【文献阅读】用于遥感数据集的视觉问答
一、文章概况
文章题目:《RSVQA: Visual Question Answering for Remote Sensing Data》
文章下载地址:
二、文献导读
摘要部分:
Abstract— This article introduces the task of visual question answering for remote sensing data (RSVQA). Remote sensing images contain a wealth of information, which can be useful for a wide range of tasks, including land cover classification, object counting, or detection. However, most of the available methodologies are task-specific, thus inhibiting generic and easy access to the information contained in remote sensing data. As a consequence, accurate remote sensing product generation still requires expert knowledge. With RSVQA, we propose a system to extract information from remote sensing data that is accessible to every user: we use questions formulated in natural language and use them to interact with the images. With the system, images can be queried to obtain high-level information specific to the image content or relational dependencies between objects visible in the images. Using an automatic method introduced in this article, we built two data sets (using low- and high-resolution data) of image/question/answer triplets. The information required to build the questions and answers is queried from OpenStreetMap(OSM). The data sets can be used to train (when using supervised methods) and evaluate models to solve the RSVQA task. We report the results obtained by applying a model based on convolutional neural networks (CNNs) for the visual part and a recurrent neural network (RNN) for the natural language part of this task. The model is trained on the two data sets, yielding promising results in both cases.
Index Terms— Convolution neural networks (CNNs), data set, deep learning, natural language, OpenStreetMap (OSM), recurrent neural networks (RNNs), very high resolution (HR), visual question answering (VQA).
本文主要介绍了遥感数据的视觉问答任务。遥感图像数据信息丰富,应用广泛,可用于土地覆盖分类、目标检测等方面。然而,现有的大多数方法都是根据具体任务来处理数据的,无法通用和方便地获取遥感数据中所含的信息。通过RSVQA,作者做了一个每个用户都可以从遥感数据中提取信息的系统,使用自然语言来表达问题,与图像互动。通过该系统,可以查询图像,获得特定图像的内容或图像之间关系的高级信息。本文创建了两个数据集(低分辨率数据集和高分辨率数据集)的图像/问题/答案三元组。从OpenStreetMap(OSM)中查询构建问题和答案所需要的信息。文中使用卷积神经网络(CNN)模型处理视觉信息,递归神经网络(RNN)模型处理自然语言部分。该模型在两个数据集上训练都取得了较好的结果。
三、文章详细介绍
遥感数数据有广泛的应用从土地覆盖/土地利用到人群估计、环境监测等。可以利用遥感数据来解决的问题的关键性质,在过去十年已作出重大努力来增加遥感数据的可用性。VQA的目的是回答一个给定图像的自由形式和开放式的问题。由于问题可以不受限制,应用于遥感数据的VQA模型可以作为涉及遥感数据的经典问题的通用解决方案(例如,“这张图像中有茅草屋顶吗?”,也包括一些非常具体的任务,包括不同性质的物体之间的关系(例如,“河的右边有茅草屋顶吗?”)。如下图所示,应用于遥感数据集的VQA模型。
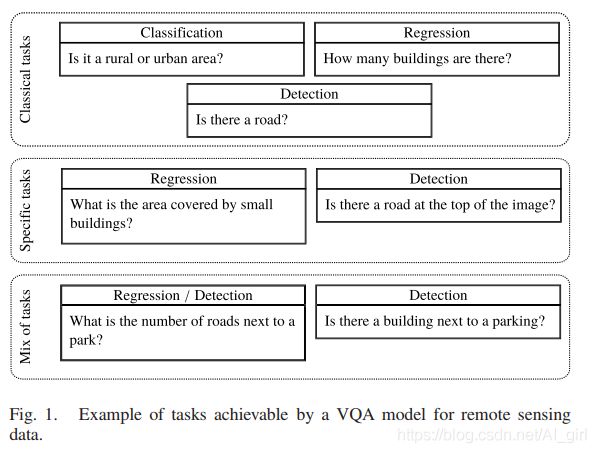
本文中,作者提出了VQA的一个新的应用,特别是与遥感图像的互交。 本文中作者提出了个面向遥感方法的VQA数据集,并评估了任务在遥感数据集上的适用性。
文章的主要贡献包括:
- 1) a method to generate remote sensing-oriented VQA data sets;(面向遥感的VQA数据集生成方法)
- 2) two data sets;(两个数据集)
- 3) the proposed RSVQA model.(提出RSVQA模型)
1、数据集
A.Method(方法)
VQA的一个主要限制因素是特定任务数据集的可用性。作者用一组遥感影像,提出了与之对应的问题和答案。 作者按照自动化程序构建了有关合成图像问题/答案对的数据集。公开的OMS数据包含地理位置信息,利用这些数据,从真实遥感数据中自动提取所需答案问/题对的相关信息。构建数据库的第一步是创建问题,第二步计算答案(注意:为每个图像提取多个答案对)。
问题构建(Question Construction)构建问题的方法如下图所示,主要由四个部分组成
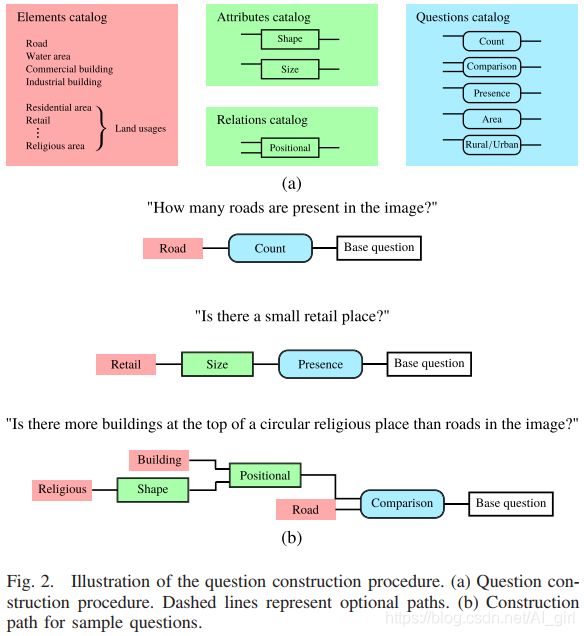
- 1) choice of an element category [highlighted in red in Fig. 2(a)];元素类别选择(红色)
- 2) application of attributes to the element [highlighted in green in Fig. 2(a)];元素属性应用(绿色)
- 3) selection based on the relative location to another element [highlighted in green in Fig. 2(a)];相对另一个元素位置选择(绿色)
- 4) construction of the question [highlighted in blue in Fig. 2(a)]问题结构(蓝色)
a)元素类别选择(Element category selection):首先从元素目录中随机选择一个元素。该目录是从OSM图层之一中提取元素建立的:道路、水域、建筑物和土地利用。道路和水域直接作为要素处理,建筑物和土地使用相关的对象是根据OSM数据规范中定义的“类型”字段定义的。土地利用对象的示例包括居住区、建筑区、宗教场所等。建筑物分为两类:商业(例如,零售和超市)和住宅(例如,房屋和公寓)。
b)属性应用( Attributes application):第二步是细化前面选择的元素类别,从形状(Shape)和尺寸(Size)两个可能的属性中随机选择一个。
1)形状(Shape)每个元素可以是正方形、矩形或圆形。元素是否属于其中一种类型取决于其集合属性(即面积/周长比和面积/外切圆面积比的硬阈值)
2)尺寸(Size)使用表面积上的硬阈值,可将元素是为"大","中","小"。如下图所示:

c)相对位置(Relative position)优化该元素的另一种可能性是与另一个元素相比查看其相对位置。 我们定义了五个关系:“左侧”,“顶部”,“右侧”,“底部”和“旁边”。这些相对位置是在图像空间(即地理位置)中理解的。
d)问题构建(Question construction):在这个过程中,一个元素(例如,道路)的属性(如,小道路)和可选的相对位置(如,位于水域左侧的道路)。最后一步是生成有关此元素的“base question”。作者定义了五种感兴趣问题,如[Fig. 2(a)]中,从中随机选择一个特定类型以获得一个基本问题,例如,在比较问题的情中,我们随机选择“小于”,“等于”和“大于”,并构造第二个元素。然后针对每个问题的类型和对象的预定义模板,将问题转化为自然语言问题。针对一类问题(例如,count)定义了多个模板(例如,(e.g., “how many__ are there?,” “what is the number of__ ?,” or “what is the amount of __?”)。使用模板的随机选择,保证了问题类型和问题模板的多样性。
答案构建(Answer Construction)从OSM提取与图像足迹相对应的对象,然后根据问题类型选择和使用对应于元素类别及其属性的对象b,以获取相对应的答案。
1)Count:在技术情况下,答案仅仅是对象的数量b。
2)Presence:通过将对象b的数量与0进行比较,可以回答存在问题。
3)Area:关于面积问题的答案是物体b的面积之和。
4) Comparison:通过将对象b的数量与第二个元素的数量进行比较来回答该问题。
5) Rural/Urban:这一类问题以特定的方式进行处理。不创建特定元素,而是计算建筑物的数量(包括商业和住宅)。根据输入数据的分辨率将建筑物的数量阈值化为一个预定义的数值来回答问题。
B.Data(数据)
本文根据上述数据集构建方法构建了两个不同特征的数据集:
1)Low Resolution (低分辨率LR):利用哨兵2号卫星在荷兰拍摄的照片,分辨率10M(数据集使用可见光波段),周期5天。该数据集取了9张覆盖荷兰的低云层图,总共被划分为772张大小为256× 256的RGB图像,覆盖面积6.55km2。利用上述构建问题的方法够建了77232个问题和答案。将数据集分为训练集(77.8%)、验证集(11.1%)和测试集(11.1%)。

