【广告技术】如何提升定向广告效果?腾讯广告提出高质量负实例生成新方法
基于CCF-腾讯犀牛鸟基金的平台支持,腾讯广告与清华大学李勇老师团队围绕分布式大规模推荐算法开展了深入的合作研究。双方最新的合作成果入选了信息检索和数据挖掘领域顶级学术会议之一ACM CIKM 2020。论文中,腾讯广告针对定向广告模型面临的数据不平衡问题,提出了一个新型模型,进而提升定向广告效果。
定向广告任务的样本难题
定向广告是当前互联网广告发展的主流形式。近些年,随着机器学习算法和深度神经网络的发展,许多广告公司开发出了一些用于广告自动定向的新工具。这些工具可以基于用户的历史数据学习广告与受众的潜在相关性,然后将他们匹配起来。因此,该任务可以重新表述为这样一个问题:针对每个广告,学习基于相关度对潜在受众进行排名。
针对每个用户,实际的在线系统首先会根据已经学到的广告和用户的相关度分数过滤候选广告,再对它们进行排序,最后将其展示给该用户。
对于每个广告的曝光(impression)数据,广告系统会将每个参与交互的用户标记为正实例,将其他未参与交互的用户标记为负实例。但在实际场景中,绝大多数都是负实例,正实例的数量很少。因此,定向广告模型面临着严重的数据不平衡问题。
已有方案及问题
在负实例上执行随机采样或下采样能在一定程度上缓解数据不平衡问题,但这样就只能用到一部分负实例,也就无法纳入整体负实例集合的部分信息。
为了提升训练过程中的负样本质量,已有研究提出了一些用于推荐系统的高级负实例采样方法,比如会对困难的负实例进行过采样的动态负实例采样。另外,也有研究者使用生成对抗网络(GAN)来生成对抗实例,进而训练出更好的推荐模型,比如IRGAN和KBGAN。
但是,上述模型关注的是商品推荐场景,其中的负实例是基于还未观察到的数据生成的。但在定向广告领域,曝光数据中本就有大量已观察到的负实例了。因此,更重要的问题是基于曝光数据生成代表性负实例(Representative Negative),这是之前还未被研究的课题,其主要难点有两个:
● 曝光数据中的信息有限,难以生成高质量的负实例。
尽管曝光数据中的负实例数量很多,但展示给用户的每个广告都意味着该广告与该用户存在一定的相关性,这会导致信息大量冗余,而且高质量的负实例也不多。
● 由于选择偏倚现象,仅靠曝光数据进行学习是不准确的。
因为在真实广告平台中,曝光数据由当前系统为用户选择最合适的广告后基于用户反馈而生成。这个选择过程不是随机的,也不是均匀的,其中会有选择偏倚。
一套基于生成对抗机制的新方案
在 CIKM 2020(ACM 信息和知识管理会议)论文**《Representative Negative Instance Generation for Online Ad Targeting》**中,清华大学和腾讯广告的研究者提出了一套新方法,可学习在避免选择偏倚的同时生成高质量的负实例。
这是如何做到的呢?
