定时任务框架APScheduler
定时任务框架APScheduler
参考:脑补链接
python 的apschediuler提供了基于日期,固定时间间隔以及crontab类型的任务,可以在主程序运行过程中快速增加新的任务或删除旧任务。为我们构建了专用的调度器或调度服务的基础块
安装:pip install apscheduler
概念:
- 触发器(triggers):调度逻辑,描述一个任务何时被触发,按日期或按时间间隔或按cronjob 表达式三种方式触发。每个作业都有自己的触发器
- 作业存储器(job stores):指定了作业放置的未知,默认保存在内存中,也可以保存在各种数据库中,充当保存,加载,更新,查找作业的中间器。obstore主要是通过pickle库的loads和dumps【实现核心是通过python的__getstate__和__setstate__重写
实现】 - 执行器(executors) :将指定的作业(调用函数)提交到线程池或进程池中运行,任务完成时,执行器通知调度器触发响应的事件。
- 调度器(schedulers):控制,通过它配置存储器,执行器,触发器,添加修改,删除任务。协调其他的运行,通知只有一个调度程序运行。

# 间歇性任务
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler # 调度器模块
def tick(): # 调度的作业
print('Tick! The time is: %s' % datetime.now())
def tick2(): # 调度的作业
print('Tick222! The time is: %s' % datetime.now())
if __name__ == '__main__':
scheduler = BlockingScheduler() # 不带参数表示使用默认的作业存储器内存
# 默认的执行器时线程执行器,最大并发数默认10
scheduler.add_job(tick, 'interval', seconds=3) # 触发器为interval ,间隔3秒运行一次
scheduler.add_job(tick2, 'cron', hour = 15,minute=34) # date按特定的时间点触发,cron按照固定的时间间隔触发
# 在每天的 15:34 触发,可以填写字符串或数字
'''
hour =19 , minute =23
hour ='19', minute ='23'
minute = '*/3' 表示每 3 分钟执行一次
hour ='19-21', minute= '23' 表示 19:23、 20:23、 21:23 各执行一次任务
'''
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C '))
try:
scheduler.start() # 捕捉中断和解释器退出异常
except (KeyboardInterrupt, SystemExit):
pass
触发器
Trigger绑定到Job,在scheduler调度筛选Job时,根据触发器的规则计算出Job的触发时间,然后与当前时间比较
确定此Job是否会被执行,总之就是根据trigger规则计算出下一个执行时间。
Trigger有多种种类,指定时间的DateTrigger,指定间隔时间的IntervalTrigger,像Linux的crontab
一样的CronTrigger
interval
scheduler.add_job(job, 'interval', minutes=1, seconds = 30, start_date='2019-08-29 22:15:00', end_date='2019-08-29 22:17:00', args=['job2'])在 2019-08-29 22:15:00至2019-08-29 22:17:00期间,每隔1分30秒 运行一次 job 方法
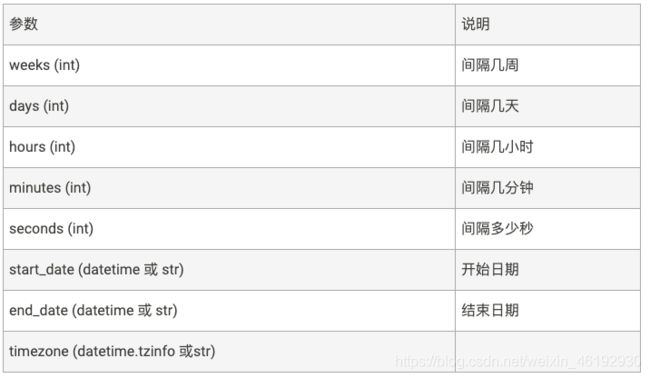
cron 在特定时间周期性地触发。

出来week,day_of_week 默认值都是*

当设置的时间间隔小于,任务的执行时间,线程会阻塞住,等待执行完了才能执行下一个任务,可以设置max_instance指定一个任务同一时刻有多少个实例在运行,默认为1
scheduler.add_job(job, ‘cron’, hour=‘22-23’, minute=‘25’, args=[‘job2’])
在每天22和23点的25分,运行一次 job 方法
配置调度器
调度器的主循环其实就是反复检查是不是有到时需要执行的任务,分以下几步进行:
-
询问自己的每一个作业存储器,有没有到期需要执行的任务,如果有,计算这些作业中每个作业需要运行的时间点,如果时间点有多个,做 coalesce 检查。
-
提交给执行器按时间点运行。
在配置调度器前,我们首先要选取适合我们应用环境场景的调度器,存储器和执行器。下面是各调度器的适用场景:
-
BlockingScheduler:适用于调度程序是进程中唯一运行的进程,调用start函数会阻塞当前线程,不能立即返回。
-
BackgroundScheduler:适用于调度程序在应用程序的后台运行,调用start后主线程不会阻塞。
作业存储器的选择有两种:一是内存,也是默认的配置;二是数据库。具体选哪一种看我们的应用程序在崩溃时是否重启整个应用程序,如果重启整个应用程序,那么作业会被重新添加到调度器中,此时简单的选取内存作为作业存储器即简单又高效。但是,当调度器重启或应用程序崩溃时您需要您的作业从中断时恢复正常运行,那么通常我们选择将作业存储在数据库中,使用哪种数据库通常取决于为在您的编程环境中使用了什么数据库。我们可以自由选择,PostgreSQL 是推荐的选择,因为它具有强大的数据完整性保护。
同样的,执行器的选择也取决于应用场景。通常默认的 ThreadPoolExecutor 已经足够好。如果作业负载涉及CPU 密集型操作,那么应该考虑使用 ProcessPoolExecutor,甚至可以同时使用这两种执行器,将ProcessPoolExecutor 行器添加为二级执行器。
知乎上看的进程和线程的区别:
做个简单的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)
- "互斥锁"进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
链接:https://www.zhihu.com/question/25532384/answer/411179772
apscheduler 提供了许多不同的方法来配置调度器。可以使用字典,也可以使用关键字参数传递。首先实例化调度程序,添加作业,然后配置调度器,获得最大的灵活性。
假如我们想配置更多信息:设置两个执行器、两个作业存储器、调整新作业的默认值,并设置不同的时区。下述三个方法是完全等同的。
配置需求
-
配置名为“mongo”的MongoDBJobStore作业存储器
-
配置名为“default”的SQLAlchemyJobStore(使用SQLite)
-
配置名为“default”的ThreadPoolExecutor,最大线程数为20
-
配置名为“processpool”的ProcessPoolExecutor,最大进程数为5
-
UTC作为调度器的时区
-
coalesce默认情况下关闭
-
作业的默认最大运行实例限制为3
1 from pytz import utc # 时区
2
3 from apscheduler.schedulers.background import BackgroundScheduler # 后台执行
4 from apscheduler.jobstores.mongodb import MongoDBJobStore # 作业存储器
5 from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
6 from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
7
8
9 jobstores = {
10 'mongo': MongoDBJobStore(), # 两个存储器
11 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
12 }
13 executors = {
14 'default': ThreadPoolExecutor(20), # 两个执行器
15 'processpool': ProcessPoolExecutor(5)
16 }
17 job_defaults = {
18 'coalesce': False,
19 'max_instances': 3
20 }
21 scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors,job_defaults=job_defaults, timezone=utc)
# 或者
1 from apscheduler.schedulers.background import BackgroundScheduler
2 scheduler = BackgroundScheduler({
# 字典的形式,你想看吗。。。
3 'apscheduler.jobstores.mongo': {
4 'type': 'mongodb'
5 },
6 'apscheduler.jobstores.default': {
7 'type': 'sqlalchemy',
8 'url': 'sqlite:///jobs.sqlite'
9 },
10 'apscheduler.executors.default': {
11 'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
12 'max_workers': '20'
13 },
14 'apscheduler.executors.processpool': {
15 'type': 'processpool',
16 'max_workers': '5'
17 },
18 'apscheduler.job_defaults.coalesce': 'false',
19 'apscheduler.job_defaults.max_instances': '3',
20 'apscheduler.timezone': 'UTC',
21 })
启动调度器
首先添加作业,一时通过add_job() ,二是通过装饰器。。。。
我们可以随时在调度器上调度作业。如果在添加作业时,调度器还没有启动,那么任务将不会运行,并且第一次运行时间在调度器启动时计算。
注意:如果使用的是序列化作业的执行器或作业存储器,那么要求被调用的作业(函数)必须是全局可访问的,被调用的作业的参数是可序列化的,作业存储器中,只有 MemoryJobStore 不会序列化作业。执行器中,只有ProcessPoolExecutor 将序列化作业。
启用调度器只需要调用调度器的 start() 方法,下面分别使用不同的作业存储器来举例说明:
1 #coding:utf-8
2 from apscheduler.schedulers.blocking import BlockingScheduler
3 import datetime
4 from apscheduler.jobstores.memory import MemoryJobStore
5 from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
6
7 def my_job(id='my_job'):
8 print (id,'-->',datetime.datetime.now())
9 jobstores = {
10 'default': MemoryJobStore()
11
12 }
13 executors = {
14 'default': ThreadPoolExecutor(20),
15 'processpool': ProcessPoolExecutor(10)
16 }
17 job_defaults = {
18 'coalesce': False,
19 'max_instances': 3
20 }
