知识图谱前沿跟进,看这篇就够了,Philip S. Yu 团队发布权威综述,六大开放问题函待解决!...

来源:AI科技评论
本文约8400字,建议阅读15分钟
本文是数据科学权威 Philip S. Yu 团队对知识图谱领域的最新综述,从发展历史、理论基础、实际应用、未来的研究方向等方面为该领域勾画出了一幅宏伟而全面的图景。

标签:知识图谱
2019 年年底,图灵奖获得者 Bengio 曾指出,我们正处于从以感知智能为代表的深度学习“系统一”,向以认知智能为代表的深度学习 “系统二”过渡的时期。
在这个过程中,知识图谱技术起到了关键性的作用。近年来,图网络的蓬勃发展也印证了这一趋势。
引入人类的知识是人工智能的重要研究方向之一。知识表征和推理受到了人类解决问题方法的启发,旨在为智能系统表征知识,从而获得解决复杂问题的能力。最近,知识图谱作为一种结构化的人类知识,同时受到了学术界和工业界人士的极大关注。
知识图谱是一种对于事实的结构化表征,它由实体、关系和语义描述组成。实体可以是真实世界中存在的对象,也可以是抽象的概念;关系则表示实体之间的关联;实体及其关系的语义描述包含定义良好的类型和属性。如今,属性图已经被广泛使用,其中节点和关系都具有属性。
术语知识图谱和知识库几乎是同义词,只有很微小的差别。当我们考虑知识图谱的图结构时,可以将其视为一个图。当涉及形式语义问题时,它又可以作为对事实进行解释和推理的知识库。知识库和知识图谱的具体形式如图 1 所示。
知识可以通过资源描述框架(RDF)被表示为一种事实三元组的形式,如(头实体,关系,尾实体)或(主语,谓语,宾语),例如(爱因斯坦,是...获奖者,诺贝尔奖)。知识也可以被表征为一种有向图,其节点代表实体,边代表关系。
为了简便起见,并顺应研究社区的发展趋势,本文中互换使用知识图谱和知识库这两个术语。
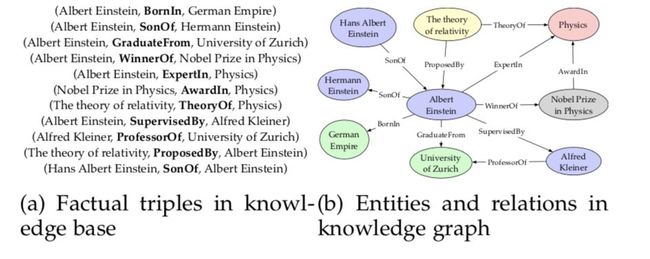
图 1:知识库和知识图谱示意图
近年来,基于知识图谱的研究主要关注的是,通过将实体和关系映射到低维向量中,获取它们的语义信息,从而实现知识表征学习(KRL)或知识图谱嵌入(KGE)。具体的知识获取任务包括知识图谱补全(KGC)、三元组分类、实体识别,以及关系抽取。
基于知识的模型得益于异构信息、丰富的知识表征本体和语义,以及多种语言知识的集成。因此,在常识理解能力和推理能力取得进步的同时,诸如推荐系统和问答系统等许多真实世界中的应用也走向了繁荣。微软的 Satori 和谷歌的知识图谱等现实世界中的产品,已经展现出了提供更多高效服务的强大能力。

论文链接:http://arxiv.org/abs/2002.00388
1 知识库简史
在逻辑学和人工智能领域,知识表征经历了漫长的发展历史。用图进行知识表征的思想最早可以追溯到 Richens 在 1956 年提出的语义网(Semantic Net),而符号逻辑知识则可以追溯到 1959 年的通用问题求解器。
起初,知识库被用于基于知识的推理的问题求解系统。MYCIN 是被用于医学诊断的、最著名的基于规则的专家系统之一,它拥有一个包含约 600 条规则的知识库。
