Tell Me Where to Look: Guided Attention Inference Network论文翻译
元学习论文总结||小样本学习论文总结
2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
转载:http://tongtianta.site/paper/852
Tell Me Where to Look: Guided Attention Inference Network
告诉我去哪儿看:引导注意推理网络
Abstract
摘要
Weakly supervised learning with only coarse labels can obtain visual explanations of deep neural network such as attention maps by back-propagating gradients. These attention maps are then available as priors for tasks such as object localization and semantic segmentation. In one common framework we address three shortcomings of previous approaches in modeling such attention maps: We (1) first time make attention maps an explicit and natural component of the end-to-end training, (2) provide self-guidance directly on these maps by exploring supervision form the network itself to improve them, and (3) seamlessly bridge the gap between using weak and extra supervision if available. Despite its simplicity, experiments on the semantic segmentation task demonstrate the effectiveness of our methods. We clearly surpass the state-of-the-art on Pascal VOC 2012 val. and test set. Besides, the proposed framework provides a way not only explaining the focus of the learner but also feeding back with direct guidance towards specific tasks. Under mild assumptions our method can also be understood as a plug-in to existing weakly supervised learners to improve their generalization performance.
只有粗糙标签的弱监督学习可以通过反向传播梯度获得深层神经网络的视觉解释,例如注意力图。这些注意图随后可用作对象本地化和语义分割等任务的先驱。在一个共同的框架中,我们解决了以往方法在建模这样的注意图时存在的三个缺点:我们(1)首次使注意图成为端到端培训的一个明确且自然的组成部分,(2)直接在这些注意图上提供自我指导通过探索网络本身的监督来改进它们;(3)无缝地弥合使用弱监督和额外监督(如果有的话)之间的差距。尽管简单,但语义分割任务的实验证明了我们方法的有效性。我们明显超越了Pascal VOC 2012 val的最新技术水平。和测试集。此外,提出的框架不仅可以解释学习者的焦点,还可以反馈直接指导特定任务。在温和假设下,我们的方法也可以理解为现有弱监督学习者的插件,以提高其泛化性能。
1. Introduction
1.介绍
Weakly supervised learning [3, 26, 33, 35] has recently gained much attention as a popular solution to address labeled data scarcity in computer vision. Using only image level labels for example, one can obtain attention maps for a given input with back-propagation on a Convolutional Neural Network (CNN). These maps relate to the network’s response given specific patterns and tasks it was trained for.The value of each pixel on an attention map reveals to what extent the same pixel on the input image contributes to the final output of the network. It has been shown that one can extract localization and segmentation information from such attention maps without extra labeling effort.
弱监督学习[3,26,33,35]近来备受关注,成为解决计算机视觉中标记数据稀缺问题的流行解决方案。例如,仅使用图像级别标签,可以获得给定输入的注意图,其中在卷积神经网络(CNN)上具有向后传播。这些地图涉及网络的响应,给出了特定的模式和任务。注意图上每个像素的值揭示了输入图像上相同像素对网络最终输出的贡献程度。已经表明,可以从这些注意图中提取本地化和分割信息,而无需额外的标记工作。
However, supervised by only classification loss, atten tion maps often only cover small and most discriminative regions of object of interest [11, 28, 38]. While these attention maps can still serve as reliable priors for tasks like segmentation [12], having attention maps covering the target foreground objects as complete as possible can further boost the performance. To this end, several recent works either rely on combining multiple attention maps from a network via iterative erasing steps [31] or consolidating attention maps from multiple networks [11]. Instead of passively exploiting trained network attention, we envision an end-toend framework with which task-specific supervision can be directly applied on attention maps during training stage.
然而,仅受分类损失的监督,关注地图通常只覆盖感兴趣对象的小型和最具区分性的区域[11,28,38]。虽然这些注意图仍然可以作为分割[12]等任务的可靠先验,但是尽可能完整地包含覆盖目标前景对象的注意图可以进一步提升性能。为此,最近的一些作品要么依靠通过迭代擦除步骤[31]或者从多个网络合并注意力图来合并来自网络的多个注意图[11]。我们设想了一种端到端的框架,可以在训练阶段直接将任务特定的监督应用于注意力图上,而不是被动地利用受过训练的网络注意力。
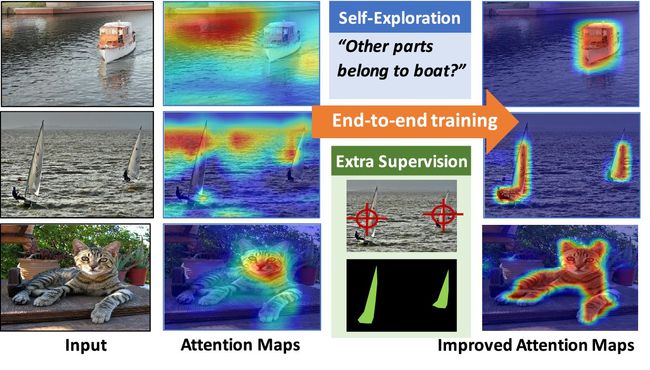
Figure 1. The proposed Guided Attention Inference Network (GAIN) makes the network’s attention on-line trainable and can plug in different kinds of supervision directly on attention maps in an end-to-end way. We explore the self-guided supervision from the network itself and propose GAINext when extra supervision are available. These guidance can optimize attention maps towards the task of interest.
图1.提出的引导注意推理网络(GAIN)使网络的注意力可以在线培训,并且可以直接在端点到端的方式上插入注意力图上的各种监督。我们从网络本身探索自我监督,并在有额外监督时提出GAINext。这些指导可以优化关注地图以完成感兴趣的任务。
On the other hand, as an effective way to explain the network’s decision, attention maps can help to find restrictions of the training network. For instance in an object categorization task with only image-level object class labels, we may encounter a pathological bias in the training data when the foreground object incidentally always correlates with the same background object (also pointed out in [24]). Figure 1 shows the example class ”boat” where there may be bias towards water as a distractor with high correlation. In this case the training has no incentive to focus attention only on the foreground class and generalization performance may suffer when the testing data does not have the same correlation (”boats out of water”). While there have been attempts to remove this bias by re-balancing the training data, we instead propose to model the attention map explicitly as part of the training. As one benefit of this we are able to control the attention explicitly and can put manual effort in providing minimal supervision of attention rather than re-balancing the data set. While it may not always be clear how to manually balance data sets to avoid bias, it is usually straightforward to guide attention to the regions of interest.We also observe that our explicit selfguided attention model already improves the generalization performance even without extra supervision.
另一方面,作为解释网络决策的有效方式,注意图可以帮助找到训练网络的限制。例如,在仅具有图像级对象类标签的对象分类任务中,当前景对象偶然与相同背景对象相关时(也在[24]中指出),我们可能在训练数据中遇到病态偏差。图1显示了示例类“船”,其中可能存在偏向于作为具有高度相关性的牵引器的水。在这种情况下,训练没有动机将注意力集中在前景课堂上,当测试数据没有相同的相关性时(“水上游艇”),泛化性能可能会受到影响。虽然有人试图通过重新平衡训练数据来消除这种偏见,但我们建议将注意图明确地建模为训练的一部分。作为其中一个好处,我们能够明确地控制注意力,并且可以采取人工努力对关注点进行最小限度的监督,而不是重新平衡数据集。虽然可能并不总是清楚如何手动平衡数据集以避免偏差,但引导对感兴趣区域的关注通常很简单。我们还观察到,即使没有额外的监督,我们的显式自引导注意模型已经提高了泛化性能。
Our contributions are: (a) A method of using supervision directly on attention maps during training time while learning a weakly labeled task; (b) A scheme for self-guidance during training that forces the network to focus attention on the object holistically rather than only the most discriminative parts; (c) Integration of direct supervision and selfguidance to seamlessly scale from using only weak labels to using full supervision in one common framework.
我们的贡献是:(a)在培训期间直接在关注地图上使用监督,同时学习弱标记任务的方法; (b)培训期间的自我指导方案,迫使网络将注意力集中在整体而不仅仅是最具有歧视性的部分; (c)将直接监督和自我指导纳入从一个共同框架中只使用薄弱标签到全面监督的无缝扩展。
Experiments using semantic segmentation as task of interest show that our approach achieves mIoU 55.3% and 56.8%, respectively on the val and test of the PASCAL VOC 2012 segmentation benchmark.It also confidently surpasses the comparable state-of-the-art when limited pixellevel supervision is used in training with an mIoU of 60.5% and 62.1% respectively. To the best of our knowledge these are the new state-of-the-art results under weak supervision.
使用语义分割作为感兴趣的任务的实验表明,我们的方法分别在PASCAL VOC 2012分割基准的阈值和测试上达到mIoU 55.3%和56.8%。当有限像素水平的监督分别用于60.5%和62.1%的mIoU训练时,它也自信地超越了可比较的最新水平。就我们所知,这些是在弱监管下的最新的最新成果。
2. Related work
2.相关工作
Since deep neural networks have achieved great success in many areas [7, 34], various methods have been proposed to try to explain this black box [3, 26, 33, 36, 37]. Visual attention is one way that tries to explain which region of the image is responsible for network’s decision. In [26, 29, 33], error backpropagation based methods are used for visualizing relevant regions for a predicted class or the activation of a hidden neuron. In [3], a feedback CNN architecture is proposed for capturing the top-down attention mechanism that can successfully identify task relevant regions. CAM [38] shows that replacing fully-connected layers with an average pooling layer can help generate coarse class activation maps that highlight task relevant regions. Inspired by a top-down human visual attention model, [35] proposes a new backpropagation scheme, called Excitation Backprop, to pass along top-down signals downwards in the network hierarchy. Recently, Grad-CAM [24] extends the CAM to various off-the-shelf available architectures for tasks including image classification, image captioning and VQA providing faithful visual explanations for possible model decisions. Different from all these methods that are trying to explain the network, we first time build up an end-to-end model to provide supervision directly on these explanations, specifically network’s attention here. We validate these supervision can guide the network focus on the regions we expect and benefit the corresponding visual tasks.