21 scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
22 scheduler.add_job(my_job, args=['job_interval',],id='job_interval',trigger='interval', seconds=5,replace_existing=True) # 5秒一次
23 scheduler.add_job(my_job, args=['job_cron',],id='job_cron',trigger='cron',month='4-8,11-12',hour='7-11', second='*/10',\
24 end_date='2018-05-30') # 10秒一次
25 scheduler.add_job(my_job, args=['job_once_now',],id='job_once_now') # 开始时执行一次
26 scheduler.add_job(my_job, args=['job_date_once',],id='job_date_once',trigger='date',run_date='2018-04-05 07:48:05') # 指定时间执行一次
27 try:
28 scheduler.start()
29 except SystemExit:
30 print('exit')
31 exit()
# 重启程序相当于第一次运行
# 如果使用数据库(我没有)
# 运行一次后,任务会放到数据库中,就是注释了在运行一次,注释掉的任务仍然会运行,程序中断后会自动重新从数据库中读取任务,
# 在添加到调度器中,所以在此运行(不注释)就会有两个相同的任务,这样可以使用 add_jog(replace_existing=True) 解决
# 如果想运行错过的任务,使用
scheduler.add_job(my_job,args = ['job_cron',] ,id='job_cron',trigger='cron',month='4-8,11-12',hour='7-11',second='*/15',
coalesce=True,misfire_grace_time=30,replace_existing=True,end_date='2018-05-30')
说明:misfire_grace_time,假如一个作业本来 08:00 有一次执行,但是由于某种原因没有被调度上,现在 08:01 了,
这个 08:00 的运行实例被提交时,会检查它预订运行的时间和当下时间的差值(这里是1分钟),大于我们设置的 30 秒限制,
那么这个运行实例不会被执行。最常见的情形是 scheduler 被 shutdown 后重启,某个任务会积攒了好几次没执行如 5 次,
下次这个作业被提交给执行器时,执行 5 次。设置 coalesce=True 后,只会执行一次。
其他操作:
1 scheduler.remove_job(job_id,jobstore=None) #删除作业 or job.remove()
2 scheduler.remove_all_jobs(jobstore=None) #删除所有作业
3 scheduler.pause_job(job_id,jobstore=None) #暂停作业
4 scheduler.resume_job(job_id,jobstore=None) #恢复作业
5 scheduler.modify_job(job_id, jobstore=None, **changes) #修改单个作业属性信息
6 scheduler.reschedule_job(job_id, jobstore=None, trigger=None,**trigger_args)#修改单个作业的触发器并更新下次运行时间
7 scheduler.print_jobs(jobstore=None, out=sys.stdout)#输出作业信息
8 scheduler.get_jobs(jobstore=None) # 获取作业
9 print_jobs(jobstore = None,out = sys.stdout) # 打印作业列表,out指定文件对象
10 job.modify(max_instances=6, name='Alternate name') # 修改 允许的并发数
11 scheduler.shutdown(wait=False) # 关闭调度器
调度器事件监听
监听报错
Event是APScheduler在进行某些操作时触发相应的事件,用户可以自定义一些函数来监听这些事件,
当触发某些Event时,做一些具体的操作
常见的比如。Job执行异常事件 EVENT_JOB_ERROR。Job执行时间错过事件 EVENT_JOB_MISSED。
1 # coding:utf-8
2 from apscheduler.schedulers.blocking import BlockingScheduler
3 from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
4 import datetime
5 import logging
6
7 logging.basicConfig(level=logging.INFO, # 配置日志记录,报错在当前目录
8 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
9 datefmt='%Y-%m-%d %H:%M:%S',
10 filename='log1.txt',
11 filemode='a')
12
13
14 def aps_test(x):
15 print (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
16
17
18 def date_test(x):
19 print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
20 print (1/0)
21
22
23 def my_listener(event):
24 if event.exception:
25 print ('任务出错了!!!!!!')
