一份覆盖前端、后端、运维三个维度的踩坑总结。一步一个脚印,我们一起成长!(实时更新)
文章目录
-
-
- 1.1 Css/Scss
-
- 1.1.1 层叠性
- 1.1.2 继承性
- 1.1.3 优先级
- 1.1.4 backgroud设置背景图片样式顺序决定是否生效
- 1.1.5 Vue在元素中要使用当前vue对象的属性作为图片路径显示在 background-image: url() css上解决办法
- 1.1.6 div里面的内容如何垂直居中
- 1.1.7 RGBA
- 1.1.8 块级元素
- 1.1.9 行级元素
- 1.1.10 行内块元素
- 1.1.11 行高
- 1.1.12 浮动
- 1.2 Java Script
-
- 1.2.1 Object.assign
- 1.2.2 前端js获取滚动条距离顶部的位置
- 1.2.3 splice删除指定数组下标
- 1.2.4 Object.keys(), Object.values()
- 1.2.5 addEventListener注册事件注意点
- 1.2.6 如何动态的为对象添加key的值
- 1.2.7 javascript ... 运算符
- 1.3 Vue.js/Nuxt.js
-
- 1.3.1 vue.js生命周期
- 1.3.2 nuxt.js 生命周期
- 1.3.3 computed(计算属性)
- 1.3.4 v-show和v-if
- 1.3.5 v-for
- 1.3.6 this.$set/Vue.set 响应式属性
- 1.3.7 自定义指令
- 1.3.8 vue-router base属性
- 1.3.9 Nuxt v-for嵌套v-if的坑
- 1.3.10 .native添加原生事件
- 1.3.11 nuxt.js重定向
- 1.3.12 vue深度监听属性
- 1.3.13 vue脚手架3.0版本之前的路由配置
- 1.3.14 前端生成excel表格自定义组件
- 1.3.15 限制输入字符的语句在linux中会失效
- 1.3.15 vue.js嵌套路由 子路由path的定义
- 1.3.16 Nuxt.js 官网提供的自定义loading组件. 并将该组件定义在nuxt.config.js的loading 选项中
- 1.3.17 vue.js父子组件加载顺序
- 1.3.18 vue.js .sync修饰符
- 1.3.19 vue.js 实现自定义组件v-model
- 1.4 ElementUI
- 1.5 npm
-
- 1.5.1 package.lock.json
- 1.5.2 package.json文件中的依赖
- 1.5.3 npm install指定版本依赖并保存至package.json
- 1.5.4 npm发布自己编写的vue.js组件库
- 1.5.5 npm+git搭建私有npm仓库
- 1.5.6 npm 和 cnpm的坑
- 1.6 Html
-
- 1.6.1 手动设置ie浏览器以最新版本渲染页面
- 1.6.2 指定浏览器对html文件的编码格式
- 1.7 ES6语法
-
- 1.7.1 export 和 export default的区别
- 1.8 跨域
-
- 1.8.1 出现跨域的原因
- 1.8.2 预检操作
- 1.9 some方法
- 1.10 React
-
- 1.10.1 在生命周期中调用异步请求的坑
- 1.10.2 react dispatch的坑
- 二. 后端
-
- 2.1 Java basic
-
- 2.1.1 Double引发的Null Pointer Exception
- 2.1.2 强转类型前提
- 2.1.3 基础数据类型相等的判断
- 2.1.4 Split方法
- 2.1.5 异常中try, finally, catch中return的顺序
- 2.1.6 Servlet中没有暴露出无参构造器(手动编写了带参构造器)
- 2.1.7 根据oss url获取远程图片, 并转成base64
- 2.1.8 动态代理抛出实际真实异常
- 2.1.9 多线程基础
-
- 2.1.9.1 volatile关键字与System.out.print的欢喜冤家
- 2.1.9.2 JDK线程状态及转换图
- 2.1.10 抽象类和接口的区别
- 2.1.11 Overload和Override的区别
- 2.1.12 ArrayList,LinkedList,Vector
- 2.1.13 HashMap, HashTable, ConcurrentHashMap
- 2.1.14 创建Class对象的几种方法
- 2.1.15 ArrayList.asList()的坑
- 2.1.16 不要在 foreach 循环里进行元素的 remove/add 操作
- 2.1.17 JVM 类加载器
- 2.1.18 Map put进去的默认类型
- 2.1.19 AtomicInteger CAS操作流程
- 2.1.20 为什么要面向抽象编程
- 2.1.21 ArrayList源码及其总结
- 2.1.22 如何判断类A是否为类B的子类
- 2.1.23 BigDecimal的几个总结
- 2.1.24 时间区间校验遇到的坑
- 2.1.25 对接第三方需要发起https请求的证书存储策略
- 2.1.26 使用BooleanUtils判断true或false不是“画蛇添足,多此一举”
- 2.1.27 布尔类型反序列的坑
- 2.1.28 再次理解“线程安全”
- 2.1.29 所谓的并发编程
- 2.1.30 使用https对接第三方的通用流程
- 2.2 Spring Cloud
-
- 2.2.1 服务注册中心Eureka
- 2.2.2 ApiGateWay(Zuul)
- 2.2.3 FeignClient
- 2.2.4 Swagger
- 2.2.5 ServerConfig
- 2.2.6 SpringCloud常用组件及作用
- 2.2.7 微服务开发需要注意的点
- 2.3 Spring
-
- 2.3.1 @RequestParam 类型映射
- 2.3.2 @RequestMapping 方法映射关系
- 2.3.3 @RequestBody注解接收Post请求ContentType为application/x-www-form-urlencoded格式的数据
- 2.3.4 @RequestMapping支持多种请求方法
- 2.3.5 @RequestMapping指定request和response的contentType
- 2.3.6 SpringBoot使用对象来接收query参数
- 2.3.7 Spring mvc 全局异常处理注解@ExceptionHandler
- 2.3.8 Spring获取ioc容器上下文的两种方式
- 2.3.9 Spring核心
- 2.3.10 Spring bean作用域
- 2.3.11 SpringBoot使job注解和异步调用注解生效前提
- 2.3.12 Springboot yml文件配置的坑
- 2.3.13 @Autowired和@Resource的区别
- 2.3.14 SpringBoot默认包扫描路径
- 2.3.15 springboot后台允许跨域及实现自定义请求头
- 2.3.16 spring 描述bean的信息
- 2.3.17 spring自动装配
- 2.3.18 spring事件驱动模型的坑
- 2.3.19 Springboot parent jar包包含的功能
- 2.3.20 spring-boot-starter-actuator
- 2.3.21 @SpringBootApplication注解
- 2.3.22 使用SPI功能集成spring自定义事件功能
- 2.3.23 启动springboot后执行某个特定的方法
- 2.3.24 springboot引用其它yml或者properties配置文件
- 2.3.25 IOC和DI的关系:
- 2.3.26 Spring的编码风格
- 2.3.27 循环依赖
- 2.3.27 单例bean中依赖原型bean生效的方法
- 2.3.28 spring aop
- 2.3.29 构建spring 5.0.x源码
- 2.3.30 BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor类型的后置处理器区别
- 2.3.31 springboot默认扫描路径导致无法加载第三方jar包的bean
- 2.3.32 spring 抽象父类也支持Autowired
- 2.3.33 spring @ConditionalOnBean注解的工作原理
- 2.3.34 spring集成mongodb的几个总结
- 2.4 Mybatis
-
- 2.4.1 parameterType为int/long时, 参数为0的处理
- 2.4.2 $和#区别
- 2.4.3 ORM映射文件 type和map后缀的区别
- 2.4.4 Mybatis resultMap中type=map, 使用枚举的typeHandler前提
- 2.4.5 使用springboot 通过继承SqlSessionDaoSupport类集成mybatis
- 2.4.6 typehandler
- 2.4.7 mybatis集成oracle的坑
- 2.4.8 mybatis用redis作为二级缓存的坑
- 2.4.9 mybatis @Select注解版本的坑
- 2.5 MySQL
-
- 2.5.1 export database/table command
- 2.5.2 import database/table command
- 2.5.3 mysql压缩版本()启动步骤
- 2.5.5 存储过程
- 2.5.6 DML和DDL概念
- 2.5.7 mysql连接数不够
- 2.5.8 flyway
- 2.5.9 mysql sql优化
- 2.5.10 mysql5.7 官方镜像设置支持存储中文及数据持久化
- 2.5.11 mysql(5.7.23)离线安装在linux(非docker镜像)
- 2.5.12 开发精度问题
- 2.5.13 MySQL不走索引的坑
- 2.5.14 mysql的可重复提交事务的特点以及引来的坑
- 2.6 Elasticsearch
-
- 2.6.1 linux构建es的坑
- 2.7 Redis
-
- 2.7.1 手动暂时性的设置密码
- 2.7.2 redis配置远程支持连接
- 2.7.3 RDB机制
- 2.7.4 AOF机制
- 2.7.5 RDB和AOF如何取舍
- 2.7.6 使用redis作为分布式锁的原理即存在的问题
- 2.7.7 使用redis做消息队列
- 2.7.8 redis五种数据类型使用场景
- 2.7.9 Redis主从集群
- 2.7.10 哨兵模式
- 2.7.11 高可用集群模式
- 2.7.12 redis中的lua脚本
- 2.8 Maven
-
- 2.8.1 install maven仓库找不到的jar包
- 2.8.2 maven profiles集成springboot build多环境
- 2.8.3 maven pom文件scope解析
- 2.8.4 maven项目打包类型
- 2.8.5 maven代码混淆插件导致spring 创建的bean找不到类型
- 2.8.6 搭建maven私服
- 2.8.7 maven编译报错
- 2.8.8 maven打出的jar包运行指定含有main方法的类
- 2.8.9 普通java maven项目打包插件(将依赖的jar包也打进去)
- 2.9 Git
-
- 2.9.1 回退版本
- 2.9.2 查看分支树
- 2.9.3 只查看commitId和comments的背景
- 2.9.4 cherry-pick和merge的区别
- 2.9.5 合并commit
- 2.9.6 git reset HEAD~ 带来的坑
- 2.9.7 Github中提交的记录在Contribution中看不到
- 2.9.8 gialab保护分支, merge代码时指定某种角色才能merge
- 2.9.9 git patch功能
- 2.9.10 git绑定多个push源, 实现同时push
- 2.9.11 git改变push源
- 2.9.12 git以https协议push 防止多次输入密码方式
- 2.10 设计模式与应用
-
- 2.10.1 简单工厂 + java多态性完成订单流水操作
- 2.10.2 适配器模式 + 动态代理集成第三方类库, 完成日志记录操作
- 2.10.3 模板方法
- 2.10.4 观察者模式
- 2.11 jvm
-
- 2.11.1 通过jstatd的方式,使用jvisualvm远程查看java进程jvm情况
- 2.12 消息中间件
-
- 2.12.1 在与第三方交互时消息中间件的使用
- 2.12.2 顺序消费的情况是怎么发生的?
- 2.12.3 @RabbitListener底层实现原理
- 2.13 Dubbo
-
- 2.13.1 服务消费者设置超时时间的坑
- 2.13.2 Dubbo RpcContext透传信息的坑
- 2.13.3 Dubbo引入服务,若服务未注册到注册中心则报错
- 2.13.4 为什么一定要在服务提供者中引用自己?
- 2.13.5 Dubbo过滤器一定要使用配置@Activate注解中的order属性来控制顺序吗
- 2.14 MongoDB
-
- 2.14.1 索引的TTL机制
- 2.14.2 创建索引的异常
- 2.15.3 mongodb条件查询null的两种情况
- 三. DevOps
-
- 3.1 Docker
-
- 3.1.1 搭建远程本地仓库
- 3.1.2 push镜像到本地仓库
- 3.1.3 使用ssh远程执行命令运行容器
- 3.1.4 挂载宿主机目录
- 3.1.5 ADD命令的坑
- 3.1.6 Dockerfile常见命令解析
- 3.1.7 指定docker 容器的时间参照物
- 3.1.8. docker commit命令
- 3.2 Jenkins
-
- 3.2.1 自动化部署maven项目
- 3.2.2 多job部署, job间传值
- 3.2.3 linux不同用户运行jenkins.war
- 3.2.4 Jenkins支持maven多模块项目(每个模块都是一个git仓库)多环境同时部署思想
- 3.2.5 jenkins multijob build多模块(每个模块都是一个git仓库)
- 3.2.6 jenkins Multijob 参数传递规则:
- 3.2.7 jenkins使用nohup后台运行jar包
- 3.2.8 jenkins运行mvn命令找不到
- 3.3 Shell脚本
-
- 3.3.1 自定义shell脚本, 完成maven多项目自动拉取远程仓库代码操作
- 3.3.2 ENV=${ENV:-"local"} 代码含义
- 3.3.3 ssh执行远程命令awk命令无法执行的问题
- 3.3.4 Sed命令根据key修改文件内容
- 3.3.4 Sed和Rename命令修改文件名
- 3.4 Nginx
-
- 3.4.1 配置反向代理
- 3.4.2 配置多个vue.js单页面项目
- 3.4.3 docker化basic auth(可配)
- 3.4.4 配置Https证书, 支持https访问.
- 3.4.5 利用nginx正向代理
- 3.4.6 Tomcat server.xml配置文件解析
- 四. Linux
-
- 4.1 常用命令(常忘)
-
- 4.1.1 给文件添加可执行权限
- 4.1.2 删除当前文件夹内所有内容
- 4.1.3 压缩当前文件夹为zip包
- 4.1.4 解压缩zip压缩包到当前目录
- 4.1.5 查看某个文件的大小
- 4.1.6 列出文件夹下面第一级每个文件的大小(包括文件夹和文件)
- 4.1.7 查找文件命令
- 4.1.8 查找某个端口被占用
- 4.1.9 查看linux各进程内存使用情况
- 4.1.10 Linux 启动项目后台保留策略
- 4.1.11 cp -r 命令的坑
- 4.1.12 清除所有log文件(内存不够时)
- 4.1.13 压缩成tar.gz压缩包
- 4.1.14 解压缩tar.gz包
- 4.1.15 Linux文件权限查看及无权限解决方案
- 4.1.16 基于linux和nginx搭建内网本地yum源
- 4.1.17 在centos7中添加一个自定义服务
- 4.1.18 如何使用命令下载sftp服务器中的文件
- 4.2 keepalived实现主备部署
-
- 4.2.1 两台centos7使用keepalived实现主备简单部署
- 4.3 linux配置环境变量的坑
- 4.4. 使用软连接完美释放环境变量
- 4.5 使用jstack定位导致cpu狂飙的问题代码
- 4.6 如何在centos7中添加一个自定义服务
- 五. Http
-
- 5.1 ContentType
- 六. IDEA
-
- 6.1 快捷键(修改成eclipse后)
-
- 6.1.1 查看接口的实现类
- 6.1.2 查看哪个地方用了当前类
- 6.1.3 类型强制转换
- 6.1.4 快速添加try catch
- 6.1.5 查找项目中的文件
- 6.1.6 查找项目中的文件(包括源码)
- 6.1.7 修改idea提示功能快捷键为 ctrl + /
- 6.1.8 修改idea关闭当前类tab快捷键为 ctrl + w
- 6.1.9 IDEA调试hashMap源码显示不了hashMap内部一些属性
- 6.2 IDEA手动搭建springmvc maven项目
- 6.3 IDEA 2019编译项目找不到sun.misc包
- 6.4 IDEA 切换同一个目录下多个项目的分支
- 七. 阿里云oss
-
- 7.1 上传图片
-
- 7.1.1 私密上传base64格式图片
- 7.2 下载图片
-
- 7.2.1 前端访问私密图片
- 八、大咖们发的文章涉及到的知识点
-
- 8.1 INSERT INTO SELECT语句造成的锁表事件
- 8.2 Java Bean Copy框架性能对比
- 8.3 如下两条SQL的抉择
-
一. 前端
1.1 Css/Scss
1.1.1 层叠性
浏览器的渲染机制是从上至下, 当有多个样式同时应用到同一个dom元素时, 默认使用最后一个样式。(不考虑手动设置权重的case)
1.1.2 继承性
1. 前提: 标签之间是嵌套关系
2. 文字颜色、字体大小、字体、行高、文字有关的属性都可被继承
3. 特殊点:
a标签不能实现字体颜色的集成, 字体大小可被继承
h1标签不可以继承字体大小, 继承过来会做一些 `计算`.
1.1.3 优先级
| 类别 | !important | 行内样式 | id选择器 | 类选择器 | 标签选择器 | 默认样式 |
|---|---|---|---|---|---|---|
| 对应权重 | 1000以上 | 1000 | 100 | 10 | 1 | 0 |
对于所有的选择器, 都会统计权重, 哪个权重大, 使用哪个(若权重一样, 则应用最后一个)
1.1.4 backgroud设置背景图片样式顺序决定是否生效
- backgroud: url(‘xxxx’); 的样式必须写在最前面。
eg: background-size: 100%; 的参数才会生效, 因为它是override机制。
同时可以在background: url(‘xxx’) 接属性。
eg: background: url(‘xxx’) no-repeat 100% 100%; 即一次性设置完。 - 使用background-image: url(‘xxx’) 的方式, 这样则不需要考虑前后顺序
1.1.5 Vue在元素中要使用当前vue对象的属性作为图片路径显示在 background-image: url() css上解决办法
- 需要使用backgroundImage属性:
<div class="supply-index" :style="{backgroundImage: 'url(' + attributeObj.image + ')'}"></div>
注意: 使用的是backgroundImage, 而不是background-image
1.1.6 div里面的内容如何垂直居中
width: 100%;
top: 50%;
transform: translateY(-50%);
- 其实top: 50%, 已经是将该dom元素垂直居中了, 但是因为要内容居中, 所以需要Y轴移动元素内容高度的50%, 即transform: translateY(-50%)
1.1.7 RGBA
- RGBA来标识颜色, 第四个参数可以增加透明度
1.1.8 块级元素
- 常用块级元素: div, h1-h6, p, ul, li
- 特点:
- 独占一行
- 可以设置宽高
- 嵌套情况下, 子元素的宽度默认与父类一致
1.1.9 行级元素
- 常用行级元素: span, a, strong, em, del, ins
- 特点:
- 在一行上显示
- 不能直接设置宽和高(若实在想设置宽和高, 可以设置成行内块元素)
- 元素的宽和高就是内容撑开宽和高
1.1.10 行内块元素
- 常用行级元素: input, img
- 特点:
- 在一行上显示
- 可以设置宽高
1.1.11 行高
- 定义: 浏览器默认文本大小为16px, 行高是基于基线与基线之间的距离 = 文字高度 + 上下边距(padding)
1.1.12 浮动
- 定义: 标准文档流: 自上而下, 自左向右, 块元素独占一行, 行元素在一行上显示, 碰到父边框后换行
1.2 Java Script
1.2.1 Object.assign
- 使用方式:
- 注意事项: 若两个对象的key一致, 那么会覆盖value, key不会重复
1.2.2 前端js获取滚动条距离顶部的位置
let scrollTop = document.documentElement.scrollTop || document.body.scrollTop
//获取当前window窗体的高度: document.documentElement.clientHeight
window.addEventListener('scroll', function(){
}, true) //注册滚动条滚动事件
document.documentElment //获取的是html元素
1.2.3 splice删除指定数组下标
arr.splice(0, 1) // => 表示从下标为0开始删除一个元素,
arr.splice(0, 1, 'test') // => 则对arr数组下标为0开始添加一个test元素
1.2.4 Object.keys(), Object.values()
- 处理数组的结果, 前者会返回数组的每一个元素对应的下标, 后者会返回每一个元素的value
1.2.5 addEventListener注册事件注意点
- 首先addEventListener添加的事件是不会被覆盖的
其次若有层级关系(会冒泡), 则遵循以下规则:
true的执行顺序在false之前
true和true之间: 外层的先触发
false和false之间: 内层的先触发
1.2.6 如何动态的为对象添加key的值
-
参考如下代码:
var objKey = "123" var objValue = 456 // 如果我们想创建一个对象,使用objKey的值作为key,objValue的值作为value,比如如下操作: var obj = { objKey: objValue} // ===> 此时的obj对象的结构为:{objKey: 456} // 如果我们一定要将obj变成{123: 456}, 那该怎么办呢? // 这样写: var obj = { [objKey]: objValue} // ===> 使用这种方式就能将obj变成 {123: 456}的结构了
1.2.7 javascript … 运算符
-
先看如下案例
let x = { a:1, b:2, c:3} let y = [{ x:4}, { y:2}, { z:2}] let z = [x, ...y] console.log(z) // /** 0: {a: 1, b: 2, c: 3} 1: {x: 4} 2: {y: 2} 3: {z: 2} */ -
很明显,JavaScript的**…运算符具体的作用为拆解**:将里面的元素拆解出来,但我们通常不单独使用它,因为会报错,eg:…y,会报:
Uncaught SyntaxError: Unexpected token '...'的错误。通常,使用**…**运算符时,会把元素拆解然后组装到一个新的对象(可以是数组,也可以是普通的对象)中去。在上述案例中,我们将y进行拆解,然后把y的每一个元素和x对象放进了z数组中去
1.3 Vue.js/Nuxt.js
1.3.1 vue.js生命周期
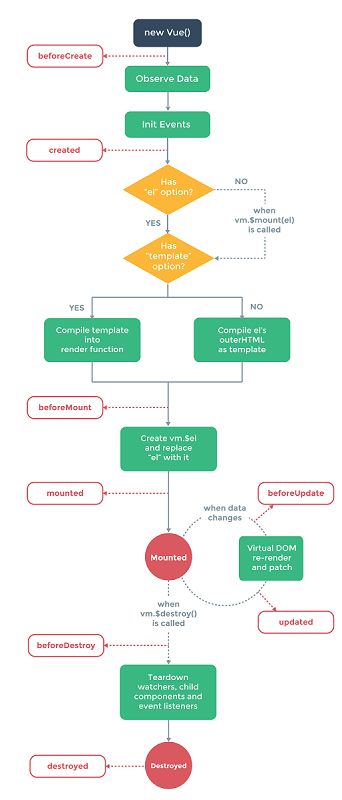
1.3.2 nuxt.js 生命周期
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HrWdg0rj-1617418951514)(./nuxt-life-time.png)]
1.3.3 computed(计算属性)
/* 举个栗子: 当前vue对象中有一个属性叫imageUrl, 但是因为它只是一个url,在动静分离的项目中,
如果要显示它必须还要在它前面添加oss host和ip, 所以此时可以使用计算属性对该属性进行处理, 计
算属性的作用比监听器更好, 因为它自带内存机制. 若this.imageUrl值没有变, 则每次获取计算属性
时都是从内存中获取
*/
computed: {
realImageUrl: function() {
return 'oss host : port ' + this.imageUrl
}
}
- 在vue中computed的属性可以使用箭头函数, 第一个参数为vm(当前vue对象). eg:
computed: {
realImageUrl: vm => {
return 'oss host : port ' + this.imageUrl
}
}
- 在nuxt中, computed的属性请使用普通函数, 如上述第一种. 若使用箭头函数的方式, 会不定时(有时能将当前vue对象依赖注入到vm参数,
有时却不能)的出现imageUrl of undefined的错误
1.3.4 v-show和v-if
1. 首先要了解css中display: none; 该属性是将dom元素给隐藏且不占用文档流,但元素依然在网
页源码中可见(F12).
2. v-show指令的功能就是上述所说.
3. v-if指令的功能是将整个dom处于 '渲染-销毁' 这样的生命周期中.
4. 区别:
v-show: 不管初始值为false/true, 都会先渲染对应的dom元素。 对于需频繁控制dom元素的隐藏/显示的需求, 消耗性能较小.
v-if: 懒加载dom元素, 只有当value为true的时候才会对dom元素进行渲染, 若由true -> false, 则会对dom元素的所有
属性(绑定的事件, 响应式数据的绑定等)进行销毁. 当由false -> true, 则会重新绑定, 所以相比v-show而言,
性能消耗较大.
1.3.5 v-for
-
先看以下示例(刚接触vue的学者渲染列表数据的经典写法)
<div v-for="(item, index) of items" :key="index"> <span>{ {item.xxx}}span> div> -
强烈建议不要使用上述的写法, 若你是做h5项目下拉式的分页功能倒无大碍. 若你是做web pc使用异步请求动态分页渲染列表时, 它会让你见到
非常奇怪的数据. 你会发现后面的几页数据(不刷新页面的前提下)始终会与前面一页的数据, 但重新刷新页面时, 数据又正常了。 出现这样的case主要是因为vue为了减少性能消耗添加缓存的原因. 在vue中, 你可以为每一个dom元素绑定key属性, 改属性是vue使用缓存的依据. 对于上面的例子, 当在web pc使用异步请求动态分页渲染列表的情景下, 若我们使用index作为当前dom元素的key, 那么在渲染后面的页数时, 后面的index基本与上一页准备销毁的dom元素的key一致, vue为了尽可能高效的渲染元素, 若发现销毁队列中的dom元素中与将要渲染的dom元素的key一致, 则会采用销毁掉列中的dom元素进行渲染.所以, 在web pc使用异步请求动态分页渲染列表的情景下, 我们应该使用唯一标识作为dom元素的key, 这个唯一标识可以是
数据结构中的唯一值或者手动引入第三方uuid类库, 将uuid与dom元素的key绑定.
