基于目标导向行为和空间拓扑记忆的视觉导航方法
基于目标导向行为和空间拓扑记忆的视觉导航方法
1、引言
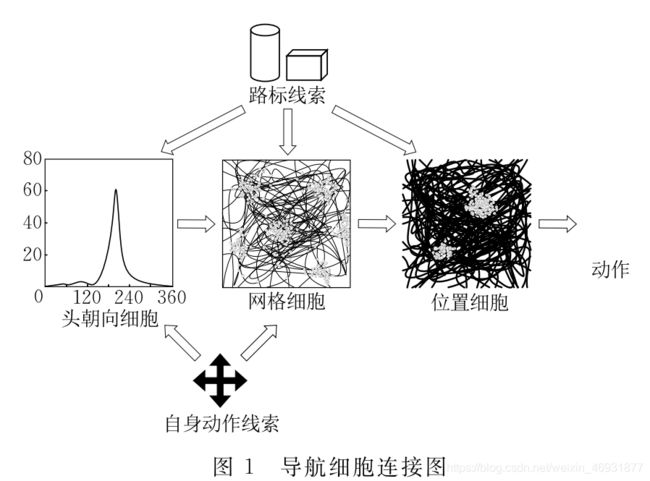
动物,包括人类在内,在空间认知和行动规划方面具有非凡的能力,与其对应的导航行为也在心理学和神经科学中得到广泛研究.1948年, Tolman提出“认知地图(cognitivemap)”概念用于说明物理环境的内在表达,自此,认知地图的存在和形式一直饱受争议.近年来,通过将电极放置在啮齿类动物脑中及研究其电生理记录,位置细胞(placecells),网格细胞(gridcells)和头朝向细胞(Head-Directioncells,HDcells)等多种有关环境编码的细胞得以被人们熟知.在空间认知过程中,每种细胞有其特定功能,它们相互合作完成对状态空间的表达,各类细胞连接如图1所示。此外,还有证据表明海马体内嗅皮层脑区不仅参与空间记忆, 在规划路径中也具有重要作用。
相比之下,移动机器人导航系统通常以同步定
位和建图(SimultaneousLocalizationandMapping,SLAM)为主要实现方式,该类方法可利用传感器数据(例如:激光、里程计、声呐、视觉等)并结合机器人自身运动信息构建未知环境的度量地图以实现自主导航.在众多SLAM方法中,与本文工作最为相近的是视觉SLAM(VisuaISLA,VSLAM)模型, 该方法主要以视觉感知环境信息,并通过摄像机姿态和多视角几何理论构建地图.为提高数据处理速度,一些VSLAM算法会优先提取图像特征点(例如:SIFT、ORB),然后通过匹配特征点完成间估计和闭环检测.基于SLAM的方法可提供高质量环境地图,但此类方法致力于位置推算和地图构建,往往需要额外的姿态或自身运动信息,且对动态环境缺乏适应性。
深度强化学习(Deep Reinforcement Learning,DLR)由深度学习(Deep Learning,DL)和强化学习(Reinforcement Learning,RL)共同组成, 它的出现在一定程度上推动了机器拟人化的发展. 由于其具有端到端的学习框架,深度强化学习也被广泛应用于导航领域,并在高维空间中展现出良好的适应性。将预训练的ResNet与具有Siamese架构的网络模型结合,实现以目标驱动的视觉导航,并在模型中增加目标适应性训练,使智能体对新目标具有更好的泛化能力.但这种方法本质上依赖于纯反应行为,在复杂环境中性能下降明显。提出一种基于策略的异步强化学习方法,并利用该方法训练结合长短时记忆网络(Long Short TermMemory Nrtwork,LSTM)的模型在3D迷宫中学习导航,实验结果表明该模型可存储环境相关信息并获得更加通用的控制策略。]验证多种辅助任务对CNN-LSTM模型的影响,在Atari测试环境中,通过对DQN(DeepQ-Networks,深度Q网络)和UNREALAgent的比较,进一步证明了LSTM的记忆功能.构建一种具有堆叠LSTM架构的模型,在结合深度预测和闭环检测后,智能体学习速度和导航效率显著提高.同时在实验过程中,是否存在LSTM和LSTM层数对导航性能的影响也得到验证.模型中包含通用LSTM的系统可储存大量环境信息,即使是在回合间随机放置目标的3D环境中也能很好地完成导航任务.然而该类方法的控制策略只针对特定环境有效,当通路中出现堵塞或障碍物时,智能体需再次映射该路径,因此有很多研究人员试图通过对空间结构进行编码以更好地应对环境变化.于乃功等人模仿海马结构空间认知机理构建细胞吸引子模型,从而实现构建精确环境认知地图.使用二维记忆图储存环境信息,利用该抽象地图可完成路径规划任务.引入一种新颖的神经导航结构,该方法可从第一人称视角学习环境表征.则通过半参数拓扑记忆(Semi-Parametric Topology Memory,SPTM)构建未知环境的拓扑地图,并使用该地图驱使智能体寻找目标.以编码环境为导航实现方式的算法可通过构建空间类图表征引导目标导向行为,受堵塞和障碍物影响较小,但路径需针对每次任务进行规划,即使在全连通环境下也是如此,这无疑会降低算法的导航效率。
综上所述,深度强化学习为获取控制策略和编码环境结构提供了多种方法,本文在此基础上将两种导航形式结合,提出一种可在学习目标导向行为过程中构建空间拓扑地图的导航方法.其中,目标导向行为由具有深度强化学习架构的智能体在环境中学习所得,而拓扑地图则基于其情景记忆和观测之间的时间距离构建.运动网络是规划模块的补充,它可以帮助智能执行所规划的路径。
2、深度强化学习简介
深度强化学习将深度学习的视觉感知能力与强化学习的行动规划能力融为一体,构建了一种对视觉世界具有更高层次理解的端到端模型.在相关研究中,深度强化学习的基本架构包括DQN和深度递归Q网络(Deep Recursive Q Networks,DRQN)。
2.1、深度Q网络
DQN是第一个被证明可在多种环境中直接通过视觉输入学习控制策略的强化学习算法,其模型如图2所示,输入为智能体观测到的连续4帧图像。

