文本分类方法总结
目录
1 机器学习的文本分类方法
1.1 特征工程
1.1.1 文本预处理
1.1.2 文本表示和特征提取
1.1.3 基于语义的文本表示
1.2 分类器
朴素贝叶斯分类(Naïve Bayes)
用朴素贝叶斯分类算法做中文文本分类
KNN
SVM
最大熵
2 深度学习的文本分类方法
2.1 文本的分布式表示:词向量(word embedding)
2.2 深度学习文本分类模型
2.2.1 fastText
2.2.2 TextCNN
2.2.3 TextRNN
2.2.4 TextRNN + Attention
2.2.5 TextRCNN
2.2.6 EntNet/DMN
2.3 总结
Reference
1 机器学习的文本分类方法
文本分类问题算是自然语言处理领域中一个非常经典的问题了,相关研究最早可以追溯到上世纪50年代,当时是通过专家规则(Pattern)进行分类,甚至在80年代初一度发展到利用知识工程建立专家系统,这样做的好处是短平快的解决top问题,但显然天花板非常低,不仅费时费力,覆盖的范围和准确率都非常有限。
后来伴随着统计学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典玩法,这个阶段的主要套路是人工特征工程+浅层分类模型。训练文本分类器过程见下图:
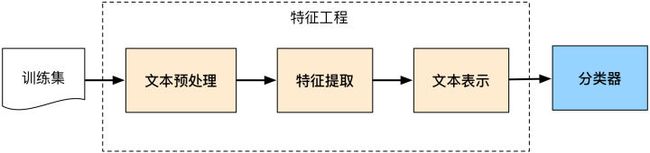
整个文本分类问题就拆分成了特征工程和分类器两部分,玩机器学习的同学对此自然再熟悉不过了
1.1 特征工程
特征工程在机器学习中往往是最耗时耗力的,但却极其的重要。抽象来讲,机器学习问题是把数据转换成信息再提炼到知识的过程,特征是“数据-->信息”的过程,决定了结果的上限,而分类器是“信息-->知识”的过程,则是去逼近这个上限。然而特征工程不同于分类器模型,不具备很强的通用性,往往需要结合对特征任务的理解。
文本分类问题所在的自然语言领域自然也有其特有的特征处理逻辑,传统分本分类任务大部分工作也在此处。文本特征工程分为文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。
1.1.1 文本预处理
文本预处理过程是在文本中提取关键词表示文本的过程,中文文本处理中主要包括文本分词和去停用词两个阶段。
预处理不是本文重点,在此就不具体介绍了。
1.1.2 文本表示和特征提取
文本表示:
文本表示的目的是把文本预处理后的转换成计算机可理解的方式,是决定文本分类质量最重要的部分。传统做法常用词袋模型(BOW, Bag Of Words)或向量空间模型(Vector Space Model),最大的不足是忽略文本上下文关系,每个词之间彼此独立,并且无法表征语义信息。词袋模型的示例如下:
( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0)一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高纬度、高稀疏性。词袋模型是向量空间模型的基础,因此向量空间模型通过特征项选择降低维度,通过特征权重计算增加稠密性。
特征提取:
向量空间模型的文本表示方法的特征提取对应特征项的选择和特征权重计算两部分。特征选择的基本思路是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、χ²统计量等。