1.3.6 this.$set/Vue.set 响应式属性
-
众所周知, vue的响应式数据是绑定在data方法中. 举个栗子:
<template> <h1>the man's name is: { { man.name}}</h1> <h2 v-if="man.age">the man's age is: { { man.age}}</h2> <button @click="modifyAge">modify age</button> </template> export default { data () { return { man: { name: 'eugene' } } }, methods: { modifyAge () { this.man.age = 13 } }, mounted () { this.man.age = 12 } } /* 1. 首先, 页面上不会显示 the man's age is 12。 因为age这个属性并不是响应式属性, 2. 其次, 就算点击 modify age button 页面也不会显示 the man's age is 13。 因 为this.$set/Vue.set方法动态添加响应式属性的前提是对象中的key不存在(在该栗子下, 虚拟dom树挂载到页面上时, mounted钩子方法就被调用了.), 否则该方法只做更新key对 应的value操作 3. 要在页面中显示the man's age is 12, 需要两个前提 A. man对象中无age属性 B. 在A的前提下调用this.$set(this.main, 'age', 12) 或 Vue.set(this.main, 'a ge', 12)方法 */ -
场景: 在当前的vue实例中有一个名为currentUser的对象, 该对象只有一个id的属性, 现需要
给该对象添加一个name和age属性, 以至于在页面中能够支持响应式渲染。方法1: 在初始化vue对象的时候给currentUser对象添加name和age属性 value均为空字符串 方法2: 使用Vue.set(this.currentUser, 'name', value) or this.$set(this.currentUser, 'name', value) 方法3: this.currentUser = Object.assign({ }, this.currentUser, { name: 'Eugene', age: 23 }) //一定要将Object.assign创建一个新对象并重新赋值给this.currentUser对象, 而不要这样使用 Object.assign(this.currentUser. { name: 'Eugene', age: 23 }) // 因为Object.assign是将结果作为返回值返回
1.3.7 自定义指令
-
注册全局自定义指令
Vue.directive('disabled', { bind: (el, binding) => { // bind钩子函数, vue挂载dom元素时会触发, 且只调用一次 }, update: (el, binding) => { // 虚拟dom树更新时, 该钩子函数会被调用 } }最好别在bind钩子函数中操作其他dom元素, 因为它在虚拟dom树被创建时会被触发, 此时html的dom树还没有生成, 无法获取其他dom元素, 至于update钩子函数是否可以获取其他dom元素待确认 -
解析

-
自定义指令官方文档api:点击跳转
1.3.8 vue-router base属性
添加该属性后 route会默认在每次跳转路由前把这个前缀给加上, 此时在浏览器中添加这个前缀或者不添加这个前缀都能match上路由
1.3.9 Nuxt v-for嵌套v-if的坑
-
如下case,一定要将前面的v-if改成v-show, 否则页面会在挂载(mounted钩子函数不会被执行)的时候失败。
具体错误如下: [nuxt] Error while initializing app DOMException: Failed to execute ‘appendChild’ on ‘Node’: This node type does not support this method.
前提: message 在实例化vue 对象时 要为false<div v-if="message">{ {message.type}}message>
1.3.10 .native添加原生事件
- 使用组件ui库, 若第三方ui库提供的组件中存在@click事件, 则直接使用@click会生效, 否者请加上.native
即 @click.native 表示使用原生的click事件
1.3.11 nuxt.js重定向
Nuxt.js 在asyncData方法中使用context上下文的redirect重定向时,
该方法有三个参数(statusCode, url, params)若只填一个url 则statusCode默认为302
若要传参数(只支持params的参数, 即锚点参数, 若存在query参数的话 重定向会失败), params参数是一个对象, key, value的格式
1.3.12 vue深度监听属性
watch: {
属性: {
//self: this,
handler: function(newValue, oldValue) {
console.log(newValue)
},
deep: true
}
}
- 通常在pc端写table组件时会用到, 一般prop为数组时, 这个会常用。
- 使用该方式对数组进行深度监听, 否则普通的监听数组内部数据进行改变时, 不会触发监听事件.
注: 在深度监听方式中, 如果要在里面处理当前vue对象, 最好别使用箭头函数, 因为此时的this为undefined,
通常会添加self:this 属性来获取当前vue对象, 并在函数里面使用self来获取vue对象.
1.3.13 vue脚手架3.0版本之前的路由配置
- vue router插件必须在src目录下(第一层)
1.3.14 前端生成excel表格自定义组件
- npm插件包: Track to this plug
- 插件包源码: Track to this repository
- 测试包: Track to this test repository
1.3.15 限制输入字符的语句在linux中会失效
- 使用
return (/[\d]/.test(String.fromCharCode(ev.keyCode || ev.which))) || ev.which === 8的方式限制输入字符, 在window环境上是可行的, 但是在linux系统下会失效
1.3.15 vue.js嵌套路由 子路由path的定义
-
vue.js 嵌套路由 chidren中的path不需要加斜杠(/)
{ path: '/user', component: () => import('具体的组件'), children: [ { path: 'list', name: 'user-index', component: () => import('具体的组件') } ] }
1.3.16 Nuxt.js 官网提供的自定义loading组件. 并将该组件定义在nuxt.config.js的loading 选项中
-
组件
-
配置
/* ** Customize the progress-bar color */ loading: '@/components/loading.vue', // 自定义loading组件的位置
1.3.17 vue.js父子组件加载顺序
- 从上往下查看
| 父组件 | 子组件 |
|---|---|
| beforeCreate | |
| created | |
| beforeMount | |
| beforeCreate | |
| created | |
| beforeMount | |
| mounted | |
| mounted | |
| beforeUpdate(可获取渲染之前的dom元素) | beforeUpdate |
| update(可获取最新的dom元素) | update |
| beforeDestroy(有vue实例) | |
| 子组件destroyed(无vue实例) | |
| 父组件beforeDestroy | |
| 父组件destroyed |
1.3.18 vue.js .sync修饰符
-
背景: 都知道在编写vue组件的时候只能使用一个v-model 完成双向数据绑定, 若想绑定多个双向数据绑定的变量呢?
-
解决方案: 使用.sync修饰符
-
父组件parent.vue
<children v-model="value" :customerAttr.sync="myValue" /> -
子组件chirldren.vue
methods: { notify (valueInner) { this.$emit("update:customerAttr", valueInner) } }=> 当在子组件中调用了notify方法时, 则会同时更新父组件的myValue的值为子组件$emit中的valueInner
-
1.3.19 vue.js 实现自定义组件v-model
-
需求:我们需要针对一个组件添加一个属性,能支持双向数据绑定,如下
// parent.vue <my-component v-model="test" />当myComponent.vue文件中的test修改后,parent.vue中的test属性也会随之改变
-
实现步骤:
-
父组件
// parent.vue -
myComponent
methods: { notify (valueInner) { // 此段代码会将valueInner中的值会同步至parent.vue文件中的test this.$emit("input", valueInner) } }
-
1.4 ElementUI
1.5 npm
1.5.1 package.lock.json
npm 5.6之后是以package.lock.json的版本为主, 5.1之前package.lock.json基本上没啥用, 因为就算指定了版本但还是会install最新的
1.5.2 package.json文件中的依赖
后面使用的是^符号(eg: ^2.0.0)的话, 如果依赖包更新了 那么会下载最新的依赖(前提, package.lock.json中没把版本定死),
若确定是使用某个依赖包的话, 那么使用~符号 eg: ~2.0.0 则只会下载2.0.0版本的依赖
1.5.3 npm install指定版本依赖并保存至package.json
-
eg: 安装前端生成excel表的依赖 xlsx: 0.14.0
npm install --save [email protected] npm install --save [email protected]
1.5.4 npm发布自己编写的vue.js组件库
-
使用vue3.0版本之前的脚手架, 搭建webpack-simple模板
vue init webpack-simple export-excel-eug -
修改webpack.config.js文件, 配置别名 ‘@’: resolve(‘src’)
个人习惯, 习惯于使用@与根目录进行映射 -
撰写自定义组件
-
调用Vue.component api全局注册组件
-
修改webpack.config.js文件, 修改打包配置
output配置: 1. 新增library="exportExcel" -> // 模块名, 其他类库使用require的方式引用的原因就是配置了这个 2. 新增libraryTarget="umd" -> // libraryTarget会生成不同umd的代码,可以只是commonjs标准的,也可以是指amd标准的,也可以只是通过script标签引入的 3. 新增umdNamedDefine="true" -> // 会对 UMD 的构建过程中的 AMD 模块进行命名。否则就使用匿名的 define 4. 修改filename为exportExcel.js entry配置 1. 修改entry配置为: entry: './src/index.js', => 指定插件打包时使用哪个入口,此index.js文件内容一般就是添加一个对象, 且对象中包含一个叫install的方法,此install方法的第一个参数就是vue,当调用Vue.use方法时就会把当前的vue对象传入,目的就是可以使用vue这个对象创建对象的组件、指令等等 -
修改package.json文件, 指定插件入口
"private": false, -> 需要发布, 因此需要将这个字段改为 false "main": "dist/exportExcelEug.js", -> 当在第三方使用类库, 使用 import ExportExcelEug from 'export-excel-eug'时, 会根据插件的package.json的main入口找文件library:指定的就是你使用require时的模块名 libraryTarget:为了支持多种使用场景,我们需要选择合适的打包格式。常见的打包格式有 CMD、AMD、UMD,CMD只能在 Node 环境执行,AMD 只能在浏览器端执行,UMD 同时支持两种执行环境。显而易见,我们应该选择 UMD 格式。 有时我们想开发一个库,如lodash,underscore这些工具库,这些库既可以用commonjs和amd方式使用也可以用script方式引入。 这时候我们需要借助library和libraryTarget,我们只需要用ES6来编写代码,编译成通用的UMD就交给webpack了 umdNamedDefine:会对 UMD 的构建过程中的 AMD 模块进行命名。否则就使用匿名的 define -
由于插件的指定路口在dist打包目录下, 所以先把包打好再发布
-
遇到的坑
错误 原因 no_perms Private mode enable, only admin can publish this module 默认镜像非官方的, 需要重新设置.命令: npm config set registry http://registry.npmjs.org npm publish failed put 500 unexpected status code 401 没有登录,需要登录: npm login 即可 npm ERR! you do not have permission to publish “your module name”. Are you logged in as the correct user? 包名被占用, 需要重新命名. 命名之前最好先去npm官网查看包名是否被占用 You cannot publish over the previously published versions 每次发布时需要更新版本, 修改package.json文件的version字段即可. npm publish时经常报403 可以确认下注册的账号是否在邮箱中验证完毕 -
发布包的一句核心话就是: 将所有的插件(插件存在install方法)export出去, 并在使用组件项目入口使用Vue.use(插件)的方式
(Vue.use方法时会触发插件的install方法)生效.附带详细教程
1.5.5 npm+git搭建私有npm仓库
-
背景: 当项目中有自己内部写好一些类库, 但是不想发布到npm公网中, 搭建私有仓库为不二选择。
-
搭建npm私有仓库的三种方式:
- cnpm搭建
- verdaccio搭建
- git
每种方式都自己的优劣势, 感兴趣可以自己研究。
-
npm + git搭建私有仓库
-
选择该方式原因
npm + git 搭建、集成速度快 -
创建私有git仓库(最好是创建一个npm私有仓库的group, 易于管理。 注:gitlab中能创建group以及私有仓库, github不能创建group, 且私有仓库需要付费)
假设在git上创建了一个group, 叫npm-pr, 私有仓库名为hello-world。 url为http://host/npm-pr/hello-world.git 或 git@host:npm-pr/hello-world.git -
初始化scope
npm init --scope=npm-pr -
push代码
上述4步算完成私有仓库的搭建
-
项目依赖类库, 从私有仓库中获取(package.json文件中配置)
// 采用ssh的方式拉取指定branch的依赖 "dependencies": { "@npm-pr/hello-world": "git+ssh://git@host:npm-pr/hello-world.git#branchName" }, // 采用https的方式拉取指定branch的依赖 "dependencies": { "@npm-pr/hello-world": "git+https://用户名:密码@host:npm-pr/hello-world.git#branchName" }, -
安装依赖
npm install @npm-pr/hello-world # 安装后的包路径为node_modules/npm-pr/hello-world 所以在对应前端框架引用插件入口出要注意文件的位置
-
1.5.6 npm 和 cnpm的坑
- 在前后端分离的项目中,我们前端通常是使用模块化开发的方式进行开发,这样就需要使用npm 和node.js。 在拉取项目进行开发的时候,我们通常要进行install操作,目的就是为了和mvn项目一样,引入一些依赖。但是,npm的镜像源是国外,因此会出现网络不稳定的情况,于是乎我们会使用cnpm来进行安装依赖。这里就会出现一个坑:当你同时使用npm和cnpm来安装依赖时,有可能出现不兼容的情况,我本人今天就出现了babel版本不一致的情况,直接导致项目启动不起来。经过网上的调研后,发现这种情况是属于npm和cnpm混用才会发生,而且有时候在纯使用cnpm时,也会出现一般奇奇怪怪的情况。因此,在开发时,建议使用原生的npm,如果出现这种奇奇怪怪的情况时,果断的使用npm来安装依赖
1.6 Html
1.6.1 手动设置ie浏览器以最新版本渲染页面
- 添加meta,使IE用最新版本渲染页面
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
1.6.2 指定浏览器对html文件的编码格式
- HTML 页面, 在head标签的meta标签中设置charset=‘utf-8’ 就能使浏览器以utf-8的标准去解码
<meta charset="UTF-8">
1.7 ES6语法
1.7.1 export 和 export default的区别
-
首先, ES6中存在多模块的概念, 相当于java中的pacakge, 在使用它的时候需要import, 但是它不同与java的package的是, 它需要手动export出去, 即将包暴露出去
-
export default 只能暴露出一个接口.eg: xxx.js文件
export default class xxx { static a = 'attribute' static f = () => { console.log('f')} }xxx中包含许多属性和方法, 且需要static修饰.
使用时:
import xxx from 'xxx文件的路径' 获取a属性: xxx.a 调用f方法: xxx.f() -
export 通常是可以暴露多个接口, 但是在import时, 需要加上 {} 来import指定的接口。eg: xxx.js文件:
const a = 'attribute' const f = () => { console.log('f')} export { a, f }使用时:
获取a属性: import { a } from 'xxx文件路径'
获取f方法: import { f } from 'xxx文件路径'
同时获取a属性和f方法: import { a, f } from 'xxx文件路径'
4. module.exports = {} 和export default {} 时等价的
1.8 跨域
1.8.1 出现跨域的原因
-
违背同源策略(协议、域名、端口都要相同)时, 就会出现跨域
eg: vue.js项目使用localhost:8080作为默认url, 而springboot项目若使用localhost:8081作为服务, 那么这就是两个不同应用程序, 当8080项目在网页中要请求springboot项目8081的一些数据时, 若8081后台没有做跨域处理, 那就会出现跨域. 在这个过程中, 是因为浏览器发现我要请求的资源并不是当前的应用程序。在请求资源时, 浏览器还会根据简单请求和非简单请求进行'预检'操作.
1.8.2 预检操作
-
浏览器将跨域请求分为两类, 简单请求和非简单请求
- 简单请求:
包括HEAD, GET, POST方法请求, 且HTTP请求头信息不会超过以下几种字段: Accept, Accept-Language, Content-Language, Last-Event-Id, Content-Type(只限于3个值: application/x-www-form-urlencoded, multipart/form-data, test/plain)- 非简单请求:
包括PUT, DELETE方法的请求以及Content-Type为application/json。 针对于非简单请求, 浏览器会'预检'(preflight)请求, 主要目的为确认服务器是否允许本地请求(包括源、请求方法、请求头信息等等), 只有预检通过时, 浏览器才会真正的发送XMLHttpRequest, 否则报错(跟跨域相关, 但具体时预检请求没有得到正确的返回状态)。
1.9 some方法
-
some方法的主要用途时some内的表达式返回true则为true, 意为存在的意思, 注意如下几种情况的写法, 主要是看箭头函数右侧的返回值
[{ a: 1, b: 2}, { a: 2, b: 1}].some(_ => _.a === 2) ======= true [{ a: 1, b: 2}, { a: 2, b: 1}].some(_ => { _.a === 2 }) ======= false [{ a: 1, b: 2}, { a: 2, b: 1}].some(_ => { return _.a === 2 }) ======= true
1.10 React
1.10.1 在生命周期中调用异步请求的坑
- 子组件要获取父组件的一些异步请求资源,如果父组件是在生命周期钩子函数调用的,那么这个异步请求资源就会一直pendding,直到父子组件都渲染结束后,这个请求才会继续往下走。
1.10.2 react dispatch的坑
- 在react中,如果我们使用dispatch机制调用了module的某个具体的方法,其中,我们对这个dispatch做了promise的then操作,目的是在dispatch执行完毕后执行then里面的操作来达到同步的目的。但是,若dispatch中的逻辑有错误,比如出现了这种xxx of undefined的错误,此时不会进入then方法,如果dispatch中有call api的操作,此时的api就会一直处于pendding状态。总结就是:dispatch内部的逻辑出错后,不会进入then后面的操作,且不会报错,这个错误会被框架给吃掉的。
二. 后端
2.1 Java basic
2.1.1 Double引发的Null Pointer Exception
Double amount = null;
amount += 123; --> Null pointer exception , 底层后调用 amount.valueOf() + 123 进而导致NullPointerException
2.1.2 强转类型前提
- Java不能直接使用(Long)的方式将integer类型强转成Long类型. 因为Integer和Long两个类没有继承关系。
==> 只有存在继承关系的两个类才能使用括号的方式进行强转。
2.1.3 基础数据类型相等的判断
- 最好使用包装类型并使用equals方法进行判断, 拿Integer和Long类型举例,在(-128 ~ 127)的范围内,是从缓存中取数据, 当不在这个范围内时, 每次都是创建新对象. 栈内存中存放对象引用地址不一致, 使用 == 来判断相等时, 当然不一致。
2.1.4 Split方法
- java split方法, 这种字符串切割 “a, b, c,” 若单独的使用split(",")的方式
那么最后的数组长度为3而不是4, 因为这会调用split一个参数的重载方法,
可以指定长度 split(",", 4) 则指定长度为4
2.1.5 异常中try, finally, catch中return的顺序
- 前提: 程序抛了异常, 并且try catch住了.
- 在catch中有return,finally中无return:
会先执行catch中的所有语句, 包括return后面的逻辑, 执行完之后不会立刻return, 而是去找有没有finally,
如果有则执行finally的语句, 再返回到catch中的return - catch和finally中都有return:
会先执行catch中的所有语句, 包括return后面的逻辑, 执行完之后不会立刻return, 再进finally, 此时发现
finally中有return, 那么就会走finally中的return逻辑, 从而catch中的return失效了, 即出口在finally了
2.1.6 Servlet中没有暴露出无参构造器(手动编写了带参构造器)
- 访问时会报500, 因为系统会采用反射的机制调用无参构造器初始化当前servlet
2.1.7 根据oss url获取远程图片, 并转成base64
-
使用ossClient的getObject方法获取图片的输入流
-
使用1024字节长度的方式, 读取输入流的信息, 并同时写进ByteArrayOutputStream输出流
ByteArrayOutputStream outStream = new ByteArrayOutputStream(); int len = 0; while ((len = ossObject.getObjectContent().read(buffer)) != -1) { outStream.write(buffer, 0, len); } -
再将输出流转成byte数组
outStream.toByteArray() -
使用jdk自带的Base64 encode编码方法, 将byte数组转成base64
- 使用字节限制每次读取的长度, 使用while循环保证能读取整个流
2.1.8 动态代理抛出实际真实异常
- 因为动态代理对象抛出的异常对象为顶级对象Throwable, 所以要获取真实对象的话, 需要调用异常的e.getCause()方法
2.1.9 多线程基础
2.1.9.1 volatile关键字与System.out.print的欢喜冤家
-
volatile关键字的作用大家也都明白, 大致就是提供多线程对临界区变量的可见性、一致性和有序性(JMM主要围绕这三个特性: Java内存模型)
在实战Java并发程序基础一书中有提到, 当jvm采用server模式运行java程序时, 由于配置比较高大上(暂时先这么理解), 导致jvm有闲
情进而导致cpu有闲情对系统进行优化, 尽量让所有的临界区的变量变得可见。 -
上面的背景只是就先介绍到这里, 咱们看下面一段代码:
public class Thread9 { private static boolean ready; private static int number; public static class ReaderThread extends Thread { @Override public void run() { while(!ready); System.out.println("死循环结束, number = " + number); } } public static void main(String[] args) throws InterruptedException { new ReaderThread().start(); Thread.sleep(1000); number = 43; ready = true; System.out.println("主线程休息3秒"); Thread.sleep(3000); } } /* 针对如上的理解, 我们可以得知, 开启ReaderThread线程时, 在主线程睡眠1秒时, ReaderThread线程一直处于死循环中, 当主线程修改临界区number和ready的变量时, 由于ReaderThread线程一直处于死循环中, 压根没给jvm留出一丝的空闲 时间, 所以jvm没法对系统进行优化,尽量让所有的临界区的变量变得可见, 所以上述代码运行结果位: ===> 控制台输出 "主线程休息3秒" 并程序一直在运行中, 给人的感觉就是无任何反应 ==> 若想让线程能够执行完毕, 则只需要在ready变量添加volatile标识符进行修饰即可。 同时:还有一种能让人意想不到的方法, 在ReaderThread线程的run方法的死循环中, 添加System.out.print()输出语句, 输出任何信息都行, 你会发现我不添加volatile标识符, 线程也能正常结束!!!! 这是为什么呢??? ==> 原因就在于System.out.print()源码中有synchronized关键字, 对于jvm而言, 有synchronized关键字的是需要 获取和释放对象的锁的, 这些操作对于jvm而言是需要等待时间的, 而此时jvm发现我有闲情了, 那么它就会优化 系统代码, 尽量保证临界区的变量能够对所有线程可见, 所以线程就正常结束了。 */
2.1.9.2 JDK线程状态及转换图

2.1.10 抽象类和接口的区别
-
抽象类
- 子类必须重写抽象类的
抽象方法 - 包含抽象方法的一定是抽象类
- 不能直接实例化对象
- 抽象方法只有声明,无方法体,方法权限不能为private
- 子类必须重写抽象类的
-
接口
- 可以同时实现多个接口
- 方法都是默认public修饰的,无方法体
- 接口中的变量默认都是public static final修饰的常量
- 实现接口的类一定要实现接口中的所有方法
-
共同点
- 都不能实例化对象
- 都有抽象方法
- 派生类都要重写或实现抽象方法
2.1.11 Overload和Override的区别
-
Overload(重载)
- 参数个数、类型不同
- 与返回值和函数修饰符无关
- 存在于同一个类中
-
Override(重写)
- 子类重写父类方法
- 方法名、参数名、参数个数、参数类型完全一致
- 子类方法权限不能小于父类, 方法权限 >= 父类
- 子类方法抛出的异常不能大于父类, 方法抛出异常 <= 父类
- final修饰的方法不能被重写
2.1.12 ArrayList,LinkedList,Vector
| 类别 | 底层实现 | 是否线程安全 | 是否可重复 | 是否有序 | 其他 |
|---|---|---|---|---|---|
| ArrayList | 线性表(数组) | 否 |
是 | 否 | 默认容量为10,每次扩容1.5倍 + 1,查询快,新增、删除慢 |
| LinkedList | 链表 | 否 |
是 | 无 | 对于新增、删除快,查询慢,一个链表,内部维护了一个叫Node的内部类,代表的就是链表上的每一个元素 |
| Vector | 线性表 | 是 |
是 | 是 | 同ArrayList,线程安全是因为内部所有操作数组的方法都加了synchronized关键字 |
2.1.13 HashMap, HashTable, ConcurrentHashMap
| 类别 | 底层实现 | 是否线程安全 | 是否可重复 | 其他 |
|---|---|---|---|---|
| HashMap | — | 否 |
否 | 可允许key或值为null,实现的是Map接口 |
| HashTable | — | 是 |
是 | 不允许key或值为null, 实现的是Directory接口 |
| ConcurrentHashMap | – | 是 |
是 | 与HashMap一致,内部使用的分段锁segment提高效率,使用大量的CAS操作来保证线程安全 |
-
HashMap源码
-
属性描述
// 默认容量大小 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 最大的容量大小, 即2的30次方 static final int MAXIMUM_CAPACITY = 1 << 30; // 默认的负载因子,扩容的参数 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 转为红黑树的阈值, 当map中的size达到了8,此时变为红黑树 static final int TREEIFY_THRESHOLD = 8; // 红黑树转链表的阈值,当map的size慢慢减少到了6,此时就会转化成链表 static final int UNTREEIFY_THRESHOLD = 6; // 数组长度至少达到64才会进行转化红黑树,否则进行的是扩容操作 // 所以如果针对同一个index对应的长度为8的链表,连续插入两个数据,数组长度就会扩容到64, // 再插入一次数据就会变化成红黑树 static final int MIN_TREEIFY_CAPACITY = 64; -
put方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 定义了三个变量 // tab为hashMap中的数组 // p为数组中的链表 // n为数组的长度 // i为当前key hash过的index Node<K,V>[] tab; Node<K,V> p; int n, i; // 若当前HashMap的实例变量table为null 或者长度为0 // 则进行实例变量table初始化 if ((tab = table) == null || (n = tab.length) == 0) // resize() 为jdk1.8的扩容方法 // 此方法包含了初始化table和扩容操作 // resize默认容量为16 // 扩容时,负载因子是0.75 // 所以当size 的长度 > 12 即插入第13个元素时,会进行扩容 n = (tab = resize()).length; // i = (n - 1) & hash ---> 获取hash的下表 // p为拿到key对应的节点(链表) // 如果等于null,则表示数组中的i的位置上没有元素,直接new一个新的 // 节点放进去即可 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { // 如果key 对应的index中有数据, // 则有两种可能: // 链表转红黑树,或者直接塞在链表后面 // e为要插入的新节点 // k为新节点key Node<K,V> e; K k; // key相同的情况下,替换数组中的链表节点 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果当前节点已经是树节点了,那么直接把它put到树中即可 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 否则是链表的情况,准备把新节点塞到链表中 else { // 无限循环(遍历链表),使用binCount属性来统计链表中的个数 for (int binCount = 0; ; ++binCount) { // 如果p节点是最后一个节点 if ((e = p.next) == null) { // 新建一个节点放在p的后面 <============> 这里是尾插法 p.next = newNode(hash, key, value, null); // 如果此时链表的长度为8,则变成红黑树,要put第九个时才会转 // 因为在put第8个的时候,size还没有加1 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 经过了上述if ((e = p.next) == null)的代码, // e存储的对象是p的下一个节点 // 如果p的下一个节点与新增的节点是一模一样的,则直接跳出循环 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // 此时将e赋值给p,而e是p的next节点 // 所以现在要开始处理p的下一个节点了 p = e; } } // 若e != null, 一定是走了 // if (e.hash == hash && // ((k = e.key) == key || (key != null && key.equals(k)))) // break; // 的逻辑 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 对map长度 + 1, 并且跟阈值作比较,如果比阈值大,则进行扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } -
为什么hashMap初始容量为16?