26 else:
27 print ('任务照常运行...')
28
29 scheduler = BlockingScheduler()
30 scheduler.add_job(func=date_test, args=('一次性任务,会出错',), next_run_time=datetime.datetime.now() + datetime.timedelta(seconds=15), id='date_task')
31 scheduler.add_job(func=aps_test, args=('循环任务',), trigger='interval', seconds=3, id='interval_task')
32 scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR) # 监视
33 scheduler._logger = logging # 启动日志模块
34
35 scheduler.start()

谷歌翻译 yyds。。。。。。
构建说明
参考:脑补链接
-
id:指定作业的唯一ID
-
name:指定作业的名字
-
trigger:apscheduler定义的触发器,用于确定Job的执行时间,根据设置的trigger规则,计算得到下次执行此job的
时间, 满足时将会执行 -
executor:apscheduler定义的执行器,job创建时设置执行器的名字,根据字符串你名字到scheduler获取到执行此
job的 执行器,执行job指定的函数 -
max_instances:执行此job的最大实例数,executor执行job时,根据job的id来计算执行次数,根据设置的最大实例数
来确定是否可执行 -
next_run_time:Job下次的执行时间,创建Job时可以指定一个时间[datetime],不指定的话则默认根据trigger获取触
发时间 -
misfire_grace_time:Job的延迟执行时间,例如Job的计划执行时间是21:00:00,但因服务重启或其他原因导致
21:00:31才执行,如果设置此key为40,则该job会继续执行,否则将会丢弃此job -
coalesce:Job是否合并执行,是一个bool值。例如scheduler停止20s后重启启动,而job的触发器设置为5s执行
一次,因此此job错过了4个执行时间,如果设置为是,则会合并到一次执行,否则会逐个执行 -
func:Job执行的函数
-
args:Job执行函数需要的位置参数
-
kwargs:Job执行函数需要的关键字参数

import asyncio
import datetime
from apscheduler.events import EVENT_JOB_EXECUTED
from apscheduler.executors.asyncio import AsyncIOExecutor
from apscheduler.jobstores.redis import RedisJobStore # 需要安装redis
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from apscheduler.triggers.interval import IntervalTrigger
from apscheduler.triggers.cron import CronTrigger
# 定义jobstore 使用redis 存储job信息
default_redis_jobstore = RedisJobStore(
db=2,
jobs_key="apschedulers.default_jobs",
run_times_key="apschedulers.default_run_times",
host="127.0.0.1",
port=6379,
password="test"
)
# 定义executor 使用asyncio是的调度执行规则
first_executor = AsyncIOExecutor() # 自定义的使用异构的调度器吧。。。
# 初始化scheduler时,可以直接指定jobstore和executor
init_scheduler_options = {
"jobstores": {
# first 为 jobstore的名字,在创建Job时直接直接此名字即可
"default": default_redis_jobstore
},
"executors": {
# first 为 executor 的名字,在创建Job时直接直接此名字,执行时则会使用此executor执行
"first": first_executor
},
# 创建job时的默认参数
"job_defaults": {
'coalesce': False, # 是否合并执行
'max_instances': 1 # 最大实例数
}
}
# 创建scheduler
scheduler = AsyncIOScheduler(**init_scheduler_options)
# 启动调度
scheduler.start()
second_redis_jobstore = RedisJobStore(
db=2,
jobs_key="apschedulers.second_jobs",
run_times_key="apschedulers.second_run_times",
host="127.0.0.1",
port=6379,
password="test"
)
scheduler.add_jobstore(second_redis_jobstore, 'second')
# 定义executor 使用asyncio是的调度执行规则
second_executor = AsyncIOExecutor()
scheduler.add_executor(second_executor, "second")
