数据结构--链表Linked List(二)
以下是学习恋上数据结构与算法记录,本篇主要内容是Java实现链表
◼链表(Linked List)
上篇的动态数组有个明显的缺点,会造成内存空间的大量浪费。但链表可以做到用到多少就申请多少内存,从而减小内存的浪费。
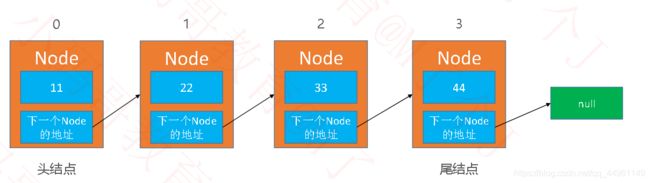
链表是一种链式存储的线性表,所有元素的内存地址不一定是连续的
 ◼接口设计
◼接口设计
链表的大部分接口和动态数组是一致的
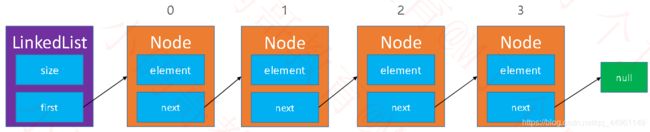 LinkedList类,用来管理链表,size属性记录存储数据的数量,first属性则是引用链表的第0个元素。
LinkedList类,用来管理链表,size属性记录存储数据的数量,first属性则是引用链表的第0个元素。
Node结点类,其中的element属性用于存储元素,next属性记录下一个节点的地址,用于指向链表中的下一个节点。
public class SingleLinkedList extends AbstractList {
private Node first;
private static class Node{
E element;
Node next;
public Node(E element, Node next) {
this.element = element;
this.next = next;
}
}
链表的创建与动态数组不同,动态数组在构造时需要传入一个容量初始值,来决定这个数组的容量。但链表元素是在添加时才创建的,内存地址不一定是连续的。所以链表不需要在单独设计构造方法,使用默认构造方法即可。
◼添加元素 - add(int index,E element)
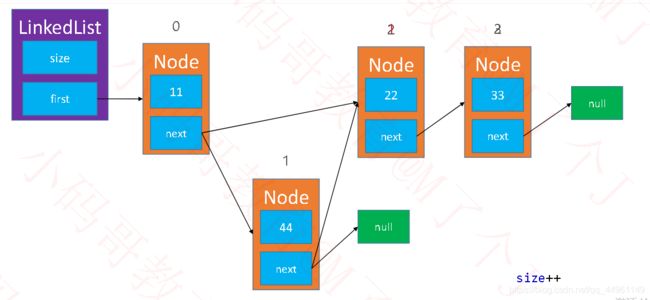
public void add(int index, E element) {
rangeCheckForAdd(index);// 检查索引是否越界
if(index==0) {//往第一个位置添加
// 创建新节点并next指向原位置节点new Node<>(element,prve.next);
//最后first指向新节点
first = new Node<>(element, first);
}else {
Node prve=node(index-1);// 找到指定位置前面的节点
// 创建新节点并next指向原位置节点new Node<>(element,prve.next);
//最后前节点prev的next指向新节点,完成桥接
prve.next=new Node<>(element,prve.next);
}
size++;
}
在编写链表过程中,要注意边界测试,比如index为0 、size–1、size
在添加删除等操作时,我们需要获得index添加位置的节点
◼node(int index) //获取index位置对应的节点对象。
private Node node(int index){
rangeCheck(index);// 检查索引是否越界
Node node = first;//从第一个开始循环遍历
for(int i=0;i ◼删除元素-remove(int index);
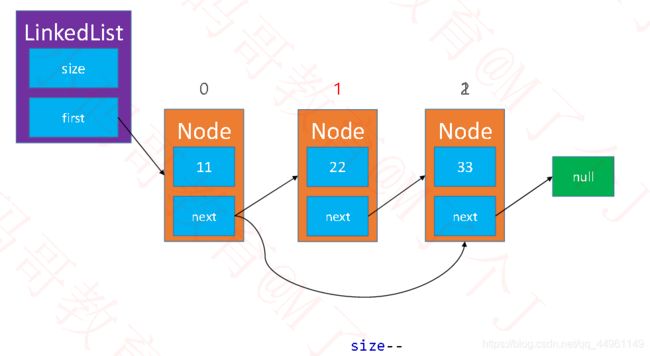 删除节点比较容易,越过指定位置节点即可(prev.next=node.next;),
删除节点比较容易,越过指定位置节点即可(prev.next=node.next;),
即指定位置的上一节点直接指向下一节点。
public E remove(int index) {
rangeCheck(index);
Node node = first;
if(index==0) {//当只有一个元素时
first=null;
}else {
Node prev=node(index-1);
node = prev.next;
prev.next=node.next;
}
size--;
return node.element;
}
可以发现,我们每次操作都需要考虑边界值,特别是第一个节点。
◼如果为了让代码更加精简,统一所有节点的处理逻辑,可以在最前面增加一个虚拟的头结点(不存储数据)
这样我们的代码就不需要考虑第一个节点,为它单独操作。
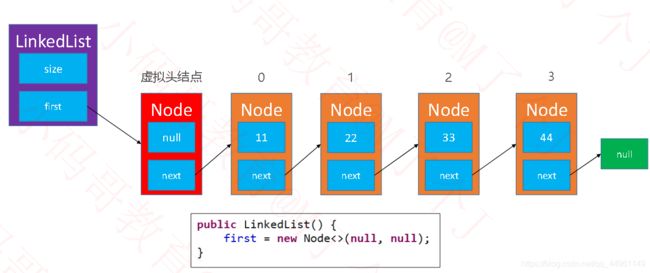