因为初始容量会参与index的运算。在hashMap中,index = (n - 1) & hash; 其中的n就是为数组容量,hash是指key的hashCode方法 返回值h与h跟16做亦或操作后的值。因为16的二进制底四位全为0, 而16 - 1 = 15的底四位就全为1了。在hashMap的设计中,为了保证hash的散列性,如果以16来和hash做&运算的话,基本上index取决于为1的那一个位置。若变成15后,低四位全为1,所以index将会取决与key的hash值,这增加了key的散列性,即为了保证key能在数组中均匀分布 -
jdk 1.7和jdk 1.8的区别
在jdk1.7时,hashMap的put操作采用的头插法,扩容条件除了size要大于默认容量16 * 负载因子0.75 = 12以外还需要数组当前index位置上不为空。而jdk1.8之后,扩容条件只有size大于12即可,并且put元素的时候采用的尾插法。 这解决了jdk1.7头插法在高并发的情况下会产生出环的情况。并且在jdk1.8时,对index的处理结果也变简单了,少了很多位运算,散列性相对于变低了,但是这影响不大,因为散列性变低了,可能发生的情况就是链表长度会比较长,但是在jdk 1.8中,当size数量超过8个且数组长度大于64时才会把链表转成红黑树。因为红黑树的查询、插入效率比链表的效率高,所以长度边长了也没关系1.7在高并发下会变成环的示意图:

-
有什么线程安全的类可以代替吗?
可以使用Collections.synchronizedMaps()将map进行转化或者使用hashTable进行替换。它们两者差别都不是特别大,都是将一些操作元素的方法加了synchronized关键字,但HashTable中put的value不能为null -
链表什么时候会被转化成红黑树?
当`map的size大于数组长度 * 负载因子` 且 `数组要被扩容两次达到64的长度后`,再往一个长度大于8的链表插入数据时,此时会被转化成红黑树 -
默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
默认大小是16,至于为什么是16,这个我不太清楚,我觉得还可以是32,64,128. 为什么呢?因为hashMap为了保证它的每个key的散列性,会执行这么一个算法: (n - 1) & hash. 其中n是数组容量大小16,hash是key的hashcode并跟16做了异或运算。因为16 的二进制为 0001 0000(这里只列出后8位),而16 - 1 = 15的二进制为0000 1111。两者相比,前者16做完运算后,只取决于hash的一个位置,而后者15取决于hash的后四位,能保证index在0-15的范围内。所以是为了保证key分布在数组中的散列性,即均匀分布。 -
HashMap的主要参数都有哪些?
负载因子、默认容量大小、链表转红黑树的两个阈值(16 * 0.75 和 64)、红黑树转链表的阈值 -
HashMap是怎么处理hash碰撞的?
通过使用key的hashcode值以及跟默认容量长度16做右移和异或操作
-
-
concurrentHashMap原理
-
构造方法
/** * initialCapacity: ConcurrentHashMap中存储HashEntry的总个数 * loadFactor: 加载因子 * concurrencyLevel: Segment的个数 ---> ConcurrentHashMap中维护的数组长度 **/ public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); // 当传入的segment数量个数大于2的16次方,则使用2的16次方 // 所以segment最大数量为2的16次方 // MAX_SEGMENTS = 2的16次方 if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments int sshift = 0; int ssize = 1; // concurrencyLevel默认等于16 // 默认情况下 // sshift ssize // 1 < 16 => 1 2 // 2 < 16 => 2 4 // 4 < 16 => 3 8 // 8 < 16 => 4 16 // 16 < 16 停止循环 // 由上可知, // ssize存储的值与传入的concurrencyLevel相同,即segment的个数(内部维护数组的长度) // sshift ---> 存储的是ssize的2的次方幂的数字,比如16 = 2的4次方,所以sshit = 4 while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; // 左移1位,乘以2的一次方 } // 32 - 4 = 28 ---> 这个变量是计算segment数组下标时用的 // 因为hash值是一个32位的int类型数字,这里用32的原因就是 // 后面会使用hash的高4位与segmentMask做&运算 this.segmentShift = 32 - sshift; // segment数组长度减一, 猜测是为了计算index时用的 this.segmentMask = ssize - 1; // 校验ConcurrentHashMap中的HashEntry的个数是否比1 << 30大 if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // 来确定每个segment中的hashEntry数组的长度 // initialCapacity为ConcurrentHashMap中HashEntry的个数 // ssize为ConcurrentHashMap中segment的个数, // initialCapacity / ssize ==> 能得到一个segment中的HashEntry数组的长度 // 若initialCapacity = 默认的16, 那么1为segment中的HashEntry数组的长度 // 此时 1 * 16 < 16, 所以c不需要自增, // 若initialCapacity = 33, 而ssize = 16, 此时c = 2 // 而 1 * 16 < initialCapacity = 33 所以此时c会加1 // 所以这一段代码的作用就是向上取整 // 从这也能看出, 因为Segment中维护的HashEntry数组的长度最小为2 // 所以至少会有 2 * ssize(concurrencyLevel)个HashEntry // 若传入的initialCapacity > 2 * ssize // 则必须要增加每个segment中HashEntry数组的长度 // eg: 上述所说的: initialCapacity = 33, ssize = 16的情况 // 33 > 2 * 16, 此时放不下33个hashEntry,所以要将 // segment中HashEntry中的数组长度加大 int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; // cap = MIN_SEGMENT_TABLE_CAPACITY = 2, 即HashEntry数组的最小长度, // 所以就算算出来的c = 1,但是最后默认长度也会变成2 // 对于上述的情况,假如initialCapacity = 33, ssize = 16 // 那么算出来的c就会等于3. 但是呢,数组等于3,这样不好,因为最后在对计算index // 时,无法保证index分布均匀,在hashMap中,一般的容量都是2的幂方次的数 // 所以此时,还要对cap进行处理,来获取大于c的2的幂次方的数 // 比如上述情况下的c = 3,所需要找出比3大的2的幂次方的数字 // 于是会执行下面一段代码,在c = 3的情况下, // cap执行完代码2 << 1 后,会变成4 int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1; // create segments and segments[0] // 创建一个Segment对象,并将里面的HashEntry的扩容值给算出来了 // 通过内部也维护了上述算出来的长度为cap的HashEntry数组 Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); // ss为放在table中的第一个segment数组, 长度为传入的concurrencyLevel Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; // 使用UNSAFE类操作数组, SBASE为Segment的offset // 在静态块中对SBASE进行了赋值 // SBASE = UNSAFE.arrayBaseOffset(sc); --> 指定位置 // 所以这段代码是将so放在了SBASE的位置上 UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; }===> 构造方法总结:Hash表的长度有限制,最大为2的16次方。即先确认hash表的长度,再根据传入的hash表长度和hashEntry的长度来确定segment中要维护多少个hashEntry,主要将hashEntry的长度对hash表长度做除法,并向上取整。最终就是初始化了hash表长度和内部维护的hashEntry数组的长度。除此之外,还确定了两个变量:一个叫segmentMask,另一个叫segmentShift。其中segmentMask其实就是
hash表的长度 - 1,segmentShift为hash表的2的幂次方的数字,比如hash表长度是16,那么segmentShift就是4(2的4次方为16) -
put方法
public V put(K key, V value) { Segment<K,V> s; // ConcurrentHashMap的value不能为null --> 其实key也不能为null, if (value == null) throw new NullPointerException(); // 内部key并没有做null处理 int hash = hash(key); // 这个就是要put进来的对象存放在segment数组的下标 // 其中segmentMask在构造方法里就处理过了,它的值为segment数组的长度 // hash >>> segmentShift 是无符号右移,高位全部补0 // 在构造方法中总结过了, segmentShift为 32 - segment长度的2的幂次方的数字(eg: segment的长度为16,那么此数字就是4),所以segmentShift = 28 // 因为hash是一个int类型的数字,所以会执行如下操作 // hash: 01000011 01000011 01000011 01000011 ===> 假设是一个任意hash值 // 当hash >>> 28后会变成如下: // hash >>> 28: 00000000 00000000 00000000 00000100 // 所以可以看到最终j的值取决于hash >>> 28操作的后四位 // 即hash的高四位,因为segmentMask为15 // 所以(hash >>> segmentShift) & segmentMask的结果为: // hash 00000000 00000000 00000000 00000100 // & // segmentMask 00000000 00000000 00000000 00001111 // j的结果: 00000000 00000000 00000000 00000100 = 4 // 由此可以得出segment数组默认为16的情况下, // 新put进来的元素放在segment的index的值取决于hash的高四位 int j = (hash >>> segmentShift) & segmentMask; // 使用UNSAFE在segment数组中拿第(j << SSHIFT) + SBASE位置上的元素 // 获取segments中(j << SSHIFT) + SBASE)位置上的元素 /** 详细解释下使用UNSAFE获取数组指定元素的逻辑 1. 获取UNSAFE对象,这里写的是伪代码 Unsafe unsafe = getUnsafe(); 2. 获取数组中存储的对象的对象头大小, 数组类型,默认为4 ns = unsafe.arrayIndexScale(Object[].class); 3. 获取数组中第一个元素的起始位置, 数组类型,默认为16 base = unsafe.arrayBaseOffset(String[].class); 4. 获取下标为4的元素 unsafe.getObject(arr, base + 3 * ns) ==> 获取的是数组中下标为4的元素 // ConcurrentHashMap中 1. 同理,获取对象头信息 int SBASE = UNSAFE.arrayBaseOffset(Segment[].class); 2. (j << SSHIFT) + SBASE 根据SSHIFT和SBASE的获取逻辑,将变形为如下代码: SBASE + (j << (31 - Integer.numberOfLeadingZeros(UNSAFE.arrayIndexScale(Segment[].class)))) UNSAFE.arrayIndexScale(Segment[].class)获取的是对象类型,所以返回的值默认为4 而4的二进制为 00000000 00000000 00000000 00000100 而Integer.numberOfLeadingZeros(4) = 29 最终变形为: SBASE + (j << (31 - 29)) = SBASE + j * 2的平方 = SBASE + j * 4 所以找到的是第五个位置 **/ if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment // 如果获取的为null,则创建一个新的 s = ensureSegment(j); // 最后在将put进来的对象放入至HashEntry中 return s.put(key, hash, value, false); }===> ConcurrentHashMap的put方法总结:主要是计算出新put进来元素要放置在哪个segment下,确定下表后,再使用cas操作获取segment,最终再调用segment的put方法添加元素
-
创建新的segment,
ensureSegment方法private Segment<K,V> ensureSegment(int k) { // 假设在外部put了一个元素到ConcurrentHashMap, // 此时要定位这个元素放在哪个segment数组的下表中 // 这个k就是下标,因为此下标上没有segment对象,所以需要创建一个 // 但是这个k并不是使用UNSAFE从数组中获取对象的下标, // 这个k是使用hash算法后的下标 final Segment<K,V>[] ss = this.segments; // 因为并发的情况,需要使用UNSAFE去操作数组,于是要计算 // UNSAFE操作数组时的下标 long u = (k << SSHIFT) + SBASE; // raw offset // 要新创建的segment对象 Segment<K,V> seg; // 使用UNSAFE校验,segment中下标为k中是否有对象 if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // 使用构造方法中创建的segment对象 // 因为此对象中存储了当前ConcurrentHashMap中每个segment内部的HashEntry数组的信息 Segment<K,V> proto = ss[0]; // use segment 0 as prototype // 默认为2 int cap = proto.table.length; // 加载因子 float lf = proto.loadFactor; // 扩容的阈值 int threshold = (int)(cap * lf); // 创建了一个HashEntry数组 HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap]; // 再次校验,segment中下标为k的地方有没有对象 // 因为有可能在高并发的情况下,第一个线程走完了上述的第一个校验 // 但是第二个线程可能已经把新建segment的流程都走完了。 // 所以在关键的地方又校验了一遍 if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck // 新建一个segment对象 Segment<K,V> s = new Segment<K,V>(lf, threshold, tab); // 这里使用了自旋锁 // 终止自旋的条件有两个 // 1. segment中index=k的位置上已经有segment对象了 // 2. 将新建的segment对象添加成功 // 在这里可能发生如下并发的情况: // 若第一个线程在while条件中校验通过了,此时进行cas操作时,操作系统发现 // 指定位置上的值不为null(被其他线程给cas成功了),此时为false, // 于是再走while条件,发现已经不为null了,于是自旋结束 while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; } -
HashEntry的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) { // 因为Segment继承了ReentrantLock类,所以它自己是一把锁 // 在高并发情况下,如果tryLock()方法返回的true,即加锁成功 // 可以放心的处理后面的逻辑了。如果加锁失败,又会采用自旋的 // 策略进行加锁 HashEntry<K,V> listNode = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { // 获取内部维护的数组 HashEntry<K,V>[] tab = table; // 使用获取index的算法,与HashMap一致 int index = (tab.length - 1) & hash; // 使用cas获取指定位置的元素,校验有没有值 HashEntry<K,V> first = entryAt(tab, index); // 一个死循环 for (HashEntry<K,V> e = first;;) { // 如果指定位置上有值 // 和hashMap一致,key相同则覆盖,并返回原来的值 // 若key不相同,则继续遍历,所以 if (e != null) // 的分支处理的逻辑是key相同的情况 if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { // TODO listNode != null的情况为获取锁失败,即在高并发的情况下,待总结 if (listNode != null) listNode.setNext(first); else // 如果指定位置上没有值,则新new一个 listNode = new HashEntry<K,V>(hash, key, value, first); // 将ConcurrentHashMap的数量 + 1 int c = count + 1; // 判断是否需要扩容 if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(listNode); else // 使用UNSAFE将新增的元素放在指定位置上 setEntryAt(tab, index, listNode); ++modCount; count = c; oldValue = null; break; } } } finally { // 解锁,完成put操作 unlock(); } return oldValue; }
-
2.1.14 创建Class对象的几种方法
-
根据类加载器
Class c = Class.forName("包.类名"); -
根据实例对象
String str = new String("test"); Class c = str.getClass(); -
根据类获取
Class c = String.class;
2.1.15 ArrayList.asList()的坑
String strArr[] = new String[] {
"a", "b"};
List list = Arrays.asList(strArr);
// => 此时执行list.add()方法会抛出UnsupportedOperationException异常, 因为返回的list类型为Arrays的内部类, 里面并没有重写add方法, 所以调用了父类的AbstractList add方法, 在AbstractList类中的add方法中抛出了UnsupportedOperationException异常并且执行strArr[0] = "h" list中的第一个元素也会改变
2.1.16 不要在 foreach 循环里进行元素的 remove/add 操作
由于单线程的fail-fast机制, 当多个线程对fail-fast集合进行修改时, 可能会抛出ConcurrentModificationException
所以最好是通过迭代器 Iterator来操作, 利用迭代器的remove方法来进行删除
2.1.17 JVM 类加载器
-
背景:
我们都知道java是跨平台的,但所谓的跨平台是指编译后的class字节码文件通过jvm能运行在不同的平台上,而jvm在 对应平台jdk的安装过程中就已经安装完成。那么运行一个普通的java程序(eg: 控制台输出Hello World)jvm在底层 做了哪些事呢? -
javac命令:
javac命令的主要作用就是将.java后缀名文件编译成.class字节码文件, 在大多数IDE中, 这一步骤在run程序的时候 都帮我们完成了。 -
java命令:
java命令就是将javac命令编译后的.class字节码文件运行起来。在此时, JVM将起着非常重要的作用。 首先, 一个普通无继承的类拥有四个类加载器: 1. 自身的classLoader: 2. AppClassLoader: 主要加载应用程序的类, 如自己编写的类、第三方jar包的类库。eg: maven中引入中的所有第三方jar包 3. ExtClassLoader: 能拿到它的引用,一般加载jdk安装目录下的jre/lib/ext文件下的所有jar包。 4. null(根类加载器): 在程序中拿不到它的引用,但是它实际存在,由c++编写, 根加载器一般加载比较重要的类. 比如jdk安装目录下的jre/lib/rt.jar类库(里面存放着jdk类库的字节码文件, 这就是我们能使用jdk api的原因) -
具体java应用程序class加载时间调用顺序如下图所示:
2.1.18 Map put进去的默认类型
- Map
2.1.19 AtomicInteger CAS操作流程
- 实例对象(eg: atomicInteger), atomicInteger.incrementAndGet() -> atomicInteger内部的UnSafe类的compareAndSwapInt方法 -> 虚拟机中的unsafe.cpp文件(c语言编写的compareAndSwapInt方法) -> 汇编语言实现原子性 -> cpu调用指令(因为整个操作变成了一个指令, 所以具备原子性了)
2.1.20 为什么要面向抽象编程
- 最大的好处是为了以后的扩展, 假设以后自己写的实现类不能实现某些需求的时候, 可以通过产生代理对象的方式
对这个类型进行填充, 这样的代码扩展性就高
2.1.21 ArrayList源码及其总结
-
ArrayList长度能自定义,但是实际长度不能自定义,就算使用构造方法添加了默认长度,但是实际上他的长度还是0(因为传入的长度是指给了arrayList一个缓冲区的数组长度),它的实际长度是要通过add方法一个一个去添加时才会变,因为arrayList的size方法就是获取它内部的一个叫
size的属性,而这个属性只有通过add方法时才会对它进行递增。 -
add(“element”)方法默认扩容:当前数组实际长度 + 当前数组实际长度/2,即扩容当前长度的1.5倍,且扩容的过程为创建一个比原来数组长度 * 1.5倍的数组,然后把原数组完全copy过去,最终再将新加入的元素放在最后,完成扩容。
-
add(index, “element”)方法的扩容:首先会校验index是否越界,其次再根据将
index即后面所有的元素copy成一个新数组,然后再将它们放在index + 1的位置上,最后再将新增的元素放入index处, -
remove(index)方法的删除:其实在arrayList中,这个不叫删除,它只是将
index + 1及其后面所有的元素copy成一个新数组,然后再把这个数组放在index位置上,它只是一个覆盖的过程 -
arrayList线程不安全,要想线程安全,可以使用Vector或者使用Collections.synchronizedList api,把一个list包装成一个线程安全的list,其实就是给所有方法加了synchronized关键字,与vector一致
-
Arraylist是一个数组,在插入和删除数据时都会造成整个数组结构的变化,所以一般不建议使用arrayList作为队列
-
源码注意事项:
A. DEFAULT_CAPACITY => ArrayList的默认大小,默认为10 B. EMPTY_ELEMENTDATA ==> 内部维护的一个空数组,当使用带容量的构造方法初始化arrayList时,会将此对象赋值给elementData C. DEFAULTCAPACITY_EMPTY_ELEMENTDATA ==> 内部维护的一个空数组, ----> 其实这一点我觉得做的蛮好,jdk做到了变量单一原则,每个变量有自己的意义 D. elementData ===> 实际存放数据的数组 E. size ==> 数组的真实大小 ----------------------------------------- 1. 默认构造方法 直接将DEFAULTCAPACITY_EMPTY_ELEMENTDATA空数据 赋值为elementData,完成初始化 2. 带容量的构造方法 若大于0 ==> 根据容量大小直接new一个新的 若==0 ===> 直接将EMPTY_ELEMENTDATA赋值给elementData 若小于0 ===> 抛异常 所有的构造方法中,对于arrayList的所有默认大小都没有变化, 一直都是10 3. add操作 因为要add,容器长度肯定会变成size + 1 所以需要用size + 1 去判断是否需要扩容 扩容的逻辑(ensureCapacityInternal): --> 如果elementData是DEFAULTCAPACITY_EMPTY_ELEMENTDATA的话, 即使用的是默认构造方法构造ArrayList的话 会从DEFAULT_CAPACITY和传入的 size + 1 取出谁最大,取出最大的值后再调用ensureExplicitCapacity(最大 值)方法 可以确定的是,如果通过指定容量的方式来初始化arrayList的话,基本上不会走这一个逻辑,因为此时的 elementData是新new出来的而不是DEFAULTCAPACITY_EMPTY_ELEMENTDATA --> 明确扩容大小(ensureExplicitCapacity) modCount++ ==> 用来标识此arrayList数据被修改多少次 有一个扩容的条件, 需要传入的值 与容器实际元素的大小的差 > 0 (minCapacity - elementData.length > 0), minCapacity为上述说的DEFAULT_CAPACITY和size + 1的最大 值随后调用grow扩容 扩容机制就是,扩大elementData数组长度的1.5倍(1.8采用了右移一位的方式,性能比除以2高) 然后创建一个长度为elementData数组长度的1.5倍的数组,最后将原数组加进来, 完成扩容后,最后再将新元素放到elementData.length + 1的位置上 所以这里可以看到,arrayList的size 都是通过add操作来添加的,它的大小并不是与elementData.length对等的, 比如说我新new一个长度自定义的,此时的elementData.length就是自定义的长度,但是size还是0 4. add(index, element)操作 rangeCheckForAdd ---> 校验index的可靠性 ensureCapacityInternal ---> 扩容机制,新增一次扩容的变量 这里的扩容机制也是通过数组复制的方式, 如果长度够,不需要扩容,则把index 及其后面的数据都copy一份,然后把它放在index + 1的位置上, 最后再将新增的元素放在index位置上 如果长度不够,则需要扩容,扩容后,同上,也是将index及其后面的数据copy一份,并放在index + 1的位置上, 最后再将新增的元素放在index位置上 5. remove操作 rangeCheck --> 校验index的可靠性, 是将index与size进行比较,而size的大小是通过add方法一步步增加的 删除的操作也比较有意思,它并不是真正的删除,而是将index + 1及其后面的数据copy了一份, 最后将这份数据放置index的位置上
2.1.22 如何判断类A是否为类B的子类
// 父类.class.isAssignableFrom(子类.class)
System.out.println(B.class.isAssignableFrom(A.class));
2.1.23 BigDecimal的几个总结
-
使用
signum()方法判断一个BigDecimal是否为正负数 -
精度问题导致的java.lang.ArithmeticException: Rounding necessary异常:
如果我们调用bigdecimal的setScala调整精度问题时,需要指定舍入模式,eg: 四舍五入模式。 如果没有指定舍入模式时。默认使用的是ROUND_UNNECESSARY模式,在此模式下,如果bigdecimal的 值为10.222444的话,你强行给他保留两位小数时,jdk会抛出信息为Rounding necessary的计算异常。 所以我们在调用setScala方法设置精度时,可以为它添加一个舍入模式,来预防这种情况下使用哪种 舍入模式进行处理,比如我们可以设置ROUND_HALF_UP模式,即四舍五入模式, 这样的话,当我们传入 10.222444的数字进来之后,会进行四舍五入,最终变成10.22
2.1.24 时间区间校验遇到的坑
-
在工作中,通常会有与第三方系统的调用,但难免会出现第三方系统的维护阶段。假设第三方系统规定了:在22:00 到 00:30之间是不允许调用第三方系统的,即使调用了,也会返回不允许调用的错误。此时,作为调用方,需要对时间段做一些内部校验,比如:在22:00 到 00:30之间不允许调用第三方接口。因此,在做校验时,需要判断当前时间是否位于22:00 到 00:30之间。
-
起初,自己做的方法很“傻”,被这个时间段给吓住了,觉得跨天了,应该会很难。结果去询问下同事后,被同事给“教训”了,同事说:不需要想那么多,只需要获取到当前时间的小时和分钟就行了,然后挨个对比。被他这么一说,我恍然大悟,于是我们可以这个去做:
只需要获取当前时间的 时分 时间即可,然后分别对小时、分钟上的数字进行比较即可。 可以使用SimpleDateFormat formatter = new SimpleDateFormat("HH:mm")的format来获取。大致的代码如下所示:
SimpleDateFormat formatter = new SimpleDateFormat("HH:mm"); String dateString = formatter.format(currentTime); String[] split = timeShort.split(":"); int hourVal = Integer.valueOf(split[0]); int minVal = Integer.valueOf(split[1]); if ((hourVal >= 22 && minVal >= 0) || (hourVal == 0 && minVal <= 30)) { // 位于22:00 到 00:30 // todo return false; } -
总结起来就是:自己对时间的操作不是特别熟悉,有时候请教下同事就能达到事半功倍的效果。如果让自己在跨天这个思维里面一直走的话,那肯定是一个死胡同,费时费力
2.1.25 对接第三方需要发起https请求的证书存储策略
-
在对接第三方应用时,无疑需要以https的方法进行交互的,这就涉及到一个问题:需要我们在代码层面发送一个https请求,而https请求的特点就是需要一个CA颁布的证书,因此我们需要在请求中携带证书,而证书是一个二进制文件。在存储它的时候我们有多种方式,以及他们的优缺点如下所示:
存储证书的方式 优点 缺点 将证书放在项目中的classpath下,到时候直接使用文件流读取即可 简单,方便 1、不安全,证书直接放在了项目中了2、每次读取需要有io消耗,耗时,性能低 将证书转成base64存在数据库中 1、相对安全,将证书存在持久层了2、每次读取直接从数据库中查,相对而言耗时少,性能高 1、每次要进行base64解码,这段过程可能会消耗一点性能,但与io消耗相比,可以忽略不计
2.1.26 使用BooleanUtils判断true或false不是“画蛇添足,多此一举”
-
案例如下:
Boolean x = param.getX(); if (BooleanUtils.isTrue(x)) { // do something }; 当x为Boolean包装类型时,它不是多此一举,因为里面会判空 如果直接修改成如下代码: if (x) { // do something } 此时如果x为null的话,因为会进行拆箱,底层会调用x.booleanValue()方法拆箱,最终会抛出空指针异常 -
因此,使用BooleanUtils判断true或false时,它内部已经覆盖了对象是否为null的情况,避免拆箱操作导致的空指针问题。
2.1.27 布尔类型反序列的坑
- 布尔类型的变量且名称是以is开头的,在反序列化时,只识别去掉is的情况。因为在jdk生成的set、get方法时,也是去掉了is。 因此,最终的反序列化的基本逻辑,都是按照set和get方法来确定的,我们只需要关注set、get方法即可
2.1.28 再次理解“线程安全”
- 为什么要再次理解一遍线程安全呢?因为我们经常在嘴上说线程安全、线程安全。但在真正写代码的时候却很容易忽略这个问题,为什么呢?因为我们认为的线程安全就是防止多线程来操作同一个资源,这也是我们做过最多的一个实验。但其实在其他的一些情景中,你可能会忽略到它。比如自己在写公司的业务逻辑时,发现了自己的不足。
- 背景是这样的:我有一个更新的api,同时还有一个定时的job任务,他们都会有一样的操作,更新数据库中的某条记录。而我在编写update操作的时候,却没有加锁,导致出现了ABA的问题。即,我更新过数据,但发现最终的结果却是我没有更新数据。当然,要解决这个问题我们可以采用乐观锁,但因本人图方便,直接把update的一连串代码给上锁了,查询和修改数据的过程全部在锁中进行操作,为了就是防止多个update操作互相影响。其实在这种情况中,update操作就是一个资源,可能有api和job会同时使用它,因此我们需要保证update操作是线程安全的。当然,在实际的开发中,我们必须要了解项目中的很多细节,要在合适的地方加锁,而不是不思想的加锁,有些地方就是不会出现并发的情况,你又何必加一把锁呢?