在这之后,人类知识表征研究社区在基于框架的语言、基于规则的表征以及混合表征方面都取得了一定的研究进展。大约在这一时期的末期,旨在集成人类知识的 Cyc 计划,开始了。
资源描述框架(RDF)和网络本体语言(OWL)相继发布,成为了语义网的重要标准。接着,人们也发布了诸如 WordNet、DBpedia、YAGO 和 Freebase 这样的开放的知识库或本体。
Stokman 和 Vries 于 1988 年提出了现代意义上的以图的形式组织知识的思想。然而,知识图谱的概念开始盛行还要等到2012 年谷歌首次在其搜索引擎中引入知识图谱,此时它们提出了被称为Knowledge Vault的知识融合框架,从而构建大规模知识图谱。知识库的发展历史简图请参阅本文附录 A。
2 相关定义和符号
研究人员做了大量工作,通过描述通用语义表征或本质特征来为知识图谱给出定义。然而,知识图谱至今仍没有被广为接受的正式定义。Paulheim 定义了 4 种知识图谱的标准。Ehrlinger 和 Wo ̈ß 分析了一些现有的定义,并提出了如下所示的定义 1,它强调了知识图谱的推理引擎。Wang 等人在定义 2 中提出了一个多关系图的定义。
受到之前这些工作的启发,我们将一个知识图谱定义为 G = {E,R,F},其中 E、R、F分别是实体、关系和事实的集合。事实可以被表示为一个三元组 (h,r,t) ∈ F。
定义 1(Ehrlinger 和 Wo ̈ß):知识图谱会获取信息并将其集成到一个本体中,使用一个推理器产生新的知识。
定义 2(Wang 等人):知识图谱是由实体和关系构成的多关系图,实体被视为节点而关系被视为各种不同类型的边。

表1:知识图谱相关符号和定义
3 知识图谱研究分类
1、知识表征学习(KRL)
知识表征学习是知识图谱领域的关键研究问题,它为许多知识获取任务和下游应用打下了基础。我们将 KRL 分为 4 个层面:表征空间、打分函数、编码模型和辅助信息。本文还给出了明确的研发 KRL 模型的工作流程。详细内容如下:
1)表征空间
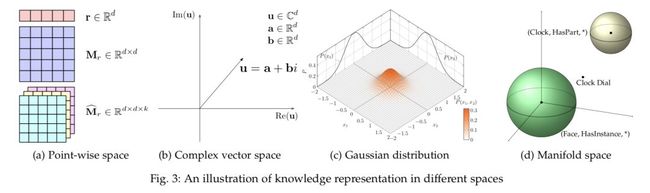
图 3:不同空间中的知识表征示意图
学习实体和关系的低维分布嵌入是表征学习的关键问题。现有的工作主要使用的是向量、矩阵、张量空间等实值点空间(如图 3a 所示),同时也会使用复杂向量空间(如图 3b 所示)、高斯空间(如图 3c 所示)以及流形(如图 3d 所示)等其它类型的空间。
2)打分函数
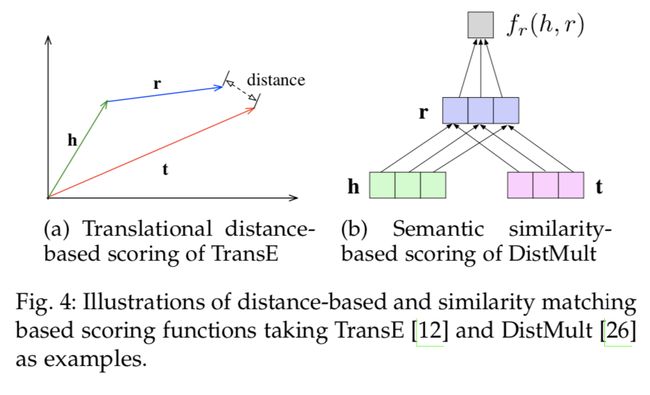 图 4:基于距离和基于相似度匹配的打分函数示意图,分别以 TransE 和 DistMult 为例
图 4:基于距离和基于相似度匹配的打分函数示意图,分别以 TransE 和 DistMult 为例
打分函数被用来衡量事实的合理性,它在基于能量的学习框架中也被称为能量函数。基于能量的学习旨在学习输入为 x、参数为 θ 的能量函数 E_θ(x),它将确保正样本比负样本有更高的得分。在本文中,统一将其称为打分函数。
典型的用于衡量事实合理性的打分函数分为两类:即基于距离的打分函数(如图 4a 所示)和基于相似度的打分函数(如图 4b)。基于距离的打分函数通过计算实体之间的距离衡量事实的合理性,通过实体间关系实现 h + r ≈ t 这种加法变换的思想被广泛使用。基于语义相似度的打分函数通过语义匹配衡量事实的合理性,它通常采用![]() 这样的乘法公式在表征空间中将头实体变换得与尾实体相近。