标准强化学习算法假设智能体通过离散时间步与环境进行交互,其目标是学习回合内可最大化奖励的策略.在每一个时间步t,智能体会根据当前状态St和策略Ω选择动作At,在执行动作后获得奖励Rt并进入下一状态St+1,每一个时间步的回报Rt定义为累积折扣奖励:
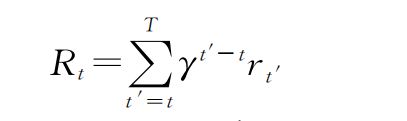
其中,T为回合最大时间步,T′为当前时间步,T为起始时间步,γ∈[0,1]为折扣因子,Rt′为当前时间步所获奖励。DQN通过动作值函数Qπ学习控制策略,Qπ定义为给定策略π和状态S下执行动作a后的期望回报:

其中,St和at为当前时间步状态及动作。在定义Qπ的同时定义最优动作值函数Q*,即Q*(s,a)=maxQπ(s,a)借助贝尔曼方程可迭代更新动作值函数:
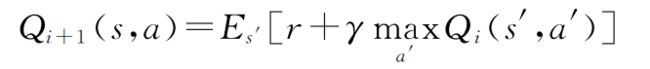
其中,s′和a′为下一时间步状态及动作。当i→∞时,Qi→Q*。DQN使用参数为θ的非线性函数逼近器—卷积神经网络(Convolutional Neural Network,CNNs)—拟合Q值。此时同样可以利用贝尔曼等式更新参数θ,定义均方误差损失函数:

其中,T为当前时间步
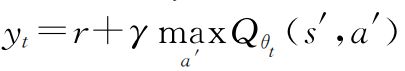
为目标,Qθt(s,a)为当前网络Q值通过微分损失函数可得梯度更新值:

通过在环境中学习不断减小损失函数,使得:
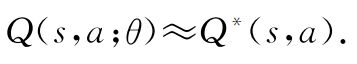
实际上DQN并不是第一个尝试利用神经网络实现强化学习的模型,它的前身是神经拟合Q迭代(Neural Fitting Q-Iteration,NFQ)而DQN性能之所以如此突出,目标网络和经验回放有不可磨灭的贡献。
2.2、深度递归犙网络
DQN已被证明能够在不同ATARI游戏上从原始视觉输入学习人类级别的控制策略,正如它的名字一样,DQN根据状态中每一个可能动作的犙值或回报)选择动作,在犙值估计足够准确的情况下,可通过在每个时间步选择犙值最大的动作获取最优策略.然而,由图2可知,DQN的输入由智能体遇到的4个状态组成,这种从有限状态学习的映射, 本身也是有限的,因此,它无法掌握那些要求玩家记住比过去4个状态更远事件的游戏.当使用DQN在部分可见马尔可夫决策过程(PartiallyObservable Markov Decision Process,POMDP)中学习控制策略时,由于无法结合过去的状态选择最优动作,DQN在POMDP环境中的表现很不稳定.为此, LSTM与DQN结合,提出DRQN模型,其结构如图3所示。

3、综合预训练模型
动作网络和时间相关性网络分别是执行绕路行为和构建拓扑地图的基础,两个网络在模型结构和训练方法上有很多相似之处,且都需要在智能体学习目标导向行为之前完成训练.因此,构建综合预训练模型对两个网络同步进行训练,下面将对两个网络和训练模型进行详细介绍:
3.1、动作网络
动作网络被训练用于选取动作,这些动作可帮助智能体完成导航节点之间的移动,进而实现利用规划路径寻找目标.动作网络以观测对(Oi,Oj)为输入,并以概率P(Oi,Oj)∈R|A|为输出,导航节点之间的动作可根据该概率选取。在以图像作为输入进行预测的方法中,使用最为普遍的是帧间差方法,这是一种作用于像素级别的预测算法,其突出特点是实时性,但该方法始终存在准确率有限和易受干扰两个问题.为提高预测精度及摆脱环境干扰物的影响,使用特征空间代替原始视觉感知作为网络输入.由于动作网络是针对智能体观测之间的动作做出预测,因此可将网络编码的物体分为三类:
(1)可被智能体动作影响的物体;