特征权重主要是经典的TF-IDF方法及其扩展方法,主要思路是一个词的重要度与在类别内的词频成正比,与所有类别出现的次数成反比。
关于特征选择和特征权重计算可以看这篇博文 NLP --- 文本分类(向量空间模型(Vector Space Model)VSM)
1.1.3 基于语义的文本表示
传统做法在文本表示方面除了向量空间模型,还有基于语义的文本表示方法,比如LDA主题模型、LSI/PLSI概率潜在语义索引等方法,一般认为这些方法得到的文本表示可以认为文档的深层表示,而word embedding文本分布式表示方法则是深度学习方法的重要基础,下文会展现。
1.2 分类器
朴素贝叶斯分类(Naïve Bayes)
用朴素贝叶斯分类算法做中文文本分类
KNN
该算法的基本思想是:根据传统的向量空间模型,文本内容被形式化为特征空间中的加权特征向量。对于一个测试文本,计算它与训练样本集中每个文本的相似度,找出K个最相似的文本,根据加权距离和判断测试文本所属的类别,具体算法步骤如下:
- 对于一个测试文本,根据特征词形成测试文本向量。
- 计算该测试文本与训练集中每个文本的文本相似度,按照文本相似度,在训练文本集中选出与测试文本最相似的k个文本。
- 在测试文本的k个近邻中,依次计算每类的权重。
- 比较类的权重,将文本分到权重最大的那个类别中。
针对海量文本数据的改进方法可见这篇博文:用于大数据分类的KNN算法研究
SVM
基于支持向量机SVM的文本分类的实现
最大熵
2 深度学习的文本分类方法
上文介绍了传统的文本分类做法,传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。而深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。接下来会分别介绍:
2.1 文本的分布式表示:词向量(word embedding)
分布式表示(Distributed Representation)其实Hinton 最早在1986年就提出了,基本思想是将每个词表达成 n 维稠密、连续的实数向量,与之相对的one-hot encoding向量空间只有一个维度是1,其余都是0。分布式表示最大的优点是具备非常powerful的特征表达能力,比如 n 维向量每维 k 个值,可以表征 个概念。事实上,不管是神经网络的隐层,还是多个潜在变量的概率主题模型,都是应用分布式表示。下图是03年Bengio在 A Neural Probabilistic Language Model 的网络结构:
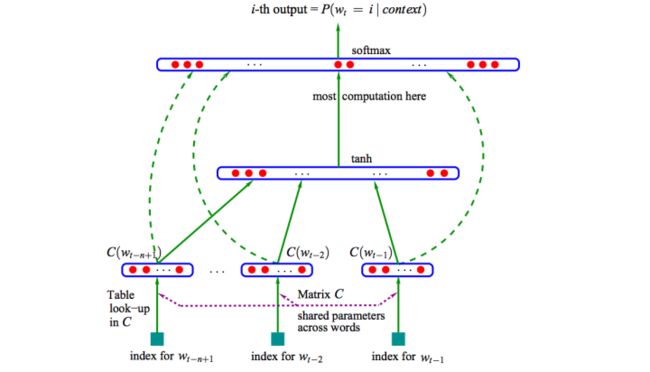
这篇文章提出的神经网络语言模型(NNLM,Neural Probabilistic Language Model)采用的是文本分布式表示,即每个词表示为稠密的实数向量。NNLM模型的目标是构建语言模型:
![]()
词的分布式表示即词向量(word embedding)是训练语言模型的一个附加产物,即图中的Matrix C。
尽管Hinton 86年就提出了词的分布式表示,Bengio 03年便提出了NNLM,词向量真正火起来是google Mikolov 13年发表的两篇word2vec的文章 Efficient Estimation of Word Representations in Vector Space 和 Distributed Representations of Words and Phrases and their Compositionality,更重要的是发布了简单好用的word2vec工具包,在语义维度上得到了很好的验证,极大的推进了文本分析的进程。下图是文中提出的CBOW 和 Skip-Gram两个模型的结构,基本类似于NNLM,不同的是模型去掉了非线性隐层,预测目标不同,CBOW是上下文词预测当前词,Skip-Gram则相反。