由于深层神经网络在很多领域取得了巨大的成功[7,34],因此已经提出了各种方法来试图解释这个黑盒子[3,26,33,36,37]。视觉注意力是试图解释图像的哪个区域负责网络决策的一种方式。在[26,29,33]中,基于误差反向传播的方法用于可视化预测类的相关区域或隐藏神经元的激活。在文献[3]中,提出了一种反馈CNN架构来捕捉自上而下的关注机制,可以成功识别任务相关区域。CAM [38]表明,用平均池层替换完全连接的层可以帮助生成突出任务相关区域的粗糙类激活图。受到自上而下的人类视觉注意模型的启发,[35]提出了一种称为激励反向传播的新反向传播方案,在网络层次中向下传递自上而下的信号。最近,Grad-CAM [24]将CAM扩展到各种现成可用架构,以完成图像分类,图像字幕和VQA等任务,为可能的模型决策提供忠实的视觉解释。与尝试解释网络的所有这些方法不同,我们第一次建立端到端模型来直接对这些解释提供监督,特别是网络的关注。我们验证这些监督可以指导网络侧重于我们所期望的区域,并从中获益于相应的视觉任务。
Many methods heavlily rely on the location information provided by the network’s attention. Learning from only the image-level labels, attention maps of a trained classification network can be used for weakly-supervised object localization [17, 38], anomaly localization, scene segmentation [12] and etc.However, only trained with classification loss, the attention map only covers small and most discriminative regions of the object of interest, which deviates from the requirement of these tasks that needs to localize dense, interior and complete regions. To mitigate this gap,
许多方法依赖于网络关注的位置信息。仅从图像级标签中学习,训练好的分类网络的注意图可以用于弱监督对象定位[17,38],异常定位,场景分割[12]等。然而,只有经过分类损失训练后,注意图才会覆盖感兴趣对象的小型且最具区分性的区域,这偏离了需要对密集,内部和完整区域进行本地化的需求。为了缓解这一差距,
[28] proposes to hide patches in a training image randomly, forcing the network to seek other relevant parts when the most discriminative part is hidden. This approach can be considered as a way to augment the training data, and it has strong assumption on the size of foreground objects (i.e., the object size vs. the size of the patches). In [31], use the attention map of a trained network to erase the moset discriminative regions of the original input image. And the repeat this erase and discover action to the erased image for several steps and combine attention maps of each step to get a more complete attention map. Similarly, [11] uses a twophase learning stratge and combine attention maps of the two networks to get a more complete region for the object of interest. In the first step, a conventional fully convolutional network (FCN) [16] is trained to find the most discriminative parts of an image. Then these most salient parts are used to supresse the feature map of the secound network to force it to focus on the next most important parts. However, these methods either rely on combinations of attention maps of one trained network for different erased steps or attentions of different networks. The single network’s attention still only locates on the most discriminative region. Our proposed GAIN model is fundamentally different from the previous approaches. Since our models can provide supervision directly on network’s attention in an endto-end way, which can not be done by all the other methods [11, 24, 28, 31, 35, 38], we design different kinds of loss functions to guide the network focus on the whole object of interest. Therefore, we do not need to do several times erasing or combine attention maps. The attention of our single trained network is already more complete and improved.
[28]提出随机地将补丁隐藏在训练图像中,迫使网络在隐藏最具判别性的部分时寻找其他相关部分。这种方法可以被认为是增加训练数据的一种方式,并且它对前景对象的大小(即,对象大小与片的大小)有很强的假设。在[31]中,使用训练好的网络的注意图擦除原始输入图像的Moset区分区域。重复这个步骤擦除和发现擦除图像的几个步骤,并结合每个步骤的注意图来获得更完整的注意图。同样,[11]使用双相学习策略,并结合两个网络的注意图来获得感兴趣对象的更完整区域。在第一步中,传统的完全卷积网络(FCN)[16]被训练来找出图像中最具区分性的部分。然后,这些最突出的部分用于超越secound网络的特征映射,以强制它专注于下一个最重要的部分。然而,这些方法要么依赖于一个训练网络的关注图的组合,以用于不同的擦除步骤或不同网络的关注。单一网络的注意力仍然只位于最具有歧视性的地区。我们提出的GAIN模型与以前的方法有根本的不同。由于我们的模型可以通过端到端的方式直接监督网络的注意力,所有其他方法都无法做到这一点[11,24,28,31,35,38],我们设计了不同类型的损失函数来指导网络侧重于整个感兴趣的对象。因此,我们不需要多次擦除或合并注意力图。我们单一的培训网络的关注已经更加完善和改善。
Identifying bias in datasets [30] is another important usage of the network attention. [24] analyses the location of attention maps of a trained model to find out the dataset bias, which helps them to build a better unbiased dataset. However, in practical applications, it is hard remove all the bias of the dataset and time-consuming to build a new dataset. How to garantee the generalization ability of the learned network is still challenging. Different from the existing methods, our model can fundamentally solve this problem by providing supervision directly on network’s attention and guiding the network to focus on the areas critical to the task of interest, therefore is robust to dataset bias.
识别数据集中的偏见[30]是网络关注的另一个重要用途。 [24]分析了经过训练的模型的关注图的位置,以发现数据集偏差,这有助于他们建立一个更好的无偏差数据集。但是,在实际应用中,难以消除数据集的所有偏见,并且耗费时间来构建新的数据集。如何保证学习网络的泛化能力仍然具有挑战性。与现有方法不同,我们的模型可以直接对网络的关注提供监督,并指导网络侧重于感兴趣任务的关键领域,从而从根本上解决这一问题,因此对数据集偏差具有强大的适用性。
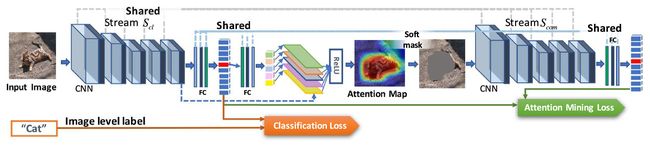
Figure 2. GAIN has two streams of networks, ![]() and
and ![]() , sharing parameters.
, sharing parameters. ![]() aims to find out regions that help to recognize the object and
aims to find out regions that help to recognize the object and ![]() tries to make sure all these regions contributing to this recognition have been discovered. The attention map is on-line generated and trainable by the two loss functions jointly.
tries to make sure all these regions contributing to this recognition have been discovered. The attention map is on-line generated and trainable by the two loss functions jointly.
图2. GAIN有两个网络流,![]() 和
和![]() ,共享参数。
,共享参数。![]() 旨在发现有助于识别物体的区域,
旨在发现有助于识别物体的区域,![]() 试图确保所有这些有助于识别的区域都被发现。注意图在线生成并可通过两种损失函数共同训练。
试图确保所有这些有助于识别的区域都被发现。注意图在线生成并可通过两种损失函数共同训练。
3. Proposed method — GAIN
3.建议的方法 - GAIN
Since attention maps reflect the areas on input image which support the network’s prediction, we propose the guided attention inference networks (GAIN), which aims at supervising attention maps when we train the network for the task of interest. In this way, the network’s prediction is based on the areas which we expect the network to focus on. We achieve this by making the network’s attention trainable in an end-to-end fashion, which hasn’t been considered by any other existing works [11, 24, 28, 31, 35, 38]. In this section, we describe the design of GAIN and its extensions tailored towards tasks of interest.
由于注意映射反映了支持网络预测的输入图像上的区域,因此我们提出了引导注意推理网络(GAIN),其目的是在我们针对感兴趣的任务训练网络时监督注意力图。通过这种方式,网络的预测基于我们期望网络关注的领域。我们通过使网络的注意力以端到端的方式进行培训来实现这一目标,这一点尚未被任何其他现有的作品所考虑[11,24,28,31,35,38]。在本节中,我们将描述GAIN的设计及其针对感兴趣任务的扩展。
3.1. Self-guidance on the network attention
3.1。网络关注的自我指导
As mentioned in Section 2, attention maps of a trained classification network can be used as priors for weaklysupervised semantic segmentation methods. However, purely supervised by the classification loss, attention maps usually only cover small and most discriminative regions of object of interest.These attention maps can serve as reliable priors for segmentation but a more complete attention map can certainly help improving the overall performance.
如第2节所述,经过训练的分类网络的注意图可以用作弱监督语义分割方法的先验。然而,纯粹受到分类损失的监督,注意图通常只覆盖感兴趣对象的小区域和最具区分性的区域。这些关注地图可以作为分割的可靠先验,但更完整的关注地图肯定有助于改善整体表现。
To solve this issue, our GAIN builds constrains directly on the attention map in a regularized bootstrapping fashion. As shown in Figure 2, GAIN has two streams of networks, classification stream  and attention mining
and attention mining 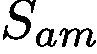 , which share parameters with each other. The constrain from stream
, which share parameters with each other. The constrain from stream  aims to find out regions that help to recognize classes. And the stream
aims to find out regions that help to recognize classes. And the stream 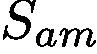 is making sure that all regions which can contribute to the classification decision will be included in the network’s attention. In this way, attention maps become more complete, accurate and tailored for the segmentation task. The key here is that we make the attention map can be on-line generated and trainable by the two loss functions jointly.
is making sure that all regions which can contribute to the classification decision will be included in the network’s attention. In this way, attention maps become more complete, accurate and tailored for the segmentation task. The key here is that we make the attention map can be on-line generated and trainable by the two loss functions jointly.