这样的乘法公式在表征空间中将头实体变换得与尾实体相近。
3)编码模型
编码模型通过特定的模型架构(如线性/双线性模型、因子分解模型、神经网络)编码实体和关系之间的相互作用。
线性模型通过将头实体投影到接近尾实体的表征空间中,将关系表示为一个线性/双线性映射。因子分解旨在将关系型数据分解到低秩矩阵中,从而进行表征学习。神经网络则通过非线性神经激活映射和更加复杂的网络结构对关系型数据进行编码。一些常见的神经网络模型如图 5 所示。
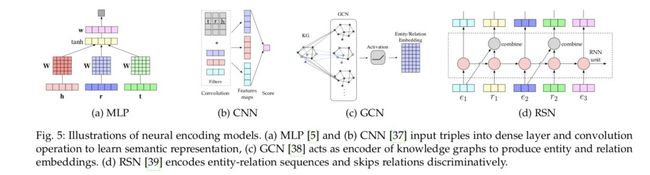
图 5:神经编码模型示意图。(a)多层感知机,和(b)卷积神经网络将三元组输入到全连接层中,并且进行卷积操作,从而学习到语义表征。(c)图卷积网络作为知识图谱编码器,生成实体和关系的嵌入。(d)RSN 有差别地对“实体-关系序列”和跳跃关系进行编码。
4)辅助信息
为了促进更有效的知识表征,多模态嵌入将诸如文本描述、类型约束、关系路径以及视觉信息等外部信息与知识图谱本身融合在了一起。
在知识图谱研究社区中,知识表征学习是非常重要的。总的来说,想要研发一个新的知识表征学习模型需要回答以下 4 个问题:(1)选择怎样的表征空间;(2)如何度量特定空间中的三元组合理性;(3)用怎样的编码模型编码关系的相互作用;(4)是否要利用辅助信息。
最常用的表征空间是欧氏点空间,它将实体嵌入到向量空间中,并且通过向量、矩阵或张量对相互作用进行建模。人们也研究了其它的表征空间(包括复杂向量空间、高斯分布、流形空间、群)。
相对于欧氏点空间,流形空间的优势在于它能够松弛基于点的嵌入;高斯嵌入可以表达出实体和关系之间的不确定性,以及多重关系语义;复杂向量空间中的嵌入可以有效地建模不同的关系连接模型,特别是对称/反对称模式。
在编码实体的语义信息和获取关系属性时,表征空间起着非常重要的作用。当我们研发一个表征学习模型时,应该选择合适的表征空间,该表征空间被精心设计以匹配编码方式的特性,并且能够在表达能力和计算复杂度之间达到平衡。
采用基于距离的度量的打分函数会用到相应的转化原则,而基于语义匹配的打分函数则会采用成分级别的操作。编码模型(尤其是神经网络)在对于实体和关系的相互作用建模的过程中起到了关键作用。双线性模型也受到了很多研究人员的关注,一些张量分解技术与此相关。其它方法则引入了文本描述、关系/实体类型,以及实体图像等辅助信息。

表 2:对近期知识表征学习工作的总结。详情请参阅附录 C
2、知识获取
知识获取旨在根据非结构化的文本构建知识图谱、补全一个现有的知识图谱,发现并识别出实体和关系。构建好的大型知识图谱对于很多下游应用是很有用的,可以赋予基于知识的模型常识推理的能力,因此为实现人工智能打下基础。
知识获取的主要任务包括关系抽取、知识图谱补全、以及其它面向实体的获取任务,如实体识别和实体对齐。大多数方法单独地形式化定义知识图谱补全和关系抽取。然而,这两种任务也可以被整合到一个统一的框架中。