◼双向链表 JDK 中的java.util.LinkedList内置的就是双向链表
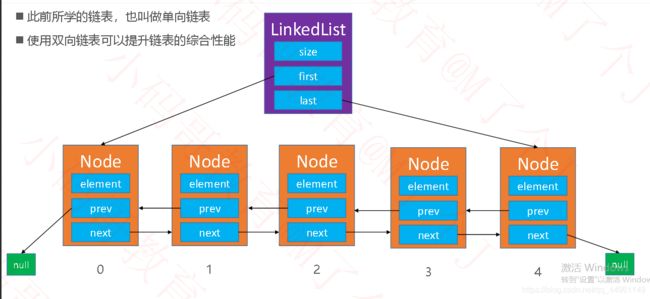
◼构造方法改为:多了一个prev属性,指向前一个节点的地址
private Node first;
private Node last;
private static class Node{
E element;
Node next;
Node prev;
public Node(Node prev,E element, Node next) {
this.prev=prev;
this.element = element;
this.next = next;
}
}
◼node方法改为:用折半方法遍历,提高效率
/**
* 获取index位置对应的节点对象
*/
private Node node(int index){
rangeCheck(index);
//折半查找
if(index>1) {
Node node = first;
for(int i=0;i node = last;
for(int i=size;i>index;i--) {
node=node.prev;
}
return node;
}
}
◼双向链表–add(int index, E element)
 以添加中间位置为例:
以添加中间位置为例:
Node next=node(index);//得到指定位置的节点,也就是之后的下一个节点
Node prev=next.prev;;//指定位置的上一个节点,也就是之后的上一个节点
Node node=new Node<>(prev,element,next);//新节点新建时就完成了指向
next.prev=node//下一个节点指向新节点
prev.next=node;//上一个节点指向新节点
public void add(int index, E element) {
rangeCheckForAdd(index);
if(index == size) { // 往最后面添加元素
Node oldLast = last;
last = new Node<>(oldLast, element, null);
if (oldLast == null) { // 这是链表添加的第一个元素
first = last;
} else {
oldLast.next = last;
}
}else {
Node next=node(index);
Node prev=next.prev;
Node node=new Node<>(prev,element,next);
next.prev=node;
if(index==0) {//prev=null
first=node;
}else {
prev.next=node;
}
}
size++;
}
◼双向链表 - remove(int index)
也是以删除中间位置为例
Node prev = node.prev;//得到指定位置的上节点
Node next = node.next;//得到指定位置的下节点
prev.next = next;//prev.next指向next节点,越过node节点
next.prev = prev;//next.prev指向prev节点,不与原本的node相连
public E remove(int index) {
rangeCheck(index);
Node node = node(index);
Node prev = node.prev;
Node next = node.next;
if (prev == null) { // index == 0
first=next;
}else {
prev.next = next;
}
if (next == null) { // index == size - 1
last = prev;
}
else {
next.prev = prev;
}
size--;
return node.element;
}
◼动态数组:开辟、销毁内存空间的次数相对较少,但可能造成内存空间浪费(可以通过缩容解决)
◼双向链表:开辟、销毁内存空间的次数相对较多,但不会造成内存空间的浪费
◼如果频繁在尾部进行添加、删除操作,动态数组、双向链表均可选择
◼如果频繁在头部进行添加、删除操作,建议选择使用双向链表
◼如果有频繁的(在任意位置)添加、删除操作,建议选择使用双向链表◼如果有频繁的查询操作(随机访问操作),建议选择使用动态数组