2.1.29 所谓的并发编程
-
之前也有总结过:所谓线程安全的含义,其实并发编程也就是为了保证线程安全的。其实我们在写业务时,有很多业务是有状态的,每种状态代表着不同的含义。拿支付系统来举例的话,支付系统中最具有代表意义的就是:支付单。对于支付单而言,它抽象起来其实就是一种交易,因为它应该拥有交易的几种状态:
1、发起
2、等待
3、处理中
4、失败
5、失败废弃
6、成功
在编写业务时,我们一定要定义业务的一些状态,每一种状态会对应一些操作。同时,要确定哪些状态是终态(到底终态后,当前业务结束,后续如果还有相同的业务的话,需要创建一笔的业务数据)。由于每一种状态都会对应一系列的操作,比如针对支付单而言,支付成功后,我们需要操作两个账户(一个账户加钱另外一个账户减钱)。因此,针对支付成功这个状态而言,我们一定要保证这样的操作只会发生一次。很显然,要保证只能操作一次,因此我们就要保证在更新支付成功状态前,需要校验下之前的状态是不是支付成功,只有之前的状态为可转化成支付成功状态的状态时(eg:处理中),我们才更新为支付成功。因此,这里有两个步骤:1、判断之前的状态是否可转化成支付成功的状态。 2、触发更新成功后的各种操作。 这两个步骤要是原子操作。这里提到了原子操作,那必然就要加锁了呀。加了锁,那不就是线程安全的么?线程安全不就是并发编程么?
-
以上的一个例子只是在说明在更新支付单为支付成功状态时一些操作,其实,如果想比较傻瓜式的保证线程安全的话,将所有带有唯一性的操作都上一把锁,变成线程同步的操作,在同步代码块中结合各种业务状态来保证某些操作不被多次执行。因此,我们对唯一性这三个字要求比较高,我们得分析出当前业务的唯一性、某些操作的唯一性等等。
2.1.30 使用https对接第三方的通用流程
-
如下图所示:

万变不离其宗,唯一不同的地方可能就是signType(非对称加密的算法)和encryptType(非对称加密的算法)了,这两个字段主要是用来标识对随机秘钥加密的方式以及签名的方式而已。这相当于就是一个说明,告知对方我当前请求对随机秘钥的处理方式以及对加密数据的验签方法。
2.2 Spring Cloud
2.2.1 服务注册中心Eureka
-
服务注册中心包括Eureka和zookeeper
-
选择Eureka作为服务注册中心原因如下:
- Eureka完全开源, 由Netflix公司生产环境三年的更新迭代,功能和性能上都非常稳定,且社区活跃
- 是SpringCloud首选推荐的服务注册与发现组件
- 与SpringCloud的其他组件 eg: Ribbon, Hystrix, Zuul等组件能无缝对接.
-
工作角色:
- 服务注册中心(register Service)
- 服务提供者(Provider Service)
- 服务消费者(Consumer Service)
2.2.2 ApiGateWay(Zuul)
-
选择Zuul作为路由网关的原因
- Zuul,Ribbon以及Eureka相结合,可以实现智能路由和负载均衡的功能
- 对外只暴露一个api端口, 由内部转发至具体服务
- 可以做用户身份认证和权限认证, 可以起到保护服务的作用
- 可以实时对请求进行日志输出
- 实现流量监控, 在高流量的情况下, 对服务进行降级
-
若在配置路由规则时,指定了请求的url那么zuul底层的ribbon就不会做负载均衡功能了
2.2.3 FeignClient
-
解析如下FeignClient定义的代码
@FeignClient(value="service-user", configuration = FeignConfig.class) @RequestMapping(value = { "/users"}) public interface UserClient { @RequestMapping(value = { "/{userId}/inner" }, method = RequestMethod.GET) FeignMessage getByIdInner(@PathVariable(value = "userId") Long userId); } /* 1. @FeignClient(value="service-user", configuration = FeignConfig.class) => FeignClient的定义: 表明使用该client是,会找到service-user模块(在服务网eureka注册服务时指定的service.application.name配置) 并配置了FeignClient的配置(FeignConfig.class), 可以添加请求拦截器已经响应拦截器 2. @RequestMapping(value = {"/v1/users"}) => 配置了FeignClient发送RPC请求时的requestMapping 3. @RequestMapping(value = { "/{userId}/inner" }, method = RequestMethod.GET) FeignMessage getByIdInner(@PathVariable(value = "userId") Long userId); => 配置了当调用geByIdInner方法时的路径, 所以当在代码中调用 userClient.getByIdInner(1L)时. 底层会发送一个 method=GET, url=/users/1/inner 的HTTP Request, 返回值通过自定义的FeignMessage来接收(底层会做序列化和反序列化操作) 4. 最重要的一个点: 如何将userClient注入到Spring的IOC容器? => 在需要用到userClient的service的入口处添加 @EnableFeignClients(basePackages = {"UserClient的包路径"}) 这样在服务启动时就会添加UserClient的实例至Spring IOC容器中 */ -
另外, FeignClient RPC底层使用的是HTTPClient, 在传递参数的时候必须要有个顺序, 所以会将Map转成LinkedHashMap
2.2.4 Swagger
-
SpringCloud集成swagger
- 需要添加swagger依赖(所有需要暴露swagger的服务都要添加, 所以可以统一加到root的pom.xml上)
<dependency> <groupId>io.springfoxgroupId> <artifactId>springfox-swagger2artifactId> <version>2.6.1version> dependency> <dependency> <groupId>io.springfoxgroupId> <artifactId>springfox-swagger-uiartifactId> <version>2.6.1version> dependency>- 在api网关处添加swagger配置信息(添加Bean到Spring IOC容器中去)
@Configuration public class SwaggerResourcesConfiguration { @Primary @Bean public SwaggerResourcesProvider swaggerResourcesProvider() { return new SwaggerResourcesProvider() { @Override public List<SwaggerResource> get() { List resources = new ArrayList(); resources.add(createResource("service-user", "service-user", "1.0")); return resources; } }; } private SwaggerResource createResource(String name, String registeredEurekaServiceName, String version) { SwaggerResource swaggerResource = new SwaggerResource(); swaggerResource.setName(name); swaggerResource.setLocation("/" + registeredEurekaServiceName + "/v1/docs"); swaggerResource.setSwaggerVersion(version); return swaggerResource; } }- 在ApiGateWay入口文件处添加@EnableSwagger2注解开启swagger功能
2.2.5 ServerConfig
2.2.6 SpringCloud常用组件及作用
- Eureka: 服务注册与发现中心, 用来存储每个服务的对应的ip和端口
- Zuul: 路由网关, 微服务api请求统一路口, 类似于nginx方向代理, 需配置一套规则才能请求到具体的服务
- Ribbon: 负载均衡, 该组件存储在ApiGateWay中, 采用轮询算法, 依次请求服务的每一个实例
- Feigh: 服务间内部调用, 底层采用动态代理, 根据feignClient接口中mvc的一些注解, 组装http请求
- Hystrix: 熔断器, 防止因某个微服务崩溃而导致整个微服务雪崩。具体内部使用采用的是每个服务走自己的线程池
2.2.7 微服务开发需要注意的点
- 微服务开发中,假设A依赖了B的model,且B的model做了修改,那么一定要将A重启,否则使用的是老对象
2.3 Spring
2.3.1 @RequestParam 类型映射
| 后台定义类型 | 前台传数据格式 |
|---|---|
| 数组类型 | value1, value2, value3 以逗号隔开 |
| List类型 | [value1, value2, value3] 以数组的形式 |
2.3.2 @RequestMapping 方法映射关系
- @RequestMapping(value=“test”) -> 在启动项目时, 框架会自动映射成/test. 最好还是加上斜杠, 规范一些。
2.3.3 @RequestBody注解接收Post请求ContentType为application/x-www-form-urlencoded格式的数据
-
在通常的前后端分离项目中, 一般在前端框架使用的异步请求框架都会全局设置ContentType为application/json.
导致在接触第三方jar包回调时遇到不同的ContentType不知如何处理在SpringBoot中的@RequestBody底层只有FormHttpMessageConverter支持解析application/x-www-form-urlencoded这种格式, 但它只能将请求体中的内容转成MultiValueMap对象。
2.3.4 @RequestMapping支持多种请求方法
-
注解中存在method属性, 是一个数组, 可以支持多种请求方式
eg: @RequestMapping( method = { RequestMethod.POST, RequestMethod.GET}, value = "/user-mapping")
2.3.5 @RequestMapping指定request和response的contentType
-
注解中存在consumes和produces注解属性
前者指定request的ContentType, 后者指定response的ContentType, 属性都为数组, 支持多种类型eg: @PostMapping( value = "/callback", consumes = { MediaType.APPLICATION_FORM_URLENCODED_VALUE + ";charset=UTF-8"}, produces = { MediaType.APPLICATION_FORM_URLENCODED_VALUE + ";charset=UTF-8"}) //指定请求和响应的ContentType为application/x-www-form-urlencoded;charset=UTF-8 的方式
2.3.6 SpringBoot使用对象来接收query参数
- 不需要@RequestParam注解, 直接添加对象类型的参数即可.
2.3.7 Spring mvc 全局异常处理注解@ExceptionHandler
- 该注解是方法级别的注解, 通常用来全局处理api请求时发生的异常
所以一般会写一把BaseController并让所有的Controller都继承它, 这样就能catch到所有Controller抛出的异常
2.3.8 Spring获取ioc容器上下文的两种方式
-
通过WebApplicationContextUtil.getApplicationContext(ServletContext)的方式
WebApplicationContextUtil.getApplicationContext(request.getSession().getServletContext()) // 通常需要获取tomcat容器中的HttpServletRequest对象来获取上下文, // 虽然 HttpServletRequest 对象可以直接在方法里将该对象注入进去, 但是还是引入了比较重的对象, 不推荐该方式 -
通过ApplicationContextAware接口
1. 创建类并实现这个接口, 添加静态的ApplicationContext类型的对象。 2. 重写里面的方法setApplicationContext方法, 初始化ApplicationContext类型的对象 3. 将当前类注入到Spring IOC容器中. 这样, Ioc容器对象就是上述的 静态的ApplicationContext类型的对象. 想要具体的bean对象, 直接调用getBean方法即可. (注入到Spring IOC容器中的原因: spring启动时, 若有这样的类, 将会将上下文对象注入到 实现ApplicationContextAware接口的对象的ApplicationContext属性中去)
- 两种方式, 建议使用第二种。
2.3.9 Spring核心
- 单例模式: 所有注入ioc容器中的对象都是单例的
- Bean工厂方法
- 静态工厂方法
- 通过使用静态方法来获取实例
- 实例工厂方法:
- 通过使用非静态方法来获取实例
- 静态工厂方法
- Inject控制反转(常用)
- set方法
- 构造函数
- Aop
- Aspect(切面): 定义了切面是什么以及何时使用
Before——在方法调用之前调用通知
After——在方法完成之后调用通知,无论方法执行成功与否
After-returning——在方法执行成功之后调用通知
After-throwing——在方法抛出异常后进行通知
Around——通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的行为 - Join point(连接点): 业务方面的代码, 作为连接点
- Advice(引入): 引入允许我们向现有的类中添加方法或属性
- Pointcut(切点): 切点定义了"何处"需要执行code, 即表达式定义。 切点会匹配通知所要织入的一个或者多个连接点
- Aspect(切面): 定义了切面是什么以及何时使用
- Annotation
2.3.10 Spring bean作用域
- singleton: 单例模式, 默认。只存在一个实例
- propytype: 原型。每次注入属性时都是new一个新对象
- request: 针对每次http请求, 都会new一个新对象, 适用于WebApplicationContext环境
- session: 每次会话都会new一个新对象, 同一次会话共用一个实例
- global-session: 所有会话共用一个实例
2.3.11 SpringBoot使job注解和异步调用注解生效前提
- 异步注解: @Async
要使注解生效, 需要在入口处添加@EnableAsync注解 - job注解: @Scheduled
要使job定时器生效, 需要在入口处添加@EnableScheduling注解
2.3.12 Springboot yml文件配置的坑
-
在2.0.5.RELEASE版本中(其它版本没有测试)若使用key为no/yes时, load到内存中的key会发生变化
eg: 存在这样一个配置product: no: product_01 yes: product_02spring在将配置文件load到内存后, 使用@Value("${product.no}")的方式是会报错的: 报无这样的key
为啥呢? 因为spring会将key load成 product[false] 或 product[true]
2.3.13 @Autowired和@Resource的区别
-
@Autowired: 默认按照byType的方式进行bean匹配, 是spring框架中的注解
-
@Resource: 默认按照byName的方式进行bean匹配, 是jdk中自带的注解
@Autowired默认是根据byType的方式依赖注入, 若byType的类型的实例不止一个(内部把异常吃掉), 则会根据byName的方式来注入(也就是变成@Resource功能),此时是根据属性名来注入的, 它会将属性名首字母大写, 前面添加set关键字变成set方法, 然后利用反射调用set方法完成注入, 所以此时的 ***属性名*** 很重要,与自己添加的set方法无关. 所以此时的byName依赖注入方式与xml配置的byName又有差异, 因为xml配置依赖注入的byName方式是根据显示的set方法名决定的。 byName的几种情况: * 1. xml配置的byName, 会根据set方法来注入 * 2. @Resource注解的byName, 会根据属性名(其实这个属性名就是bean的名字), * 这个属性名又分是注解中的属性名还是变量名. 总而言之, 不管是@Resource注解中的 * name属性名还是要依赖注入的变量名, 在@Resource的byName方式下, 这个名字一定 * 就是bean的名字 * 3. @Autowired注解当注入的类型有多个时, 会退化成@Resource的功能 byType自动装配有多个相同类型bean时的处理方法: * 1. 将属性名设置成 要注入bean的名字(原理是会降级成@Resource注入模式, 即下述的第三点) * 2. 在一个bean中添加@Primary注解, 表示当遇到多个类型的时候, 使用此bean进行注入 * 3. 修改成@Resource注解, 添加存在bean的set方法或者注解中添加bean的名称 * 4. @Autowired和@Qualifier结合使用, 并在@Qualifier注解中添加指定注入bean的name
2.3.14 SpringBoot默认包扫描路径
-
默认包扫描路径为Springboot项目入口类所在包及子包,所以如果项目中会依赖一些common的jar包, 并且jar包中包含一些
springboot的注解时, 必须要保证依赖common包的路径能被springboot扫描注解时扫描到eg:
假设一个springboot项目依赖一个jar包, 其中这个jar包会存在一个spring 上下文的工具类(一般用于因加载顺序无法 进行依赖注入属性时, 会用它来获取spring管理的bean, 通常是实现ApplicationContextAware接口)。 当在使用redis 作为mybatis的二级缓存时, 需要对实现mybatis Cache接口的类添加redisTemplate类型的对象, 并重写一些方法, 此时redisTemplate是无法依赖注入进去的。 此时就会通过获取spring上下文的工具类来获取bean, 所以此时若该工具类 存在实例化bean的相关注解时, 必须保证该类会在springboot的包扫描有效路径下。 不仅是在这种case下, 比如说在过滤器、拦截器中要注入一些属性时, 也是会注入失败的(因为过滤器或者拦截器加载的时 间是在spring上下文之前的), 此时必须要依赖spring上下文来获取bean对象。
2.3.15 springboot后台允许跨域及实现自定义请求头
-
集成WebMvcConfigurerAdapter类, 重写addCorsMappings方法, 添加针对请求mapping设置允许的请求方法、源等其它关于跨域的设置.如下:
@Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/**").allowedMethods("PUT", "GET", "POST", "DELETE").allowedOrigins("*"); } -
引入spring security类库. 写一个过滤器继承WebSecurityConfigurerAdapter并重写configure方法, 配置允许自定义请求头的部分信息,以及将继承OncePerRequestFilter的过滤器添加到UsernamePasswordAuthenticationFilter过滤器前面. 如下
public class CorsConfigration extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http.csrf() .disable() .cors() .and() .authorizeRequests() .antMatchers( "/**" ) .permitAll() .anyRequest().authenticated(); http.headers().cacheControl().disable(); // add jwt filter http.addFilterBefore(new JwtAuthFilter(), UsernamePasswordAuthenticationFilter.class); } }public class JwtAuthFilter extends OncePerRequestFilter { @Override public void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { Boolean isFilter = !request.getRequestURI().equals("/user/login"); if (isFilter) { if (getJwtToken(request) == null) { response.sendError(HttpServletResponse.SC_UNAUTHORIZED, "无token"); return; } String authToken = request.getHeader("jwt-token"); logger.info(authToken); } chain.doFilter(request, response); } @Override public void destroy() { // Nothing to do } private String getJwtToken(HttpServletRequest request) { return request.getHeader(ContextUtil.JWT_TOKEN); } }
2.3.16 spring 描述bean的信息
1. class: 类的全路径
2. name: bean的名称
3. scope: 作用域
4. constructor-arg: 注入依赖关系
5. properties: 注入依赖关系的
6. lazy-initialization mode: 是否懒加载
7. initialization方法: 在bean的所有属性注入之后调用的钩子函数
8. destrction方法: 包含bean的容器被销毁时的钩子函数
2.3.17 spring自动装配
-
byName:
-
优点:解决了byType多个类型注入抛异常的问题
-
缺点: 代码有点看不懂, eg: xml配置了UserDao类型的两个bean, id分别叫userDao和userDao1。其中userService依赖了UserDao的类型(不使用@Autowired注解), 它的名字叫testDao, 并存在如下方法:
public void setUserDao(UserDao userDao) { this.testDao = userDao; }, 那么它会将id为userDao(bean中name没配置的话, id=name)的bean注入到testDao中, 若存在如下方法:
public void setUserDao1(UserDao userDao) { this.testDao = usreDao; }, 那么它会将userDao1这个bean注入到testDao中去
总而言之就是, byType是根据bean name的首字母变成大写, 并添加set的方法名来注入的。
-
-
byType:
- 缺点: 当同一个类型有多个bean的时候, 注入时会抛出异常, 因为spring不知道注入哪一个
-
全局设置(xml配置):
在spring的beans标签中添加属性default-autowire="byType" -
作用于单个bean:
<bean id="xxx" class="com.xx.xxx.xxxx" autowire="byName"/>
2.3.18 spring事件驱动模型的坑
- spring事件驱动模型三个关键类: ApplicationEvent, ApplicationListener, ApplicationContext
- 步骤
- 事件本身继承ApplicationEvent类, 事件本身, 可以自定义逻辑属性, 在监听器中会用到该类
- 添加事件处理监听器, 实现ApplicationListener接口 => 需要将该类添加到spring容器中, 否则监听不到事件
- 使用springContext上下文发布事件, ApplicationContext.publishEvent(事件实例);
2.3.19 Springboot parent jar包包含的功能
1. 默认的jdk1.8编译环境
2. UTF-8编译环境
3. 自身依赖了一些jar包, 比如log4f等等
4. 可以支持resource目录下的文件使用pom文件中定义的一些属性
2.3.20 spring-boot-starter-actuator
- 常用于生产环境, 可用于项目的监管和check
2.3.21 @SpringBootApplication注解
- 包含了@EnableAutoConfiguration和@ComponentScan注解, 可以使用这两个注解代替@SpringBootApplication注解启动一个springboot程序
2.3.22 使用SPI功能集成spring自定义事件功能
- 背景: jdk默认支持SPI功能, 原则是在classpath中添加META-INF/services文件夹, 并在里面添加以接口命名的文件, 内容为接口的实现类, 这样执行java程序的时候使用ServiceLoader类就能获取到实例并执行对应的方法了
- 集成spring SPI步骤
- 在classpath路径下添加如下文件 META-INF/spring.factories
- 在spring.factories类中存储值: org.springframework.context.ApplicationListener=自定义监听器的全路径(若有多个, 使用逗号隔开)
- 监听器类要实现org.springframework.contextApplicationListener接口, 并重写里面的方法
- 所有实现了org.springframework.contextApplicationListener接口的监听器会在如下几个场景中被触发:
- 在启动springboot时, 由ApplicationStartingEvent类来进行第一次触发
- 当已知要在上下文中使用的环境但在创建上下文之前, 由ApplicationEnvironmentPreparedEvent触发
- 在刷新开始之前但在加载bean定义之后由ApplicationPreparedEvent触发
- 在刷新上下文之后但在调用任何程序和命令行运行程序之前由ApplicationStartedEvent触发
- 在调用任何应用程序和命令行程序之后, 由ApplicationReadyEvent触发
- 如果启动时发生异常, 由ApplicationFailedEvent触发
2.3.23 启动springboot后执行某个特定的方法
1. 两个实现方式: 实现CommandLineRunner或ApplicationRunner接口可实现
2. 若两种方法都实现了, 并且像按照某些顺序执行, 则可以继续实现org.springframework.core.Ordered接口或者使用org.framework.core.annotation.Order胡杰来达到要求
2.3.24 springboot引用其它yml或者properties配置文件
- 使用spring.profiles.include来配置. eg: spring.profiles.include=common 则会加载applicatioin-common.yml或application-common.properties文件
2.3.25 IOC和DI的关系:
- IOC是控制反转的意思(Inversion of control): 是面向对象的一种设计原则, 可以用来降低代码之间的耦合
DI(Dependency Injection)是依赖注入, 是IOC的一种实现, IOC的实现除了DI还有Dependency Lookup(eg: JNDI的实现) - 依赖注入的方式: 构造器、set方法、接口注入(Spring3才有的, Spring4之后就没有了)
2.3.26 Spring的编码风格
1. schemal-based --- xml格式
2. anotation-based --- annotation
3. java-based --- javaconfig => springboot基本上就是基于此模式开发的
2.3.27 循环依赖
- spring 单例与单例之间的循环引用是ok的, 但是如果相互引用的bean中有原型对象(scope=“prototype”)的话, 那么会报错
2.3.27 单例bean中依赖原型bean生效的方法
-
背景: 当一个单例bean中依赖了原型bean时, 当每次使用单例bean的时候里面的原型bean都是同一个对象, 这样就失去了原型bean的作用。现在要期待每次使用单例bean时里面的原型bean都是新new出来的
-
解决方法:
-
除去依赖原型bean, 每次使用它的时候从使用spring上下文的getBean方法获取
-
使用@Lookup注解。 如下, 每次都使用PrototypeUtils.getBasicService()来获取原型BasicService对象, 重载的带参数方法, 表示需要注入内部的属性, 所以BasicService需要提供不同的构造方法, 如下述的BasicService类
@Component public abstract class PrototypeUtils { @Lookup public abstract BasicService getBasicService(); @Lookup public abstract BasicService getBasicService(String name); }@Component @Scope("prototype") public class BasicService { private String userName; public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } public BasicService(String userName) { this.userName = userName; } public BasicService() { } }
-
2.3.28 spring aop
-
参考此文件
-
关于spring的aop,它支持同一个织入绑定多个切点,eg:
@Pointcut( "execution(public * org.springframework.data.repository.CrudRepository.save(..)) || " + "execution(public * com.baomidou.mybatisplus.core.mapper.BaseMapper.insert(..)) || " + "execution(public * com.baomidou.mybatisplus.core.mapper.BaseMapper.update*(..))") public void aroundPointcut() { } @Around("aroundPointcut()") public Object process(ProceedingJoinPoint proceedingJoinPoint) { // Do something }如上代码指定了,一个环绕通知同时绑定了三个切点:分别为org.springframework.data.repository.CrudRepository的save方法、com.baomidou.mybatisplus.core.mapper.BaseMapper的insert方法、com.baomidou.mybatisplus.core.mapper.BaseMapper以update打头的方法。在执行这三个切点指定的方法之前,都会执行环绕通知内的逻辑
2.3.29 构建spring 5.0.x源码
1. 安装gradle, 并配置环境变量(建议4.4.1版本)
2. 查看源码根目录的`import-into-idea.md`文件, 按照提示将`spring-aspects`模块去除, 并要先编译`spring-core` 和 `spring-oxm`两个项目
3. idea导入项目, 设置gradle安装目录和本地仓库地址。
为了避免jvm内存溢出,配置jvm参数 `-XX:MaxPermSize=2048m -Xmx2048m -XX:MaxHeapSize=2048m`
4. 导入项目进行build, 若报错`No such property: value for class: org.gradle.api.internal.tasks.DefaultTaskDependencyPossible solutions: values`
打开`spring-beans.gradle`文件并将`compileGroovy.dependsOn = compileGroovy.taskDependencies.values - "compileJava"`注释掉
5. 重新build, 应该会成功
6. 若自己添加module进行集成并发现`spring-beans`模块编译报错, 一般是某个jar报没导入, 请确认`SpringNamingPolicy`类中的`DefaultNamingPolicy`
是否正常导入, 若无, 请依次执行如下命令: `gradle objenesisRepackJar`, `gradle cglibRepackJar`
7. 若出现 `java: 找不到符号 符号: 变量InstrumentationSavingAgent 位置` 错误, 请先编译下`spring-instrument`模块,
最好是build完之后, 执行下gradle 根目录的编译按钮, 这样所有的子模块都会进行编译
2.3.30 BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor类型的后置处理器区别
1. BeanDefinitionRegistryPostProcessor继承了BeanFactoryPostProcessor后置处理器
2. BeanDefinitionRegistryPostProcessor可以获取BeanDefinitionRegistry, 可以手动添加自定义的
BeanDefinition至bean工厂而BeanFactoryPostProcessor只提供了BeanFactory(ConfigListableBeanFactory),
没有手动添加BeanDefinition的api
3. 通过上下文的addBeanFactoryPostProcessor方法添加BeanDefinitionRegistryPostProcessor类型的后置处理器是最先执行, 是在执行BeanDefinitionRegistryPostProcessor(分别执行实现了PriorityOrdered、Ordered、和没实现PriorityOrdered和Ordered接口的)类型的后置处理器之后完成的
2.3.31 springboot默认扫描路径导致无法加载第三方jar包的bean
SpringBoot默认包扫描路径为入口类所在包及所有子包, 当依赖其他包(其他包中有springboot的相关注解, eg: 通用类的jar包)时, 依赖的包毕竟在扫描范围内注解才会生效。 背景: 主项目的默认扫描包为com.eugene.demo(即springboot入口类在该包下), 而依赖的一个类ApplicationContextHolder(主要是为了获取spring的上下文,方便获取bean)在com.eugene.demo中, 导致这个类的注解一直没有生效。
2.3.32 spring 抽象父类也支持Autowired
- spring若子类是一个bean,父类没有添加相关注解,那么父类的一些属性如果有@Autowired注解的话,也是能依赖注入的(就算父类为抽象类一样能完成注入)
2.3.33 spring @ConditionalOnBean注解的工作原理
-
spring中@ConditionalOnBean注解的工作原理大致可以以如下步骤进行描述
首先@Condition系列的注解的工作原理是发生在构建BeanDefinition的check部分,在spring中我们可以把扫描出来的对象以BeanDefinition的形式进行描述。在构建好BeanDefinition对象后,因为有条件注解功能的存在,所以spring需要对BeanDefinition进行check。其中有一个注解叫@ConditionalOnBean。它的含义为:当前bean的构建依赖于@ConditionalOnBean注解传入的值。那么就有可能出现依赖的bean还未被扫描到就进行了check,进而导致bean不能被spring扫描到。 因此@ConditionalOnBean注解的使用需要check的bean是否在check之前就被加入到spring容器中去了
2.3.34 spring集成mongodb的几个总结
- springboot集成mongodb,添加@Indexed注解就可以为某个字段添加缓存。看了下源码:这是因为它内部有一个MongoPersistentEntityIndexResolver的类在底层为指定的字段添加了索引。
- spring集成mongodb,只需要在接口中定义方法就可以进行数据查询了。如果方法的定义是一个list接收的话,会返回一个list。如果是一个单纯的po对象接收的话,假设插件条件可以查出来多条,但是最终获取到的是第一条数据
- mongodb更新一条记录时,若字段不存在了,那在保存时,此字段也不会在mongo中保存了。即若id为1的记录保存在mongo时,它存在name个age的属性,假设下次存储id为1的记录时,它只提供了一个叫age的属性,那么在mongdo中存储的数据将会只包含id和age属性,name属性就会消失。
2.4 Mybatis
2.4.1 parameterType为int/long时, 参数为0的处理
-
若传入的参数为0, mybatis会将它当成
空字符串处理, 所以会查出name为空字符串的数据<select id="countApplicant" parameterType="int" resultType="long"> select>
2.4.2 $和#区别
-
KaTeX parse error: Expected 'EOF', got '#' at position 14: 会存在sql注入的风险, #̲不会。 因为是将数据和sql语句一起编译的 而#是先编译sql语句再将数据绑定上去, 即跟原生jdbc的问号占位符一样(?, ?, ?..)