Han 等人基于互注意力机制提出了一种联合学习框架,这种互注意力机制被用于知识图谱和文本之间的数据融合,该框架同时解决了根据文本进行知识图谱补全和关系抽取的问题。此外,还有一些任务也与知识补全有关(例如,三元组分类和关系分类)。在本节中,我们将完整地回顾知识补全、实体发现和关系抽取三步知识获取技术。
1)知识图谱补全(KGC)
由于大多知识图谱具有不完整性,人们研发知识补全技术将新的三元组添加到一个新的知识图谱中。典型的子任务包括链接预测、实体预测和关系预测。下面我们给出面向任务的定义 3。
定义 3:给定一个不完整的知识图谱 G=(E,R,F),知识图谱补全旨在推理出缺失的三元组 T={(h,r,t)|(h,r,t)∉ F}。
初期的知识图谱补全研究重点关注为三元组预测学习低维嵌入。在本文中,我们将其称为基于嵌入的方法。
然而,大多数这些方法都不能获取多级关系。因此,最近的工作转而探索多级关系路径并引入了逻辑关系,我们分别将其称为关系路径推理和基于规则的推理。三元组分类是知识图谱补全的一个辅助任务,它被用来评价事实三元组的正确性。
2)实体发现
实体发现可以从文本中获取面向实体的知识,并且在各个知识图谱之间进行知识融合。根据具体情况,可以将实体发现任务分为几种不同的类别。
我们以一种序列到序列(Seq2Seq)的方式探究实体识别任务;而实体分类任务则重点讨论的是有噪声的类型标签和零样本分类;实体消歧和对齐任务会学习统一的嵌入,它们提出迭代式的对齐模型解决对齐种子实体数量有限的问题。但是如果新对齐的实体性能很差,它将会面临误差累积的问题。
近年来,针对特定语言的知识越来越多,因此必然激发了对于跨语言知识对齐的研究。
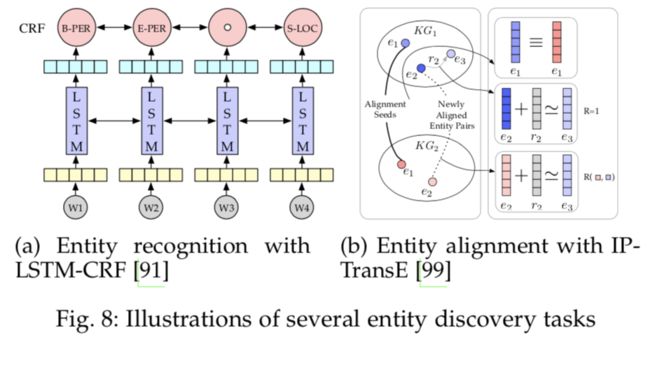
图 8:一些实体发现任务的示意图
3)关系抽取
关系抽取是自动构建大型知识图谱的关键任务,该任务将从朴素文本中抽取出未知的关系事实,并将他们添加到知识图谱中。
由于缺乏带有标签的关系型数据,远程监督(Distant Supervision)技术(又称弱监督或自监督)使用启发式匹配,假设在关系型数据库的监督下,包含相同实体的句子可能表达相同的关系,从而创建训练数据。
Mintz 等人将远程监督用于关系分类任务,他们用到的文本特征包括词法和句法特征、命名实体标签,以及连接词特征。传统的方法高度依赖于特征工程,而最近的一种方法则探索了特征之间的内在联系。深度神经网络也正在改变知识图谱和文本的表征学习。最近在神经关系抽取(NRE)方法上的研究进展如图 9 所示。
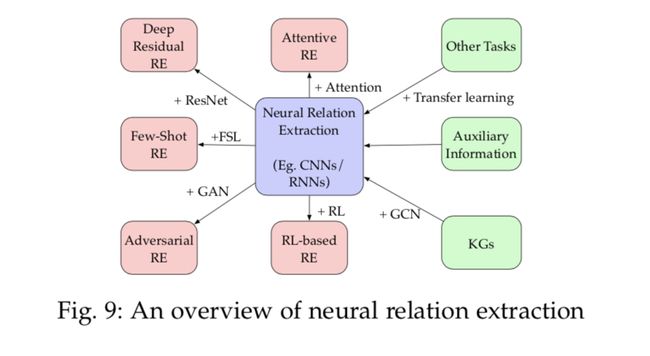
图 9:神经关系抽取概览
关系抽取任务在远程监督的假设下会遇到带有噪声的模式,特别是在不同领域之间进行远程监督时。因此,对于弱监督关系抽取来说,减小带噪声标签的影响是非常重要的(例如,通过多示例学习将多个句子组成的包作为输入,使用注意力机制在示例上进行软选择从而减少带噪声的模式,基于强化学习的方法将示例选择表示为硬性决策。另一个原则是,尽可能学习到更加丰富的表征。由于深度神经网络可以解决传统特征抽取方法中的误差传播问题,该领域一直被基于深度神经网络的模型所主导。
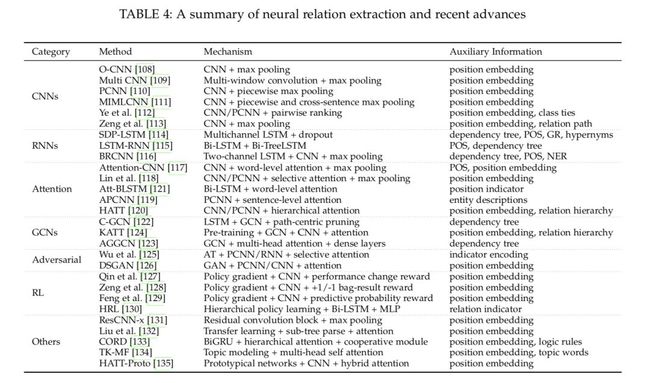 表 4:神经关系抽取近期研究进展一览