为了解决这个问题,我们的GAIN以正则化引导方式直接在注意力图上形成约束。如图2所示,GAIN有两个网络流,分类流和注意挖掘,它们彼此共享参数。来自流的约束旨在找出有助于识别类的区域。而流正在确保所有可能有助于分类决策的区域都将纳入网络的关注。通过这种方式,关注地图变得更完整,准确并针对分割任务进行量身定制。这里的关键是我们可以通过两种损失函数联合生成和训练注意图。
Based on the fundemantal framework of Grad-CAM [24], we streamlined the generation of attention map. An attention map corresponding to the input sample can be obtained within each inference so it becomes trainable in training statge. In stream  , for a given image I, let
, for a given image I, let 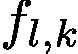 be the activation of unit k in the l-th layer. For each class c from the ground-truth label, we compute the gradient of the score
be the activation of unit k in the l-th layer. For each class c from the ground-truth label, we compute the gradient of the score ![]() corresponding to class c, with respect to activation maps of
corresponding to class c, with respect to activation maps of 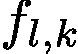 . These gradients flowing back will pass through a global average pooling layer [14] to obtain the neuron importance weights
. These gradients flowing back will pass through a global average pooling layer [14] to obtain the neuron importance weights 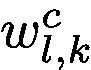 as defined in Eq. 1.
as defined in Eq. 1.
基于Grad-CAM [24]的福特框架,我们简化了注意图的生成。可以在每个推理中获得与输入样本相对应的注意图,从而在训练统计中变得可训练。在流中,对于给定的图像I,让成为第l层中单元k的激活。对于来自地面实况标签的每个类别c,我们计算![]() 对应于类别c的分数的梯度,相对于的激活图。这些反馈的梯度将通过一个全局平均汇聚层[14],以获得如公式(1)中定义的神经元重要性权重。 1。
对应于类别c的分数的梯度,相对于的激活图。这些反馈的梯度将通过一个全局平均汇聚层[14],以获得如公式(1)中定义的神经元重要性权重。 1。
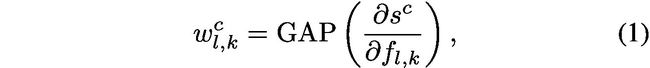
where 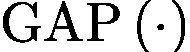 means global average pooling operation.
means global average pooling operation.
意味着全球平均汇集运营。
Here, we do not update parameters of the network after obtaining the  by back-propagation. Since
by back-propagation. Since 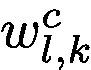 represents the importance of activation map
represents the importance of activation map  supporting the prediction of class c, we then use weights matrix
supporting the prediction of class c, we then use weights matrix  as the kernel and apply 2D convolution over activation maps matrix
as the kernel and apply 2D convolution over activation maps matrix ![]() in order to integrate all activation maps, followed by a ReLU operation to get the attention map
in order to integrate all activation maps, followed by a ReLU operation to get the attention map 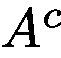 with Eq. 2. The attention map is now on-line trainable and constrains on
with Eq. 2. The attention map is now on-line trainable and constrains on 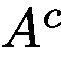 will influence the network’s learning:
will influence the network’s learning:
在这里,我们不通过反向传播获得后更新网络参数。由于代表支持c类预测的激活图的重要性,因此我们使用权重矩阵作为核,并在激活图矩阵![]() 上应用2D卷积以集成所有激活图,然后进行ReLU操作以获得注意图与Eq。 2。注意图现在可以在线培训,的约束将影响网络的学习:
上应用2D卷积以集成所有激活图,然后进行ReLU操作以获得注意图与Eq。 2。注意图现在可以在线培训,的约束将影响网络的学习:
![]()
where l is the representation from the last convolutional layer whose features have the best compromise between high-level semantics and detailed spatial information [26]. The attention map has the same size as the convolutional feature maps (  in the case of VGG [27]).
in the case of VGG [27]).
其中l是来自最后卷积层的表示,其特征具有在高级语义和详细空间信息之间的最佳折衷[26]。注意图具有与卷积特征映射(VGG [27]情况下的)相同的大小)。
We then use the trainable attention map 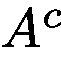 to generate a soft mask to be applied on the original input image, obtaining
to generate a soft mask to be applied on the original input image, obtaining 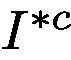 using Eq. 3.
using Eq. 3. 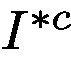 represents the regions beyond the network’s current attention for class c.
represents the regions beyond the network’s current attention for class c.
然后,我们使用可训练注意图生成一个软掩膜应用于原始输入图像,使用方程式获得。 3。表示超出网络当前关注类别c的区域。
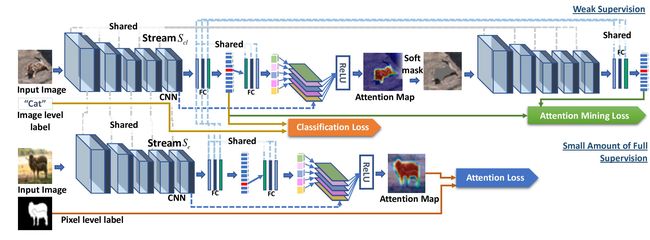
Figure 3. Framework of the GAINext. Pixel-level annotations are seamlessly integrated into the GAIN framework to provide direct supervision on attention maps optimizing towards the task of semantic segmentation.
图3. GAINext的框架。像素级注释无缝集成到GAIN框架中,以提供对关注地图优化的直接监督,以实现语义分割任务。
![]()
where ⊙ denotes element-wise multiplication. 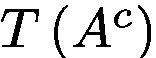 is a masking function based on a thresholding operation. In order to make it derivable, we use Sigmoid function as an approximation defined in Eq. 4.
is a masking function based on a thresholding operation. In order to make it derivable, we use Sigmoid function as an approximation defined in Eq. 4.
其中⊙表示单元乘法。 是基于阈值操作的屏蔽功能。为了使其可导,我们使用Sigmoid函数作为方程中的近似值。 4。
where σ is the threshold matrix whose elements all equal to σ. ω is the scale parameter ensuring  approximately equals to 1 when
approximately equals to 1 when  is larger than σ, or to 0 otherwise.
is larger than σ, or to 0 otherwise.
其中σ是其元素都等于σ的阈值矩阵。 ω是尺度参数,确保当大于σ时大约等于1,否则为0。
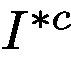 is then used as input of stream
is then used as input of stream 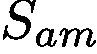 to obtain the class prediction score. Since our goal is to guide the network to focus on all parts of the class of interest, we are enforcing
to obtain the class prediction score. Since our goal is to guide the network to focus on all parts of the class of interest, we are enforcing 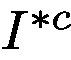 to contain as little feature belonging to the target class as possible, i.e. regions beyond the high-responding area on attention map area should include ideally not a single pixel that can trigger the network to recognize the object of class c. From the loss function perspective it is trying to minimize the prediction score of
to contain as little feature belonging to the target class as possible, i.e. regions beyond the high-responding area on attention map area should include ideally not a single pixel that can trigger the network to recognize the object of class c. From the loss function perspective it is trying to minimize the prediction score of 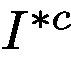 for class c. To achieve this, we design the loss function called Attention Mining Loss as in Eq. 5.
for class c. To achieve this, we design the loss function called Attention Mining Loss as in Eq. 5.
然后将用作流的输入以获得类别预测分数。由于我们的目标是引导网络关注所有感兴趣的类别,我们正在强制尽可能少地包含属于目标类的特征,即注意图区域上的高响应区域之外的区域应该包括理想情况下不是一个可以触发网络识别c类对象的像素。从损失函数的角度来看,它试图最小化对c类的预测分数。为了达到这个目的,我们设计了称为注意采矿损失的损失函数。 5。
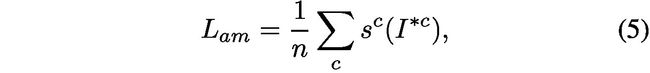
where 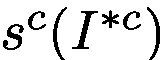 denotes the prediction score of
denotes the prediction score of 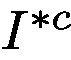 for class c. n is the number of ground-truth class labels for this image I.
for class c. n is the number of ground-truth class labels for this image I.
表示c类的的预测分数。 n是该图像的地面实况类别标签的数量。
的总和。
![]()
where  is for multi-label and multi-class classification and we use a multi-label soft margin loss here. Alternative loss functions can be use for specific tasks. α is the weighting parameter. We use
is for multi-label and multi-class classification and we use a multi-label soft margin loss here. Alternative loss functions can be use for specific tasks. α is the weighting parameter. We use ![]() in all of our experiments.
in all of our experiments.
用于多标签和多类分类,我们在这里使用多标签软边缘损失。替代损失函数可用于特定任务。 α是加权参数。我们在所有的实验中都使用![]() 。
。
With the guidance of  , the network learn to extend the focus area on input image contributing to the recognition of target class as much as possible, such that attention maps are tailored towards the task of interest, i.e. semantic segmentation. We demonstrate the efficacy of GAIN with self guidance in Sec. 4.