2) High-Resolution (高分辨率HR):从USGS上获取高分辨率RGB正射影像(HRO),分辨率15CM,该数据集为美国一些地区,采用从2000到2016年的数据。该数据集中提取了美国东北岸161个贴图,被分成10659张大小为512×512的图像(每张占地5898平方米)。
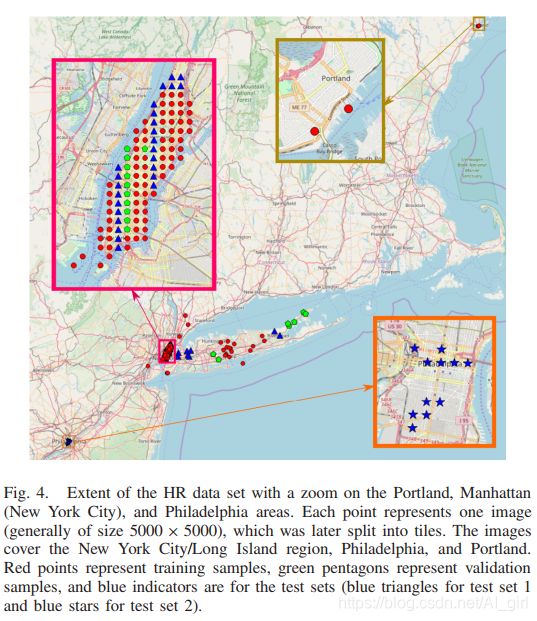
如上图Fig. 4所示,HR数据集的范围可扩展到波特兰,曼哈顿(纽约市)和费城地区。 每个点代表一个图像(通常大小为5000×5000),然后将其拆分为图块。 图像涵盖纽约市/长岛地区,费城和波特兰。 红点表示训练样本,绿色五边形表示验证样本,蓝色用于测试集(测试集1用蓝色三角形表示,测试集2用蓝星表示)。
利用上述构建问题的方法够建了1066316个问题和答案,将数据集分为训练集(61.5%)、验证集(11.2%)和测试集(测试集1 20.5%,6.8%为测试设置2)。从fig.4中可以看到,测试集1覆盖了训练集和验证集相似的区域,而测试集2覆盖的费城没有在训练集中出现,测试集2 实用的是另一个传感器上面的数据。
3)Differences Between the Two Data Sets:由于他们的特点,两个数据集分别代表了VQA两种不同的应用实例。
LR数据集有较大的时间和空间范围。这个特性对VQA未来大规模查询有很大的帮助,LR(10M)分辨率,一些小物体在图像上看不到(如房子、道路和树木等),限制了模型给出答案的准确性。HR数据集分辨率很高,有大量感兴趣信息来回答典型问题。因此,相随与LR数据集,关于对象覆盖或者较小的对象问题都可以从这些数据集中得到答案。然而这种数据集周期较长,获取成本较高。
基于上述这些不同之处,分别为两个数据集够早了不同类型的问题。是在HR数据集中询问有关对象面积的问题。关于城市、农村分类问题只在LR数据集中提问。考虑数据的分布个误差范围,作者量化了两个数据集的不同答案。
1) Counting in LR:覆盖范围相对较大,图中包含的小物体的数量可能很高,数值答案程重尾分布,如下图Fig. 5所示:

准确的说,26.7%的数字答案是“0”,50%的答案小于“7”,最高的数字答案是“17139”。在大多数情况下,在65 536像素的图像上区分17 139个物体是不可能的。因此,数值答案被量化为以下类别:
- 0;
- between 1 and 10;
- between 11 and 100;
- between 101 and 1000;
- more than 1000
2)以类似的方式两花了HR数据集中面积的的问题。这类答案中绝大部分(60.9%)是“0 m2”,分布也呈现出重尾现象,因此也使用与LR相同的量化方式
C. Discussion(讨论)
1)Questions/Answers Distributions:这两个类型的数据集每个问题的答案分布如下图Fig. 6所示。大多数问题类型程均匀分布(LR数据集中的“农村/城市”问题除外,每个图像仅被询问一次)。

在HR数据集的答案分布中,答案为“no”的占了37.7%。在LR数据集中,答案为“yes”的频率为34.9%,而“no”的频率是34.3%。
2)Limitations of the Proposed Method:作者提出的图像/问题/答案三元组生成的方法在人工标注时有自动和易于扩展的优点,但也存在一定的局限性。首先,可能会出现注释丢失注册错误的情况。此外,图像采集日期可能与OSM采集日期不相匹配,此外,用于自动构造和提供答案的模板比传统的VQA数据集更加有限(LR数据集有9个可能的答案,HR数据集有98个可能的答案)。
2、VQA MODEL(VQA模型)
利用基于深度学习的VQA模型研究遥感VQA任务的难点,温州港提出的网络模型结构如下图Fig. 7所示。
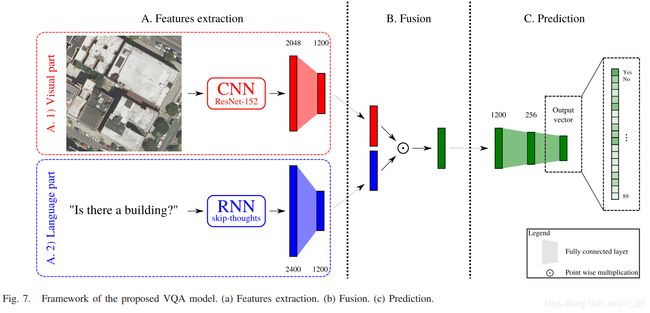
VQA模型主要由三部分组成:
- feature extraction;(特征提取)
- fusion of these features to obtain a single feature vector representing both the visual information and the question;(特征融合)
- prediction based on this vector.(预测)
如上图所示,该模型是端到端的学习过程,融合后的图像可以看作是图像和问题的联合嵌入,作为预测步骤的输入。下面详细介绍这三个部分 。
A. Feature Extraction(特征提取)
VQA模型的第一个组成部分是特征提取,是为了获得图像和问题中信息的低维表示。
1)Visual Part(视觉部分):一般使用CNN从2维图像中提取特征,本文使用ResNet-152在ImageNet上进行预训练。使用输入的残差映射避免了不必要的退化问题。最后的平均池化层和全连接层用一个1 × 1的二维卷积代替,共输出2048个特征向量,学习最终的全连阶层获得一个1200维的特征向量。
2) Language Part(语言部分):使用skip-thoughts模型在BookCorpus数据集上进行训练得到特征向量。这个是个循环神经网络模型,是为了生成一个表示单词序列的向量。模型训练时,对书中的一个句子进行编码,然后在对其解码,以获得该书中两个相邻的句子。在该模型中,作者使用编码器,然后是一个全连接层(大小从2400元素到1200个元素)。
B. Fusion(融合)
在这一步中,有两个大小相同的特征向量(一个表示图像,一个表示问题)。将其合并成一个向量,对向量元素使用双曲正切函数后进行元素点乘。
C. Prediction(预测)
通过使用具有256个元素的隐藏层的MLP,将此1200维的向量投影到答案空间。将问题表述为分类任务,其中每个可能的答案都是一类。 因此,输出向量的大小取决于可能答案的数量。
D. Training Procedure(训练过程)
模型训练使用Adam优化器,学习率为10-5,直到收敛为止(LR 设为150个epoch,HR维35个epoch)。每个全连阶层使使用0.但的dropout。因两个输入的数据集大小不同(HR图像是4倍大),训练批次也不同,HR数据集使用70个批量实例,对LR数据集使用280个批量实例。
3、分析
图8和图9中不同测试集的一些预测:





模型在LR数据集上的数值性能见表II:

混淆矩阵如图10所示:

HR数据集在两个测试集上的表现见表III:

混淆矩阵如图11所示:

4、结论