Spark读取csv,json文件
spark读取文件
- 一.读取csv文件
-
- 1.用sparkContext读文件
- 2.用sparkSession读文件
- 3.去除表头
-
- mapPartitionsWithIndex
- filter
- 4.查询语句(DataFrame)
- 4.列类型转化(将birthyear的类型转化为double型)
- 二.读取json文件
一.读取csv文件
要读取的csv文件
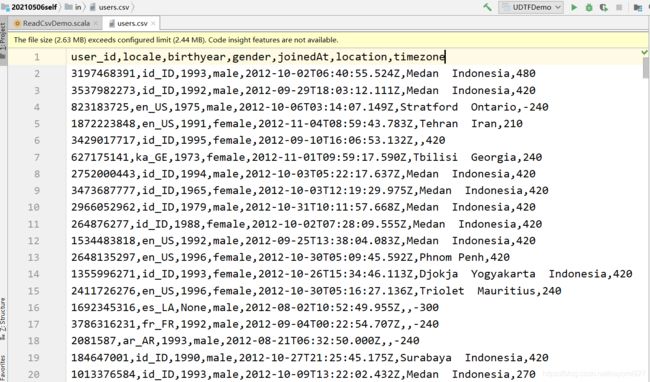
1.用sparkContext读文件
val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readcsv")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val lines:RDD[String]=sc.textFile("in/users.csv")
lines.take(5).foreach(println)//读五行
user_id,locale,birthyear,gender,joinedAt,location,timezone
3197468391,id_ID,1993,male,2012-10-02T06:40:55.524Z,Medan Indonesia,480
3537982273,id_ID,1992,male,2012-09-29T18:03:12.111Z,Medan Indonesia,420
823183725,en_US,1975,male,2012-10-06T03:14:07.149Z,Stratford Ontario,-240
1872223848,en_US,1991,female,2012-11-04T08:59:43.783Z,Tehran Iran,210
2.用sparkSession读文件
val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readcsv")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val spark:SparkSession=SparkSession.builder().master("local[*]").appName("readcsvspark").getOrCreate()
val df:DataFrame=spark.read.format("csv").option("header","true").load("in/users.csv")//option("header","true")表示是否将第一行作为表头
df.printSchema() //打印表结构
df.show(3) //打印文件3行
root
|-- user_id: string (nullable = true)
|-- locale: string (nullable = true)
|-- birthyear: string (nullable = true)
|-- gender: string (nullable = true)
|-- joinedAt: string (nullable = true)
|-- location: string (nullable = true)
|-- timezone: string (nullable = true)
+----------+------+---------+------+--------------------+------------------+--------+
| user_id|locale|birthyear|gender| joinedAt| location|timezone|
+----------+------+---------+------+--------------------+------------------+--------+
|3197468391| id_ID| 1993| male|2012-10-02T06:40:...| Medan Indonesia| 480|
|3537982273| id_ID| 1992| male|2012-09-29T18:03:...| Medan Indonesia| 420|
| 823183725| en_US| 1975| male|2012-10-06T03:14:...|Stratford Ontario| -240|
+----------+------+---------+------+--------------------+------------------+--------+
3.去除表头
mapPartitionsWithIndex
val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readcsv")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val lines:RDD[String]=sc.textFile("in/users.csv")
val lines1:RDD[String]=lines.mapPartitionsWithIndex((index:Int,value:Iterator[String])=>{
if(index==0) //index表示分区索引,value代表分区的内容
value.drop(1) //当分区索引为0时,删除第一行,也就是表头 drop 丢弃前n个元素新集合
else
value
})
val lines2:Array[Array[String]]=lines1.map(x=>x.split(",")).take(2) //数据太多,这边就展示两行
for(x<-lines2){
//使用增强for循环遍历数组
println(x.toList)
}
List(3197468391, id_ID, 1993, male, 2012-10-02T06:40:55.524Z, Medan Indonesia, 480)
List(3537982273, id_ID, 1992, male, 2012-09-29T18:03:12.111Z, Medan Indonesia, 420)
filter
val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readcsv")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val lines:RDD[String]=sc.textFile("in/users.csv")
val lines1:RDD[Array[String]]=lines.filter(x=>x.startsWith("user_id")==false).map(x=>x.split(",")) //filter返回false时过滤
