Python必应壁纸爬取系列(一):Bing当天壁纸太美你却爬取不到?使用Python,70行代码保存当天必应的超美壁纸屏保(Python获取Microsoft的当天唯美壁纸)
很多时候我们在使用微软的时候都会看到微软提供的一些漂亮的屏保,我们在打开微软官方的搜索引擎Bing时就会看到这样的图片
那么我们如何爬取这样美丽的图片呢,我们今天就来讲解一下。在这里我要说明的是,我在这里使用的是一个第三方的网站存储的必应图片,也就是说随时有可能不能访问(要是网站挂掉了之后就不行了)。但是这个网站的分类功能真的是我比较喜欢的,所以我还是写一个并不是官方渠道的爬取,如果想看官方渠道爬取的可以访问我的另一篇文章
阅读顺序
- 网站介绍
- 捋顺思路
-
- 准备工作
- 定义爬取类
- 访问网站
- 获取图片
- 下载图片
- 提高分辨率
- 完整代码
- 转载声明
网站介绍
这个网站叫做Preapix,是一个典型的外国网站,中国境内可能会出现响应较慢的情况,但是我用测速网站的工具测试了一下,除了云南电信是无法响应之外,国内大部分地区还是可以响应的
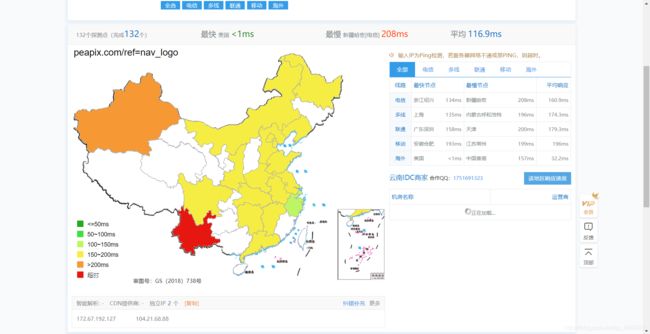
话不多说,我们现在就来分析如何爬取这个网站的图片
捋顺思路
准备工作
首先我们写一下这样的代码,如果我们看到可以访问的话,证明我们已经实现了第一步网络基础了,接下来就是要进行再一次测速
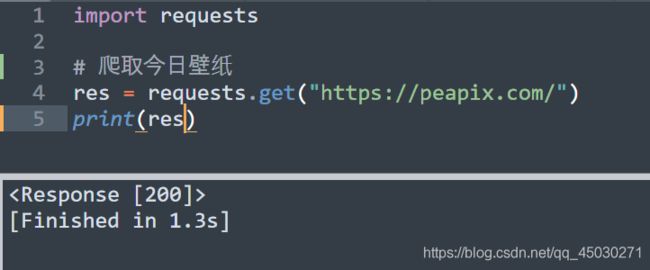
如果在五秒钟之类运行完了程序,那么证明我们的网速是可以的
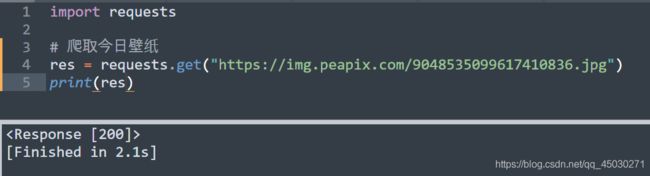
import requests
# 爬取今日壁纸
res = requests.get("https://img.peapix.com/9048535099617410836.jpg")
print(res)
定义爬取类
我们首先先创建几个要使用到的函数
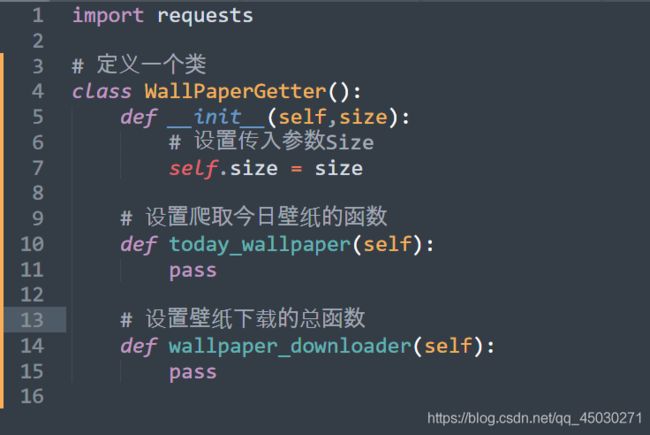
传参后没有问题及证明我们运行成功
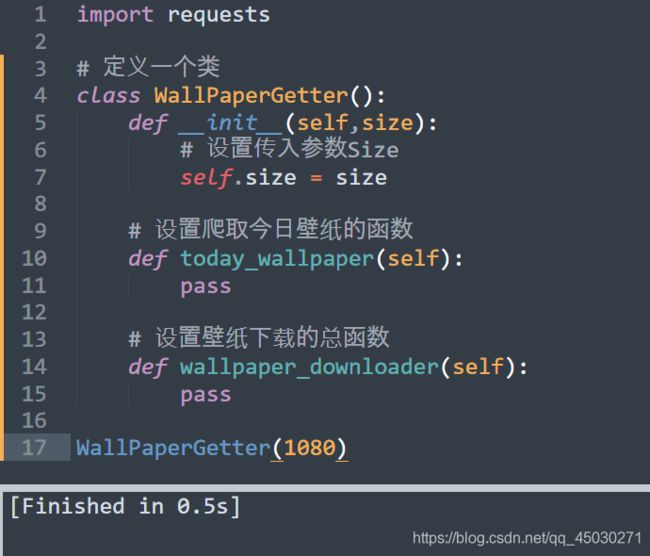
访问网站
我们可以看到,今日壁纸在一层层嵌套里面
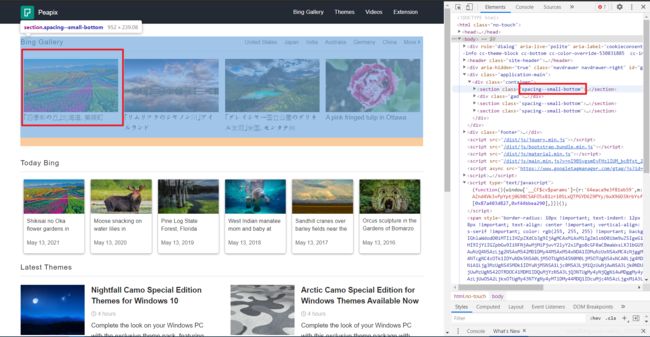
我们将today_wallpaper函数写入这样几行代码,同时在主函数里面调用today_wallpaper函数,如下图所示
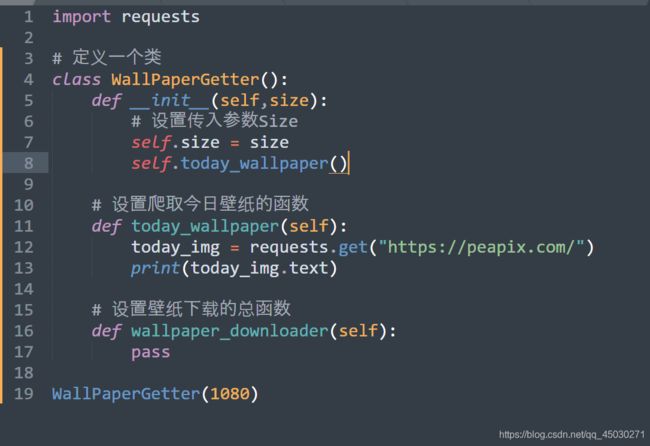
我们可以发现,这里似乎就是真实图片的地址