(2)不受智能体动作影响,但其动作可影响智能体的物体;
(3)与智能体动作完全无关的物体.
注:本文致力于构建一个对(1)和(2)敏感,且不受(3)影响的特征空间,并利用其完成动作预测.
相较人为设计的特征,本文使用深度神经网络(Deep Neural Network,DNN)自动生成特征.动作网络模型如图4所示,它具有端到端架构,在这种架构下特征不会与动作分离,而是在一起相互学习,从
而确保特征不会对任何不能影响或不受智能体动作影响的物体进行编码。
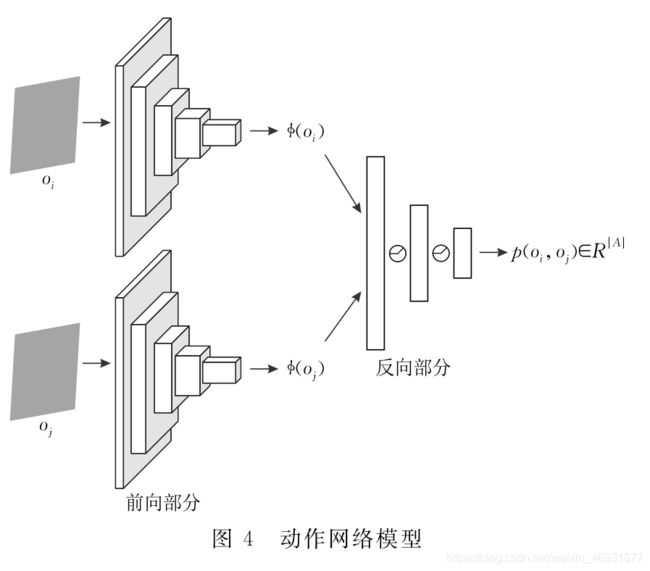
动作网络模型中包含前向和反向两部分,其中,前向部分是基于ResNet-18的深度卷积编码器,可将原始观测(Oi,Oj)编码为特征向量[ф(Oi),ф(Oj)];反向部分则以特征向量作为输入并计算动作概率.
3.2、时间相关性网络
时间相关性网络的目标是通过时间距离寻找情景记忆中的导航节点,这对于避免存储冗余观测和构建拓扑地图至关重要.同时,本文的视觉感知任务(包括智能体定位及目标检测)也由时间相关性网络实现. 在探索过程和随后的目标导向行为中,智能体会多次遍历环境并储存大量情景观测数据.通过阅读有关哺乳动物空间认知方式的研究,了解到哺乳动物可利用一个观测,特别是包含路标的观测,映射一个邻近空间,以此高效认知环境.本文的拓扑地图构建方法也是受此启发,判断观测是否邻近可通过图像特征相似度法实现,但由于智能体视角的多变性,导致该类方法并不能很好地显示观测是否邻近.因此,为降低环境特征对算法性能的影响,舍弃图像相似度方法,采用在情景记忆中得到广泛研究的时间距离判断观测是否邻近.从概念上讲,时间相关性网络可被看成一个分类任务,它给予时间上邻近的观测较高的相似值,而给予时间上远离的观测较低的相似值.由于观测序列的连续性,较短的时间距离必然导致相邻的观测, 且时间距离只与观测之间的步长有关,不受图像特征影响.时间相关性网络模型如图5所示,它包含嵌入和比较两部分:嵌入部分用于抽象化视觉输入
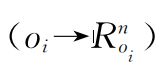
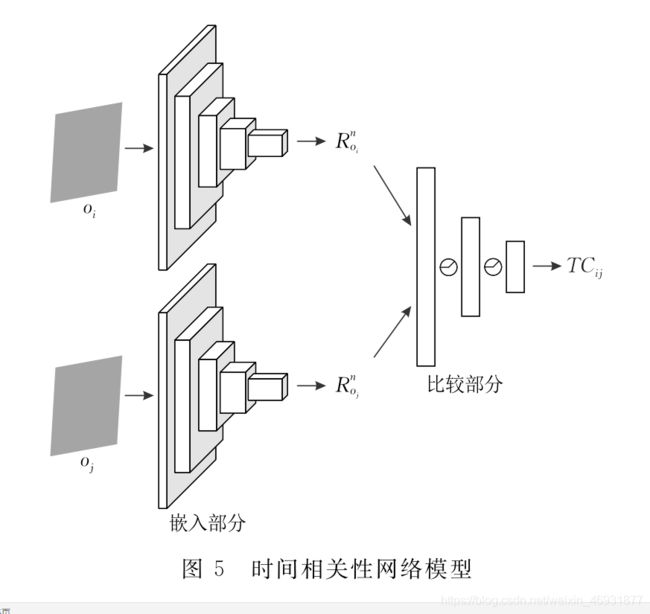
其结构基于ResNet-18;比较部分以特征作为输入并计算时间相关系数:

其中

为Oi和Oj之间的时间相关系数,E(Oi)为观测Oi特征化过程,TC(x,y)用于计算特征间的时间相关系数。
3.3、训练模型
由3.1节和3.2节可知,动作网络和时间相关性网络有很多相似之处.第一,两个网络都使用Siamese架构学习特征和进行预测,其卷积部分全部基于RseNet-18.第二,虽然两个网络所使用的训练样本具有不同的形式,但其原始数据来源于同一随机探索环境的智能体.第三,两个网络都以自监督学习为训练方式,且使用相同训练方法和超参数.最后,对R-network不同部分重要性的研究更是促使我们将两个网络放在同一模型中进行训练.考虑到特征对预测的影响,舍弃时间相关性网络的嵌入部分,保留动作网络的前向部分,并使用动作预测误差构建特征,综合预训练模型如图6所示.

在使用该模型进行训练时,两个网络的损失函数分别计算.其中,动作网络通过监督学习进行训练,并使用交叉熵作为损失函数.训练样本形式为:
![]()
动作ai对应式中第一个观测oi,该样本以情景记忆{o1,o2,·········on}和动作序列{a1,a2,…, an}为原始数据,}为原始数据,并使用K个时间步分割而成.网络训练被定义为学习函数L:
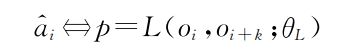
其中,ai^是ai的预测值,P为动作预测概率,oi和oi+k为相隔k个时间步的两个观测,网络参数θL通过式进行优化:
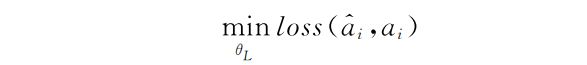
其中,loss用于衡量预测动作与实际动作之间的差异.通过以随机运动的智能体轨迹作为原始训练数据,可习得有效的动作条件分布P(a|oi,oi+k).时间相关性网络的训练样本由两个观测和一个二进制标签组成:〈oi,oi+k,Yik〉数据同样来源于随机探索环境的智能体.如果两个观测值之间至多相隔K个时间步,则认为它们邻近(Yik=1)负样本由两个至少相隔M·K个时间步的观测组成,M用于扩大正负样本间差异.最后,利用逻辑回归作为损失函数并输出邻近概率。
4、导航方法
智能体与新环境的交互分为两个阶段:在第一阶段内,智能体随机探索环境,并使用收集到的数据训练动作网络和时间相关性网络;在第二阶段内,智能体同步学习目标导向行为和构建空间拓扑地图, 并将二者结合用于完成导航任务.
4.1、目标导向行为
目标导向行为可看作智能体在回合内学习最大化奖励策略时的副产物,而具有深度强化学习架构的系统更是在该领域取得了最先进的成果,所以本文模型也以深度强化学习为基本导航框架,并增加额外输入和辅助任务以提升学习效率. 为使智能体更高效地学习目标导向行为,导航框架以DRQN模型为基础,并针对本文任务做出以下调整:
(1)由于导航过程中使用辅助任务提升智能体学习效率,多余的卷积层会增加模型训练难度, 因此将DRQN模型中卷积层由3层减少至2层;
(2)为缓解辅助任务带来的额外计算压力,对训练数据进行降维处理,即将DRQN模型中第一层和第
二层卷积输出的32张和64张特征图分别减少至16张和32张特征图.改进后的导航模型如图7所示,其输入包括:观测ot∈R3×w×h(其中W和H为图像的宽度和高度)、上一时间步动作at-1∈R|a|和奖励Rt-1∈R.同时,使用模型后端分离的线性层计算策略π和值函数V。
在训练方法上,没有直接利用DQN所依赖的动作值函数Q(st,at;θ)和均方误差学习导航,而是使用异步优势Actor- CRITIC (A3C) 算法在给定状态狊狋的情况下学习策略π(at|st;θ)和值函数V(st;θ). 且在整个训练过程中,除仿真环境内可获得的奖励(苹果、目标)外,不增加动作或碰撞惩罚,所用奖励函数如式(9)所示:
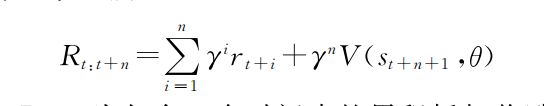
其中,Rt:t+n为包含狀个时间步的累积折扣奖励,狉狋+犻为当前时间步所获奖励,V(st+n+1,θ)为环境终端网络值函数,在损失函数中使用熵正则化处罚代替均方误差:

在训练过程中,多个智能体与多个环境并行交互.尽管后续实验证明该模型可从原始视觉输入中学习目标导向行为,但部分数据显示智能体学习效率与拓扑地图构建速度密切相关.也就是说,导航策略越快趋于稳定,地图就越快覆盖整个空间.因此,为提高智能体学习效率和减少构建地图所需数据量,在模型中结合一个名为碰撞预测的辅助任务,其实现方法如图8所示:
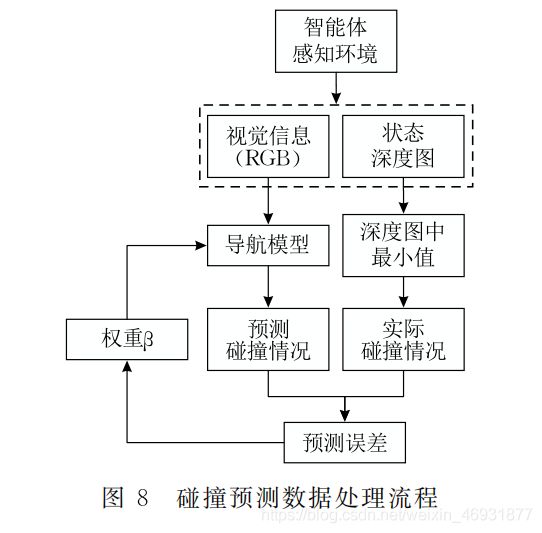
其中,碰撞概率由LSTM后的单层感知器输出,预测误差Lcp通过实际和预测情况比较所得,并结合权重β应用于损失函数:

不难发现,本文模型中使用的辅助任务实际上利用了空间深度信息.但与大多数算法不同,我们没有将深度图直接作为模型输入以寻求更好效果,而是以损失函数的形式呈现环境结构信息,并利用其提供的密集训练信号加速引导学习.此外,碰撞预测为在线(对于当前帧)辅助任务,不依赖任何形式的回放机制.
4.2、空间拓扑记忆
拓扑地图是一种记忆空间结构的方法,文中用导航节点对其进行填充.在每一探索回合结束后, 结合时间相关性网络和智能体观测序列对地图进行更新,从而实现利用情景记忆递增地描述状态空间. 构建拓扑地图包括两个阶段:(1)初始阶段.此时模型内没有任何有关环境的记忆,输入的观测序列将作为智能体对环境的第一认知,因此需简化序列本身.假设智能体在环境中运行犜个时间步得到情景记忆(O1,O2,…,Ot),以首次简化为例,通过时间相关性网络计算序列内第一个观测狅1与其他观测Oi的时间相关系数:

其中,狋犮1为第一次简化的时间相关系数,I=2,3,…,T.根据阈值Tct,省略与o1邻近的观测,简化示意图如图9所示.这是简化的第一次迭代,观测O1将作为第一个导航节点W1储存在拓扑地图中,然后使用随后的观测和同样的方法持续简化序列直到最后一个观测.
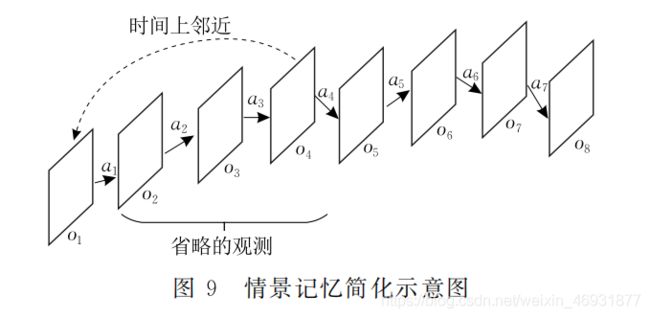
简化过程按情景记忆内观测的先后顺序进行, 所以地图中的导航节点递增储存且在理论上连通. 但在规划路径时,需考虑动作网络的预测能力,因此,使用式检测导航节点是否可达:
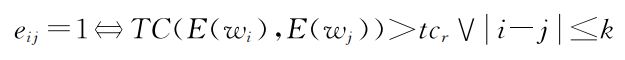
其中,Eij为导航节点间连接关系,Wi和Wj为地图中导航节点,Tcr∈(0.5,Tct)为可达性阈值,i和j为导航节 点脚标,式中包含时间距离和空间关系两种判别方法. 扩张阶段.此时模型中已包含部分环境拓扑地图,智能体需通过集成每个观测序列不断扩充地图.因此,当前情景记忆(O1,O2,…,Ot)c中的每一个观测都需要与地图中的每一个导航节点进行比较以得到它们之间的时间相关系数:

其中,Tcc为当前情景记忆与拓扑地图间的时间相关系数,Oi(i=1,2,…,T)为当前序列中的观测,WX(X=1,2,…,n)为拓扑地图中的导航节点.如果当前情景记忆中的观测全部与拓扑地图邻近,则不需要更新地图.相反,如果在当前序列中的观测,即使只有一个观测不能使用拓扑地图进行映射,那么该观测将作为新的导航节点添加到地图中.此时,需要创建与其对应的连接:
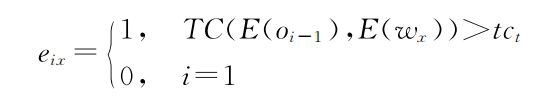
其中,Oi-1为Oi前一时间步的观测,Oi(i∈[2,T])为当前情景记忆中新发现的导航节点,Wx(x∈[1,n])为拓扑地图中的导航节点,Tct为邻近阈值。
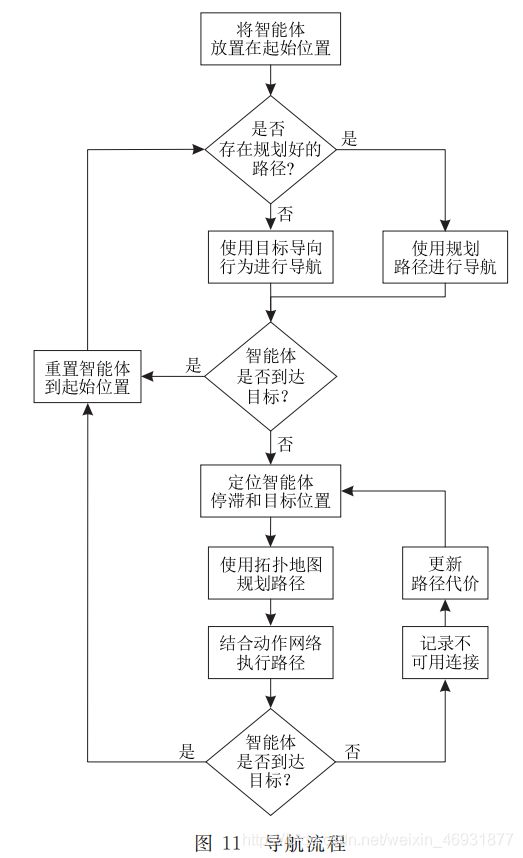
4.3、导航流程
导航任务以回合制进行,每个回合持续固定的时间步或直到找到目标为止.在回合内,智能体起始位置固定,通过目标导向行为或规划的路径完成导航任务.由于控制策略在无障碍环境中获得,因此当不确定环境中是否存在堵塞时,可使用具有目标导向行为的智能体进行试探性导航.如果智能体在一定时间步内到达目标,则证明环境中没有堵塞,导航任务可通过该策略完成.相反,如果智能体在一定时间步内无法接触目标,则证明环境中存在堵塞,单纯的目标导向行为已不再适用,导航任务需结合拓扑地图和路径规划完成. 在重新规划路径之前,需确定智能体停滞和目标所属导航节点,并将它们作为路径的起点和终点. 该视觉感知过程由时间相关性网络实现:对于确认智能体停滞位置,可使用当前观测与拓扑地图内导航节点进行比较,并根据时间相关系数确定智能体所属导航节点;对于目标检测,本文仿真环境中的目标有其固定的形状和颜色,并可在学习目标导向行为中收集获得,利用该类图片和时间相关性网络可定位目标位置.定位方法如图10所示,图中黑色圆形分别代表当前目标和智能体所属导航节点,黑色线段代表堵塞位置.

在得到起始和目标位置后,根据迪杰斯特拉算法寻找导航节点狑犪和狑犵之间的最优路径:
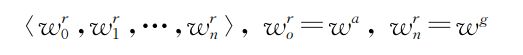
其中,Wa为起始节点,Wg为目标节点.然而从图10可以看出,由于拓扑地图是在全连通环境下构建的, 规划的路径(黑色路径)可能包含跨越堵塞的连接, 而这在实际导航中并不可行.类似的不可用连接应被发现,并避免在接下来的路径规划中使用.因此, 一旦发现智能体长时间停留在一个位置,就证明路径中包含跨越堵塞的连接.此时,应将该连接的路径代价设置为无穷大,并使用修正的拓扑地图重新规划路径.由于导航节点之间相互连接,且环境中的堵塞可能不止一处,所以路径规划是一个迭代调整的过程,整个导航流程如图11所示