, the network learn to extend the focus area on input image contributing to the recognition of target class as much as possible, such that attention maps are tailored towards the task of interest, i.e. semantic segmentation. We demonstrate the efficacy of GAIN with self guidance in Sec. 4.
在的指导下,网络学习扩大输入图像的焦点区域,有助于尽可能识别目标类别,从而使注意图谱适合于感兴趣的任务,即语义分割。我们在第二部分展示了GAIN的自我指导的效用。 4。
3.2. GAINext: integrating extra supervision
3.2。 GAINext:整合额外的监督
In addition to letting networks explore the guidance of the attention map by itself, we can also tell networks which part in the image they should focus on by using a small amount of extra supervision to control the attention map learning process, so that to be tailored for the task of interest. Based on this idea of imposing additional supervision on attention maps, we introduce the extension of GAIN: GAINext, which can seamlessly integrate extra supervision in our weakly supervised learning framework. We demonstrate using the self-guided GAIN framework improving the weakly-supervised semantic segmentation task as shown in Sec. 4. Furthermore, we can also apply GAINext to guide the network to learn features robust to dataset bias and improve its generalizability when the testing data and training data are drawn from very different distributions.
除了让网络自己探索关注地图的指导之外,我们还可以通过使用少量额外的监督来控制注意地图学习过程来告诉网络中他们应该关注的图像的哪些部分,以便定制为感兴趣的任务。基于这种对关注图进行额外监督的想法,我们引入GAIN:GAINext的扩展,它可以在我们的弱监督学习框架中无缝集成额外的监督。我们演示如何使用自导GAIN框架来改进弱监督语义分割任务,如第2节所示。 4。此外,我们还可以应用GAINext指导网络学习对数据集偏差具有鲁棒性的特征,并在测试数据和训练数据来自非常不同的分布时提高其泛化性。
Following Sec. 3.1, we still use the weakly supervised semantic segmentation task as an example application to explain the GAINext. The way to generate trainable attention maps in GAINext during training stage is the same as that in the self-guided GAIN. In addition to  and
and 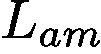 , we design another loss
, we design another loss 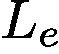 based on the given external supervision. We define
based on the given external supervision. We define 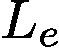 as:
as:
继Sec。 3.1,我们仍然使用弱监督语义分割任务作为示例应用程序来解释GAINext。GAINext在训练阶段生成可训练关注地图的方式与自引导GAIN相同。除了和,我们还根据给定的外部监督设计了另一种损失。我们将定义为:

where 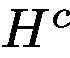 denotes the extra supervision, e.g. pixel-level segmentation masks in our example case.
denotes the extra supervision, e.g. pixel-level segmentation masks in our example case.
表示额外的监督,例如,我们的例子中的像素级分割掩码。
Since generating pixel-level segmentation maps is extremely time consuming, we are more interested in finding out the benefits of using only a very small amount of data with external supervision, which fits perfectly with the GAINext framework shown in Figure 3, where we add an external stream  , and these three streams share all parameters. Input images of stream
, and these three streams share all parameters. Input images of stream  include both image-level labels and pixel-level segmentation masks. One can use only very small amount of pixel-level labels through stream
include both image-level labels and pixel-level segmentation masks. One can use only very small amount of pixel-level labels through stream  to already gain performance improvement with GAINext (in our experiments with GAINext, only 1∼10% of the total labels used in training are pixel-level labels). The input of the stream
to already gain performance improvement with GAINext (in our experiments with GAINext, only 1∼10% of the total labels used in training are pixel-level labels). The input of the stream  includes all the images in the training set with only image-level labels.
includes all the images in the training set with only image-level labels.
由于生成像素级分割图非常耗时,因此我们更感兴趣的是发现只使用非常少量的外部监控数据的好处,这完全符合图3中所示的GAINext框架,我们添加了外部流,并且这三个流共享所有参数。流的输入图像包括图像级标签和像素级分割掩码。通过流,只能使用非常少量的像素级标签,以增加GAINext的性能(在我们用GAINext进行的实验中,训练中使用的总标签中只有1〜10%是像素级标签)。流的输入包括仅具有图像级标签的训练集中的所有图像。
The final loss function, 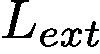 , of GAINext is defined as follows: Lext = Lcl + αLam + ωLe, (8)
, of GAINext is defined as follows: Lext = Lcl + αLam + ωLe, (8)
GAINext的最终损失函数定义如下:Lext = Lcl +αLam+ωLe,(8)
where 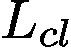 and
and  are defined in Sec. 3.1, and ω is the weighting parameter depending on how much emphasis we want to place on the extra supervision (we use
are defined in Sec. 3.1, and ω is the weighting parameter depending on how much emphasis we want to place on the extra supervision (we use ![]() in our experiments).
in our experiments).
和在第2节中定义。 3.1,而ω是权重参数,取决于我们希望在额外的监督下多加强调(我们在实验中使用![]() )。
)。
GAINext can also be easily modified to fit other tasks. Once we get activation maps  corresponding to the network’s final output, we can use
corresponding to the network’s final output, we can use  to guide the network to focus on areas critical to the task of interest. In Sec. 5, we show an example of such modification to guide the network to learn features robust to dataset bias and improve its generalizability. In that case, extra supervision is in the form of bounding boxes.
to guide the network to focus on areas critical to the task of interest. In Sec. 5, we show an example of such modification to guide the network to learn features robust to dataset bias and improve its generalizability. In that case, extra supervision is in the form of bounding boxes.
GAINext也可以很容易地修改来完成其他任务。一旦我们得到与网络最终输出相对应的激活图,我们就可以使用来指导网络将重点放在对感兴趣任务关键的区域。在第二部分5,我们展示了这种修改的例子,以指导网络学习对数据集偏倚强健的特征并提高其泛化能力。在这种情况下,额外的监督就是边界框的形式。
4. Semantic segmentation experiments
4.语义分割实验
To verify the efficacy of GAIN, following Sec. 3.1 and 3.2, we use the weakly supervised semantic segmentation task as the example application. The goal of this task is to classify each pixel into different categories. In the weakly supervised setting, most of recent methods [11, 12, 31] mainly rely on localization cues generated by models trained with only image-level labels and consider other constraints such as object boundaries to train a segmentation network. Therefore, the quality of localization cues is the key of these methods’ performance.
为了验证GAIN的有效性, 3.1和3.2,我们使用弱监督语义分割任务作为示例应用程序。此任务的目标是将每个像素分为不同的类别。在弱监督环境下,最近的大多数方法[11,12,31]主要依赖于仅由图像级标签训练的模型生成的定位线索,并考虑其他约束(如对象边界)来训练分割网络。因此,定位线索的质量是这些方法表现的关键。
Compared with attention maps generated by the stateof-the-art methods [16, 24, 38] which only locate the most discriminative areas, GAIN guides the network to focus on entire areas representing the class of interest, which can improve the performance of weakly supervised segmentation. To verify this, we adopt our attention maps to SEC [12], which is one of the state-of-the-art weakly supervised semantic segmentation methods. SEC defines three key constrains: seed, expand and constrain, where seed is a module to provide localization cues C to the main segmentation network N such that the segmentation result of N is supervised to match C. Note that SEC is not a dependency of GAIN. It is used here in order to evaluate improvements brought by attention priors produced by GAIN. In principal it can be replaced by other segmentation frameworks for this application. Following SEC [12], our localization cues are obtained by applying a thresholding operation to attention maps generated by GAIN: for each per-class attention map, all pixels with a score larger than 20% of the maximum score are selected. We use [15] to get background cues and then train the SEC model to generate segmentation results using the same inference procedure, as well as parameters of CRF[13].
与最先进的方法[16,24,38]产生的注意力图相比,GAIN只引导网络集中在代表感兴趣等级的整个区域,这可以改善弱的表现监督分割。为了验证这一点,我们将我们的注意力映射到SEC [12],这是最先进的弱监督语义分割方法之一。SEC定义了三个关键约束:种子,扩展和约束,其中种子是为主分割网络N提供定位线索C的模块,使得N的分割结果被监督以匹配C.注意,SEC不是GAIN的依赖性。它在此用于评估由GAIN生产的关注度先进带来的改进。原则上它可以被这个应用程序的其他分割框架所取代。根据SEC [12],我们的定位线索是通过对由GAIN生成的注意图应用阈值操作获得的:对于每个每类注意图,选择具有大于最大分数的20%的分数的所有像素。我们使用[15]获得背景线索,然后训练SEC模型以使用相同的推理过程生成分割结果,以及CRF参数[13]。
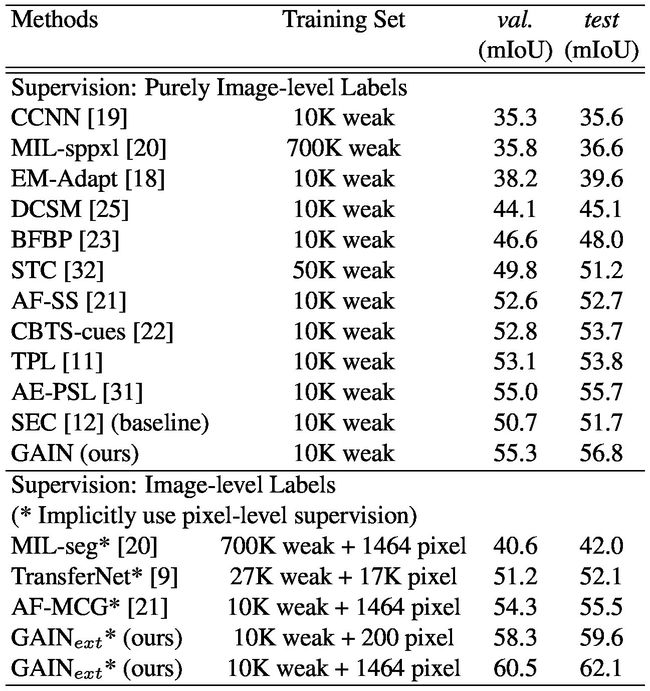
Table 1. Comparison of weakly supervised semantic segmentation methods on VOC 2012 segmentation val. set and segmentation test set. weak denotes image-level labels and pixel denotes pixellevel labels.Implicitly use pixel-level supervision is a protocol we followed as defined in [31], that pixel-level labels are only used in training priors, and only weak labels are used in the training of segmentation framework, e.g. SEC [12] in our case.