表 4:神经关系抽取近期研究进展一览
3、时序知识图谱
现有的知识图谱研究大多数都关注的是静态知识图谱,其中事实不会随着时间而变化,然而目前对知识图谱的时序动态变化的研究则较少。然而,由于结构化的知识仅仅在特定的时间段内成立,所以时序信息是非常重要的,而事实的演化也会遵循一个时间序列。
近期的研究开始将时序信息引入知识表征学习和知识图谱补全任务。为了与之前的静态知识图谱产生对比,我们将其称为时序知识图谱。为了同时学习时序嵌入和关系嵌入,人们进行了大量的研究工作。
1)时序信息嵌入
在与时序有关的嵌入中,我们通过将三元组拓展成时序四元组 (h,r,t,τ) 来考虑时序信息。其中 τ 提供了关于事实何时成立的额外的时序信息。Leblay 和 Chekol 利用带有时间标注的三元组研究了时序范围预测问题,并简单地拓展了现有的嵌入方法。例如,将 TransE 拓展为基于向量的 TTransE 定义如下:
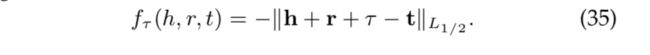
2)实体动态
现实世界中的事件会改变实体的状态,并因此影响相应的关系。为了提升时间范围预测的性能,上下文时序剖面模型将时序范围预测形式化定义为了状态变化检测问题,利用上下文学习状态和状态变化向量。
Know-evolve是一种深度演化知识网络,它研究了实体和它们演化后的关系的知识演化现象。人们使用了一种多变量时序点过程对事实的发生进行建模,研发出了一种新型的循环网络学习非线性时序演化的表征。
为了获取节点之间的相互作用,RE-NET 通过基于循环神经网络的编码器和邻居聚合器对事件序列进行建模。具体而言,他们使用循环神经网络来获取时序实体相互作用的信息,并且通过邻居聚合器将同时发生的相互作用进行聚合。
3)时序关系依赖
在关系链中,沿着时间线存在时序依赖关系。例如,“在...出生 →从...毕业 → 在...工作 → 在...去世”。Jiang 等人提出了基于时间的嵌入,这是一种带有时序正则化的联合学习框架,从而引入时间顺序和一致性信息。作者将时序打分函数定义如下:
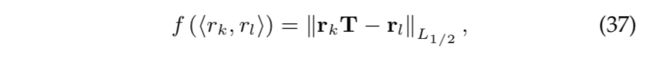
其中,![]() 是一个非对称矩阵,它为时序顺序关系对⟨r_k,r_l⟩编码了关系的时序顺序。此后,人们又进一步通过整数线性规划公式,应用了不相交性、有序性和跨度三种时间一致性约束。
是一个非对称矩阵,它为时序顺序关系对⟨r_k,r_l⟩编码了关系的时序顺序。此后,人们又进一步通过整数线性规划公式,应用了不相交性、有序性和跨度三种时间一致性约束。
4)时序逻辑推理
研究人员还研究了时序推理的逻辑规则。Chekol 等人探究了在非确定性时序知识图谱上进行推理的马尔科夫逻辑网络和概率软逻辑。RLvLR-Stream 则考虑闭合时间路径规则,并从知识图谱流中学习规则的结构进行推理。
4、基于知识图谱的应用
对于人工智能应用来说,丰富的结构化知识是很有用的。但是如何将这些符号化的知识融合到现实世界应用的计算框架中仍然是一大挑战。本节将介绍一些近期的基于深度神经网络的知识驱动方法在自然语言理解(NLU)任务上的应用。
1)自然语言理解