-
所以通常在模糊模糊查找时会添加bind标签将需要模糊查找的key预先编译好, 再直接用#将bind定义的变量keywordWrapper进行筛选即可,。
2.4.3 ORM映射文件 type和map后缀的区别
-
parameterType和parameterMap
* parameterType指的是传递进去的参数类型, 基本数据类型以及pojo类型(map或类对象) * parameterMap 一般很少用 -
resultMap和resultType
* resultType 返回基本数据类型 * resultMap 返回对象类型, 同时该对象需要在xml文件中配置model与db字段的映射关系
2.4.4 Mybatis resultMap中type=map, 使用枚举的typeHandler前提
-
需要在字段中添加javaType类型, 指定具体的枚举类是什么, 否则直接使用typeHandler会抛出
Object does not represent an enum type的异常<resultMap id="demoMap" type="map"> <result column="user_id" property="userId"/> <result column="status" property="status" javaType="枚举的具体类的class路径" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"/> <result column="age" property="age"/> resultMap>
2.4.5 使用springboot 通过继承SqlSessionDaoSupport类集成mybatis
- 必须重写setSqlSessionTemplate或者setSqlSessionFactory方法, 同时在方法中添加
@Autowire注解来开启mybatis功能(注入sqlSessionTemplate),
否则会抛初始化sqlSessionTemplate相关的异常
2.4.6 typehandler
-
resultMap中的typeHandler需要加双引号
<resultMap type="Order" id="orderMap"> <id column="order_id" property="orderId"/> <result column="status" property="status" typeHandler="com.eugene.dao.mybatis.typehandler.OrderStatusTypeHandler" /> <result column="price" property="price"/> <result column="payment_type" property="paymentType" typeHandler="org.apache.ibatis.type.EnumOrdinalTypeHandler"/> resultMap> -
insert和update中属性转换不需要双引号
<insert id="insertSelective" parameterType="com.eugene.sumarry.sbrabbitmq.Entity.OrderRecord"> INSERT INTO ORDERS VALUES #{orderId}, #{status, typeHandler=com.eugene.dao.mybatis.typehandler.OrderStatusTypeHandler} insert>
2.4.7 mybatis集成oracle的坑
-
sql语句中不能添加分号, 否则会抛 ORA-00911: 无效字符的异常
-
需要全局配置jdbcTypeForNull为null, 才能插入null。
springboot配置的值为: mybatis.configuration.jdbcTypeForNull= 'NULL' 根据mybatis源码的configuration类中有jdbcTypeForNull属性得知上述配置, 当然也可以看官网
2.4.8 mybatis用redis作为二级缓存的坑
-
控制台输出二级缓存Cache Hit Ratio一直未0.0
从如下几个方面检查问题: 1. 命名空间是否开启了二级缓存 2. mybatis的二级缓存是否配置为true 3. 实体类是否实现了序列化接口
2.4.9 mybatis @Select注解版本的坑
-
在mybatis支持将sql写在@Select注解中,eg
@Select("SELECT * FROM user WHERE user_id = #{userId}")但是这有个前提,就是保证mybatis的版本在3.4.3及以上。在今天遇到的坑是:
项目中依赖mybatis-spring-boot-starter 1.2.0版本你,其内置依赖的mybatis版本为3.4.2,而项目中使用到了**@Select注解**,导致项目启动一直失败,报错如下:
Caused by: java.lang.NoSuchFieldError: INSTANCE at com.baomidou.mybatisplus.core.MybatisMapperAnnotationBuilder.parseStatement(MybatisMapperAnnotationBuilder.java:341) at com.baomidou.mybatisplus.core.MybatisMapperAnnotationBuilder.parse(MybatisMapperAnnotationBuilder.java:155) at com.baomidou.mybatisplus.core.MybatisMapperRegistry.addMapper(MybatisMapperRegistry.java:86) at com.baomidou.mybatisplus.core.MybatisConfiguration.addMapper(MybatisConfiguration.java:122) at org.apache.ibatis.builder.xml.XMLMapperBuilder.bindMapperForNamespace(XMLMapperBuilder.java:408) at org.apache.ibatis.builder.xml.XMLMapperBuilder.parse(XMLMapperBuilder.java:94)追踪至MybatisMapperAnnotationBuilder类的parseStatement方法的341行后发现:
public class NoKeyGenerator implements KeyGenerator { /** * A shared instance. * @since 3.4.3 */ public static final NoKeyGenerator INSTANCE = new NoKeyGenerator(); // ..... }其内部调用的NoKeyGenerator.INSTANCE属性在3.4.3版本才生效,因此项目启动不起来。最终发现,它与@Select注解有关。因此解决这个问题有两个方案:一个是升级mybatis-spring-boot-starter为1.3.0版本,另一个是将@Select注解的功能移动到xml中去。为了不影响其他的模块(微服务项目),因此选择将@Select注解的功能移动到xml中去,完美解决这个问题。
2.5 MySQL
2.5.1 export database/table command
mysqldump -h host -u username -p database > target file
eg: 导出指定服务器(127.0.0.1)的test数据库到本地 test_local.sql 文件
mysqldump -h 127.0.0.1 -u root -p test > c:\test_local.sql
eg: 导出指定服务器(127.0.0.1)的test数据库的user表到本地 test_user.sql 文件
mysqldump -h 127.0.0.1 -u root -p test user > c:\test_user.sql
2.5.2 import database/table command
mysql --default-character-set=utf8 -h host -u username -p database > source file
eg: 将c盘根目录下test数据库的sql文件test_local.sql 导入本地test_local数据库
mysql --default-character-set=utf8 -u root -p test_local < c:\test_local.sql
或者登录到mysql(登录时需指定与sql文件同编码格式)并指定db 使用source命令
eg: mysql --default-character-set=utf8 -u root -p test_local
source c:\test_local.sql
eg: 将c盘根目录下的test_user.sql表导入本地test_local数据库user表
mysql --default-character-set=utf8 -u root -p test_local user < c:\test_user.sql
或者登录到mysql(登录时需指定与sql文件同编码格式)并指定db 使用source命令
eg: mysql --default-character-set=utf8 -u root -p test_local
source c:\test_local.sql
ps: --default-character-set=xxx 编码格式具体根据导出的db时选择的编码一致
2.5.3 mysql压缩版本()启动步骤
A. 配置mysql bin目录的环境变量
B. 执行mysqld --initialize-insecure --user=mysql (若执行时报xxxx120.dll文件不存在, 则需下载vcredist_x64.exe并安装)
C. 执行mysqld --install -> 安装服务
D. 执行net start mysql -> 启动服务
E. 默认用户名是root 无密码
2.5.5 存储过程
-
语法:
DELIMITER $$ DROP PROCEDURE IF EXISTS testProc2$$ CREATE PROCEDURE testProc2() BEGIN DECLARE username INT; DECLARE done INT DEFAULT 0; -- 定义一个done变量, 用来判断cursor是否继续循环 DECLARE my_cur CURSOR FOR SELECT `name` FROM `info`; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true; -- 如果游标FETCH NEXT无数据了的话, 那么就会设置done为true OPEN my_cur; FETCH my_cur INTO username; WHILE(NOT done) DO INSERT INTO user_info(username) VALUES(username); FETCH my_cur INTO username; END WHILE; CLOSE my_cur; END; $$ DELIMITER ;注意:
- 存储过程内定义的变量尽量不与需要操作的表的字段一致, 否则会将表中的字段的值填充到变量中.
- 一般使用存储过程的场景为:
- 需要频繁操作同一个sql语句. eg: 在权限表中, 每添加一个权限就需要将该权限与超级管理员关联起来. 此时可以创建一个将权限关联至超级管理员的存储过程
- 当更新表字段需要同一个表中的字段作为条件时(mysql会报错
#1093 - You can't specify target table 'xxxx' for update in FROM clause).
意思就是: 不能先select出同一表中的某些值,再update这个表(在同一语句中)
当然也可以采用嵌套子查询的方式解决, 即将select出来的结果当作一个视图, 再将视图作为条件更新表字段
2.5.6 DML和DDL概念
- DDL(DATA DEFINITAION LANGUAGE 数据定义语言): 使用范围: 对database, table有操作 eg: ALTER DROP CREATE
- DML(DATA MANIPULATION LANGUAGE 数据操纵语言): 使用范围: 对数据的操作 update,create,insert,delete,存储过程, 视图等等
2.5.7 mysql连接数不够
-
背景: 当整个团队集体开发某个需求时, 通常会选择一个人的db作为服务器db, 此时容易造成数据库连接池不够
解决方案:-- 查看数据库最大连接数 SHOW variables LIKE '%max_connections%'; * 方案1: -- 重新设置全局最大链接数变量 SET GLOBAL max_connections=1024; 但,这种方式在重启mysql服务时就会失效 * 方案2: 修改mysql配置文件my.cnf,在[mysqld]段中添加或修改max_connections值: max_connections=1024
2.5.8 flyway
2.5.9 mysql sql优化
-
前提: 首先得找出哪些sql需要被优化
步骤: 1. 开启慢查询sql日志功能: SET GLOBAL slow_query_log = 1(可提前查看是否开启: SHOW VARIABLES LIKE '%slow_query_log%'); 2. 设置慢sql记录的阈值: SET GLOBAL long_query_time = 2;(查询超过两秒的sql都会记录到日志中去) 注意: 可能设置后执行 SHOW GLOBAL VARIABLES LIKE 'long_query_time'; 不会看到修改后的结果, 此时需重新开启一个连接才能看到 3. 设置日志存储位置: SET GLOBAL slow_query_log_file = 'c:\\mysql-slow.log';(或者使用默认的: SHOW VARIABLES LIKE '%slow_query_log_file%') 4. 查看慢查询日志 5. 统计有多少条慢sql: SHOW GLOBAL STATUS LIKE 'slow_queries'; -
使用Explain分析sql
语法: EXPLAIN SQL语句Explain的具体分析可参考: https://www.cnblogs.com/dwlovelife/p/11110215.html
2.5.10 mysql5.7 官方镜像设置支持存储中文及数据持久化
-
自己修改镜像
根据官方提供的内容()可知,mysql 5.7版本镜像的配置文件位于/etc/mysql/mysql.conf.d目录下 于是我们启动容器,将容器中/etc/mysql/mysql.conf.d目录下的文件copy至宿主机, 1. 运行容器: => 若本地无此容器,则先从镜像仓库中下载 docker run --name mysql --rm -it -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root mysql:5.7 2. 进入容器查看/etc/mysql/mysql.conf.d目录下是否有配置文件 docker exec -it mysql bash ls /etc/mysql/mysql.conf.d => 执行完上述两个命令后可以发现/etc/mysql/mysql.conf.d目录下确实有mysql.conf文件 3. 将配置文件移动到宿主机上 若第二步骤进入了容器,可使用exit命令退出容器,然后执行如下命令 mkdir -p /mysql/conf docker cp mysql:/etc/mysql/mysql.conf.d /mysql/conf/ => 执行完这两命令可以发现,在宿主机的/mysql/conf目录下已经有了mysqld.cnf文件 4. 修改/mysql/conf/mysqld.conf文件 vim /mysql/conf/mysql.conf.d/mysqld.cnf 在[mysqld]节点下新增 character-set-server=utf8 5. 将mysql存储数据文件夹挂载到宿主机,保证数据持久化 mkdir -p /mysql/data 6. 使用如下命令重启镜像 docker stop mysql docker run --name mysql -it -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -v /mysql/conf/mysql.conf.d/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf -v /mysql/data:/var/lib/mysql mysql:5.7 -
使用自己修改后的镜像
基于docker hub mysql:5.7镜像改造,只在配置文件/etc/mysql/mysql.conf.d/mysqld.cnf中添加了character-set-server=utf8配置docker pull registry.cn-hangzhou.aliyuncs.com/avengereug/mysql:5.7
2.5.11 mysql(5.7.23)离线安装在linux(非docker镜像)
-
官网下载linux通用版本:
# 下载地址 https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -
将压缩包移动至linux中
-
解压缩并重命名
tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz \ mv mysql-5.7.31-linux-glibc2.12-x86_64 /usr/local/mysql -
创建mysql用户和mysql专用文件夹(为了保证关于mysql的文件只允许mysql用户来修改)
useradd mysql && mkdir -p /data/mysql && chown mysql:mysql -R /data/mysql -
创建mysql配置文件,并填充内容
vim /etc/my.cnf ## 内容如下 [mysqld] bind-address=0.0.0.0 port=3306 user=mysql basedir=/usr/local/mysql datadir=/data/mysql socket=/tmp/mysql.sock log-error=/data/mysql/mysql.err pid-file=/data/mysql/mysql.pid #character config character_set_server=utf8mb4 symbolic-links=0 -
初始化mysql服务(此步骤执行完,会在/data/mysql文件夹内生成mysql核心文件)
/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql/ --datadir=/data/mysql/ --user=mysql --initialize -
查看mysql密码
cat /data/mysql/mysql.err | grep password -
添加mysql环境变量(也可以使用软连接)
vim /etc/profile # 在最后一行填充如下代码 export MYSQL_HOME=/usr/local/mysql/ export PATH=$PATH:$MYSQL_HOME/bin # 更新环境变量 source /etc/profile -
将mysql添加服务并设置开机自动启动
# 挨个执行如下代码 cp /usr/local/mysql/support-files/mysql.server /etc/rc.d/init.d/mysqld chmod +x /etc/rc.d/init.d/mysqld chkconfig --add mysqld -
启动mysql服务
service mysqld start -
登录mysql
# 需要注意,这里会提示输入密码,将上述第7步看到的密码填充至此即可 mysql -u root -p -
登录mysql重设密码(如果想使用默认密码,可忽略此步骤)
set password = password('root'); -
配置远程连接
# 在登录mysql命令行中挨个执行如下命令 grant all privileges on *.* to 'root'@'%' identified by 'root'; flush privileges;
2.5.12 开发精度问题
- 在MySQL中bitint类型的值已经不能用Long类型的来装了,会出现精度丢失的问题,此时应该改为String类型来装
2.5.13 MySQL不走索引的坑
- 在MySQL中有设置一个varchar类型的字段的索引,但是在查询的时候,传入的却是数字类型,因此不会走索引。因此,在判断是否走索引时,也需要考虑下类型是否匹配。类型不匹配的字段查询,就算字段有索引,也不会走索引的,因为MySQL底层会做类型转换
2.5.14 mysql的可重复提交事务的特点以及引来的坑
- 在可重复提交事务的事务隔离级别中,若需要更新同一条的数据时,第一个事务隔离级别拿到锁后,迟迟没有提交,第二个事务则会等到第一个事务提交后才能继续往下执行。
- 在公司的一种业务中:分布式锁和mysql的事务锁互斥了,等到分布式锁到了释放锁的时间才提交事务,导致一些dubbo调用直接超时。具体的案例后续再细说。
2.6 Elasticsearch
2.6.1 linux构建es的坑
1. es目录不能在 root下或root的子目录下
2. 需要添加JAVA_HOME环境变量 (/etc/profile文件)
3. 需要添加用户组, 并添加普通用户, 并给普通用户设置es文件夹的使用(可读)权限 chown -R 用户组:用户 es文件夹目录
4. 必须使用普通用户启动elasticsearch(使用'su 用户' 命令切换用户)
5. 根据官网提示, 因为elasticsearch是使用java编写的, 至少需要java1.8版本支持, 最好使用java1.8.0_131版本
6. 服务器内存小的机器, 需要修改elasticsearch的config/elasticsearch.yml文件修改对内存大小 -Xms128 -Xmx512m (其实就是启动java程序限制了堆内存最小值和最大值)
7. 修改config文件夹下的elasticsearch.yml文件 自定义配置文件中的cluster.name(建议直接去掉前面的注释), node.name(建议直接去掉前面的注释), netword.host
(建议使用0.0.0.0, 该配置会允许外网访问), http.port(建议直接去掉前面的注释)等配置
8. 配置运行时环境内存大小:
服务器运行内存比较小的 => 修改config文件夹下的jvm.options文件, 只指定最小堆内存-Xmx512m 最大堆内存设置去掉.
编辑 /etc/security/limits.conf文件, 修改(此文件修改后需要重新登录用户才会生效)
* soft nofile 65535 -> * soft nofile 65536 (限制线程同时打开文件数)
=> 注销重新登录后 输入命令验证是否生效:
ulimit -Hn, ulimit -Sn
* hard nproc 4096 -> * hard nproc 4096 (限制同时开启线程的最大数)
=> 注销重新登录后 输入命令验证是否生效:
ulimit -Hu, ulimit -Su
具体可参考 https://www.cnblogs.com/yesuuu/p/6962340.html
编辑/etc/sysctl.conf 追加以下内容: vm.max_map_count=655360 保存后运行 sysctl -p 命令检验是否添加成功
9. es搭建环境内容太小、线程数太小等常见问题: https://www.cnblogs.com/zhi-leaf/p/8484337.html
10. logstash版本要与elasticsearch版本一致
2.7 Redis
2.7.1 手动暂时性的设置密码
config set requirepass 1234
- 一般不推荐这样做, 推荐直接修改配置文件
2.7.2 redis配置远程支持连接
- 配置文件中,network中的修改 bind: 0.0.0.0
2.7.3 RDB机制
-
Redis是基于内存的,一般存在内存的数据,我们把应用关闭后,数据就不见了,而redis能做到持久化的原因是因为
它将持久化的数据转成RDB(内容是二进制)文件存在硬盘上了,当redis内部执行shutdown命令或者执行save/bgsave
命令时就会将RDB里面的数据重新加载到内存中了。
那么我们是如何保证RDB里面的数据是最新的呢?这就跟触发RDB机制有关了,
我们可以手动执行save(阻塞)/bgsave(非阻塞)命令、也可以在配置文件中配置相关内容,比如说redis的默认配置:
save 900 1 // 900s 内有一个数据进行更改
save 300 10 // 300s内 有10个数据进行更改
save 60 10000 // 60s内有10000个数据进行了更改,
当满足上述条件后,redis的rdb操作将被触发。
此时redis会fork出一个子进程,专门来做数据持久化,将数据首先写进一个临时文件中(文件名: temp-当前redis进程ID.rdb),
后续再把数据写入RDB文件。因为redis是线程的,所以fork出的子进程并不会干扰主进程的操作,相当于是异步持久化。
这样就达到了redis数据持久化的功能。ps:若想让redis引用其他的rdb文件,需要修改配置,并且将rdb文件与启动redis的目录一致。
2.7.4 AOF机制
-
什么是AOF机制?
在使用redis时可能会出现这样一种场景,当应用在进行写操作时,并没有达到RDB的默认触发机制(eg: save 900 1)以及没有手动调用save/bgsave命令。此时若停电了!那么在上一次同步RDB到未触发RDB机制的过程中对数据的修改将会丢失。所以此时要利用redis
中的AOF机制来处理。redis的AOF机制,它可以将对数据的增删改操作记录在一个文件中,当出现上述断电的情况时,我们可以使用AOF机制,将记录过的命令重新再运行一遍,这样数据就恢复了! -
如何开启AOF机制?
配置文件中配置: appendonly为yes,默认的aof文件名为: appendonly.aof -
如何触发AOF机制?
配置文件中分别有如下三种:
appendfsync always --> 每次发生增删改操作时,就把命令记录到aof文件,会影响redis性能,但是安全
appendfsync everysec --> 每秒记录一次,比较安全,但有可能会丢失1s以内的数据
appendfsync no --> 由操作系统来决定什么时候进行记录,无法保证是否做了持久化
所以,一般使用的是appendfsync everysec的配置来进行aof触发机制 -
如何运行的?
若按照appendfsync everysec的配置进行aof触发机制的话,当执行增删改操作时,会在配置文件中的dir配置的路径下生成一个
appendonly.aof文件,里面保存的一些redis识别的内容。 -
注意事项: 若AOF机制开启了,那么redis在重启的时候,将会从aof文件中加载,rdb文件将无用
所以若AOF和RDB机制同时且有appendonly.aof文件,那么redis将不会读取RDB文件。
若appendonly.aof文件文件不存在,则会读取RDB中的文件
2.7.5 RDB和AOF如何取舍
-
根据各自的特点来决定:
RDB是做持久化的,虽然会fork一个子进程来做持久化操作,但是会影响到redis服务器的性能,当redis负载量非常大的时候,这难免
也是一个影响性能的操作。而且它只能备份某个时间点的数据,若在备份过程中有一些额外的原因导致系统故障,则未备份的部署数据
可能会丢失,如果比较倾向于实时性的持久化操作,不建议用RDB。RDB比较适合灾难恢复,可以采用异地容灾的操作,这样至少能保证
一大部分的数据AOF是将所有的增删改命令以追加的方式写在aof文件中,通过redis的配置来决定aof同步的频率。当aof机制打开时,redis在重启时
加载的是aof文件。aof还能支持重写瘦身,会分析命令,比如记录了set a 1; set b 2这两条命令,当使用文件重写瘦身后,aof文
件只会存储set a 1 b 2这一个指令.但是一般是这两种机制都加上,基本上在硬盘不坏掉的情况下,数据基本不会丢失
2.7.6 使用redis作为分布式锁的原理即存在的问题
-
因为redis的单线程特性,所以它的一些命令都是具有原子性操作的。
而使用redis作为分布式锁的主要核心就是setnx(set if not existes)命令 + expire命令,
若key存在,则无法再set,若set成功,然后在执行完逻辑后,将key设置过期时间。
但是这样会有一个问题: 就是setnx和expire时两个操作,不具备原子性,也许我的应用在获取锁
还没有来得及设置过期时间应用程序突然挂了,那这个锁就一直卡到那里了。为了解决这个问题,
redis中存在一个setex(set expire)命令, 这个名字把上述setnx + expire的非原子性问题
给解决了。但是又出现了一个问题: 万一锁过期了,但是业务逻辑还没执行完,怎么办?
