
源自Google的MapReduce计算模型。MapReduce是一种集群数据并行计算的编程模型,它并不提供数据处理的工作,具体的任务还需编码实现,开发需要具备一门程序语言如:java、python、ruby等)。MapReduce编程模型有Map(映射)和Reduce(规约)两个阶段。
MapReduce分布式计算模型,分而自治的理念,两层含义1).大而化小。2).异化而同。可以应对了大数据的数据量巨大(Valume)和数据种类多样(Variety)挑战。
假设我们手上有很多复杂的数据,那么怎样来处理呢?1.把数据分类,分类后的数据就不复杂了,这就是异化为同。2.分割,分割就是把数据切分为小块,这样就可以并发或则批量处理了,这既是大而化小。
MapReduce当时作为Google的三大法宝之一,在处理大数据上面巨大的优势,那么MapReduce是怎样实现这样高效的呢?
1.MapReduce工作原理讲解

MapReduce分为Map阶段和Reduce阶段,下面这个例子可以很好的解释。
假如我们要制作苹果酱,通常我们先将苹果切块,放入搅拌机中进行搅拌就制作出了我们的苹果酱。将MapReduce应用到这个操作上。
Map(映射):将苹果切碎,是作用在苹果上的一个Map操作。所以Map一个苹果,Map就会将苹果切碎。Map过程中可能出现苹果坏掉的情况,你只要将坏掉的苹果扔掉即可,Map可以将坏掉的苹果过滤掉,Map出来的数据就是好的没有坏掉的苹果。
Reduce(规约):你将苹果放入搅拌机进行搅拌得到苹果酱。你在搅拌之前需要切好原料,所以Reduce一般是和Map在一起的,但是Map可以独立存在。
当苹果酱推向市面获得市场的认可,接到了大量的订单。此时就需要雇佣很多人来切苹果,购买大量的搅拌机用来生产苹果酱。并行工作生产苹果酱满足订单需求。同理MapReduce在计算资源不足的情况下可以增加计算单元,提高数据处理能力,满足业务需求。
MapReduce是一款强大的分布式的计算框架。分布式计算的原理就是分而自治,假如我们需要统计出一大摞牌中红桃牌的数量,最快速的方法就是给在座的每一位分一摞纸牌进行统计,然后他们将统计结果汇报到我这里来进行汇总得到结论。分布式计算一方面是将结果化繁为简,比如这个例子中每一位成员不会将红桃的纸牌传给我而只是化简为一个统计数值。另外有一个隐含之意就是牌需要分配均匀,这一摞扑克牌预先是被充分洗过,就可以避免如果红桃集中分配到某一个人手上,而导致他的速度要比其他人慢很多。
2.错误处理
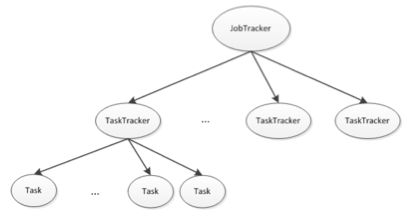
MapReduce有3类错误如下:
1).JobTracker错误,应该说是最严重的一种错误,任务完全无法在集群上执行。尽管这种错误发生概率极小但是还是可以避免。启动多个JobTracker,通过选举机制确定那一个是主JobTracker,主JobTracker负责任务的执行,如果主JobTracker发生错误,其等待的JobTracker通过选举机制产生一个新的主JobTracker重新执行任务。
2).TaskTracker错误,TaskTracker通过心跳机制不断的与JobTracker通信,如果某一个TaskTracker停止或很少向JobTracker发送心跳,JobTracker会监控TaskTracker发送心跳的情况,从而将此TaskTracker从等待任务调度池中移除。此TaskTracker将不会执行集群的任务,直到此TaskTracker节点的故障排除。
3).子任务失败,TaskTracker将子任务的执行情况发送给JobTracker,如果子任务执行失败,JobTracker将重新加入到调度队列中重新分配给其他的TaskTracker执行,如果尝试4次任务仍然没有完成,此时整个作业就失败了。
这三类错误的严重程度,JobTracker错误>TaskTracker错误>子任务(Task)错误。
3.作业调度
MapReduce为用户提供了以下三种作业调度机制,用户可以按照自己的需求任意选择调度算法。
1).先入先出FIFO(First in First out),它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业
2).公平调度器,每一个任务都会被分配相等的时间处理任务。
3).容量调度器,该调度器会对同一用户提交的作业所占资源量进行限定,比如限定每一个作业只能占用1G的内存,如果整个内存有10G可以允许10个任务被加载到内存中执行。
MapReduce的作业调度并没有很高的实时性的要求,它是本着最大吞吐的原则去设计的,所以MapReduce默认采用的调度策略是FIFO(First in First out先进先出的原则)。
4.Shuffle与排序
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce,Shuffle是必须要了解的。从最基本的要求来说,我们对Shuffle过程的期望可以有:
1).完整地从map端拉取数据到reduce端。
2).在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
3).减少磁盘IO对task执行的影响。
洗牌和排序非常消耗集群资源,Shuffle阶段在Map阶段和Reduce阶段之间。Shuffle阶段并不是简单的将Map端结果直接发送给Reduce端,因为Shuffle阶段的好坏直接影响整个MapReduce的性能。在实际情况下我们在执行任务可能是10个Map的节点,却只有2个Reduce节点,Reduce过程会出现大量数据通过集群网络进行传输,同理Reduce阶段中占据大量时间也是数据拉取耗时,较好Shuffle过程就需要将Map结果数据放到Reduce很容易得到的服务器上面。
Shuffle是一个非常复杂的过程,我这里只是简单的进行了讲解,有兴趣可以去深入理解。
小结
MapReduce作为Hadoop主要的核心内容,在数据处理方面为我们提供了方法。通过对原理、错误、作业调度和Shuffle的阅读我们能够清晰的理解MapReduce。
MapReduce在大数据中解决数据计算处理问题,但是MapReduce是Hadoop最早出现的技术,在Hadoop生态圈成长的过程中已有很多更好的替代方案,我们将下一回分享。