基于知识的自然语言理解通过被注入统一语义空间的结构化知识提升了语言表征的性能。最近,该领域由知识驱动的研究进展利用了显式的事实知识和隐式的语言表征,并探索了许多自然语言理解任务。
Chen 等人提出了在两个知识图谱(即一个基于槽(slot-based)的语义知识图谱和基于单词的词法知识图谱)上的双图随机游走技术,从而考虑口语理解中的槽间关系。Wang 等人通过加权的单词-概念嵌入实现的基于知识的概念模型增强了短文本表征学习。Peng 等人融合了外部知识库,从而为短社交文本的事件分类任务构建了异构信息图谱。
2)问答系统基于知识的问答(KG-QA)系统使用来源于知识图谱的事实回答自然语言问题。基于神经网络的方法在分布式语义空间中表征问题和答案,也有一些方法进行了符号知识注入,从而实现常识推理。
通过将知识图谱作为外部智能来源,简单的事实型问答系统或单一事实问答系统就可以回答设计单个知识图谱事实的简单问题。Bordes 等人通过将知识库作为外部记忆,将记忆网络用于简单的问答。
这些基于神经网络的方法将神经编码器-解码器模型结合起来,获得了性能的提升。但是想要处理复杂的多级关系还需要能够处理多级常识推理的、更加专用的网络设计。结构化的知识提供了富含信息的常识观察,并作为一种关系型归纳偏置存在,它促进了最近关于多级推理的符号和语义空间之间的常识知识融合的研究。
3)推荐系统
研究人员通过协同过滤对推荐系统进行了广泛的研究,该方法使用了用户的历史信息。然而,这种方法往往不能解决稀疏性问题和冷启动问题。将知识图谱作为外部信息引入可以为推荐系统赋予常识推理的能力。
通过注入基于知识图谱的辅助信息(例如,实体、关系和属性),研究人员在用于提升推荐性能的嵌入正则化方面做了大量工作。还有一些工作考虑到了关系路径和知识图谱的结构,KPRN 将用户和商品之间的交互看做知识图谱中的实体-关系路径,并且使用 LSTM 获取序列的依赖性,从而在路径上进行用户喜好预测。
4 未来的研究方向
研究人员做了大量工作解决知识表征及其相关应用面临的挑战,但是仍然有一些艰难的开放问题有待解决,未来也有一些前景光明的的研究方向。
1、复杂的推理
用于知识表征和推理的数值化计算需要连续的向量空间,从而获取实体和关系的语义信息。然而,基于嵌入的方法在复杂逻辑推理任务中有一定的局限性,但关系路径和符号逻辑这两个研究方向值得进一步探索。在知识图谱上的循环关系路径编码、基于图神经网络的信息传递等具有研究前景的方法,以及基于强化学习的路径发现和推理对于解决复杂推理问题是很有研究前景的。
在结合逻辑规则和嵌入的方面,近期的工作将马尔科夫逻辑网络和 KGE 结合了起来,旨在利用逻辑规则并处理其不确定性。利用高效的嵌入实现能够获取不确定性和领域知识的概率推理,是未来一个值得注意的研究方向。
2、统一的框架
已有多个知识图谱表征学习模型被证明是等价的。例如,Hayshi 和 Shimbo 证明了 HoIE 和 ComplEx 对于带有特定约束的链接预测任务在数学上是等价的。ANALOGY 为几种具有代表性的模型(包括 DistMult、ComplEx,以及 HoIE)给出了一个统一的视角。Wang 等人探索了一些双线性模型之间的联系。Chandrahas 等人探究了对于加法和乘法知识表征学习模型的几何理解。