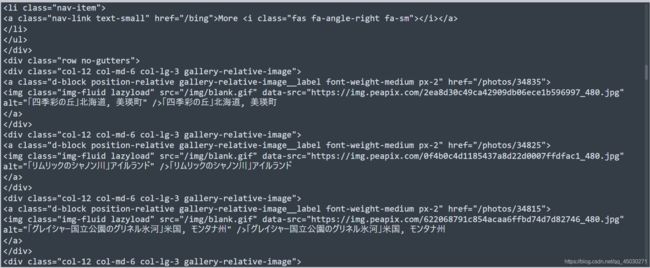
对比一下我们就可以发现,没错了
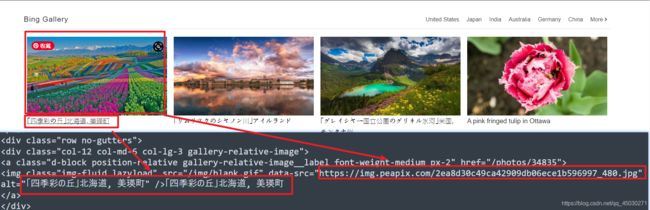
访问一下图片,咦,这图片是不是太小了
不管了,先爬取了再说,把代码变成这样
import requests
from bs4 import BeautifulSoup
# 定义一个类
class WallPaperGetter():
def __init__(self,size):
# 设置传入参数Size
self.size = size
self.today_wallpaper()
# 设置爬取今日壁纸的函数
def today_wallpaper(self):
today_img = requests.get("https://peapix.com/")
today_img = today_img.text
# 获取我们的HTML解释器
today_img_soup = BeautifulSoup(today_img,'html.parser')
# 获取所有col-12 col-md-6 col-lg-3 gallery-relative-image
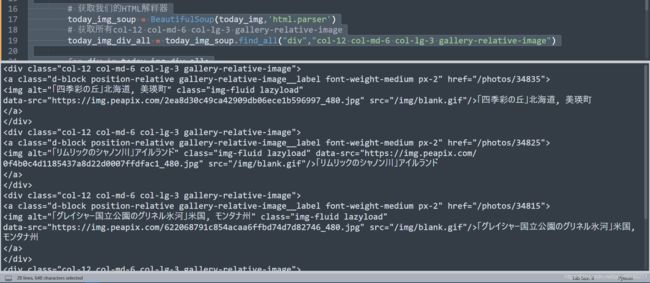
today_img_div_all = today_img_soup.find_all("div","col-12 col-md-6 col-lg-3 gallery-relative-image")
for div in today_img_div_all:
print(div)
# 设置壁纸下载的总函数
def wallpaper_downloader(self):
pass
WallPaperGetter(1080)
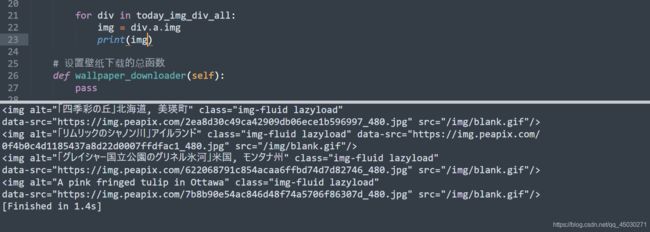
获取图片
您看,这不就成了吗?再来一波清洗,我们直接获取IMG属性
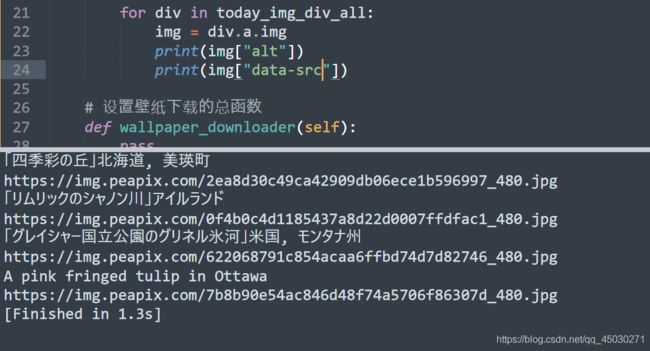
完美,成功,接下来就是赋值了
我们把代码写成这样,也就是加上了赋值和调用下载函数这简单一步
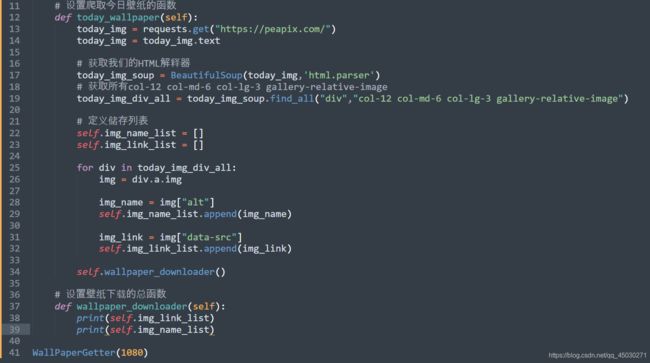
我们可以看到,我们的调用成功了

import requests
from bs4 import BeautifulSoup
# 定义一个类
class WallPaperGetter():
def __init__(self,size):
# 设置传入参数Size
self.size = size