所以就算使用setex指令来使用也会存在问题,虽然redisson提供了一些解决方案,创建锁的时候
添加定时任务去监控这把锁。但是还需要额外额外开定时任务,比较浪费。要比较好的来使用redis作为分布式锁还要结合lua脚本(可以将非原子性的操作变成原子性操作。
比如上述的: setnx + expire)
我们可以使用set redisLock 随机value nx ex 1000来创建分布式锁(其中过期时间可以稍微长一点),
使用此命令保证了互斥性和非死锁性。
然后再使用lua脚本去删除锁(先获取锁的值是否和随机的value一直,然后再删除)
这里面为什么要用到随机value? 因为有可能其他客户端会删除这个key,但此时这个key的value并不是自己
设置的,这就保证了我创建的锁,只有我知道它的value,进而我根据它的value来删除,那就肯定只有自己
才能删除了。同时,若程序执行到删除锁的步骤,突然挂了,也不会出现死锁的情况,因为设置了过期时间,
所以这个过期时间很重要,需要权衡业务逻辑的执行时间
2.7.7 使用redis做消息队列
- 可以利用redis的list数据接口的特性,在redis中它的数据结构是一个linkedList(链表), 且支持左、右
插值。
所以我们可以使用生产者将消息lpush至list中,然后消费者rpop出来消费
2.7.8 redis五种数据类型使用场景
- string
string的使用场景特别多,可以使用incr命令的一致性来完成点赞操作、普通的缓存功能比如缓存认证token等等 - lsit
list的使用场景特别多,因为它是链表的数据结构以及redis提供的lpush和rpop的api,可以使用list作为消息队列。
若数据消费者比较多可以使用延迟的brpop命令阻塞的消费信息。
同时基于它的lrange命令,我们可以将经常访问的翻页功能(文章列表、粉丝列表等等)放入redis中,提高翻页查询效率
同时,应用的首页可以使用list作为热点数据 - hash
hash就和java中的map一致,我们可以把一些缓存的对象存入hash中,若下次只想获取对象中的某一个属性时,使用hash就可以
取出来(这比把对象序列化成jsonstring,然后再反序列化拿它的字段好太多)。 - set
set是无序的,可以使用它的一些交集、差集、并集来做一些操作。 - sortset
可以排序,比如首页中的热点新闻、热点商品。我们可以符合条件的数据找出来,然后使用sortset进行排序,这样的话可以省去
db中的排序压力。
2.7.9 Redis主从集群
-
master节点: 关闭RDB、AOF机制,这些功能由从节点去做就好了。修改当前对应的pid、日志文件名即可、可
设置密码(设置的话,从节点要保持一致)。 -
slave节点:开启RDB、AOF机制,将对应的pid、日志文件名改成对应节点能识别的名字即可、
设置replicaof masterIp masterPort,设置masterauth(如果master配置密码的话)。启动即可 -
可以在任意一台节点中使用
info replication命令查看集群信息,包括当前节点的角色、偏移量、runid等等
若想横向扩容,新增一个配置文件,并使用此配置文件启动即可。 -
注意点: slave节点第一次连接master节点时会进行全量更新,master节点虽然把rdb机制关了,但是此时还是会
进行后台save,即bgsave命令。除此之外,master节点还会新增缓冲区(缓冲区大小默认1m,可配置)来临时
存储master节点的写操作。若途中对master节点缓冲区的空间写满了,那么它会将最开始执行的那个命令对应的
结果给移除(所以,缓冲区它是一个队列)。后续的增量同步,取决于master节点和slave节点的偏移量。可以动态扩容,但是动态扩容设置的主节点信息都会在下次重启后丢失。
2.7.10 哨兵模式
- 参考链接:哨兵模式相关总结
2.7.11 高可用集群模式
- 参考链接:高可用集群模式总结
2.7.12 redis中的lua脚本
-
一个案例对应一个lua脚本
案例: 有一个负载均衡的轮询算法,我们使用redis来实现。正常情况下,同一个实例的节点只有3个,但可能出现动态扩容或缩减的情况,因此,实例可能增加或减少。 基于redis来实现这个功能的话,我们把所有的实例放到redis的list中,负载均衡一次,我们就从队列中取一个实例,然后将它返回,最后再把它放到队列末端去,其对应redis的操作就是:负载均衡一次 <=> rpop一次,将实例再次放入队列中 <=> lpush一次。因为我们得保证 lpush和rpop以及将rpop出队的元素返回 这三个操作是一个原子性操作。因此我们选择了lua脚本。但可能会出现扩容和缩容的情况,因此我们得动态的添加队列中的实例或减少队列中的实例,并且这一操作也是原子性的。 -
针对于初始化队列的lua脚本:
private static final String INITIALIZE_QUEUE_SCRIPT = "if (redis.call('exists', KEYS[1]) == 0 or redis.call('LLEN', KEYS[1]) ~= ARGV[1] ) then \n" + " redis.call('DEL', KEYS[1]) \n" + " table.remove(ARGV, 1) \n" + "return redis.call('LPUSH', KEYS[1], unpack(ARGV)) \n" + " end "; // 调用处,其中keys是一个List的list,args也是一个List jedis.eval(INITIALIZE_QUEUE_SCRIPT, keys, args)的list。keys的长度为1,args的长度为5(其中第一个参数为当前放入队列中的数量) 上述的lua脚本主要是做一件事:初始化一个队列。其中会传入keys和args。keys中存储的是队列的名称,只有一个元素。args中包含要放入队列的数量,以及每个元素。eg:我要往队列中放入:1,4,15三个实例。那么,args的值为:3,1,4,15。第一个数字3表示接下来要往队列中塞3个元素。
其主要功能为:当队列不存在或者 当前要放入队列的实例与redis中的队列长度不一致,那么则重新初始化队列(删除队列再初始化队列)。其中一个特殊点就是:args中的第一个元素其实仅仅是用来判断当前要放入的实例与redis现存的实例个数是否一致,因此在实际初始化队列时,要把它给移除,即lua脚本中的**table.remove(ARGV, 1)**代码,它表示:移除ARGV数组中的第一个元素。
-
针对于入队出队的lua脚本:
private static final String OBTAIN_ELEMENT_SCRIPT = "local element = redis.call('RPOP', KEYS[1]) \n " + "if (element) then \n " + " local lpushOperate = redis.call('LPUSH', KEYS[1], element) \n " + " if (lpushOperate) then \n " + " return element \n " + " else \n " + " return null \n " + " end \n " + "else \n " + " return null \n " + "end \n ";首先,先出队,然后把出队后的参数拿到手,再执行入队操作,最后再将出队后的参数返回。
2.8 Maven
2.8.1 install maven仓库找不到的jar包
mvn install:install-file -Dfile=需要install到本地仓库的jar包路径 -DgroupId=jar包的groupId -DartifactId=jar包的artifactId -Dversion=jar包的版本 -Dpackaging=jar
eg: 手动安装```c:\common-auth-0.0.1-SNAPSHOT.jar```
mvn install:install-file -Dfile=c\common-auth-0.0.1-SNAPSHOT-core.jar -DgroupId=com.cloud -DartifactId=common-auth -Dversion=0.0.1-SNAPSHOT -Dpackaging=jar
2.8.2 maven profiles集成springboot build多环境
在父(根)pom.xml文件添加如下配置:
<profiles>
<profile>
<id>localid>
<properties>
<conf.active>localconf.active>
properties>
<activation>
<activeByDefault>trueactiveByDefault>
activation>
profile>
<profile>
<id>devid>
<properties>
<conf.active>devconf.active>
properties>
<activation>
<activeByDefault>falseactiveByDefault>
activation>
profile>
profiles>
<build>
<resources>
<resource>
<directory>src/main/resourcesdirectory>
<excludes>
<exclude>confexclude>
excludes>
resource>
<resource>
<directory>src/main/resources/conf/${conf.active}directory>
resource>
resources>
build>
---------------------------------------------------------------------
在子模块中的pom.xml文件添加如下配置:
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
2.8.3 maven pom文件scope解析
- compile: 缺省值,适用于所有阶段,会随着项目一起发布。
- provided: 目标容器已经提供了这个artifact。所以在打包的时候该jar包不会被打进去。
- runtime,只在运行时使用,如JDBC驱动,适用运行和测试阶段。
- test,只在测试时使用,用于编译和运行测试代码。不会随项目发布。
- system,类似provided,需要显式提供包含依赖的jar,Maven不会在Repository中查找它。
2.8.4 maven项目打包类型
<packaging>pompackaging> -> 父类型都为pom类型
<packaging>jarpackaging> -> 内部调用或者作服务使用, 打成jar包
<packaging>warpackaging> -> 需要部署的项目
- maven父项目指定了version版本号后, 在依赖的子项目中,加入parent标签, 并将父模块的groupId、artifactId、version、relativePath指定后, 若子模块没有指定版本号, 则会继承父类的版本号. 若指定了, 则使用自己的, 否则使用父类的
2.8.5 maven代码混淆插件导致spring 创建的bean找不到类型
后台代码使用maven build代码混淆后, 最好是在spring bean 容器创建bean的时候指定名称, 并在注入时使用同样的名称,
尤其是配置类, 在为配置类创建bean时指定bean的name(eg: @Componet(value="test")), 在使用
@Resource注解时要指定name为test(eg: @Resource(name="test")),
否则可能会遇到这种情况: Bean named 'XXX' is expected to be of type 'TTT' but was actually of type 'TTT'
若使用@Autowired注入属性, 不会出现上述问题
2.8.6 搭建maven私服
-
使用Nexus搭建私服
-
背景: 某些公司使用局域网, 不能访问外网, 此时在一台能连接外网的机器中搭建私服, 开发者只需要将maven拉取仓库的地址指向它既可。
-
步骤:
2.1. 参考此教程, 只需完成到创建一个maven仓库步骤既可, 需注意一点, Nexus开放的端口为8081, 第一次进入页面点击右上角的Sign in, 并按照页面的提示进行操作(这里会告诉我们用户名是什么, 密码存在服务器的哪个文件夹上, 并且会让你再次设置密码)
2.2. 配置Maven配置文件settings.xml, 指定servers地址和mirrors<servers> <server> <id>my_repositoryid> <username>adminusername> <password>2.1步骤所说的再次设置的密码password> server> servers> <mirrors> <mirror> <id>tm_repositoryid> <mirrorOf>*mirrorOf> <name>TianMa Nexus Repositoryname> <url>http://nexus服务器ip:端口(默认8081,可以自己设置)/repository/创建的仓库地址/url> mirror> mirrors>2.3. 使用idea使用该配置文件对应的maven
-
注意: 该仓库只是
hostd类型, 并没有设置代理, 所以若此仓库中无jar包, 那么就下载不下来, 若想将该仓库作为中转方,
当仓库中也没jar包时再从maven仓库中去下载, 则还需要添加一个代理仓库. 具体的可以搜一下相关资料或看官方文档.
-
2.8.7 maven编译报错
-
MAVEN打包的`parent.relativePath points at wrong local POM问题
解决方法1: 先将parent中的modules注释掉,再进行打包。等parent模块安装完后,再重新打包 解决方法2:在子pom文件中,配置属性
2.8.8 maven打出的jar包运行指定含有main方法的类
-
maven打出的jar包运行指定入口类(有可能一个jar包中有多个类中有main方法)
mvn -Dexec.mainClass=包含main方法的类的全限名 exec:java
2.8.9 普通java maven项目打包插件(将依赖的jar包也打进去)
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>2.4.1version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>com.eugene.sumarry.entry.ApplicationmainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
2.9 Git
2.9.1 回退版本
- git reset --hard HEAD~N 或 git reset --hard commitId~
- git reset --soft HEAD~N 或 git reset --soft commitId~
区别:
1. --hard回退到指定版本, 并直接将当前版本与回退版本之间的commit给忽略掉(输入git status命令只会看到落后版本的提示)
2. --soft回退到指定版本, 会将当前版本与回退版本之间的commit给缓存到寄存区(输入git status命令可以看到所有回退的所有改动)
解释下 '~':
在git中HEAD表示的是当前版本, 而~表示的是包含指定版本(CommitId), 所以HEAD~的意思就是包含当前版本(CommitId)
但同时~后面可以接数字, 表示包含当前版本的前面N个版本, eg HEAD~2 表示包含当前版本的前面2个版本
2.9.2 查看分支树
git log --graph --pretty=oneline --abbrev-commit
2.9.3 只查看commitId和comments的背景
在自动化部署时, 通常会将最新的commitId(前6位)作为镜像的tag, 若需要确定自己的代码有没有上环境时, 可以根据镜像的tag和commit来确认,
但git log命令呈现的东西太多, 提供给我们想要的信息(commitId)太少, 所以可以使用如下命令查看更多的commitId
git log --pretty=oneline, 当然也可以使用linux管道流关键字(grep)进行commit定位 git log --pretty=oneline | grep 112233
2.9.4 cherry-pick和merge的区别
主要区别在于整个项目流水线:
1. 使用cherry-pick的方式将某个提交应用到当前分支和在当前分支修改代码提交代码一致.
2. 使用merge的方式在流水线会多一个分支.
[外链图片转存中…(img-9tIfrox7-1617418951521)]
2.9.5 合并commit
背景: 合并commit有益于管理整个项目, 对于一个issue, 一个小模块应该是只包含一个commit, 这样能清晰的看到代码的改动
命令: git rebase -i commitId~ 或 git rebase -i HEAD~N
与回退版本的操作差不多, 选择需要合并的commitId即可
在rebase界面根据页面的提示操作即可
完成rebase操作后需要强制push代码, 所以此操作有风险, 一定要本地的代码是最新的.
究极合并commit命令: 我们通常是一个bug只能有一个commit的,那么当我们已经把merge request发出去了,然后被leader
review后打了回来,要改点东西。这个时候改完后要重新提交呀,按照规范,我们需要把改动和上一次commit合并。按照
传统git rebase的做法,我们还需要些commit内容、还需要指定使用哪一个内容。。。 太麻烦!使用如下命令即可解决
这种情况情况: git add . && git commit --amend --no-edit
2.9.6 git reset HEAD~ 带来的坑
首先我想操作的是想把某个被add进去的文件给reset回来, 结果操作成 git reset HEAD~ 了
最后执行的结果就是, 将我本地的改动和当前分支的最新的一次提交的改动给合并了. 导致分支的commit
回退到最新提交的上一个版本. 所以此时我本地的改动乱了.
为啥会出现这样的情况?
首先, HEAD关键字是分支上当前的指针, git reset HEAD 命令后面如果接的是文件, 效果是能和我的初衷一样的,
但是如果后面加的是~的话, 那么就会将某次提交的改动回退.而正巧 HEAD~ 和HEAD~1 是一样的(即
HEAD~默认会在~后面加一个数字1), 所以 git reset HEAD~n 比 git reset --soft commitId~/HEAD~n 更强.
因为前者是将commit回退 并将改动与本地的改动合并. 而后者是将commit回退, 但是将改动放入寄存区(git add后的区域)
如果要将改动与本地的改动合并的话 还要多执行一个 git reset . 操作.
2.9.7 Github中提交的记录在Contribution中看不到
- 原因: 记录是提交了, 但是author与git中的用户名和邮箱不一致
- 解决方案:
- git log 查看命令找到想要在Contribution生效的提交
- 执行git rebase -i -p commitId~ => 与合并commit类似, 找到一个范围
- 进入修改页面, 将需要修改author信息的commit前面的pick修改成edit或者e
- 保存退出(windows: Esc + : + wq + 回车)
- 重新设置author信息: git commit --amend --author=“AvengerEug [email protected]”
包括用户名和邮箱 - 执行: git rebase --continue 完成当前commit信息的修改.
Notes:
若commitId和HEAD指针包含的commit较多
则需要重复执行 3-6步
- 若想支持以后的提交都能生效, 则需要全局配置git的用户名和密码
- 若想针对单个项目生效则在对应的仓库中执行如下代码:
git config user.name “xxxx”
git config user.email “[email protected]” - 具体可参考此
2.9.8 gialab保护分支, merge代码时指定某种角色才能merge
- project => setting => repository => Protected Branched => 选择需要保护的分支, 设置merge和push的角色
2.9.9 git patch功能
-
patch功能可以将每一个提交的改动打成一个patch文件, 也可以将领先于某个分支的改动打成patch
-
将领先于某个分支的改动打成patch
git format-patch -M origin/test-ci -
将某个提交及之前的提交都打成patch
git format-patch commitId~ -
应用patch, 应用当前目录下的所有patch文件
git am ./*.patch
2.9.10 git绑定多个push源, 实现同时push
- 命令格式: git remote set-url --add
- 命令: git remote set-url --push origin git@host:AvengerEug/test.git
当执行git push origin branchName时, 会同时往两个仓库push代码
2.9.11 git改变push源
- 可以实现从某个仓库中拉代码, 并push到另外一个仓库
- git remote set-url --add origin git@host:AvengerEug/test.git
当执行git push origin branchName时, 会push到自己设置的origin源
2.9.12 git以https协议push 防止多次输入密码方式
-
执行如下命令
git config --global credential.helper store
2.10 设计模式与应用
2.10.1 简单工厂 + java多态性完成订单流水操作
- 参考此项目
2.10.2 适配器模式 + 动态代理集成第三方类库, 完成日志记录操作
- 参考此项目
2.10.3 模板方法
- 参考此项目
2.10.4 观察者模式
-
参考此项目
-
spring的事件驱动模型就是基于观察者设计模式来的
2.11 jvm
2.11.1 通过jstatd的方式,使用jvisualvm远程查看java进程jvm情况
-
创建jstatd.all.policy文件
进入java安装路径的bin目录(eg: /usr/local/jdk/bin) 创建jstatd.all.policy文件,文件名可以任意,但是后缀必须为policy.并填充如下内容 grant codebase "file:/usr/local/jdk/lib/tools.jar" { permission java.security.AllPermission; }; -
执行如下命令启动jstatd进程
nohup jstatd -J-Djava.security.policy=jstatd.all.policy -J-Djava.rmi.server.hostname=192.168.111.153 -J-Djava.rmi.server.logCalls=true -p 2050 &解析:
其中
-J-Djava.security.policy=jstatd.all.policy需要指定jstatd.all.policy文件的路径
-J-Djava.rmi.server.hostname=192.168.111.153中的192.168.111.153需要在host文件中配置当前主机的真实ip(linux下可以使用hostname -i命令查看)
-J-Djava.rmi.server.logCalls=true表示打印日志
-p 2050表示jstatd进程占用2050端口,可以不加此参数,默认为1099
-
远程连接时,要注意远程服务器是否开放了对应的端口
2.12 消息中间件
2.12.1 在与第三方交互时消息中间件的使用
-
以调用第三方转账接口为例,详细说明使用消息中间件来其中的用处
假设存在这么一个业务: 账户A需要向账户B转账,因此要调用第三方银行的转账接口。按照常用的逻辑来讲,转账的业务是同步处理的,我们必须要依赖于第三方的转账接口的状态来决定当前的转账业务是成功还是失败。 在这样的case中,我们需要 1、上游服务调用支付平台转账接口 2、支付平台:查询账户A的信息 3、支付平台:查询账户B的信息 4、支付平台:调用第三方转账接口,等待接口 5、支付平台:根据第三方转账接口的返回值来决定这个转账业务是成功还是失败。 6、上游服务根据结果做对应逻辑处理 这样的case有一个问题: 在第三步的过程中,假设第三方转账接口因为各种原因(网络或其程序内部的原因),执行了40s才返回结果。而对于微服务项目而言,肯定会有熔断机制(防止服务雪崩)。 因此我们肯定会设置服务间调用的超时时间(比如:2s),那在这种情况下上游调用支付平台的转账接口肯定会触发熔断机制,然后抛出一个超时异常,上游服务根据超时异常 判断此转账的业务是失败的。但其实,第三方的转账接口其实是成功的(只是返回的比较慢。),也就是说在支付平台系统中,账户A向账户B转账的业务是失败的,余额也没有 进行任何的划分,但是对第三方而言,其实这比钱已经划分成功了!因此这是有问题的 为了解决这个问题,我们可以在调用第三方接口时,统一采用异步才做,并且对应的业务单据返回"处理中"状态,其执行过程如下所示: 1、上游服务调用支付平台转账接口 2、支付平台:查询账户A的信息 3、支付平台:查询账户B的信息 4、支付平台:异步调用第三方转账接口 5、支付平台:直接返回处理中状态 6、上游服务保存支付平台返回的状态 7、在第四步的异步线程中,异步线程需要同步等待第三方响应结果,并根据响应结果发送消息至消息中间件,支付平台与上游服务同时监听此消息,对转账业务状态进行更新。 因此,可以通过异步 + 中间状态的方案来进行优化
2.12.2 顺序消费的情况是怎么发生的?
-
消息的顺序消费问题要怎么样才会发生呢?目前来说存在这么一种情况:
在我们的支付业务中,当订单完成后,我们是需要进行分账的。只有状态为完成的订单才能申请退货。 本来业务侧发送的消息的顺序是:订单完成消息、订单退款消息 然后监听这个队列只有服务A的某个消费者,但由于服务A是集群部署的(有两个实例),然后在消费的过程中 实例1的消费者拿到了 订单完成消息 并处理业务逻辑,实例2的消费者拿到了 订单退款消息 并处理业务逻辑。 但由于实例1在处理订单完成消息时耗时比较长,且处理了一些逻辑耗时比较长,处理的一些数据已经达到了订单退款的要求了。此时实例2的消费者 已经将订单退款消息的业务逻辑给处理完了。 此时就出现了顺序不一致的问题。 -
如何解决这个问题呢?
针对上述的业务场景来说的话,因为处理的对象是同一个订单,其实可以为订单号加锁,保证一次只能处理一个消息。 假设实例1正在处理订单完成消息,此时实例2正在处理订单退款消息,由于加了锁,实例2的消息只能处理等待状态,等实例1处理完毕后,实例2才拿到锁 处理订单退款逻辑。如果实例2等待锁时间超时的话,可以发送一条延时消息,或者添加一条告警,后续由人工来手动触发订单退款消息。 假设实例2先拿到锁,正在处理,但我们的业务逻辑中,订单没有完成,此时处理退款也会失败的。此时的退款应该会写一个告警,由后续操作来触发。 上述情况是针对同一个主体来操作的,假设我们有这么一种情况: 业务侧发来的消息是:delete、update、add,虽然只有服务A监听了这个队列,但由于是集群部署(假设此时有三个实例)。此时很有可能因为每个实例的负载量不同,最终的执行顺序变成了:add、update、delete。 为了解决这种情况:我们一定要保证只有一个消费者,即只能有一个实例(不能集群部署),然后由一个实例去将这些消息落地(存入表中,标识当前消息要交给哪个业务侧去处理),再由对应的业务侧来处理这些数据。但这种解决方案能承载的并发量并不高。但没办法,因为要保证顺序性就必须要牺牲并发性,两者是互斥的。就算使用上述的锁机制,最终其实还是降低的并发性。
2.12.3 @RabbitListener底层实现原理
- 之前一直认为,@RabbitListener注解的底层实现原理是基于aop实现的,但实际上却是我错了。今天凌晨,生产环境上出了一个问题:消息消费失败,无法调用
private修饰的方法。通过问题定位后,发现是因为@RabbitListener注解修饰在了一个私有方法了。但很奇怪的时,这段代码以前一直没有发生过错误。但目前发生了错误的原因是因为我们对@RabbitListener注解做了aop操作,我们手动的消息落地了,将一些消费失败,抛了异常的消息落地了。正因为这一个操作,导致出现了异常。 - 原因是这样的:在未对@RabbitListener注解做aop操作时,@RabbitListener注解的底层是将所有的@RabbitListener注解标识的方式做了一层映射关系,消息服务器推送消息时,此时会将这个消息中绑定的队列找到对应消费消息的方法,然后根据之前保存的映射关系(保存了当前方法由哪个类来执行)来反射调用方法,其中内部还对私有方法做了处理,能够强制执行私有方法。而在产生问题的消费者中,它所处的类并没有实现某个接口,因此在对@RabbitListener注解做aop操作时,使用的是cglib代理,而cglib代理会忽略到private修饰的方法。而最终在映射时,指定了方法的执行对象为cglib生成的代理对象。而cglib生成的代理对象中并没有private修饰的方法,最终抛出了异常:Listener method ‘private void xxxxxxx(yyyyyyyy)’ threw exception
- 总结:通过这次生产环境的事故,我们发现了@RabbitListener底层的实现其实不是通过aop代理的,而是通过一个映射关系来处理的。当接收到消息时,根据消息中的队列来找到对应的消费者,进而根据早已经保存好的映射关系(@RabbitListener注解标识的方法由哪个类来处理)反射调用。而之前没有出现问题的原因是:原生的bean并没有被代理,内部还是存在private方法的,而经过代理后(cglib),它直接忽略了private方法,最终保存到映射关系中的结果为@RabbitListener注解标识的方法由代理类来处理,而代理类中无private修饰的方法,最终导致抛出异常。
2.13 Dubbo
2.13.1 服务消费者设置超时时间的坑
- 服务消费者要调用服务提供者的某个方法时,设置了请求的超时时间。比如20s,当请求时间超过20s时,消费者会中断线程,直接返回(相当于服务降级)。但是服务提供者实际上还是在执行方法。。并不是说消费者直接返回超时后,请求就没有执行了,这是不对的!
2.13.2 Dubbo RpcContext透传信息的坑
-
在使用Dubbo进行微服务开发时,可能需要将服务A的一些信息,传递到服务B中。这个时候有两种方式:
第一种方式:在服务B的接口中添加对应的参数,在服务A调用服务B时直接将参数写在服务B的参数签名处即可
第二种方式:在rpc调用时做一些手脚,如果是普通的http的话,我们可以把参数放在请求头中。如果是Dubbo微服务框架的话,我们可以使用Dubbo透传机制,即把参数放在RpcContext的attachments中,其底层就是基于ThreadLocal的map。使用方式为:
放值:RpcContext.getContext().setAttachment(key, value); 取值:RpcContext.getContext().getAttachment(key);但需要注意,里面的变量是基于线程而言的,如果服务A开了另外一个线程去透传信息的话,服务B是无法接收透传信息的。因为RpcContext.getContext()这段代码的含义就是获取当前线程所对应的RpcContext。而RpcContext.getContext().setAttachment(key, value);整段代码的含义就是将key和value放到当前线程对应的RpcContext中的map中去。这只是一个准备过程,后续在发起RPC调用之前,会拿到当前线程对应的RpcContext中的map信息填充到http中,然后在服务B中再从http中拿到对应的请求参数,完成透传。假设我们是在服务A中开了另外一个线程去透传信息的,那么RpcContext.getContext().setAttachment(key, value)的代码的作用就是将key和value放到另外线程对应的rpcContext中的map中去了。自然在执行rpc调用前获取不到透传信息,就无法将透传信息放到http中去了
-
同时,透传时,key的名称不能是小驼峰格式,下游服务将key序列化后,会把key全部变成小写,导致无法获取到透传信息的假象
2.13.3 Dubbo引入服务,若服务未注册到注册中心则报错
-
Dubbo引入服务,若服务未注册到注册中心则报错(比如A服务需要引入B服务,但是A服务部署了,B服务没有部署,则会报错)。报错信息:
No provider available from registry 127.0.0.1:2181 for service org.apache.dubbo.demo.DemoService on consumer 192.168.56.1 use dubbo version , please check status of providers(disabled, not registered or in blacklist).
2.13.4 为什么一定要在服务提供者中引用自己?
-
Dubbo的@Service注解做了两件事:
1、服务导出
2、将当前服务添加到spring容器中去
因此,在同一个服务提供者中,因为服务A要调用服务B(服务A和服务B在同一个服务提供者中),我们直接使用spring的@Autowired注解注入即可。那在这种情况下(两个服务都在同一个提供者中)会用@Reference注解引用服务呢?