除此之外,提出了Hierarchical Softmax 和 Negative Sample两个方法,很好的解决了计算有效性,事实上这两个方法都没有严格的理论证明,有些trick之处,非常的实用主义。详细的过程不再阐述了,有兴趣深入理解word2vec的,推荐读读这篇很不错的paper:word2vec Parameter Learning Explained。额外多提一点,实际上word2vec学习的向量和真正语义还有差距,更多学到的是具备相似上下文的词,比如“good”“bad”相似度也很高,反而是文本分类任务输入有监督的语义能够学到更好的语义表示,有机会后续系统分享下。
至此,文本的表示通过词向量的表示方式,把文本数据从高纬度高稀疏的神经网络难处理的方式,变成了类似图像、语音的的连续稠密数据。深度学习算法本身有很强的数据迁移性,很多之前在图像领域很适用的深度学习算法比如CNN等也可以很好的迁移到文本领域了,下一小节具体阐述下文本分类领域深度学习的方法。
2.2 深度学习文本分类模型
词向量解决了文本表示的问题,该部分介绍的文本分类模型则是利用CNN/RNN等深度学习网络及其变体解决自动特征提取(即特征表达)的问题。
2.2.1 fastText
fastText 是上文提到的 word2vec 作者 Mikolov 转战 Facebook 后16年7月刚发表的一篇论文 Bag of Tricks for Efficient Text Classification。把 fastText 放在此处并非因为它是文本分类的主流做法,而是它极致简单,速度快,模型图见下:
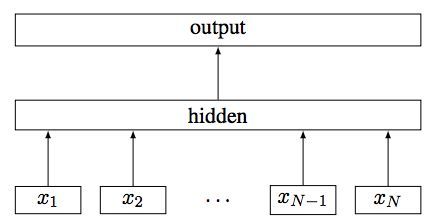
具体结构参考这篇文章 fastText原理及实践
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
2.2.2 TextCNN
本篇文章的题图选用的就是14年这篇文章提出的TextCNN的结构(见下图)。fastText 中的网络结果是完全没有考虑词序信息的,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,CNN原理就不讲了,核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
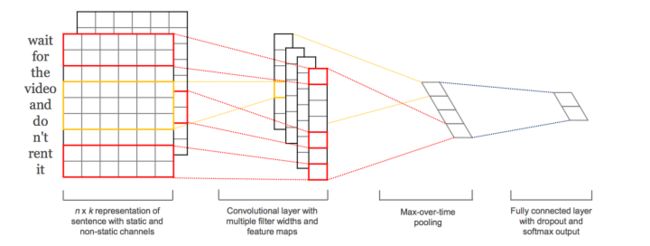
TextCNN的详细过程原理图见下:
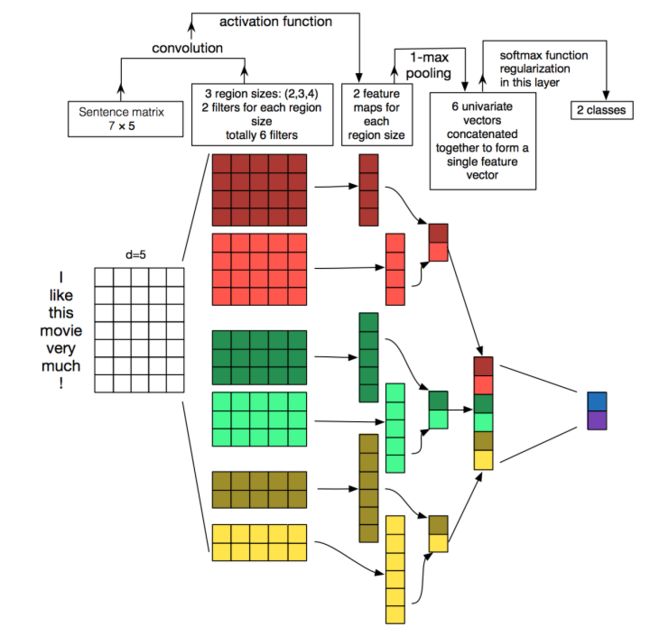
2.2.3 TextRNN
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。具体在文本分类任务中,Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 "n-gram" 信息。
RNN算是在自然语言处理领域非常一个标配网络了,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介绍了RNN用于分类问题的设计,下面介绍两种structure。