首先,研究者提出了一种名为**代表性负实例生成器(RNIG)**的新型生成器模型,其在生成代表性负实例时会同时使用已观察的曝光数据和未观察的曝光数据,从而可以避免选择偏倚。RNIG 可与定向广告模型搭配使用来获得更好的表现。另外,他们又设计出一种新的特征匹配方案,可基于曝光数据中已观察的负实例学习广告-用户负相关性,再通过匹配重要的特征来生成高质量的负实例。
如下图所示,左侧为新提出的生成器RNIG,右侧则为与之搭配使用的判别器。基于生成对抗机制,生成器(G)的目标是生成判别器(D)难以区分的样本,而判别器的目标则是区分生成样本和真实样本。
 新提出的生成器-判别器框架
新提出的生成器-判别器框架
具体而言,在训练过程中,生成器首先会基于候选负实例集合计算一个概率分布,然后从中采样一个负实例样本作为输出。然后,判别器使用这个生成的负实例样本和已交互的实例作为输入,通过最小化BPR损失(贝叶斯个性化排名损失)来最大化两个输入的分数之差,从而更清楚地分辨它们。接下来,来自判别器的结果会促使生成器生成有代表性的负实例。更优质的负实例能让判别器得到更好的提升,并由此在预测广告-用户相关度上取得更好的表现。
● 代表性负实例生成器(RNIG)
这个框架的判别器部分比较常规,主要的改进在生成器方面。该生成器首先包含一个嵌入层。这是一个全连接层,可将每个输入特征投射成一个密集向量表征。然后再将嵌入集合馈送给编码器,得到广告向量和用户向量。广告和用户编码器是两个相互独立的多层感知器(MLP),其最底层最宽,后面每层的神经元都会少一些。编码层之上则是另一个MLP,用于学习广告向量和用户向量之间的高阶交互,这个MLP的每层大小是恒定的。之后,最后隐藏层的输出向量会被转换成负实例的代表度分数。
● 通过特征匹配生成代表性负实例
这篇论文的另一个贡献是为RNIG模型提出了一种新的匹配方法,即匹配生成的负实例与曝光数据观察得到的负实例的特征分布。生成的负实例会与一个正实例配对,然后输入判别式定向模型D以学习它们的成对的排名关系。
根据RNIG一开始基于曝光数据学习到的概率分布,再进一步衡量隐含特征空间中的相似度。当将生成的负实例发送给判别器D以学习广告-用户相关性之后,该负实例在隐含特征空间中的表征应该根据判别器D的信号来设计。不管判别器D的具体模型结构如何,其最后的预测层都需要计算广告与用户之间的预测相关性分数。
在操作过程中,计算采样的生成负实例集与采样的观察负实例集的特征向量分布之间的最大平均差异(MMD),并以此衡量这两个集合之间的距离。通过最大化这一距离,可以促使生成器生成在隐含特征嵌入方面类似于观察数据的样本。
这样,RNIG就有两个目标了:一是基础的生成负实例的概率分布与曝光数据中的负实例分布的重叠损失;另一个就是上述MMD损失。研究者采用了加权和的方式来整合这两个损失。
最后,研究者还提出了进一步的改进,即计算正实例和观察到的负实例中两个分布之间的Jensen-Shannon散度(JSD),然后选取JSD最大的K个特征作为重要特征集,之后再通过一个掩码操作使得该重要特征集之外的其它特征对负实例生成无影响。这样能避免噪声数据的影响,使得生成的代表性负实例能在最重要和最关键的方面与已观察的负实例类似。
● 实验结果与未来展望
研究者从腾讯广告采集了一个真实数据集并执行了实验,结果如下表所示:
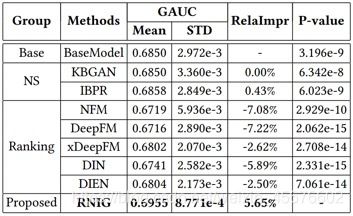
可以看到,基于GAUC和RelaImpr这两项指标,RNIG比之前的其它方法都显著更优。
未来研究者还将继续研究新提出的RNIG模型的普适性,看其是否也适用于其它不同的定向广告场景。
点击链接,参阅有关RNIG的详细介绍和数学描述。
想要了解广告技术相关的前沿观点,可搜索腾讯广告算法大赛公众号,点击主页底部菜单栏 【干货学堂】,进入 【广告技术】 专栏,获取顶会论文的详细解读,掌握更多技术知识。
拓展阅读
【广告技术】用张量分解预测广告库存,广告投放更可靠!
【广告技术】使用图神经网络进行信息聚合与推理,解决多证据事实验证问题
【广告技术】隐私集合交集运算结合同态加密,在保障数据安全的同时追踪广告效果