表1.比较弱监督的语义分割方法对VOC 2012分段值的影响。集和分割测试集。弱表示图像级标签,像素表示像素级标签。隐式地使用像素级监督是我们遵循的[31]中定义的协议,像素级标签仅用于训练先验,而只有弱标签用于分割框架的训练。 SEC [12]在我们的案例中。
4.1. Dataset and experimental settings
4.1。数据集和实验设置
Dataset and evaluation metrics. We evaluate our results on the PASCAL VOC 2012 image segmentation benchmark [6], which has 21 semantic classes, including the background. The images are split into three sets: training, validation, and testing (denoted as train, val, and test) with 1464, 1449, and 1456 images, respectively. Following the common setting [4, 12], we use the augmented training set provided by [8]. The resulting training set has 10582 weakly annotated images which we use to train our models.We compare our approach with other approaches on both the val and test sets. The ground truth segmentation masks for the test set are not publicly available, so we use the official PASCAL VOC evaluation server to obtain the quantitative results. For the evaluation metric, we use the standard one for the PASCAL VOC 2012 segmentation — mean intersection-over-union (mIoU).
数据集和评估指标。我们在PASCAL VOC 2012图像分割基准[6]上评估我们的结果,其中有21个语义类,包括背景。图像分为三组:训练,验证和测试(分别表示为train,val和test),分别为1464,1449和1456图像。遵循共同设置[4,12],我们使用[8]提供的增强训练集。由此产生的训练集有10582个弱注释图像,我们用它来训练我们的模型。我们将我们的方法与val和测试集上的其他方法进行比较。测试集的地面实况分割掩模并不公开,因此我们使用官方的PASCAL VOC评估服务器来获取定量结果。对于评估指标,我们使用PASCAL VOC 2012分割的标准指标 - 平均相交(mIoU)。
Implementation details. We use the VGG [27] pretrained from the ImageNet [5] as the basic network for GAIN to generate attention maps. We use Pytorch [1] to implement our models. We set the batch size to 1 and learning rate to 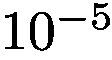 . We use the stochastic gradient descent (SGD) to train the networks and terminate after 35 epochs. For the weakly-supervised segmentation framework, following the setting of SEC [12], we use the DeepLab-CRFLargeFOV [4], which is a slightly modified version of the VGG network [27]. Implemented using Caffe [10], DeepLab-CRFLargeFOV [4] takes the inputs of size 321×321 and produces the segmentation masks of size 41×41. Our training procedure is the same as [12] at this stage. We run the SGD for 8000 iterations with the batch size of 15. The initial learning rate is
. We use the stochastic gradient descent (SGD) to train the networks and terminate after 35 epochs. For the weakly-supervised segmentation framework, following the setting of SEC [12], we use the DeepLab-CRFLargeFOV [4], which is a slightly modified version of the VGG network [27]. Implemented using Caffe [10], DeepLab-CRFLargeFOV [4] takes the inputs of size 321×321 and produces the segmentation masks of size 41×41. Our training procedure is the same as [12] at this stage. We run the SGD for 8000 iterations with the batch size of 15. The initial learning rate is 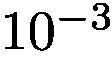 and it decreases by a factor of 10 for every 2000 iterations.
and it decreases by a factor of 10 for every 2000 iterations.
实施细节。我们使用从ImageNet [5]预训练的VGG [25]作为GAIN的基本网络来生成关注图。我们使用Pytorch [1]来实现我们的模型。我们将批量大小设置为1,并将学习速率设置为。我们使用随机梯度下降(SGD)来训练网络,并在35个时期后终止。对于弱监督分割框架,在SEC [12]设置之后,我们使用DeepLab-CRFLargeFOV [4],这是VGG网络的稍微修改版本[27]。用Caffe [10]实现,DeepLab-CRFLargeFOV [4]采用尺寸为321×321的输入,并产生大小为41×41的分割掩模。我们的训练程序与现阶段的[12]相同。我们以批量大小15运行8000次迭代的SGD。初始学习率是,每2000次迭代它就会减少10倍。
4.2. Comparison with state-of-the-art
4.2。与最先进的技术进行比较
We compare our methods with other state-of-the-art weakly supervised semantic segmentation methods with image-level labels. Following [31], we separate them into two categories. For methods purely using image-level labels, we compare our GAIN-based SEC (denoted as GAIN in the table) with SEC [12], AE-PSL [31], TPL [11], STC
我们将我们的方法与其他最先进的弱监督语义分割方法与图像级标签进行比较。在[31]之后,我们将它们分成两类。对于纯粹使用图像级标签的方法,我们将我们的基于GAIN的SEC(在表中表示为GAIN)与SEC [12],AE-PSL [31],TPL [11],STC
[32] and etc. For another group of methods, implicitly using pixel-level supervision means that though these methods train the segmentation networks only with image-level labels, they use some extra technologies that are trained using pixel-level supervision. Our GAINext-based SEC (denoted as GAINext in the table) lies in this setting because it uses a very small amount of pixel-level labels to further improve the network’s attention maps and doesn’t rely on any pixel-level labels when training the SEC segmentation network. Other methods in this setting like AF-MCG [38], TransferNet [9] and MIL-seg [20] are included for comparison. Table 1 shows results on PASCAL VOC 2012 segmentation val. set and segmentation test. set.
[32]等。对于另一组方法,隐式使用像素级监督意味着虽然这些方法仅使用图像级标签训练分割网络,但它们使用一些额外的技术,这些技术是使用像素级监督进行训练的。我们基于GAINext的SEC(在表格中表示为GAINext)位于此设置中,因为它使用非常少量的像素级标签来进一步改善网络的注意力图,并且在训练时不依赖任何像素级标签SEC分割网络。其他包括AF-MCG [38],TransferNet [9]和MIL-seg [20]在内的方法也包括在内以作比较。表1显示了PASCAL VOC 2012分段值的结果。设置和分割测试。组。
Among the methods purely using image-level labels, our GAIN-based SEC achieves the best performance with 55.3% and 56.8% in mIoU on these two sets, outperforming the SEC [12] baseline by 4.6% and 5.1%. Furthermore, GAIN outperforms AE-PSL [31] by 0.3% and 1.1%, and outperforms TPL [11] by 2.2% and 3.0%. These two methods are also proposed to cover more areas of the class of interest in attention maps. However, they either rely on the combinations of attention maps of one trained network for different erasing steps [31] or attention maps from different networks [11].Compared with them, our GAIN makes the attention map trainable and uses  loss to guide attention maps to cover entire class of interest. The design of GAIN already makes the attention map of a single network cover more areas belonging to the class of interest without the need to do iterative erasing or combining attention maps from different networks, as proposed in [11, 31].
loss to guide attention maps to cover entire class of interest. The design of GAIN already makes the attention map of a single network cover more areas belonging to the class of interest without the need to do iterative erasing or combining attention maps from different networks, as proposed in [11, 31].
在纯粹使用图像级标签的方法中,我们的基于GAIN的SEC在这两组中的mIoU上达到最佳性能,其性能优于SEC [12]基准的4.6%和5.1%,达到55.3%和56.8%。此外,增益优于AE-PSL [31] 0.3%和1.1%,优于TPL [11] 2.2%和3.0%。这两种方法也被提出来覆盖关注地图中感兴趣类别的更多区域。然而,它们要么依赖于一个训练网络的注意图组合来进行不同的擦除步骤[31]或者来自不同网络的注意图[11]。与他们相比,我们的GAIN使得注意图可训练并使用损失来指导注意力图以涵盖整个兴趣类别。如[11,31]中提出的,GAIN的设计已经使单个网络的注意图覆盖更多属于感兴趣类别的区域,而不需要执行迭代擦除或结合来自不同网络的注意图。

Figure 4. Qualitive results on Pascal VOC 2012 segmentation val. set. They are generated by SEC (our baseline framework), our GAIN-based SEC and GAINext-based SEC implicitly using 200 randomly selected (2%) extra supervision.
图4. Pascal VOC 2012分段值的质量结果组。它们由SEC(我们的基准框架),我们的基于GAIN的SEC和基于GAINext的SEC隐式地使用200个随机选择的(2%)额外监督而生成。
By implicitly using pixel-level supervision, our GAINext-based SEC achieves 58.3% and 59.6% in mIoU when we use 200 randomly selected images with pixel-level labels (2% data of the whole dataset) as the pixel-level supervision. It already performs 4% and 4.1% better than AF-MCG [38], which relies on the MCG generator [2] trained in a fully-supervised way on the PASCAL VOC. When the pixel-level supervision increases to 1464 images for our GAINext, the performance jumps to 60.5% and 62.1%, which is a new state-of-the-art for this challenging task on a competitive benchmark. Figure 4 shows some qualitative example results of semantic segmentation, indicating that GAIN-based methods help to discover more complete and accurate areas of classes of interest based on the improvement of attention maps. Specifically, GAIN-based methods discover either other parts of objects of interest or new instances which can not be found by the baseline.
