《Python数据挖掘入门与实践》第一章第五节(1.5)中关于分类问题提到了一种简单实用的分类算法——OneR算法。
其实现方式多少有点麻烦,本人不才,用Pandas库用对其代码进行了优化,这里介绍了两者优化的方式。
(什么是OneR算法?戳这里http://blog.csdn.net/baidu_25555389/article/details/73379036)
本次所有代码的运行环境均为Anoconda的jupyter notebook。
方法一,在作者思路上进行优化
作者的思路是首先创建一个函数,给定这个函数数据集,特征类,特征值,即可计算出这个特征值所对应因变量类别出现的次数,并进行错误率或者准确率计算。
这里用的数据是经典的“鸢尾花”数据,其数据可以直接再scikit-learn库中进行导入。特征主要有四个:'萼片长度','萼片宽度', '花瓣长度', '花瓣宽度'。
因变量y有三个类别分别为'山鸢尾','变色鸢尾','维吉尼亚鸢尾'
每个特征值均为连续变量,首先将其以均值为分解点,将每个特征划分为两类(高低两类)。
1、导入数据
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# 导入数据
dataset = load_iris()
x = dataset.data
y = dataset.target
# 导入pd的dataframe
df = pd.DataFrame(x,columns=['x%s'% str(i+1) for i in range(4)])
df['y'] = pd.Series(y)
df.head()
df.describe().round(3)
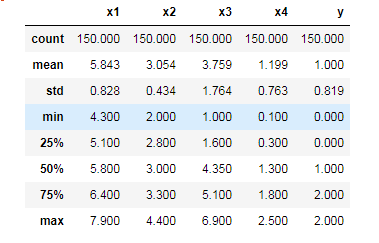
数据基本内容.png
2、将特征值离散化
# 以均值对每个特征进行区分,遍历每个值与均值做个减法
df = df.assign(sl=lambda x : x.x1 - x.x1.mean())
df = df.assign(sw=lambda x : x.x2 - x.x2.mean())
df = df.assign(pl=lambda x : x.x3 - x.x3.mean())
df = df.assign(pw=lambda x : x.x4 - x.x4.mean())
# 将每个自变量的值与0进行比较
df2 = df.iloc[:,5:].round(3) > 0
df2['y'] = pd.Series(y)
# 将大于0的True设置为1,将小于0的Fales设置为0
dict_map = {
False:0,
True:1
}
# 遍历每一列用map方法进行转换
for i in range(4):
df2.iloc[:,i] = df2.iloc[:,i].map(dict_map)
df2.head()
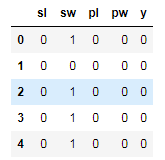
离散化后的数据
其中sl,sw,pl,pw分别代表离散处理后的'萼片长度','萼片宽度', '花瓣长度', '花瓣宽度'。
3、将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
X, y = df2.iloc[:,:4],df.iloc[:,4].values
X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size = 0.25, random_state = 0)
4、定义类别统计函数
# 自定义一个函数,统计具有给定特征值的个体在各个类别中出现的次数,并以datafranme的形式返回。
def train_feature_value(X, y, feature_index, feature_val):
# 给index和columns定义基础值
feature = {
0 : '萼片长',
1 : '萼片宽',
2 : '花瓣长',
3 : '花瓣宽',
}
values = {
0 : ' -- 低',
1 : ' -- 高',
}
# 设置初始dataframe
df_error = pd.DataFrame(np.zeros((1,3)),
index=[feature[feature_index]+values[feature_val]],
columns=['山鸢尾','变色鸢尾','维吉尼亚鸢尾'])
# 遍历,寻找,增加
for sample, i in zip(X.iterrows(),y):
if sample[1][feature_index] == feature_val:
df_error.iloc[0,i] += 1
return df_error
4、遍历所有特征并计算
frames = []
for i in range(4):
for j in range(2):
df_error = train_feature_value(X_train,y_train,i,j)
frames.append(df_error)
# 将所有的datafram合并
result = pd.concat(frames)
result
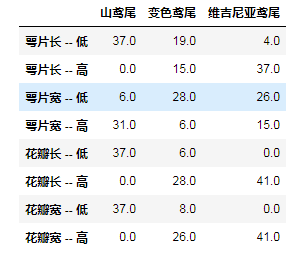
各个特征值所对应的类别数量
5、遍历每个特征,并计算所对应每个类别的准确率
for i in range(len(result)):
result.iloc[i] = result.iloc[i]/result_sum[i]
result.round(3)
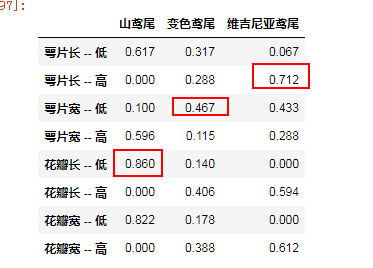
所有特征所对应类别的准确率
由此可以得到每个类别的鸢尾花所对应的主要特征,其中山鸢尾所对应的唯一特征是,花瓣长度值低;变色鸢尾所对应唯一特征为萼片宽度低;维吉尼亚鸢尾所对应的唯一特征为萼片长度高;
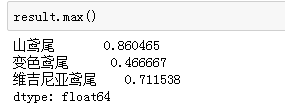
用max方法可以快速查看
6、选取花瓣长度,来预测山鸢尾
X_test['y'] = X_test['pl']
true_counts = 0
for i , j in zip(X_test.iloc[:,4],y_test):
if i == j:
true_counts += 1
print('预测准确率为%.2f%%' % (true_counts/len(y_test)*100))
最终预测准确率为73.68%。虽然准确率并不高,但考虑到只用到了一个特征, 这个结果已经很理想了。
方法二,用交叉表直接得到特征类别数量表
运用Pandas自带的crosstab方法可以快速计算类别特征数量
X_train['y'] = y_train
train_data = X_train
feature = {
0 : '萼片长',
1 : '萼片宽',
2 : '花瓣长',
3 : '花瓣宽',
}
values = {
0 : ' -- 高',
1 : ' -- 低',
}
frames2 = []
for i in range(4):
df2=pd.crosstab(train_data.iloc[:,i],train_data.iloc[:,4])
frames2.append(df2)
df4 = pd.concat(frames2)
df4['index'] = result.index
df4.columns = ['山鸢尾','变色鸢尾','维吉尼亚鸢尾','index']
df4.set_index('index')

特征类别统计表
第二种方法比较简单直接,计算出统计表以后再用前面代码进行准确率计算,提取主要特征,进行预测即可,在此不作赘述。