lines1.take(2).foreach(x=>println(x.toList)) //将数组转化为list打印
List(3197468391, id_ID, 1993, male, 2012-10-02T06:40:55.524Z, Medan Indonesia, 480)
List(3537982273, id_ID, 1992, male, 2012-09-29T18:03:12.111Z, Medan Indonesia, 420)
4.查询语句(DataFrame)
查询user_id和birthyear
val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readcsv")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val spark:SparkSession=SparkSession.builder().master("local[*]").appName("readcsvspark").getOrCreate()
val df:DataFrame=spark.read.format("csv").option("header","true").load("in/users.csv")
df.select("user_id","birthyear").printSchema()
df.select("user_id","birthyear").show(3)
root
|-- user_id: string (nullable = true)
|-- birthyear: string (nullable = true)
+----------+---------+
| user_id|birthyear|
+----------+---------+
|3197468391| 1993|
|3537982273| 1992|
| 823183725| 1975|
+----------+---------+
only showing top 3 rows
4.列类型转化(将birthyear的类型转化为double型)
val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readcsv")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val spark:SparkSession=SparkSession.builder().master("local[*]").appName("readcsvspark").getOrCreate()
val df:DataFrame=spark.read.format("csv").option("header","true").load("in/users.csv")
val df1:DataFrame=df.select("user_id","birthyear")
//withColumn是新增列函数 第一个参数是新增列名,第二个参数col是原有列
//cast是类型转换函数
val df2:DataFrame=df1.withColumn("birthyear",df1("birthyear").cast(DoubleType))
df2.printSchema()
df2.withColumnRenamed("birthyear","birthyear2").printSchema() //改名
//isNullAt是数值类型判空
//此处过滤出birth不为空并且数值小于1995的
df2.filter(x=> !x.isNullAt(1) && x.getDouble(1)<1995).show(3)
root
root
|-- user_id: string (nullable = true)
|-- birthyear: double (nullable = true)
root
|-- user_id: string (nullable = true)
|-- birthyear2: double (nullable = true)
+----------+---------+
| user_id|birthyear|
+----------+---------+
|3197468391| 1993.0|
|3537982273| 1992.0|
| 823183725| 1975.0|
+----------+---------+
only showing top 3 rows
二.读取json文件
要读取的json文件

val conf:SparkConf=new SparkConf().setMaster("local[*]").setAppName("readjson")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val spark:SparkSession=SparkSession.builder().master("local[*]").appName("readjsonspark").getOrCreate
//用sparkcontext读文件
val lines:RDD[String]=sc.textFile("in/user.json")
lines.foreach(println)
//导包
import scala.util.parsing.json.JSON
//将文件用map形式读出来
val rdd:RDD[Option[Any]]=lines.map(x=>JSON.parseFull(x))
rdd.foreach(println)
//用sparksession读文件
spark.read.format("json").load("in/user.json").show()
{
"id":3, "name":"wangwu", "age":23}
{
"id":1, "name":"zhangsan", "age":21}
{
"id":4, "name":"zl", "age":23}
{
"id":2, "name":"lisi", "age":22}
Some(Map(id -> 3.0, name -> wangwu, age -> 23.0))
Some(Map(id -> 1.0, name -> zhangsan, age -> 21.0))
Some(Map(id -> 2.0, name -> lisi, age -> 22.0))
Some(Map(id -> 4.0, name -> zl, age -> 23.0))
+---+---+--------+
|age| id| name|
+---+---+--------+
| 21| 1|zhangsan|
| 22| 2| lisi|
| 23| 3| wangwu|
| 23| 4| zl|
+---+---+--------+