self.today_wallpaper()
# 设置爬取今日壁纸的函数
def today_wallpaper(self):
today_img = requests.get("https://peapix.com/")
today_img = today_img.text
# 获取我们的HTML解释器
today_img_soup = BeautifulSoup(today_img,'html.parser')
# 获取所有col-12 col-md-6 col-lg-3 gallery-relative-image
today_img_div_all = today_img_soup.find_all("div","col-12 col-md-6 col-lg-3 gallery-relative-image")
# 定义储存列表
self.img_name_list = []
self.img_link_list = []
for div in today_img_div_all:
img = div.a.img
img_name = img["alt"]
self.img_name_list.append(img_name)
img_link = img["data-src"]
self.img_link_list.append(img_link)
self.wallpaper_downloader()
# 设置壁纸下载的总函数
def wallpaper_downloader(self):
print(self.img_link_list)
print(self.img_name_list)
WallPaperGetter(1080)
下载图片
接下来我们便要开始下载了,由于后面都比较简单,那么我也就不说那么多,直接上代码
import requests
from bs4 import BeautifulSoup
# 定义一个类
class WallPaperGetter():
def __init__(self,size):
# 设置传入参数Size
self.size = size
self.today_wallpaper()
# 设置爬取今日壁纸的函数
def today_wallpaper(self):
today_img = requests.get("https://peapix.com/")
today_img = today_img.text
# 获取我们的HTML解释器
today_img_soup = BeautifulSoup(today_img,'html.parser')