通过隐式使用像素级监督,当我们使用200个随机选择的像素级标签(整个数据集的2%数据)作为像素级监督时,基于GAINext的SEC在mIoU中达到58.3%和59.6%。它已经比AF-MCG的性能提高了4%和4.1%[38],它依靠MCG发生器[2],以全监督的方式对PASCAL VOC进行培训。当像素级监控增加到GAINext的1464张图像时,性能跳跃到60.5%和62.1%,这对于具有竞争力的基准测试来说是一项新的挑战性任务。图4显示了语义分割的一些定性实例结果,表明基于GAIN的方法有助于根据关注映射的改进发现更加完整和准确的感兴趣类别区域。具体而言,基于GAIN的方法会发现感兴趣对象的其他部分或基线无法找到的新实例。
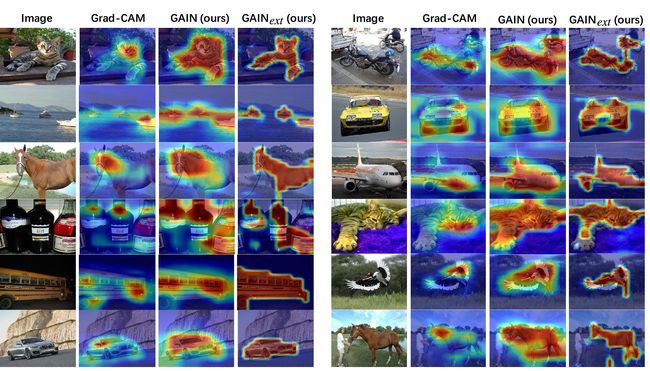
Figure 5. Qualitative results of attention maps generated by Grad-CAM [24], our GAIN and GAINext using 200 randomly selected (2%) extra supervision.
图5. Grad-CAM生成的关注图的定性结果[24],我们的GAIN和GAINext使用200个随机选择的(2%)额外监督。
We also show qualitative results of attention maps generated by GAIN-base methods in Figure 5, where GAIN covers more areas belonging to the class of interest compared with the Grad-CAM [24]. With only 2% of the pixel-level labels, the GAINext covers more complete and accurate areas of the class of interest as well as less background areas around the class of interest (for example, the sea around the ships and the road under the car in the second row of Figure 5).
我们还展示了图5中由GAIN-base方法生成的关注图的定性结果,其中GAIN涵盖了与Grad-CAM相比更多属于感兴趣类的区域[24]。只有2%的像素级标签,GAINext覆盖了感兴趣的类别的更完整和准确的区域以及更少的感兴趣类别周围的背景区域(例如,船只周围的海洋和汽车下方的道路在图5的第二行中)。
More discussion of the GAINext We are interested in finding out the influence of different amount of pixel-level labels on the performance. Following the same setting in Sec. 4.1, we add more randomly selected pixel-level labels to further improve attention maps and adopt them in the SEC [12]. From the results in Table 3, we find that the performance of the GAINext improves when more pixel-level labels are provided to train the network generating attention maps. Again, there are no pixel-level labels used to train the SEC segmentation framework.
GAINext的更多讨论我们感兴趣的是发现不同数量的像素级标签对性能的影响。在第二节中的相同设置之后。 4.1,我们添加更多随机选择的像素级标签,以进一步改善关注图并在SEC中采用它们[12]。从表3的结果中,我们发现当提供更多的像素级标签来训练网络生成注意力图时,GAINext的性能会提高。同样,没有用于训练SEC分割框架的像素级标签。

Table 3. Results on Pascal VOC 2012 segmentation val. set with our GAINext-based SEC implicitly using different amount of pixel-level supervision for the attention map learning process.
表3. Pascal VOC 2012分段值的结果。使用我们的基于GAINext的SEC隐式地使用不同数量的像素级监督来进行注意力映射学习过程。
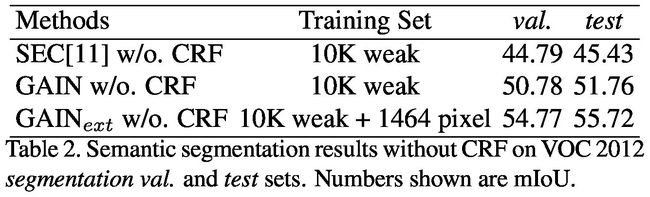
We also evaluate performance on VOC 2012 seg. val. and seg. test datasets without CRF as shown in Table 2.
我们还评估VOC 2012 seg的性能。 VAL。和seg。测试数据集无CRF,如表2所示。
5. Guided learning with biased data
5.有偏向的数据引导学习
In this section, we design two experiments to verify that our methods have potentials to make the classification network robust to dataset bias and improve its generalization ability by providing guidance on its attention.
在本节中,我们设计了两个实验来验证我们的方法有潜力使分类网络对数据集偏倚具有鲁棒性,并通过提供其关注的指导来提高其泛化能力。
Boat experiment. As shown in the Figure 1, the classification network trained on Pascal VOC dataset focuses on sea and water regions instead of boats when predicting there are boats in an image.Therefore, the model failed to learn the right pattern or characteristics to recognize the boats, suffering from the bias in the training set. To verify this, we construct a test dataset, namely “Biased Boat” dataset, containing two categories of images: boat images without sea or water; and sea or water images without boats. We collected 50 images from Internet for each scenario. Then we test the model trained without attention guidance, GAIN and GAINext described in Section 3.2 and 4.2 on this Biased Boat test dataset. Results are reported in Table 4. The models are exactly those trained in Sec 4.2. Some qualitative results are shown in Figure 6.
船实验。如图1所示,在Pascal VOC数据集上训练的分类网络,在预测图像中存在船只时,将重点放在海水和水域,而不是船只。因此,该模型未能学习正确的模式或特征来识别船只,而这些都受到训练集中偏差的影响。为了验证这一点,我们构建了一个测试数据集,即“偏船”数据集,其中包含两类图像:无船或无水的船只图像;和没有船只的海水或水的图像。我们从每个场景收集了来自Internet的50个图像。然后我们测试没有注意引导的训练模型,在3.2节和4.2节中描述的GAIN和GAINext在这个偏航船测试数据集上。结果报告在表4中。这些模型正是在4.2节中训练的那些模型。图6显示了一些定性结果。

Figure 6. Qualitative results generated by Grad-CAM [24], our GAIN and GAINext on our biased boat dataset. All the methods are trained on Pascal VOC 2012 dataset. -# denotes the number of pixel-level labels of boat used in the training which were randomly chosen from VOC 2012. Attention map corresponding to boat shown only when the prediction is positive (i.e. test image contains boat).
图6. Grad-CAM生成的定性结果[24],我们的GAIN和GAINext对我们的偏倚船数据集。所有方法均使用Pascal VOC 2012数据集进行培训。 - #表示从VOC 2012中随机选择的训练中使用的像素级标签的数量。仅当预测为正时(即测试图像包含船)才显示对应于船的注意图。
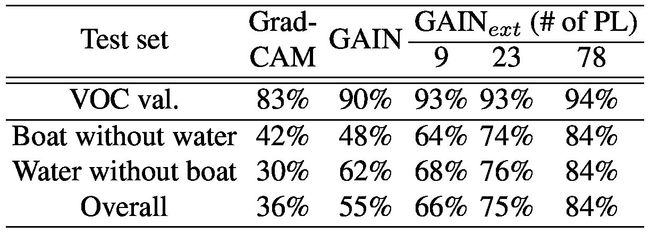
Table 4. Results comparison of Grad-CAM [24] with our GAIN and GAINext tested on our biased boat dataset for classification accuracy. All the methods are trained on Pascal VOC 2012 dataset. PL labels denotes pixel-level labels of boat used in the training which are randomly chosen.
表4. Grad-CAM的结果比较[24]与我们的GAIN和GAINext在我们的有偏差的小船数据集上测试的分类精度。所有方法均使用Pascal VOC 2012数据集进行培训。PL标签表示训练中使用的随机选择的船的像素级标签。
It can be seen that with Grad-CAM [24] training on VOC 2012, the network has trouble predicting whether there is boat in the image in both of the two scenarios with 36% overall accuracy. In particular, it generates positive prediction incorrectly on images with only water 70% of the time, indicating that “water” is considered as one of the most prominent feature characterizing “boat” by the network. Using GAIN with only image-level supervision, the overall accuracy on our boat dataset has been improved to 55%, with significant improvement (32% higher in accuracy, error rate reduced by almost 50% relatively) on the scenario of “water without boat”. This could be attributed to that GAIN is able to teach the learner to capture all relevant parts of the target object, in this case, both the boat itself and the water surrounding it in the image. Hence when there is no boat but water in the image, the network is more likely to generate a negative prediction. However with the help of self-guidance, GAIN is still unable to fully decouple boat from water due to the biased training data, i.e. the learner is unable to move its attention away from the water. That is the reason why only 6% improvement on accuracy is observed in the scenario of “boat without water”.