1、在做单元测试时,如果我们写的一些dubbo过滤器指定是在 服务提供者 侧生效时,而此时我们要测试过滤器的一些功能,这个时候我们就可以使用@Reference注解来引用同一个提供者的其他服务了。此时我们就是在模拟消费者请求服务提供者的逻辑
2.13.5 Dubbo过滤器一定要使用配置@Activate注解中的order属性来控制顺序吗
- 看情况,如果过滤器是我们自己编写的,我们可以修改spi文件中每个过滤器的配置顺序(默认:配在下面,优先被执行)。但如果我们要添加同一个类型的过滤器,已经有第三方框架(jar包)也提供了,此时我们无法保证第三方框架的spi文件和我们自己开发的spi文件哪个优先执行。因此,此时就要使用order属性来控制顺序了
2.14 MongoDB
2.14.1 索引的TTL机制
- MongoDB支持为索引数据创建过期时间,具体参考官方文档:TTL Indexes
- 其主要工作原理为:为索引的数据添加一个过期时间,从新数据被添加的那一刻开始算起,过了设置的时间后,数据会被清除。它的过期时间设置比redis更强大,redis的过期时间是把整个key给删除了。而MongoDB的过期时间机制可以精确到索引中的数据。
2.14.2 创建索引的异常
-
在spring集成MongoDB开发是,我们可以在代码中为某个字段添加索引,其主要就是**@Indexed**注解的功效。但是mongodb在创建索引时,会定义索引。因此同一个创建索引的代码反复执行不会出现任何问题。但如果创建索引的代码中有变化,比如:我为字段a创建索引时,指定了过期时间。然后在第二次创建时没有指定过期时间,此时就会抛出如下异常:
com.mongodb.MongoException: Index with name: code already exists with different options因此,在出现这个异常时,我们需要确定索引是否需要重新被定义?如果需要重新被定义则需要把原来的索引给删除,再重新创建。
2.15.3 mongodb条件查询null的两种情况
-
mongodb是非关系型数据库,我们在实际开发时,经常会遇到为某个实体添加一些字段(eg:添加username字段)。这样的话就会导致:新保存的实体字段是存在的, 但是旧数据是灭有新增加的字段的。因此,我们在做查询时,为了兼容,可能会考虑到字段不存在的情况,需要判断这个字段是否存在,如下所示:
# 判断这个字段是否存在 db.getCollection("user").find({ "username": { "$exists": false}})有时候,我们需要查找年龄为18且(username为avengerEug或username为null)的用户,因此我们很容易写出这样的sql:
# 查询年龄为18的用户,其中username为null或者为avengerEug的用户 db.getCollection("user").find({ "age": 18, "$and": [ { "$or": [ { "username": { "$exists": false}}, { "username": null} ] } ] })针对这种情况,其实有更好的解决方案.
-
如下sql的两种含义:
# 使用如下sql查询出来的数据会有两种情况 # 1、username字段不存在 # 2、username存在,但它的值为null db.getCollection("user").find({ "username": null})因此最开始的sql我们可以优化成如下表现形式:
# 查询年龄为18的用户,其中username为null或者为avengerEug的用户 db.getCollection("user").find({ "age": 18, "username": null })使用此种方式,间接清晰了很多,也增加了sql的可读性。
-
因此,在mongo中,若查询条件为is null的情况,筛选出来的数据可能包含字段不存在和字段存在且值为null的情况
三. DevOps
3.1 Docker
3.1.1 搭建远程本地仓库
-
下载镜像registry: docker pull registry => 默认在registry.hub.docker.com 中拉去镜像
-
运行镜像: docker run -itd -v /data/registry:/var/lib/registry -p 5555:5000
–restart=always -name registry registry:latest命令解析: -itd: 在容器中打开一个伪终端进行交互操作, 并在后台运行 -v 把宿主机的 /data/registry目录绑定到容器的/var/lib/registry目录(该目录是registry容器中存放镜像文件的目录), 来实现数据持久化 -p: 映射端口, 宿主机的5555端口映射到容器的5000端口 --restart=always: 重启策略, 假如容器异常退出会自动重启 --name registry: 自定义容器名为registry registry:latest: 镜像名和tag名 -
运行registry镜像成功后, 可以在另外一台机器创建镜像并push到该仓库中
-
在另外一台机器中(最好是linux),
创建Dockerfile文件, 内容如下:
FROM ubuntu
CMD echo ‘Hello docker!’并在与Dockerfile文件同级目录下执行
docker build -t 47.100.26.16:5555/project/vue-docker:v1 .(命令中的.非常重要,它是一个上下文的路径,假设DockerFile中有一个指令为ADD test.jar test.jar,那么将在当前目录下找test.jar, 同时.也表示Dockerfile的路径)来build镜像,
或者使用docker build -t 47.100.26.16:5555/project/vue-docker:v1 Dockerfile文件的路径来build镜像 -
执行完第4步的时候, 此时运行docker images命令 可以看到名称为47.100.26.16:5555/project/vue-docker tag为v1的镜像
-
此时在本地新建
/etc/docker/daemon.json文件, 若该文件中已存在, 则添加 “insecure-registries”: [“远程registry1仓库的ip以及端口”, “远程registry2仓库的ip以及端口”, ‘等等, 以此类推’], eg如下:{ "insecure-registries": ["http://47.100.26.16:5555"] }做此步骤的原因是, 若不添加 则会默认以https的请求去访问registry镜像仓库, 修改完之后需要重新加载daemon重启docker服务,
命令:sudo systemctl daemon-reload && sudo systemctl restart docker重启之后 可以执行docker info命令查看刚刚的配置有没有生效, 若能看到配置则代表生效
-
此时可以执行push命令, 将仓库push到自己搭建的仓库了
命令: docker push 47.100.26.16:5555/project/vue-docker:v1 -
执行完第7步后, 可以选择在47.100.26.16机器上pull镜像或者在其他机器中pull镜像了.
命令: docker pull 47.100.26.16:5555/project/vue-docker:v1
注: 若是在47.100.26.16本机上pull的话, 则可以直接把ip改成127.0.0.1或者也可以重复第六步的步骤, 将47.100.26.16:5555配置进去
若是在没有将47.100.26.16:5555该配置配置到daemon.json文件的话, 需要额外配置一下才能拉取镜像 -
执行镜像
命令: docker run -d -p 8000:80 镜像名:tag 或者 docker run -d -p 8000:80 镜像Id注意: 1. 47.100.26.16远程docker仓库的公网ip, 并要开启5555公网ip 2. 制作的镜像tag名必须为 镜像仓库的url可以访问的地址. 通常将它设置成 docker镜像仓库公网ip:公网端口/project/自定义镜像名:tag名 目的是在执行docker push/pull命令时, 能找到远程仓库镜像的地址(规则是这样)
3.1.2 push镜像到本地仓库
-
假设本地仓库地址叫 192.168.2.101, 端口为5555, 存在一个tomcat镜像,镜像id为0s0asdfsdfh
-
若本地仓库的服务不支持https协议,则需要在**/etc/docker.daemon.json**文件中添加如下配置:
"insecure-registries": ["192.168.2.101:5555"] -
重命名镜像tag:
# docker tag repository/tag # 按照如下例子: # repository为: 192.168.2.101:555 => 不能添加协议, 比如: https://、http:// ………… # tag必须全部为小写,不能出现大写 docker tag 192.168.2.101:5555/customize-image:v1 -
push镜像
# 等待push成功即可 docker push 192.168.2.101:5555/customize-image:v1 -
查看镜像是否push成功
# 若能看到对应的镜像信息表示push成功 curl -i http://192.168.2.101:5555/v2_catalog
3.1.3 使用ssh远程执行命令运行容器
3.1.4 挂载宿主机目录
背景: 需要php运行环境运行指定项目
- 克隆该项目到本地
- docker build -t docker-php:latest .
- docker run -it -d -p 8002:80 -v /root/php/resource:/var/www/html docker-php:latest
注意:
* clone上述指定项目时, 可以在直接使用作者提供的快速拉取和运行镜像的命令:
docker pull richarvey/nginx-php-fpm:latest & sudo docker run -d richarvey/nginx-php-fpm
这样就可以省略上述制作镜像的第二步.
* 解析下第三条命令:
-it: 在容器中打开一个伪终端进行交互操作
-d: 容器在后台运行
-v: 挂载宿主机目录 前者为宿主机挂载目录, 后者为容器中目录 eg: -v /root/php/resource:/var/www/html
至于为什么挂载到容器的/var/www/html目录, 由制作镜像时nginx的配置文件决定(公共资源目录: 可以通过
ngxin直接访问资源的路径).
3.1.5 ADD命令的坑
正常在linux系统中, cp命令或者mv命令
eg: mv/(cp -r) ./test /root/test2 命令会将test整个文件夹放到 /root/test2 文件夹下,
但是 ADD命令是将 ./test文件夹下面的所有东西 放到/root/test2文件夹下
相当于 cp -r ./test/* /root/tes2
3.1.6 Dockerfile常见命令解析
- 格式
- 注释行前面要加井号, 就算注释换了行也要加,和java的中"//"一致
- 指令 + 参数的格式 eg: FROM centos => FROM就是指令,centos就是参数
- 第一个指令必须是FROM
| 命令(不区分大小写,最好用大写,能更好的区别参数) | 规则 | 描述 | 示例 | 注意事项 |
|---|---|---|---|---|
| FROM | FROM 镜像名 | 指定基础镜像 | FROM <镜像>:[TAG] | 无 |
| MAINTAINER | MAINTAINER 维护者信息 | 镜像的维护者 | MAINTAINER ‘[email protected]’ | 无 |
| COPY | COPY … COPY ["",…""] |
将宿主机的文件复制到镜像中去 | COPY 源文件(夹) 目标文件(夹) | 1. 必须是build上下文中的路径,不能是父目录中的文件 2. 如果是目录,其内部文件或子目录会被递归复制,但目录自身不会被复制 3. 如果指定了多个,或在中使用了通配符,则必须是一个目录,则必须以/结尾 4. 如果不存在,将会被自动创建,包括其父目录路径 |
| ADD | ADD … ADD ["",…""] |
将宿主机的文件添加到镜像中去 | ADD 源文件(夹) 目标文件(夹) | 1. 和COPY指令基本相同 2. 支持tar文件和url路径 3. 若是一个URL则执行的文件将被下载,但不会被解压 4. 如果是一个本地系统上压缩格式的tar文件,它会展开成一个目录; 但是通过URL获取的tar文件不会自动展开 5. 如果有多个,直接或间接使用了通配符指定多个资源,则必须是目录并且以/结尾 |
| WORKDIR | WORKDIR | 指定工作目录, 在该命令下执行的文件操作 | WORKDIR /usr/local/src | 若在此命令后面执行了ADD或COPY命令,那么目标文件(夹)都会添加/usr/local/src前缀 同时我们进入容器后的工作目录也为/usr/local/src(这就是我们进入容器后发现有些容器是/目录, 有些是其他的目录) |
| ENV | ENV ENV =… |
指定环境变量, ENV = 或 ENV key value | ENV JAVA_HOME /usr/local/jdk ENV PATH P A T H : PATH: PATH:JAVA_HOME/bin/ |
调用格式: v a r i a b l e N a m e 或 者 variableName或者 variableName或者{variableName} |
| RUN | RUN RUN ["","",""] |
后面接shell脚本的命令, 会按照shell脚本的格式解析. 用来指定docker build过程中运行指定的命令 |
RUN echo ‘Hello docker’ | 无 |
| CMD | CMD CMD ["<可执行的命令>","",""] CMD ["",""] |
后面接shell脚本命令, 与RUN不同的是, 该CMD后面接的命令是在镜像启动后被执行的 | 无 | CMD命令可以写多个,但是只有最后一个CMD命令会生效, 所以我们在拉取其他人制作镜像的时候,若他人的镜像在启动时使用CMD命令来启动程序的, 那么我们在使用docker run命令添加shell命令时,会将里面的CMD命令覆盖。eg: 使用docker run --name tomcat -it -d -p 8080:8080 tomcat:latest ls命令启动 tomcat镜像时,容器不会被启动,容器启动时执行的命令为ls。 CMD ["",""] 此种方式是为ENTRYPOINT指令添加参数的 |
| ENTRYPOINT | ENTRYPOINT ENTRYPOINT["","",""] |
容器启动时需要执行的命令 | ENTRYPOINT [“java”, “-jar”, “/root/test.jat”] | 与CMD类似,但它不会被docker run中的命令给覆盖。 它和CMD指令,谁在最后面,谁就生效 |
| VOLUME | VOLUME VOLUME [""] |
挂载卷,可以将容器中的某个目录挂在到宿主机的随机目录下,eg: mysql中的数据存储就可以使用此命令将mysql存放的持久化数据挂载到宿主机的随机目录下, 保证容器重启后也能正常访问数据 |
VOLUME 中的mountpoint为容器中的一个目录,而挂在到宿主机的目录是随机产生的。 可以使用docker inspact 容器id命令来查看数据, 找到key为MOUNTS的信息就可以找到挂载到宿主机的详细目录了 |
|
| ARG | ARG userName = defaultValue | 与ENV命令类似,定义环境变量的,但它支持我们在build镜像的时候使用–build-arg =格式来为变量填充值 | docker build -t test:latest --build-arg userName = eugene . | |
| ONBUILD | ONBUILD | 用来在Dockerfile中定义一个触发器 |
3.1.7 指定docker 容器的时间参照物
-
背景: 在前后端分离的项目中, 难以避免在前端使用new Date()函数, 该函数获取的是当前电脑的时间, 加入当前电脑是UTC标准时间, 那么就会比我们正常的中国时间少8个小时。所以, 根据这种情况, 会衍生出一种case: 就是在本地显示的时间是好的, 但是一上docker化的dev或者qa或者生产环境的时候就会出现少了8个小时, 原因是dev、qa、生产环境是将nginx服务器放在docker里, 会根据docker的时间区来获取时间戳的年月日, 进而出现本地环境和dev、qa、生产环境出现不一样的情况
-
解决方案: (设置容器中的时间与当地的保持一致即可)在制作docker的Dockerfile文件添加如下配置:
ENV TZ=Asia/Shanghai RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo '$TZ' > /etc/timezone
3.1.8. docker commit命令
# 此命令一般用作于二次开发, 假设我们从docker hub中拉取了一个nginx镜像,然后我们要将我们的web前端vue项目丢进nginx里,我们先把nginx镜像运行起来,然后使用docker cp命令将vue build后的文件丢进nginx镜像中指定的可访问的目录下。再使用docker commit命令对容器进行提交,最终得到我们想要的镜像
docker commit -m "提交信息" -a "作者" 容器id或者容器名称 新镜像名:新镜像tag
3.2 Jenkins
3.2.1 自动化部署maven项目
3.2.2 多job部署, job间传值
3.2.3 linux不同用户运行jenkins.war
linux若分别以普通user启动jenkins.war, 那么会在/home/user/.jenkins/ 目录下建job目录.
若以root的身份启动的话, 则会在/root/.jenkins/ 目录下建job目录.
所以在后续需要启动jenkins时, 要注意使用root身份启动还是user身份启动, 因为他们读取的job目录是不一样的.
3.2.4 Jenkins支持maven多模块项目(每个模块都是一个git仓库)多环境同时部署思想
-
背景:
问: 什么情况下会不支持多环境同时部署? 答: 众所周知, maven项目的仓库设置的只有一个, 当在同一台搭建jenkins的电脑部署生产环境和测试环境的时, 使用的是同一个本地仓库, 生产环境一般部署是master分支, 测试环境部署测试环境的branch, 在maven项目build 的过程中, 一般都需要install jar包到本地仓库, 以便于打包的时候能找到依赖. 试问, 同时install不同branch的 jar包, 但jar包的groupId、artifactId、version都没有改变, 那肯定会出问题呀. 解决方案: 引入版本控制插件: 1. 在根项目pom文件中的build -> plugins标签中添加如下代码, 引入插件:org.codehaus.mojo versions-maven-plugin 2.3 false
3.2.5 jenkins multijob build多模块(每个模块都是一个git仓库)
- 背景: 在多模块的springboot项目中, 可能会存在项目中统一以来的common类库(自己编写的), 在改common类库
会添加许多common的配置, eg: jdbc, log, mybatis mapping扫描包, mybatis别名配置等等. 所以
在模块打包时, 需要保证common的类库已经存在与maven 本地仓库了, 此时multijob的作用就体现了出来. - multijob: multijob是一个插件, 它可以控制jenkins job的执行顺序, 串行还是并行.
- 实现步骤:
- 建立一个Multijob pipeline(外层, 主要是一个壳子, 该途径可以让job之间串行或者并行) 参数化构建.
添加参数, 一般都是branch name, 这样就能指定拉去哪个环境的代码了 - 在ADD BUILD STEP TAB下添加一些阶段(phase)性的job, 可以设置串行或者并行
串行即使用队列(sequence)的方式, 并将触发机制设置成successful
并行则使用并列(parallel)的方式, 并将触发机制设置成always
即在这可以设置一些job的执行顺序, 这样就可以解决一些项目依赖与另一个项目先启动的问题,
eg: 要先启动eureka再启动其他服务, 因为其他服务要往eureka注册
- 建立一个Multijob pipeline(外层, 主要是一个壳子, 该途径可以让job之间串行或者并行) 参数化构建.
3.2.6 jenkins Multijob 参数传递规则:
- 通过build step为downstream job phase的传递规则, downstream job 参数名必须与upstream
job定义的参数名一致, 这样在upstream job的multijob触发downstream job phase时,
downstream job才能接收到参数. - 通过post-build-action为trigger parameterized build on other projects的传递规则
通过设置parameters type为predefined paremters的方式, 以key=value的方式定义传递参数,
ps: 要获取upstream job传递的参数或者当前job自定义的参数时要使用${key}的方式
3.2.7 jenkins使用nohup后台运行jar包
-
背景
在linux环境中启动一个程序想放入后台正常做法是使用nohup加&符号。 -
解决方案
需要使用如下命令:
nohup java -jar xxx.jar > myLog.log 2>&1 &
将日志输出重定向到myLog.log文件中
3.2.8 jenkins运行mvn命令找不到
-
背景:
在安装maven时, 配置环境变量配置到了~/.bashrc(~/.bash_profile)文件, 该文件的环境变量是针对于当前用户而言, 导致在jenkin build maven项目时提示命令找不到, 因为jenkins运行命令时, 他所处的用户组和用户是
3.3 Shell脚本
3.3.1 自定义shell脚本, 完成maven多项目自动拉取远程仓库代码操作
3.3.2 ENV=${ENV:-“local”} 代码含义
- 首先这是一个定义变量的过程, ${}里面的ENV是变量名接收值, 相当于springboot的@requestParam(value = ‘a’, defaultValue=“string”) String b 中的a, 用来接收参数,而后面的local是默认值,
中间一定要加横线所以在执行脚本时设置参数值是这样表示的: ENV=test ./脚本名字那么此时脚本中的ENV变量就会变成test
3.3.3 ssh执行远程命令awk命令无法执行的问题
- 使用双引号将整个命令包括起来, 使用单引号将awk后面的表达式括起来, 并在$x前添加转义符()
eg: ssh -i xxxx.pem [email protected] “docker ps -a | grep vue-docker-v1 | awk ‘{print $1}’”
命令解析: 将docker信息包含vue-docker-v1的容器输出第一个参数(containerId),
这么做的原因通常是在部署时, 需要停止容器再重新打镜像.
3.3.4 Sed命令根据key修改文件内容
- sed -i “s/需要修改的key/需要修改的内容/g” 目标文件
(后面加了一个g表示全局替换, 与正则中的g含义一致)
3.3.4 Sed和Rename命令修改文件名
-
eg: 将test111.txt文件名中的1全部替换成2
echo test111.txt | sed "s/1/2/g" | xargs mv test111.txt -
替换文件名的命令还有rename命令, 但是该命令是批量修改文件名
eg: 将当前目录下的所有htm后缀的文件统一改成html后缀rename "s/\.htm/\.html" *.htm
3.4 Nginx
3.4.1 配置反向代理
-
在server部分添加如下配置:
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/json; sendfile on; keepalive_timeout 65; #gzip on; upstream domain { server 192.168.1.110; } server { listen 80; server_name 192.168.1.122; location /api { # 使用固定的域名去请求后端,有可能后端指定了一定要使用域名才能访问 # 如果要获取请求的真实域名的话,只需要配置成:proxy_set_header Host $Host; 即可 proxy_set_header Host "in-domain.com"; # 将请求头携带到后端 proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 如果http://adomain后面不加/,则会匹配192.168.1.122,将192.168.1.122后面的所有uri添加到in-domain.com后面 # 如果http://domain后面加了/,则会匹配192.168.1.122/api,将192.168.1.122/api后面的所有url添加到in-domain.com后面 proxy_pass http://domain/; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }反向代理允许重新定义或者添加http请求头
语法: proxy_set_header field value;-
根据proxy_pass的不同,最终反向代理的url也会不同,具体如下所示:
-
proxy_pass的定义 请求url 反向代理后的url 备注 http://192.168.1.122 http://192.168.1.122/api/test.do http://192.168.1.110/api/test.do 因为proxy_pass中没有添加**/**,因此会认为host后面所有的uri都要被反向代理到后端去 http://192.168.1.122/ http://192.168.1.122/api/test.do http://192.168.1.110/test.do 因为proxy_pass中有添加**/,因此会认为/api**后面所有的uri都要被反向代理到后端去 -
同时,若后端项目指定了一定要固定的域名才能访问的话,此时我们可以使用proxy_set_header Host来配置固定的域名,比如如下配置:
# 在进行反向代理时,将域名固定成:in-domain.com proxy_set_header Host "in-domain.com";
-
3.4.2 配置多个vue.js单页面项目
-
在server部分添加如下配置:
location / { try_files $uri $uri/ /index.html; } if (!-e $request_filename) { rewrite ^/expo/.* /expo/index.html last; } ---------------------------------------------- 含义: 第一个配置为常见的vue.js单页面配置, 只需要添加这行配置, 并将打好的包放入ngxin访问的根目录下即可完成部署 第二个配置为配置多个vue.js单页面的配置: 解析: 条件: 若请求的资源不是一个文件 条件内语句块: 若请求uri中以expo为前缀, 则重定向到 uri为/expo/index.html 注: 1. 要保证build后的所有文件放在ngxin根目录下的expo文件夹下. 1. 静态资源要以expo文件夹为基准eg: 在vue脚手架3.0版本之前, 初始化项目并采用默认build的方式打包的index.html文件内容为
<html> <head> <meta charset=utf-8> <meta name=viewport content="width=device-width,initial-scale=1"> <title>expotitle> <link href=/static/css/app.2f09759cd2fab12147a7ee7a21efe173.css rel=stylesheet> head> <body> <div id=app>div> <script type=text/javascript src=/static/js/manifest.28e76dc415eb565ab385.js>script> <script type=text/javascript src=/static/js/vendor.3af6701d2adeecbcec08.js>script> <script type=text/javascript src=/static/js/app.04c768f7c6f8cd515016.js>script> body> html>重点在于link标签的
script标签, 默认为当前目录下的static文件夹下. 其实真正的规则为
${assetsPublicPath}/${assetsSubDirectory}/css(js)/xxxx.css(js)
而assetsPublicPath和assetsSubDirectory变量可以在config/index.js文件中配置,
所以在上述的配置中, 若请求的url为:127.0.0.1/expo/test那么nginx内部会重定向到127.0.0.1/expo/index.html即进入ngxin第二种路由: 此时index.html各种静态资源在ngxin可访问的根目录下, 此时会报404.如果要访问expo/index.html 文件访问成功
- 首先在ngxin根目录下创建
expo文件夹 - 并修改vue.js配置文件即build后的index.html文件 如下图:
[外链图片转存中…(img-Rhn55CT4-1617418951522)],
[外链图片转存中…(img-EUtGkJFS-1617418951522)] - 将build后的包整个丢进expo文件夹内
- 重新reload ngxin, 再次访问即可
- 首先在ngxin根目录下创建
3.4.3 docker化basic auth(可配)
-
拉取准备好的镜像包
git clone https://github.com/AvengerEug/docker-nginx-basic-auth.git -
执行命令
TAG=auth USERNAME=eug PASSWORD=pwd123 ./build.sh docker_build各细节可跟踪至该repository
3.4.4 配置Https证书, 支持https访问.
3.4.5 利用nginx正向代理
-
背景: 同一个局域网中的linux中被限制不能连外网, 所以可以代理到局域网中某台能上网的电脑
-
步骤:
- nginx配置:
server { resolver xxxx; # 这里使用同网段的DNS域名, window中使用ipconfig -all 命令可以获取到 listen YYYY; # 正向代理的端口 location / { proxy_pass http://$http_host$request_url; } }- linux中需要执行如下命令
export http_proxy=http://用户名:密码@可以上网的nginx地址:监听代理的端口 -
但只能代理到http请求, https请求代理不上
3.4.6 Tomcat server.xml配置文件解析
- 连接器:Connector
- protocol解析默认是http/1.1(tomcat会默认采用当前版本默认的io模型启动进程, 也可以指定某个模型的类全路径来启动) 在tomcat8是采用java的nio传输模型, 在tomcat7之前是采用java的bio传输模型
- minThread: 处理业务代码的线程池最小的线程数
- maxThread: 处理业务代码的线程池初始化最大的线程数
- acceptCount: 线程池中的数量满了, 后续的线程会进入等待队列中, 此配置就是限制队列中最大的等待数量, 若超出数量抛出异常, 若等待时间超时页抛出异常
- connectionTimeout: 连接超时时间
- SSLEnabled: 是否开启ssl验证在https访问时需要开启
- enabledLookups: 如果为true则可以通过调用request.getRemoteHost进行DNS查询来的带远程客户端的实际主机名, 否则只返回远程客户端的ip地址
*. Engine: tomcat中的service和engine是一对一的 - name: 对应的engine名
- defaultHost: 默认主机名, 当输入localhost:8080时 会走到name为localhost的Host节点
*. Host: 一个Engine有多个Host - name: 对应的一个主机
- appBase: host的根目录(用作于解析web项目的目录(自动解压war包)).
表示这个主机工作的根目录, 相对于bin目录所处的目录而言. - unpackWARs: 设置为true, 表示默认解压war包
- autoDeploy: 设置为true, 设置自动部署
*. Context: 上下文路径 - docBase: 相对于Host标签下的appBase而言,
- path: 访问上下文路径. eg: Host的appBase为webapps, name为localhost; Context的docBase为eugene, Context的path为’/test’, 那么访问localhost:8080/test 则会默认访问到webapps/eugene文件夹去
四. Linux
4.1 常用命令(常忘)
4.1.1 给文件添加可执行权限
- eg: chmod +x build.sh
4.1.2 删除当前文件夹内所有内容
- rm -r *
4.1.3 压缩当前文件夹为zip包
- zip -r target.zip ./
4.1.4 解压缩zip压缩包到当前目录
- unzip target.zip -d ./ 或 unzip target.zip
4.1.5 查看某个文件的大小
- du -h 文件名
4.1.6 列出文件夹下面第一级每个文件的大小(包括文件夹和文件)
- du -ah --max-depth=1 文件夹名
4.1.7 查找文件命令
- 基本: find / -name '文件名
- 通配符: find / -name ‘.conf’
4.1.8 查找某个端口被占用
- ps -ef | grep 80
- netstat -anp | grep 80
4.1.9 查看linux各进程内存使用情况
- top
- 指定某个线程: top | grep 进程名
4.1.10 Linux 启动项目后台保留策略
- 背景: 通常要在后台执行会加上 & 符号, 但这样不稳定, 也许你关闭终端后, 通过这样的方式运行的程序就会挂掉.