# 获取所有col-12 col-md-6 col-lg-3 gallery-relative-image
today_img_div_all = today_img_soup.find_all("div","col-12 col-md-6 col-lg-3 gallery-relative-image")
# 定义储存列表
self.img_name_list = []
self.img_link_list = []
for div in today_img_div_all:
img = div.a.img
img_name = img["alt"]
self.img_name_list.append(img_name)
img_link = img["data-src"]
self.img_link_list.append(img_link)
print("解析完毕")
self.wallpaper_downloader()
# 设置壁纸下载的总函数
def wallpaper_downloader(self):
# print(self.img_name_list)
# print(self.img_link_list)
print("开始获取下载链接")
len_img = len(self.img_name_list)
# print(len_img)
# 创建循环
for num in range(0,len_img):
# print(num)
wallpaper_img = requests.get(self.img_link_list[num])
print(self.img_name_list[num]+"-----访问成功")
# 获取网页内容
wallpaper_img = wallpaper_img.content
# 写入文件
with open(self.img_name_list[num]+".jpg","wb+")as img_write:
img_write.write(wallpaper_img)
print(self.img_name_list[num]+"-----写入成功")
img_write.close()
WallPaperGetter(1080)
但是我们爬取的结果的分辨率似乎不是特别高啊
提高分辨率
所以我们要怎样增加分辨率呢?这里其实我们可以来探讨一下,发现我们的链接有没有什么特别奇怪的地方
![]()
有没有觉得这个_480很奇怪呢?
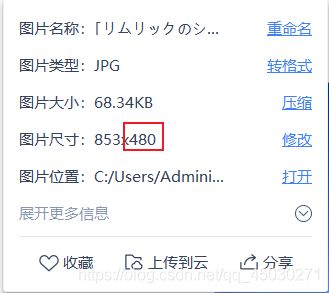
怎么图片的宽度就是480呢?那我们调一下1080试试
果然,它变大了,变得和屏幕一样大,那要是不加数字会怎么样呢?