可以看出,通过对2012年VOC的Grad-CAM [24]培训,网络无法预测两种情况下图像中是否存在船只,整体精度为36%。尤其是,它在70%的时间内只有水分的图像上产生了不正确的预测,表明“水”被认为是网络表征“船”的最显着特征之一。使用GAIN只有图像级别的监督,我们的船只数据集的整体准确性已经提高到55%,在“没有船只的情况下”显着提高(准确性提高32%,错误率相对降低近50%) ”。这可以归因于GAIN能够教导学习者捕获目标对象的所有相关部分,在这种情况下,船只本身以及图像周围的水。因此,当图像中没有船只,但网络更可能产生负面预测。然而,在自我指导的帮助下,由于有偏见的训练数据,GAIN仍然无法将船舶与水完全分离,即学习者无法将注意力从水中移开。这就是为什么在“无水船”的情况下,只有6%的准确性提高。
On the other hand with GAINext training with small amount of pixel-level labels, similar levels of improvements are observed in both of the two scenarios. With only 9 pixel-level labels for “boat”, GAINext obtained an overall accuracy of 66% on our boat dataset, an 11% improvement compared to GAIN with only self-guidance. In particular significant improvement is observed in the scenario of boats without water. With 78 pixel-level labels for “boat” used in training, GAINext is able to obtain 84% of accuracy on our “boat” dataset and performance on both of the two scenarios converged. The reasons behind these results could be that pixel-level labels are able to precisely tell the learner what are the relevant features, components or parts of the target objects hence the actual boats in the image can be decoupled from the water. This again supports that by directly providing extra guidance on attention maps, the negative impact from the bias in training data can be greatly alleviated.
另一方面,用少量像素级标签进行GAINext训练,在两种情况下都观察到类似的改进水平。GAINext只有9个像素级的“船”标签,在我们的船数据集上获得了66%的总体准确度,与只有自引导的GAIN相比,提高了11%。在没有水的船只情况下,观察到特别显着的改善。在培训中使用78个像素级的“船”标签时,GAINext能够在我们的“船”数据集上获得84%的准确性,并且两种情况下的性能都趋于一致。这些结果背后的原因可能是像素级标签能够精确地告诉学习者目标物体的相关特征,组件或部分是什么,因此图像中的实际船只可以与水分离。通过直接提供关于注意图的额外指导,这再次支持了这一点,因此可以大大减轻训练数据中偏倚的负面影响。
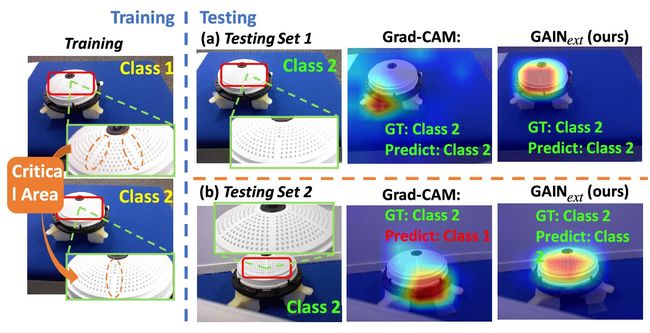
Figure 7. Datasets and qualitative results of our toy experiments. The critical areas are marked with red bounding boxes in each image. GT means ground truth orientation class label.
图7.我们玩具实验的数据集和定性结果。每个图像中的关键区域都标有红色边界框。 GT表示地面真相定位类标签。
Industrial camera experiment. This one is designed for a challenging case to verify the model’s generalization ability. We define two orientation categories for the industrial camera which is highly symmetric in shape. As shown in Figure 7, only features like gaps and small markers on the surface of the camera can be used to effectively distinguish their orientations. We then construct one training set and two test sets. Training Set and Testing Set 1 are sampled from Dt without overlap. Testing Set 2 is acquired with different camera viewpoints and backgrounds. There are 350 images for each orientation category in the Training Set resulting in 700 images in total and 100 images each in Testing Set 1 and Testing Set 2. We train VGG-based Grad-CAM and our GAINext method on Training Set. In training GAINext, manually drawn bounding boxes (20 for each classes taking up only 5% of the whole training data) on critical areas are used as external supervision.
工业相机实验。这是一个具有挑战性的案例来验证模型的泛化能力。我们为高度对称的工业相机定义两种定位类别。如图7所示,只能使用摄像机表面上的间隙和小标记等特征来有效区分其方位。然后我们构造一个训练集和两个测试集。训练集和测试集1从Dt采样而不重叠。测试集2是通过不同的相机视点和背景获取的。训练集中的每个方向类别有350个图像,总共产生700个图像,测试集1和测试集2各有100个图像。我们在训练集上训练基于VGG的Grad-CAM和我们的GAINext方法。在训练GAINext时,在关键区域手动绘制边界框(每个类只占20%,占整个训练数据的5%)被用作外部监督。
At testing stage, though Grad-CAM can correctly classify (very close to 100% accuracy) the images in Testing Set 1 where the camera viewpoint and background are very similar to the training set, it only gets random guess results (close to 50% accuracy) on Testing Set 2 where images are taken from different shooting camera viewpoint with different background. This is due to the fact that there is severe bias in the training dataset and the learner fails to capture the right features (critical area) to separate the two classes. On the contrary, using GAINext with small amount of images with bounding-box labels (5% of the whole training data), the network is able to focus its attention on the area specified by the bounding box labels hence better generalization can be observed when testing with Testing Set 2.Although shooting camera viewpoint and scene background are quite different from the training set, the learner can still correctly identify the critical area on the camera in the image as shown in last column second row in 7, and hence correctly classified all images in both Testing Set 1 and Testing Set 2. The results again suggest that our proposed GAINext has the potential of alleviating the impact of biases in training data, and guiding the learner to generalize better.
在测试阶段,尽管Grad-CAM可以对测试集1中的图像进行正确分类(非常接近100%的准确率),其中相机的视点和背景非常类似于训练集,它只能得到随机猜测结果(接近50%准确性)在测试集2上,其中图像是从不同背景的不同拍摄相机视点拍摄的。这是因为训练数据集中存在严重偏差,学习者未能捕捉到正确的特征(关键区域)来分离两个类别。相反,使用带有边界框标签(占整个训练数据的5%)的少量图像的GAINext,网络能够将其注意力集中在由边界框标签指定的区域上,因此可以观察到更好的泛化使用测试集2进行测试。虽然拍摄相机的视点和场景背景与训练集有很大不同,但学习者仍可以正确识别图像中相机上的关键区域,如7中最后一列第二行所示,因此在两个测试集中正确分类了所有图像1和测试装置2。结果再次表明,我们提出的GAINext有可能缓解偏差在训练数据中的影响,并指导学习者更好地推广。
6. Conclusions
6。结论
We propose a framework that provides direct guidance on the attention map generated by a weakly supervised learning deep neural network in order to teach the network to generate more accurate and complete attention maps. We achieve this by making the attention map not an afterthought, but a first-class citizen during training. Extensive experiments demonstrate that the resulting system confidently outperforms the state of the art without the need for recursive processing during run time. The proposed framework can be used to improve the robustness and generalization performance of networks during training with biased data, as well as the completeness of the attention map for better object localization and segmentation priors. In the future it may be illuminating to deploy our method on other high-level tasks than categorization and to explore for instance how a regression-type task may benefit from better attention.
我们提出了一个框架,该框架为由弱监督学习深度神经网络产生的注意图提供直接指导,以便教导网络产生更准确和完整的注意图。我们通过使注意图不是事后才想到的,而是在培训期间成为一流的公民。大量的实验表明,所得到的系统在运行时不需要递归处理就可以胜过现有技术。所提出的框架可以用来改善在有偏差的数据训练期间网络的鲁棒性和泛化性能,以及用于更好的对象定位和分割先验的关注图的完整性。将来,将我们的方法部署在除分类之外的其他高级别任务中可能更具启发性,并且可以探讨例如回归类型任务如何能够从更好的关注中受益。
7. Acknowledgments
7.致谢
This paper is based primarily on the work done during Kunpeng Li’ s internship at Siemens Corporate Technology. This research is supported in part by the NSF IIS award 1651902, ONR Young Investigator Award N00014-14-10484 and U.S. Army Research Office Award W911NF-171-0367.
本文主要基于在鲲鹏李在西门子企业技术实习期间所做的工作。这项研究部分得到了NSF IIS奖1651902,ONR青年研究者奖N00014-14-10484和美国陆军研究局奖W911NF-171-0367的支持。
References
参考
[1] Pytorch. http://pytorch.org/.
[1] Pytorch。 http://pytorch.org/。
[2] P. Arbel´aez, J. Pont-Tuset, J. T. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In CVPR, 2014.
[2] P. Arbel'aez,J. Pont-Tuset,J. T. Barron,F. Marques和J. Malik。多尺度组合分组。在CVPR,2014年。
[3] C. Cao, X. Liu, Y. Yang, Y. Yu, J. Wang, Z. Wang, Y. Huang, L. Wang, C. Huang, W. Xu, et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In CVPR, 2015.
[3] C. Cao,X. Liu,Y. Yang,Y. Yu,J. Wang,Z. Wang,Y. Huang,L. Wang,C. Huang,W. Xu,et al。思考两次:用反馈卷积神经网络捕捉自上而下的视觉注意力。在CVPR,2015年。
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015.
[4] L.-C. Chen,G.Papandreou,I.Kokkinos,K.Murphy和A.L.Yuille。深卷积网和全连接crfs的语义图像分割。在ICLR,2015。
[5] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
[5] J. Deng,W. Dong,R. Socher,L.-J.李,李,和费菲。 Imagenet:一个大规模的分层图像数据库。在CVPR,2009年。
[6] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. IJCV, 88(2):303–338, 2010.