- 目的: 要想脱离终端来执行程序的话应该使用 nohup命令, 三要素(nohup 运行的命令 & )
- 示例: 示例是运行一个打包好的springboot项目(后台启动项目, 并使用dev环境的配置)
nohup java -jar test.jar --spring.profiles.active=dev --server.port=8888 &
4.1.11 cp -r 命令的坑
在执行 cp -r 源文件夹 目标文件夹命令时,
若目标文件夹中存在一个与源文件夹同名的文件夹的话, 那么它会将整个源文件夹copy到目标文件夹中同名文件夹的里面
eg: cp -r /root/test /root/info/test => 它会将/root/test copy到/root/info/test下,
所以/root/info/test 里面会多一个test文件夹.
ps: 它并不是将/root/test文件夹中的内容copy到/root/info/test中, 若要实现此需求, 请执行
cp -r /root/test/* /root/info/test
4.1.12 清除所有log文件(内存不够时)
- find . -name “*.log | xargs rm”
4.1.13 压缩成tar.gz压缩包
-
将当前目录压缩成test.tar.gz
tar -czf test.tar.gz ./*
4.1.14 解压缩tar.gz包
-
解压缩test.tar.gz包 至root目录下
tar -zxvf test.tar.gz -c /root
4.1.15 Linux文件权限查看及无权限解决方案
- 如下图
[外链图片转存中…(img-JyeosYLP-1617418951523)]
4.1.16 基于linux和nginx搭建内网本地yum源
1. 背景: 内网无法上网, linux yum无法安装软件, 原因就是找不到yum源, 此时我们需要有一个公共的yum源
2. 前提: 要有yum源包, 可以在网上下载对应系统yum类库。比如如下是网易开源的yum包, 是一个镜像
eg: http://mirrors.163.com/centos/7.7.1908/isos/x86_64/CentOS-7-x86_64-Everything-1908.iso
-
假设:
搭建yum源的linux服务器ip地址为: 192.168.1.1 nginx开放的端口为80, 且没修改过nginx任何配置 -
nginx搭建yum源步骤:
4.1. 将镜像文件内容解压缩到/var/www/html目录下
4.2. 在nginx监听80端口的server节点下修改如下配置文件(将资源路径指向/var/www/html):
location / { autoindex on; root /var/www/html; }4.3. 访问http://192.168.1.1:80 若能查看到/var/www/html文件夹的目录则算安装成功
-
使用搭建的yum源步骤:
5.1. 将/etc/yum.repos.d/文件下的所有.repo后缀名的文件内容的enabled设置成05.2. 创建文件/etc/yum.repos.d/local.repo
5.3. 填充如下内容至/etc/yum.repos.d/local.repo文件
[local] name=local baseurl=http://192.168.1.1:80 enabled=1 gpgcheck=1 gpgkey=http://192.168.1.1:80/YYYY ## gpgkey中的YYYY这一串字符串根据访问http://192.168.1.1:80的结果而定, 目的就是指定一个key. ## 在网易提供的yum源(http://mirrors.163.com/centos/6/os/x86_64/)中,我们可以指定YYYY为RPM-GPG-KEY-CentOS-65.4. 清理无用源
yum clean all5.5. #查看是否存在local源
yum repolist5.6. 若第五步存在则可以安装依赖了
4.1.17 在centos7中添加一个自定义服务
-
创建一个服务文件, eg创建nginx服务
1. vim /usr/lib/systemd/system/nginx.service 2. 修改内容如下(每一行后面的注释需要去掉): [Unit] Description=nginx - high performance web server # 服务的描述 After=network.target remote-fs.target nss-lookup.target # 在启动network、remote-fs、nss-lookup服务启动后再启动 [Service] Type=forking # 以后台模式启动 ExecStart=/usr/local/nginx/sbin/nginx # => systemctl start nginx ExecReload=/usr/local/nginx/sbin/nginx -s reload => systemctl reload nginx ExecStop=/usr/local/nginx/sbin/nginx -s stop => systemctl stop nginx [Install] WantedBy=multi-user.target # 表示多用户命令行状态 -
重新加载服务systemctl daemon-reload
-
设置开机自动启动
systemctl enable nginx.service或者
在/etc/rc.d/rc.local文件夹中添加代码:systemctl start nginx
在将/etc/rc.d/rc.local设置成可执行文件:chmod +x /etc/rc.d/rc.local
4.1.18 如何使用命令下载sftp服务器中的文件
-
通常,我们使用的是scp命令下载服务器的文件,但为了安全,可能会使用sftp。那如何使用命令下载呢?
sftp -o port=端口号 用户名@服务器ip地址:/root/aaa.txt ./ # 意思就是将服务器中的/root/aaa.txt文件下载到本地
4.2 keepalived实现主备部署
4.2.1 两台centos7使用keepalived实现主备简单部署
1. 搭建keepalived服务
* 设备A: centos7 64位操作系统
1. 安装keepalived服务
yum install keepalived
2. keepalived默认的配置文件在/etc/keepalived/keepalived.conf
更改配置文件内容为如下内容:
```shell
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER # 主节点
interface eth0 # 网卡, centos7 使用ip addr查看, centos一般为ens33
virtual_router_id 51 # 虚拟路由id, 这个要和副实例保持一致
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.213.100 # 主实例的ip地址, 要求与当前主机的ip同一个网段, 到时候会根据此虚拟ip作为入口
}
}
```
3. 使用service keepalived start来启动服务
4. 使用service keepalived status来查看服务实例, 会在控制台中看到许多Sending gratuitous ARP on ens33 for
192.168.213.100的信息, 表示启动成功
* 设备B: centos7 64位操作系统
1. 与设备一的步骤一致, 需要修改的配置为: 修改vrrp_instance VI_1节点的state为BACKUP => 标识它为一个备用节点
-
做好验证准备工作
-
我们需要搭建一个nginx(nginx的搭建步骤忽略)应用来验证
在设备A中的nginx访问资源的根目录下(一般为nginx安装目录的html文件夹下):
执行命令: echo “keepalived1” > test.html在设备B中的nginx访问资源的根目录下(一般为nginx安装目录的html文件夹下):
执行命令: echo “keepalived1” > test.html
-
-
启动nginx
-
第一步: 访问 192.168.213.100/test.html => 无论怎么刷新, 最后在页面上看到的内容始终为 “keepalived1”
-
第二步: 将设备A的keepalived1服务停掉: systemctl stop keepalived 再刷新页面, 可以看到内容变成了"keepalived2"
-
第三步: 将设备A的keepalived1服务开启: systemctl start keepalived 再刷新页面, 可以看到内容又变成了"keepalived1"
==> 至此, keepalived的主备模式搭建成功
-
-
存在的几个缺陷:
-
因为它keepalived是通过虚拟ip进行交互的, 我们一般使用keepalived是想完成主备功能, 那肯定是要在主备中部署应用服务的,
若应用服务挂了, 比如前端vue.js项目, nginx没运行起来, 那么此时是不会将请求分发到备用服务器的, 所以我们可以写一个脚本
来检测: 如果应用服务挂了那么就将当前机器的keepalived的服务给杀掉,
所以可以在/etc/keepalived/keepalived.conf文件中添加如下代码:vrrp_script chk_http_port { script "/usr/sbin/nginx.sh" // 要执行的脚本, 脚本内容忽略, 大致内容就是nginx进程不再了, 就停止keepalived服务 interval 3 // 每隔3秒执行一次 weight 2 }
-
4.3 linux配置环境变量的坑
-
通常,在window系统下,有时候我们为了图方便,直接将bin目录下的某个文件配置在环境变量中。eg: jdk的安装目录在:
H:\JAVA-1.8-JDK, 我们为了图方便,直接在系统变量中添加H:\JAVA-1.8-JDK\bin来达到环境变量的配置,在是在linux下,我们不能直接export java的bin目录, 会报如下错误-bash: export: `/root/jdk1.8/bin': not a valid identifier正确的格式应该为:
export PATH=$PATH:/root/jdk1.8/bin要将
PATHexport出去
4.4. 使用软连接完美释放环境变量
-
由于在linux执行命令时,会从如下几个目录去查找:
/usr/local/bin/, /usr/bin, /root/bin, /bin等等等等(其实这几个目录就是配在环境变量的)
其中,我们可以把命令软连接到上述的目录下,比如: /usr/local/bin假设我们把jdk的安装包解压到了/usr/local/jdk下
那么我们可以不配置环境变量,直接使用如下命令
ln -s /usr/local/jdk/bin/java /usr/local/bin/java
即可完成java命令的环境变量配置,当然,这样的做法比较单一,
比如我一个目录下有很多命令(eg: zookeeper的bin目录,有zkServer.sh也有zkCli.sh).
这个时候就要诶个的去软连接,此时
比较好的做法就是配置环境变量了。
4.5 使用jstack定位导致cpu狂飙的问题代码
- 使用
top -c命令,查看占用cpu资源过高的线程, 可以按大写的p来进行排序,占用最高的进程会排在第一位,假设为4669 - 执行
top -Hp 4669查看进程中占用cpu最高的线程, 假设为4686 - 为进程生成快照
jstack -l 4669 > 4669.log - 将4686转成十六进制: 0x124e
- 使用vim命令打开4669.log文件,并按 ‘/’, 输入
0x124e, 按回车。定位线程的栈信息 - 可以按上下方向建来看更多的日志,往下翻,看堆栈信息,基本上就能定位到某一行了
ps: 可以写一个死循环来测试上述方案。
基本的思路就是找到占用cpu资源高的进程,并使用jstack -l 进程ID > threadInfo.log命令生成线程快照文件
然后使用 top -Hp 进程ID 查看占用cpu资源高的线程,并将线程ID转成16进制。
再使用线程ID的16进制数据,从上述生成的线程快照文件去定位线程信息,基本上就能定位到代码中的具体某一行
4.6 如何在centos7中添加一个自定义服务
1. 创建一个服务文件, eg创建nginx服务
vim /usr/lib/systemd/system/nginx.service
内容如下(每一行后面的注释需要去掉):
[Unit]
Description=nginx - high performance web server # 服务的描述
After=network.target remote-fs.target nss-lookup.target # 在启动network、remote-fs、nss-lookup服务启动后再启动
[Service]
Type=forking # 以后台模式启动
ExecStart=/usr/local/nginx/sbin/nginx # => systemctl start nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload => systemctl reload nginx
ExecStop=/usr/local/nginx/sbin/nginx -s stop => systemctl stop nginx
[Install]
WantedBy=multi-user.target # 表示多用户命令行状态
2. 重新加载服务systemctl daemon-reload
3. 设置开机自动启动systemctl enable nginx.service
或者
systemctl enable rc-local.service => 启动rc.local服务
systemctl start rc-local.service => 开启rc-local服务
在/etc/rc.d/rc.local 文件夹中添加代码: systemctl start nginx
在将/etc/rc.d/rc.local设置成可执行文件: chmod +x /etc/rc.d/rc.local
五. Http
5.1 ContentType
-
ContentType存在的意义:
在互联网中有成百上千种不同的数据类型, 它用来定义数据类型的格式. -
在请求头中指定ContentType的意义:
告诉服务器使用什么格式以及编码来解析请求中的消息
eg: Content-Type: application/json;charset:utf-8; -
常用的ContentType类型:
1. application/x-www-form-urlencoded 这种类型是将请求参数url编码后, 放到请求体中, 通常用于表单的提交. 通常会在后面添加 ;charset:utf-8 保证中文不乱码 2. application/json 使用这个类型,需要参数本身就是json格式的数据,参数会被直接放到请求实体里,不进行任何处理。服务端/客户端会按json格 式解析数据(约定好的情况下)get请求下会将key-value解析出来,放到URL的参数里面
六. IDEA
6.1 快捷键(修改成eclipse后)
6.1.1 查看接口的实现类
- Ctrl + t
6.1.2 查看哪个地方用了当前类
- Ctrl + Alt + F7
6.1.3 类型强制转换
- Alt + Enter
6.1.4 快速添加try catch
- Ctrl + Alt + t
6.1.5 查找项目中的文件
- Ctrl + Shift + R
6.1.6 查找项目中的文件(包括源码)
- 按两次Shift
6.1.7 修改idea提示功能快捷键为 ctrl + /
- File -> setting -> keymap -> 搜索basic -> 将Alt + 空格 的快捷键改成Alt + /
6.1.8 修改idea关闭当前类tab快捷键为 ctrl + w
- File -> setting -> keymap -> 搜索close -> 找到Window下面的Editor Tabs下面的Close, 改成Ctrl + w
6.1.9 IDEA调试hashMap源码显示不了hashMap内部一些属性
- 参考链接https://blog.csdn.net/qq_31772441/article/details/96469953
6.2 IDEA手动搭建springmvc maven项目
1. 新建maven项目,并添加springmvc的依赖
2. 右键项目名 -> Add Framework Support -> 选中springmvc支持
3. 修改web.xml文件, 将dispatchServlet配置成第一个加载的servlet,并配置dispatchServlet需要加载的配置文件(这一步在第二步完成的时候
应该就应该做好了)
4. Ctrl + Shift + Alt + s 打开项目结构, 在Artifacts tab中选择Available Elements下面项目名称点击右键 -> put into output root
目的是将依赖的jar包添加至包中,保证在tomcat运行的时候能运行正常
5. 配置mvn配置文件, 主要是开启包扫描、注解驱动、自动扫描装配功能以及jsp等静态资源映射
6. 配置tomcat, 唯一需要注意的点就是在新增tomcat中的deployment中需要添加artifact,目的就是将项目的output放入tomcat中
7. 配置多环境打包,pom.xml文件配置:
<profiles>
<profile>
<id>localid>
<properties>
<conf.active>localconf.active>
properties>
<activation>
<activeByDefault>trueactiveByDefault>
activation>
profile>
<profile>
<id>devid>
<properties>
<conf.active>devconf.active>
properties>
<activation>
<activeByDefault>falseactiveByDefault>
activation>
profile>
profiles>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-war-pluginartifactId>
<version>2.2version>
<configuration>
<webXml>web\WEB-INF\web.xmlwebXml>
<warSourceDirectory>webwarSourceDirectory>
configuration>
plugin>
plugins>
<resources>
<resource>
<directory>src/main/resourcesdirectory>
<excludes>
<exclude>confexclude>
excludes>
resource>
<resource>
<directory>src/main/resources/conf/${conf.active}directory>
resource>
resources>
build>
同时需要在resources文件夹下新建conf文件夹并在里面创建不同环境的文件夹,并在不同环境的文件夹中新增以properties结尾的配置文件。
6.3 IDEA 2019编译项目找不到sun.misc包
- 原因:sun.misc包可能会在jdk高版本中被移掉,而IDEA 2019版本在编译project时,默认使用的是JDK11的版本,在JDK11中,已经没有sun.misc包了。因此我们需要显示的把它降低版本为jdk1.8
- 执行步骤:
- 1、Ctrl + Shift + Alt + s 打开项目结构图
- 2、找到Project Structure -> Project -> Project SDK,将版本改成jdk 1.8即可(需要指定本地安装jdk1.8的路径)
6.4 IDEA 切换同一个目录下多个项目的分支
-
背景:现在是微服务的时代,一个项目下可能有多个服务,同时这些服务对应的是一个单独的仓库。然后我们可能会出现在develop-1.1.0分支开发的时候,突然有个紧急情况,需要切换到release-1.0.0分支修bug。此时我们使用git 命令行一个仓库一个仓库的切换分支,效率有点低。此时可以借助IDEA来完成
-
思路:
我们的目标是切换分支至release-1.0.0修bug,但是有可能,我们本地有基于develop-1.1.0分支的修改,此时这些改动应该提交至develop-1.1.0分支,所以我们要先提交本地的改动至develop-1.1.0分支,然后再切换分支到release-1.0.0修bug -
步骤:
1、IDEA右上角有一个绿色的钩,点击直接提交代码至本地分支(操作时注意不要push,因为我们要遵循一个task或者一个bug一个提交的宗旨,我们提交到本地只是为了保存本地的改动,后续应该要对分支进行合并保证一个task或者一个bug只有一个commit的宗旨) 2、点击IDEA右下角的分支按钮。eg: Git:develop-1.1.0 3、在弹出框的右上角中有一个齿轮,点击它,并选中:Execute branch operation on all roots. 就是开始在当前根目录下开启执行分支操作。 4、执行完第三步后,重复第二步操作,会发现在弹出的框中会出现"Common Remote Branches"的标题,在里面选择指定的分支进行checkout,这样就能将当前目录下的所有仓库同时切换到指定分支上(如果看不到远程分支,应该执行fetch操作,点击IDEA右上角的一个向左倾斜的箭头即可。) -
注意点:
必须保证微服务中每个项目的远程分支有相同名字的分支,eg:必须每个微服务都有release-1.0.0分支,才能同时切换远程的Remote分支
七. 阿里云oss
7.1 上传图片
7.1.1 私密上传base64格式图片
OSSClient ossClient = new OSSClient(endpoint, accessId, accessKey);
ObjectMetadata objectMetadata = new ObjectMetadata();
// 此段代码设置是否为私密
objectMetadata.setObjectAcl(CannedAccessControlList.Private);
ossClient.putObject(bucket, fileName, new ByteArrayInputStream(Base64.getDecoder().decode(imgBase64)), objectMetadata);
7.2 下载图片
7.2.1 前端访问私密图片
- 原理: 根据需要请求的资源, 由后端对此资源进行临时授权(新增签名以及请求过期时间, 返回对该资源访问的完整url), 具体参考oss临时授权文档,
使用签名URL进行临时授权部分
八、大咖们发的文章涉及到的知识点
8.1 INSERT INTO SELECT语句造成的锁表事件
-
文章地址(点击右侧链接跳转):一条 SQL 引发的事故。来自:
Java 一日一条公众号 -
总结:
在MySQL的InnerDB存储引擎中,默认的事务隔离级别机制为:
可重复读。在可重复读的机制下,我们执行如下sql(假设name字段有索引)SELECT id FROM table WHERE name = '123' FOR UPDATE此时会锁住索引树中 name为123的那个叶子节点,如果我们除了筛选出id还要筛选出其他的信息,比如age,如下:
SELECT id, age FROM table WHERE name = '123' FOR UPDATE此时因为age这个字段不在索引name对应的B+树内,因此会进行回表操作。又因为我们指定了FOR UPDATE,因此会添加排他锁,所以最终此条SQL会造成name为’123’对应的id,以及id对应的那条数据被锁住,这就是所谓的行锁,如果name没有索引时,此时就会进行全表扫描,直接上升为表锁。
根据文章的内容可知,INSERT INTO SELECT 语句会添加锁,所以我们在执行这样的sql语句时,一定要保证where条件走索引,否则就会升级为表锁,最终导致锁表,无法执行其他插入、更新、删除操作
8.2 Java Bean Copy框架性能对比
-
背景:今日,项目团队进行了code review的环节,因为团队使用的是微服务架构,因此会有许多的PO、VO,这就避免不了要对VO、PO一些公共属性的
copy。在review环节,我提出了为什么不采用Bean Copy(eg:Spring Framework)框架来替代大量的set方法,然后才得知Bean Copy框架会影响性能。因此特
地搜索了一些相关文章并做了如下总结。
-
文章地址(点击右侧链接跳转):Java Bean Copy框架性能对比
-
总结:
所有的Java Bean Copy框架底层都会用反射,用了反射就会影响性能,根据文章中的内容结论可知:
setter>cglib>spring>apache实践建议:
1、要性能要求较高的部分,避免使用Bean Copy框架,而是采用
set的方式进行处理2、如果要使用Bean Copy框架,优先使用cglib
8.3 如下两条SQL的抉择
-
SQL本身
SELECT COUNT(p.pay_id) FROM (SELECT pay_id FROM pay WHERE create_time < '2020-09-05' AND account_id = 'fe3bce61-8604-4ee0-9ee8-0509ffb1735c') tmp INNER JOIN pay p ON tmp.pay_id = p.pay_id WHERE state IN (0, 1); SELECT COUNT(pay_id) FROM pay WHERE create_time < '2020-09-05' AND account_id = 'fe3bce61-8604-4ee0-9ee8-0509ffb1735c' AND state IN (0, 1); -
背景条件:在
pay表中存在500多万条数据,且存在account_id和create_time组成的二级索引。因现在要做一个统计功能,出于性能考虑,因此写了这两条SQL来敲定最终写在代码中的版本。 -
个人拙见:
在accountId和createTime组成的二级索引下,因为有state字段的筛选,这两条sql在执行的过程中应该都会进行回表操作,但是第一条sql有join操作,需要耗费时间申请临时表内存,因此第一条SQL执行效率可能会更差一点 -
追溯根源:
背景:
由于500多万条数据比较多,就算换成脚本也需要好几十兆,因此建议使用应用程序或者SQL的存储过程进行插入,由于鄙人对MySQL的存储过程比较蹩脚,因此我采用程序的方式来表进行插入500万条数据执行步骤:
-
执行如下SQL建DB、表
-- 创建库 CREATE DATABASE test; -- 创建表 USE test; CREATE TABLE pay( pay_id INT PRIMARY KEY AUTO_INCREMENT, account_id VARCHAR(36) NOT NULL COMMENT '账户ID', create_time DATETIME NOT NULL COMMENT '创建时间', state TINYINT(1) NOT NULL COMMENT '支付状态. 0:成功,1:失败,2:冻结' ); -
执行指定程序地址,点击跳转
-
添加索引(放在第三步的原因:因为每次插入数据都会更新索引,为了提高程序插入数据的效率)
-- 创建accountId和createTime组成的二级索引 ALTER TABLE pay ADD INDEX index_accountId_createTime(account_id, create_time); -
分别按如下步骤执行上述两条SQL,并根据查询优化器来确定哪个SQL更好
- 执行INNER JOIN的SQL
-- 第一步:打开查询优化器的日志追踪功能 SET optimizer_trace="enabled=on"; -- 第二步:执行SQL SELECT COUNT(p.pay_id) FROM (SELECT pay_id FROM pay WHERE create_time < '2020-09-05' AND account_id = 'fe3bce61-8604-4ee0-9ee8-0509ffb1735c') tmp INNER JOIN pay p ON tmp.pay_id = p.pay_id WHERE state IN (0, 1); -- 第三步: 获取上述SQL的查询优化结果 SELECT trace FROM information_schema.OPTIMIZER_TRACE; -- 第四步: 分析查询优化结果 -- 全表扫描的分析,rows为表中的行数,cost为全表扫描的评分 "table_scan": { "rows": 996970, "cost": 203657 }, -- 走index_accountId_createTime索引的分析,评分为1.21 "analyzing_range_alternatives": { "range_scan_alternatives": [ { "index": "index_accountId_createTime", "ranges": [ "fe3bce61-8604-4ee0-9ee8-0509ffb1735c <= account_id <= fe3bce61-8604-4ee0-9ee8-0509ffb1735c AND create_time < 0x99a74a0000" ], "index_dives_for_eq_ranges": true, "rowid_ordered": false, "using_mrr": false, "index_only": true, "rows": 1, "cost": 1.21, "chosen": true } ], "analyzing_roworder_intersect": { "usable": false, "cause": "too_few_roworder_scans" } }, -- 最终选择走index_accountId_createTime索引,因为评分最低,只有1.21 "chosen_range_access_summary": { "range_access_plan": { "type": "range_scan", "index": "index_accountId_createTime", "rows": 1, "ranges": [ "fe3bce61-8604-4ee0-9ee8-0509ffb1735c <= account_id <= fe3bce61-8604-4ee0-9ee8-0509ffb1735c AND create_time < 0x99a74a0000" ] }, "rows_for_plan": 1, "cost_for_plan": 1.21, "chosen": true } 综上所述,针对于INNER JOIN,在MySQL处理后,它最终选择走index_accountId_createTime索引,而且评分为1.21- 执行另外一条SQL
-- 第一步:打开查询优化器的日志追踪功能 SET optimizer_trace="enabled=on"; -- 第二步:执行SQL SELECT COUNT(pay_id) FROM pay WHERE create_time < '2020-09-05' AND account_id = 'fe3bce61-8604-4ee0-9ee8-0509ffb1735c' AND state IN (0, 1); -- 第三步: 获取上述SQL的查询优化结果 SELECT trace FROM information_schema.OPTIMIZER_TRACE; -- 第四步: 分析查询优化结果 -- 全表扫描的分析,rows为表中的行数,cost为全表扫描的评分 "table_scan": { "rows": 996970, "cost": 203657 } -- 走index_accountId_createTime索引的分析,评分为2.21 "analyzing_range_alternatives": { "range_scan_alternatives": [ { "index": "index_accountId_createTime", "ranges": [ "fe3bce61-8604-4ee0-9ee8-0509ffb1735c <= account_id <= fe3bce61-8604-4ee0-9ee8-0509ffb1735c AND create_time < 0x99a74a0000" ], "index_dives_for_eq_ranges": true, "rowid_ordered": false, "using_mrr": false, "index_only": false, "rows": 1, "cost": 2.21, "chosen": true } ], "analyzing_roworder_intersect": { "usable": false, "cause": "too_few_roworder_scans" } } -- 最终选择走index_accountId_createTime索引,跟全表扫描的评分相比,比全表扫描低太多 "chosen_range_access_summary": { "range_access_plan": { "type": "range_scan", "index": "index_accountId_createTime", "rows": 1, "ranges": [ "fe3bce61-8604-4ee0-9ee8-0509ffb1735c <= account_id <= fe3bce61-8604-4ee0-9ee8-0509ffb1735c AND create_time < 0x99a74a0000" ] }, "rows_for_plan": 1, "cost_for_plan": 2.21, "chosen": true } -
总结
综上所述,针对于评分而言,第一条SQL(使用INNER JOIN的方式比较好),因此优先选择第一条SQL。 所以,以后遇到这种SQL选择问题时,按照如上方案,把查询优化器的记录搬出来,这样就能知道这条SQL可能走哪些索引,最终走了哪个索引,以及具体的评分是多少。
-