同样,他其实还是1080,所以默认的图片宽度就是1080,大家也可以试一试别的数字。现在为了提高分辨率,我们更改代码为这样
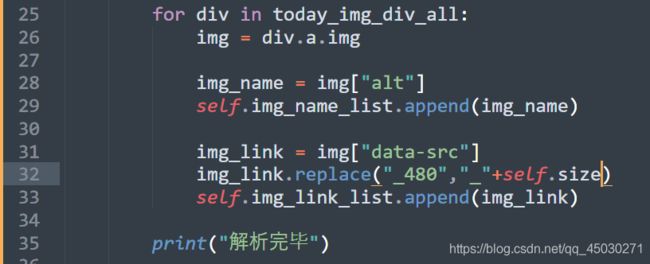
使用REPLACE方法代替字符串,并且将其变成我们所传入的参数
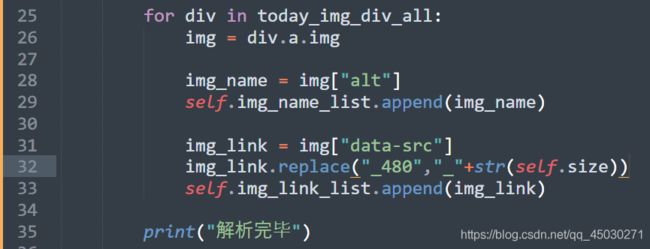
也可以加一下STR转换一下我们参数的类型
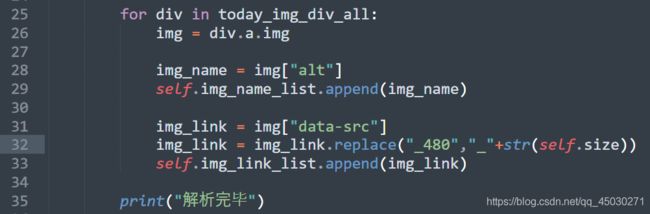
其实REPLACE函数并不会更改原字符串,所以我们要重新来一次赋值
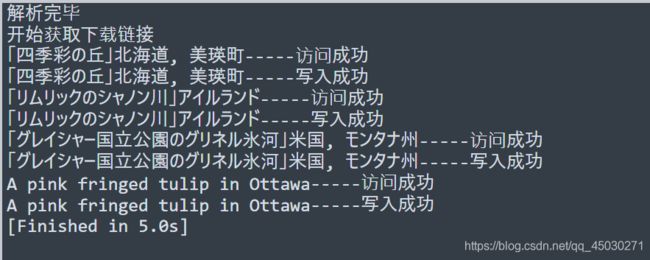

一前一后时间一对比,就立马不同了
完整代码
import requests
from bs4 import BeautifulSoup
# 定义一个类
class WallPaperGetter():
def __init__(self,size):
# 设置传入参数Size
self.size = size
self.today_wallpaper()
# 设置爬取今日壁纸的函数
def today_wallpaper(self):
today_img = requests.get("https://peapix.com/")
today_img = today_img.text
# 获取我们的HTML解释器
today_img_soup = BeautifulSoup(today_img,'html.parser')
# 获取所有col-12 col-md-6 col-lg-3 gallery-relative-image
today_img_div_all = today_img_soup.find_all("div","col-12 col-md-6 col-lg-3 gallery-relative-image")
# 定义储存列表
self.img_name_list = []
self.img_link_list = []
for div in today_img_div_all:
img = div.a.img
img_name = img["alt"]
self.img_name_list.append(img_name)
img_link = img["data-src"]
img_link = img_link.replace("_480","_"+str(self.size))
self.img_link_list.append(img_link)
print("解析完毕")
self.wallpaper_downloader()
# 设置壁纸下载的总函数
def wallpaper_downloader(self):
# print(self.img_name_list)
# print(self.img_link_list)
print("开始获取下载链接")
len_img = len(self.img_name_list)
# print(len_img)
# 创建循环
for num in range(0,len_img):
# print(num)
wallpaper_img = requests.get(self.img_link_list[num])
print(self.img_name_list[num]+"-----访问成功")
# 获取网页内容
wallpaper_img = wallpaper_img.content
# 写入文件
with open(self.img_name_list[num]+".jpg","wb+")as img_write:
img_write.write(wallpaper_img)
print(self.img_name_list[num]+"-----写入成功")
img_write.close()
WallPaperGetter(1080)
转载声明
博客在2021年5月13日首发自CSDN,如需转载,请附上原文链接:Python必应壁纸爬取系列(一):Bing当天壁纸太美你却爬取不到?使用Python,70行代码保存当天必应的超美壁纸屏保(Python获取Microsoft的当天唯美壁纸)