1)structure 1
流程:embedding--->BiLSTM--->concat final output/average all output----->softmax layer
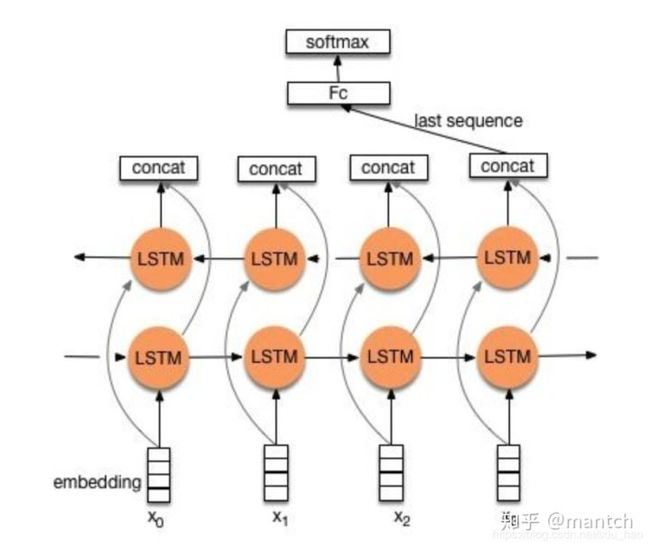
2)structure 2
流程:embedding-->BiLSTM---->(dropout)-->concat ouput--->UniLSTM--->(droput)-->softmax layer
结构图如下图所示:
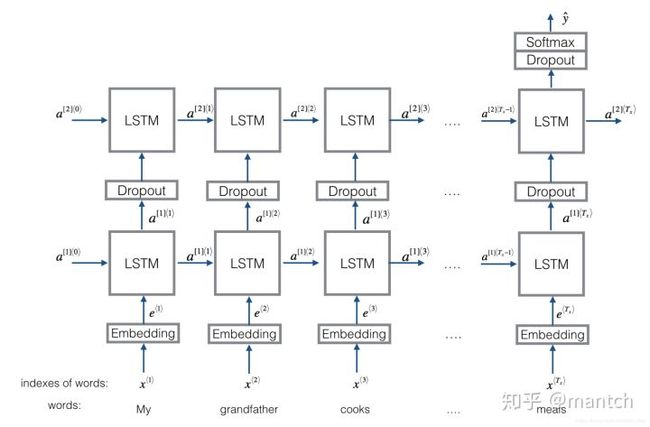
与之前结构不同的是,在双向LSTM(上图不太准确,底层应该是一个双向LSTM)的基础上又堆叠了一个单向的LSTM。把双向LSTM在每一个时间步长上的两个隐藏状态进行拼接,作为上层单向LSTM每一个时间步长上的一个输入,最后取上层单向LSTM最后一个时间步长上的隐藏状态,再经过一个softmax层(输出层使用softamx激活函数,2分类的话则使用sigmoid)进行一个多分类。
2.2.4 TextRNN + Attention
CNN和RNN用在文本分类任务中尽管效果显著,但都有一个不足的地方就是不够直观,可解释性不好,特别是在分析badcase时候感受尤其深刻。而注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来,研究了下学术界果然有类似做法。
这其中比较典型的就是HAN,具体可以见这篇文章HAN(Hierarchical Attention Network)
2.2.5 TextRCNN
我们参考的是中科院15年发表在AAAI上的这篇文章 Recurrent Convolutional Neural Networks for Text Classification 的结构:
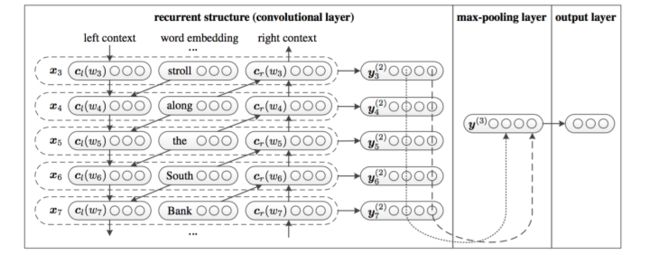

2.2.6 EntNet/DMN
对这两个网络没有研究过,具体参考这篇文章 基于深度学习的文本分类
2.2.7 Bert
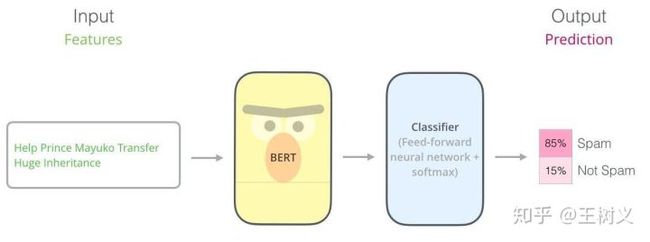
Ber的结构讲解有很多,大家可自行搜索。
2.2.8 DPCNN
DPCNN可参考这篇文章DPCNN深度金字塔卷积神经网络介绍
2.3 总结
文本分类在深度学习的时代逃过了特征提取类似距离的定义的过程, 但是依然逃不了模型的选择, 参数的优化,编码和预处理的考量(one-hot, n-gram等等) ,以及时间的平衡。
概况说来,主要有5大类模型:
- 词嵌入向量化:word2vec, FastText等等
- 卷积神经网络特征提取:Text-CNN, Char-CNN等等
- 上下文机制:Text-RNN, BiRNN, RCNN等等
- 记忆存储机制:EntNet, DMN等等
- 注意力机制:HAN等等
最后再推荐下Github上关于文本分类的总结,讲的非常全面:https://github.com/brightmart/text_classification
Reference
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
用于大数据分类的KNN算法研究
fastText原理及实践
textRNN & textCNN的网络结构与代码实现!
基于深度学习的文本分类