地址调用不就可以了吗?不过,事情他就怕一个大字。比如,我们的用户服务使用的系统很多,调用频率也很高,我们想做一些负载均衡,把访问压力分散开来,于是我们在多个服务器上启动了多个用户服务的进程(此处假如启了 100 个)。那么问题来了,这 100 个里,你选哪一个服务来用?什么,你说随缘挑选,那你可真是太棒了。
有人可能会说,用 nginx 做个反向代理并负载均衡呀。可是,这里有个问题,那就是没有服务的可用性检测,如果你拿到的是一个异常宕掉的服务,那么调用就出问题了...
好了好了,不多废话了,上面的这些问题,服务有效性、负载均衡在 Spring Cloud 里也有解决方案,服务有效性依靠 Eureka 的心跳机制来解决,而负载均衡则是基于 Ribbon 来实现。Ribbon 是一个用于对 HTTP/TCP 请求进行控制的负载均衡客户端,官网地址:
http://cloud.spring.io/spring-cloud-netflix/multi/multi_spring-cloud-ribbon.html
Ribbon 的详情此处不表,如有兴趣,可向往官网查阅。Ribbon 大概的思路是,先从 Eureka Server 端获取已注册的可用服务列表到客户端,然后根据 Ribbon 实现的各种策略(如轮询,随机,过滤无效链接等)对服务进行挑选(负载均衡)。
3.2 如何在 Eureka Client 使用 Ribbon
示例:现在我们的物流服务中需要调用用户的信用用以完善部分的物流信息与流程。那么,我们怎么从前面的用户服务中调用用户信息呢?
第一步,创建一个物流的 Eureka Client 服务
此处过程省略,请参考前文 Eureka Client 的创建与注册。第二步,在物流服务中调用 user-service 服务
LogisticsController.java 类如下:
package com.jiangzhuolin.logisticsservice.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@RequestMapping(value = "/logistics/")
public class LogisticsController {
@Autowired
private RestTemplate restTemplate;
@RequestMapping(value = "/message")
public String message(String userId) {
String response = restTemplate.getForObject("http://USER-SERVICE/user/{userId}", String.class, userId);
return response;
}
}
需要注意的是,RestTemplate 类在 pring boot 1.4 版本以后便不再支持自动注入了,需要进行声明。参考:
https://stackoverflow.com/questions/28024942/how-to-autowire-resttemplate-using-annotations
此处由于使用的是 2.02 的 spring boot,因此,在启动类中作了一个简单的声明
package com.jiangzhuolin.logisticsservice;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
@EnableDiscoveryClient
public class LogisticsServiceApplication {
public static void main(String[] args) {
SpringApplication.run(LogisticsServiceApplication.class, args);
}
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
其中 @Bean 表示声明一个 Bean 对象,而 @LoadBalanced 表示声明一个基于 Ribbon 的负载均衡。
- 第三步,运行程序
此处,我为项目配置监听端口为 8070 并在本机的 IDEA 中直接运行,然后,在浏览器中调用 logistics 的接口 http://localhost:8070/logistics/message?userId=1,得到结果如下所示:
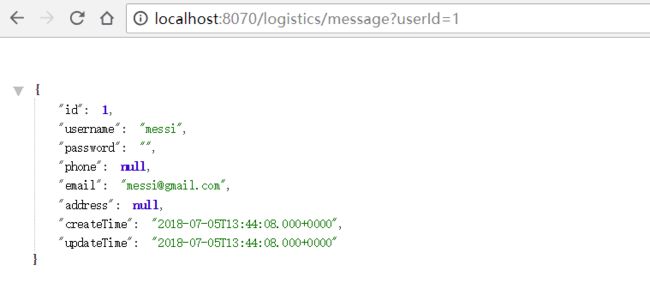
至此,我们基于 Ribbon 的服务消费示例就完成了,是不是异常地简单呢~
三、总结
本文浅显地聊了服务拆分及服务消费一些场景和使用示例。虽然篇幅挺长,但实际都是粗浅的表面,仅限于使用层面。不过,人类的历史来看,不都是从浅入深的过程。从树上掉下苹果捡起来就啃到发现万有引力历经不少年头,所以,先学怎么用没毛病。扯远了,扯远了...
由此,我们也看出,Spring Cloud 依托于 Spring 的大而全的套件,基本已经帮我们实现了很多的造轮子工作,甚至不仅造好了轮子,连车架都造好了,我们只需要上车就走,奔向那诗与远方...
对不起,串场了,告辞告辞~
本文项目源码地址:
user-service: https://github.com/jiangzhuolin/user-service
logistics-service: https://github.com/jiangzhuolin/logistics-service