大多数工作分别使用不同的模型形式化定义了知识获取的知识图谱补全任务和关系抽取任务。Han 等人将知识图谱和文本放在一起考虑,并且提出了一种联合学习框架,该框架使用了在知识图谱和文本之间共享信息的互注意力机制。不过这些工作对于知识表征和推理的统一理解的研究则较少。
然而,像图网络的统一框架那样对该问题进行统一的研究,是十分有意义的,将填补该领域研究的空白。
3、可解释性
知识表征和注入的可解释性对于知识获取和真实世界中的应用来说是一个关键问题。在可解释性方面,研究人员已经做了一些初步的工作。ITransF 将稀疏向量用于知识迁移,并通过注意力的可视化技术实现可解释性。CrossE 通过使用基于嵌入的路径搜索来生成对于链接预测的解释,从而探索了对知识图谱的解释方法。
然而,尽管最近的一些神经网络已经取得了令人印象深刻的性能,但是它们在透明度和可解释性方面仍存在局限性。一些方法尝试将黑盒的神经网络模型和符号推理结合了起来,通过引入逻辑规则增加可解释性。
毕竟只有实现可解释性才可以说服人们相信预测结果,因此研究人员需要在可解释性和提升预测知识的可信度的方面做出更多的工作。
4、可扩展性
可扩展性是大型知识图谱的关键问题。我们需要在计算效率和模型的表达能力之间作出权衡,而只有很少的工作被应用到了多于 100 万个实体的场景下。一些嵌入方法使用了简化技术降低了计算开销(例如,通过循环相关运算简化张量的乘积)。然而,这些方法仍然难以扩展到数以百万计的实体和关系上。
类似于使用马尔科夫逻辑网络这样的概率逻辑推理是计算密集型的任务,这使得该任务难以被扩展到大规模知识图谱上。最近提出的神经网络模型中的规则是由简单的暴力搜索(BF)生成的,这使得它在大规模知识图谱上不可行。例如 ExpressGNN 试图使用 NeuralLP 进行高效的规则演绎,但是要处理复杂的深度架构和不断增长的知识图谱还有很多研究工作有待探索。
5、知识聚合
全局知识的聚合是基于知识的应用的核心。例如,推荐系统使用知识图谱来建模用户-商品的交互,而文本分类则一同将文本和知识图谱编码到语义空间中。不过,大多数现有的知识聚合方法都是基于注意力机制和图神经网络(GNN)设计的。
得益于 Transformers 及其变体(例如 BERT 模型),自然语言处理研究社区由于大规模预训练取得了很大的进步。而最近的研究发现,使用非结构化文本构建的预训练语言模型确实可以获取到事实知识。大规模预训练是一种直接的知识注入方式。然而,以一种高效且可解释的方式重新思考只是聚合的方式也是很有意义的。
6、自动构建和动态变化
现有的知识图谱高度依赖于手动的构建方式,这是一种开销高昂的劳动密集型任务。知识图谱在不同的认知智能领域的广泛应用,对从大规模非结构化的内容中自动构建知识图谱提出了要求。
近期的研究主要关注的是,在现有的知识图谱的监督信号下,半自动地构建知识图谱。面对多模态、异构的大规模应用,自动化的知识图谱构建仍然面临着很大的挑战。
目前,主流的研究重点关注静态的知识图谱。鲜有工作探究时序范围的有效性,并学习时序信息以及实体的动态变化。然而,许多事实仅仅在特定的时间段内成立。
考虑到时序特性的动态知识图谱,将可以解决传统知识表征和推理的局限性。
编辑:王菁
校对:林亦霖