# *********** 关于 APScheduler中有关Event相关使用示例 *************
# 定义函数监听事件
def job_execute(event):
"""
监听事件处理
:param event:
:return:
"""
print(
"job执行job:\ncode => {}\njob.id => {}\njobstore=>{}".format(
event.code,
event.job_id,
event.jobstore
))
# 给EVENT_JOB_EXECUTED[执行完成job事件]添加回调,这里就是每次Job执行完成了我们就输出一些信息
scheduler.add_listener(job_execute, EVENT_JOB_EXECUTED)
# *********** 关于 APScheduler中有关Job使用示例 *************
# 使用的是asyncio,所以job执行的函数可以是一个协程,也可以是一个普通函数,AsyncIOExecutor会根据配置的函数来进行调度,
# 如果是协程则会直接丢入到loop中,如果是普通函数则会启用线程处理
# 我们定义两个函数来看看执行的结果
def interval_func(message):
print("现在时间: {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
print("我是普通函数")
print(message)
async def async_func(message):
print("现在时间: {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
print("我是协程")
print(message)
# 将上述的两个函数按照不同的方式创造触发器来执行
# *********** 关于 APScheduler中有关Trigger使用示例 *************
# 使用Trigger有两种方式,一种是用类创建使用,另一个是使用字符串的方式
# 使用字符串指定别名, scheduler初始化时已将其定义的trigger加载,所以指定字符串可以直接使用
if scheduler.get_job("interval_func_test", "default"):
# 存在的话,先删除
scheduler.remove_job("interval_func_test", "default")
# 立马开始 2分钟后结束, 每10s执行一次 存储到first jobstore second执行
scheduler.add_job(interval_func, "interval",
args=["我是10s执行一次,存放在jobstore default, executor default"],
seconds=10,
id="interval_func_test",
jobstore="default",
executor="default",
start_date=datetime.datetime.now(),
end_date=datetime.datetime.now() + datetime.timedelta(seconds=240))
# 先创建tigger
trigger = IntervalTrigger(seconds=5) # 类对象的方式
if scheduler.get_job("interval_func_test_2", "second"):
# 存在的话,先删除
scheduler.remove_job("interval_func_test_2", "second")
# 每隔5s执行一次
scheduler.add_job(async_func, trigger, args=["我是每隔5s执行一次,存放在jobstore second, executor = second"],
id="interval_func_test_2",
jobstore="second",
executor="second")
# 使用协程的函数执行,且使用cron的方式配置触发器
if scheduler.get_job("cron_func_test", "default"):
# 存在的话,先删除
scheduler.remove_job("cron_func_test", "default")
# 立马开始 每10s执行一次
scheduler.add_job(async_func, "cron",
args=["我是 每分钟 30s 时执行一次,存放在jobstore default, executor default"],
second='30',
id="cron_func_test",
jobstore="default",
executor="default")
# 先创建tigger
trigger = CronTrigger(second='20,40')
if scheduler.get_job("cron_func_test_2", "second"):
# 存在的话,先删除
scheduler.remove_job("cron_func_test_2", "second")
# 每隔5s执行一次
scheduler.add_job(async_func, trigger, args=["我是每分钟 20s 40s时各执行一次,存放在jobstore second, executor = second"],
id="cron_func_test_2",
jobstore="second",
executor="second")
# 使用创建trigger对象直接创建
print("启动: {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
asyncio.get_event_loop().run_forever()