[6] M. Everingham,L. Van Gool,C. K. Williams,J. Winn和A. Zisserman。 pascal可视对象类(voc)挑战。 IJCV,88(2):303-338,2010。
[7] Y. Gong, S. Karanam, Z. Wu, K.-C. Peng, J. Ernst, and P. C. Doerschuk. Learning compositional visual concepts with mutual consistency. arXiv preprint arXiv:1711.06148, 2017.
[7] Y. Gong,S. Karanam,Z. Wu,K.-C.彭,J.恩斯特和P. C. Doerschuk。学习具有相互一致性的构图视觉概念。 arXiv预印本arXiv:1711.06148,2017。
[8] B. Hariharan, P. Arbel´aez, L. Bourdev, S. Maji, and J. Malik. Semantic contours from inverse detectors. In ICCV, 2011.
[8] B. Hariharan,P. Arbel'aez,L. Bourdev,S. Maji和J. Malik。反向检测器的语义轮廓。在ICCV,2011年。
[9] S. Hong, J. Oh, H. Lee, and B. Han. Learning transferrable knowledge for semantic segmentation with deep convolutional neural network. In CVPR, 2016.
[9] S. Hong,J. Oh,H. Lee和B. Han。用深度卷积神经网络学习可转移语义分词知识。在CVPR,2016。
[10] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In MM. ACM, 2014.
[10] Y. Jia,E. Shelhamer,J. Donahue,S. Karayev,J. Long,R. Girshick,S. Guadarrama和T. Darrell。 Caffe:用于快速特征嵌入的卷积体系结构。在MM中。 ACM,2014。
[11] D. Kim, D. Cho, D. Yoo, and I. So Kweon. Two-phase learning for weakly supervised object localization. In ICCV, 2017.
[11] D. Kim,D. Cho,D. Yoo和I. So Kweon。弱监督对象定位的两阶段学习。在ICCV,2017。
[12] A. Kolesnikov and C. H. Lampert. Seed, expand and constrain: Three principles for weakly-supervised image segmentation. In ECCV, 2016.
[12] A. Kolesnikov和C. H. Lampert。种子,扩大和约束:弱监督图像分割的三个原则。在2016年的ECCV中。
[13] P. Kr¨ahenb¨uhl and V. Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. In NIPS, 2011.
[13] P. Kr?anhenb?uhl和V. Koltun。在高斯边缘电位完全连接的crf中的有效推断。在NIPS,2011年。
[14] M. Lin, Q. Chen, and S. Yan. Network in network. In ICLR, 2014.
[14] M. Lin,Q. Chen和S. Yan。网络中的网络。在ICLR,2014年。
[15] N. Liu and J. Han. Dhsnet: Deep hierarchical saliency network for salient object detection. In CVPR, 2016.
[15] N. Liu和J. Han。 Dhsnet:用于显着物体检测的深层次显着网络。在CVPR,2016。
[16] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431– 3440, 2015.
[16] J. Long,E. Shelhamer和T. Darrell。用于语义分割的完全卷积网络。在CVPR,第3431-3440页,2015年。
[17] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Is object localization for free?-weakly-supervised learning with convolutional neural networks. In CVPR, 2015.
[17] M. Oquab,L.Bottou,I.Laptev和J.Sivic。用卷积神经网络进行免费的 - 弱监督学习的对象本地化。在CVPR,2015年。
[18] G. Papandreou, L.-C. Chen, K. Murphy, and A. L. Yuille. Weakly-and semi-supervised learning of a dcnn for semantic image segmentation. In ICCV, 2015.
[18] G.帕潘德里欧,L.-C. Chen,K. Murphy和A. L. Yuille。用于语义图像分割的dcnn的弱监督学习和半监督学习。在ICCV,2015。
[19] D. Pathak, P. Krahenbuhl, and T. Darrell. Constrained convolutional neural networks for weakly supervised segmentation. In ICCV, 2015.
[19] D. Pathak,P. Krahenbuhl和T. Darrell。弱监督分割的约束卷积神经网络。在ICCV,2015。
[20] P. O. Pinheiro and R. Collobert. From image-level to pixellevel labeling with convolutional networks. In CVPR, 2015.
[20] P. O. Pinheiro和R. Collobert。从图像级到卷积网络的像素级标签。在CVPR,2015年。
[21] X. Qi, Z. Liu, J. Shi, H. Zhao, and J. Jia. Augmented feedback in semantic segmentation under image level supervision. In ECCV, 2016.
[21] X.齐,Z.刘,J.史,赵,和J.贾。图像级监督下的语义分割增强反馈。在2016年的ECCV中。
[22] A. Roy and S. Todorovic. Combining bottom-up, top-down, and smoothness cues for weakly supervised image segmentation. In CVPR, 2017.
[22] A. Roy和S. Todorovic。将自下而上,自顶向下和平滑的线索组合为弱监督图像分割。在CVPR,2017年。
[23] F. Saleh, M. S. A. Akbarian, M. Salzmann, L. Petersson, S. Gould, and J. M. Alvarez. Built-in foreground/background prior for weakly-supervised semantic segmentation. In ECCV, 2016.
[23] F. Saleh,M. S. A. Akbarian,M. Salzmann,L. Petersson,S. Gould和J. M. Alvarez。内置前景/背景之前进行弱监督语义分割。在2016年的ECCV中。
[24] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In ICCV, 2017.
[24] R. R. Selvaraju,M. Cogswell,A. Das,R. Vedantam,D. Parikh和D. Batra。渐变凸轮:通过基于渐变的本地化从深层网络进行视觉解释。在ICCV,2017。
[25] W. Shimoda and K. Yanai. Distinct class-specific saliency maps for weakly supervised semantic segmentation. In ECCV, 2016.
[25] W.下田和K.亚伊。用于弱监督语义分割的不同类特定显着图。在2016年的ECCV中。
[26] K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. In ICLR Workshop, 2014.
[26] K. Simonyan,A. Vedaldi和A. Zisserman。深入卷积网络:可视化图像分类模型和显着图。 2014年在ICLR研讨会上。
[27] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[27] K. Simonyan和A. Zisserman。用于大规模图像识别的非常深的卷积网络。在ICLR,2015。
[28] K. K. Singh and Y. J. Lee. Hide-and-seek: Forcing a network
[28] K. K. Singh和Y. J. Lee。隐藏和寻求:强制网络
to be meticulous for weakly-supervised object and action localization. In ICCV, 2017.
对弱监督对象和行动定位要细致。在ICCV,2017。
[29] J. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller. Striving for simplicity: The all convolutional net. In ICLR Workshop, 2015.
[29] J. Springenberg,A. Dosovitskiy,T. Brox和M. Riedmiller。争取简单:全卷积网。 2015年在ICLR研讨会上。
[30] A. Torralba and A. A. Efros. Unbiased look at dataset bias. In CVPR, 2011.
[30] A. Torralba和A. A. Efros。无偏见的数据集偏差。在CVPR,2011年。
[31] Y. Wei, J. Feng, X. Liang, M.-M. Cheng, Y. Zhao, and S. Yan. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In CVPR, 2017.
[31]魏巍,冯锋,X.梁,M.-M. Cheng,Y. Zhao和S. Yan。有对抗擦除的对象区域挖掘:一种简单的分类到语义分割的方法。在CVPR,2017年。
[32] Y. Wei, X. Liang, Y. Chen, X. Shen, M.-M. Cheng, J. Feng, Y. Zhao, and S. Yan. Stc: A simple to complex framework for weakly-supervised semantic segmentation. IEEE TPAMI, 2017.
[32] Y. Wei,X. Liang,Y. Chen,X. Shen,M.-M. Cheng,J. Feng,Y. Zhao和S. Yan。 Stc:一种简单到复杂的弱监督语义分割框架。 IEEE TPAMI,2017。
[33] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014.
[33] M. D. Zeiler和R. Fergus。可视化和理解卷积网络。在ECCV,2014年。
[34] H. Zhang, V. Sindagi, and V. M. Patel. Image deraining using a conditional generative adversarial network. arXiv:1701.05957, 2017.
[34] H. Zhang,V. Sindagi和V. M. Patel。使用条件生成对抗网络的图像降级。 arXiv:1701.05957,2017。
[35] J. Zhang, Z. Lin, J. Brandt, X. Shen, and S. Sclaroff. Topdown neural attention by excitation backprop. In ECCV, 2016.
[35] J. Zhang,Z. Lin,J. Brandt,X. Shen和S. Sclaroff。激励反向传播的Topdown神经注意力。在2016年的ECCV中。
[36] Z. Zhang, Y. Xie, F. Xing, M. McGough, and L. Yang. Mdnet: A semantically and visually interpretable medical image diagnosis network. In CVPR, 2017.
[36] Z. Zhang,Y. Xie,F. Xing,M. McGough和L. Yang。 Mdnet:语义和视觉可解释的医学图像诊断网络。在CVPR,2017年。
[37] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene cnns. In ICLR, 2014.
[37] B. Zhou,A. Khosla,A. Lapedriza,A. Oliva和A. Torralba。物体探测器出现在深度场景中。在ICLR,2014年。
[38] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In CVPR, 2016.
[38] B. Zhou,A. Khosla,A. Lapedriza,A. Oliva和A. Torralba。学习歧视性本地化的深层特征。在CVPR,2016。