Scrapy爬取花千骨小说
Scrapy爬取花千骨小说
文章目录
- Scrapy爬取花千骨小说
- 前言
- 一、创建项目、爬虫
- 二、实战
-
- 1.items.py如下:
- 2.settings.py:
- 3.pipelines.py:
- 4.spider.py:
- 三、运行结果
前言
本次是爬取https://136book.com中的花千骨小说,文中难点基本都注释了,若还有什么问题欢迎在下面评论区留言。
一、创建项目、爬虫
详细创建请参考之前博客或百度自学。
(创建一个名为花千骨的项目)
cmd命令:scrapy startproject huaqianhu
(创建一个名为spider的爬虫)
cmd命令:scrapy genspider -t basic spider 136book.com
二、实战
1.items.py如下:
代码如下(示例):
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class HuaqianguItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
text = scrapy.Field()
url = scrapy.Field()
2.settings.py:
代码如下(示例):
修改下面的设置
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'huaqiangu.pipelines.HuaqianguPipeline': 300,
}
3.pipelines.py:
代码如下(示例):
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import codecs
class HuaqianguPipeline:
def process_item(self, item, spider):
# 自定义目录,保存到本地
for i in range(len(item['title'])):
path = 'D:\\python\\代码文件\\代码\\Scrapy网络爬虫实战\\huaqiangu\\' + item['title'][i]
self.file = codecs.open(path, "wb", encoding="UTF-8")
for j in item["text"]:
self.file.write(j)
def close_spider(self, spider):
self.file.close()
4.spider.py:
代码如下(示例):
import scrapy
from huaqiangu.items import HuaqianguItem
import re
from scrapy.http import Request
class SpiderSpider(scrapy.Spider):
name = 'spider'
allowed_domains = ['136book.com']
start_urls = ['https://www.136book.com/huaqiangu']
def parse(self, response):
item = HuaqianguItem()
# 提取url
url_all = response.xpath('//ol[@class="clearfix"]/li/a/@href').extract()
item['url'] = url_all[16:]
for url_one in item['url']:
yield Request(url_one, callback=self.parse1) # 回调函数
def parse1(self, response):
item = HuaqianguItem()
# 提取标题
item['title'] = response.xpath("//div[@id='main_body']/h1/text()").extract()
# 提取文本,因为文本中有不可避免的空格,因此处理下
lis = []
for i in response.xpath("//*[@id='content']/p/text()").extract():
lis.append(re.sub('\s+', '', i).strip())
item['text'] = lis
yield item
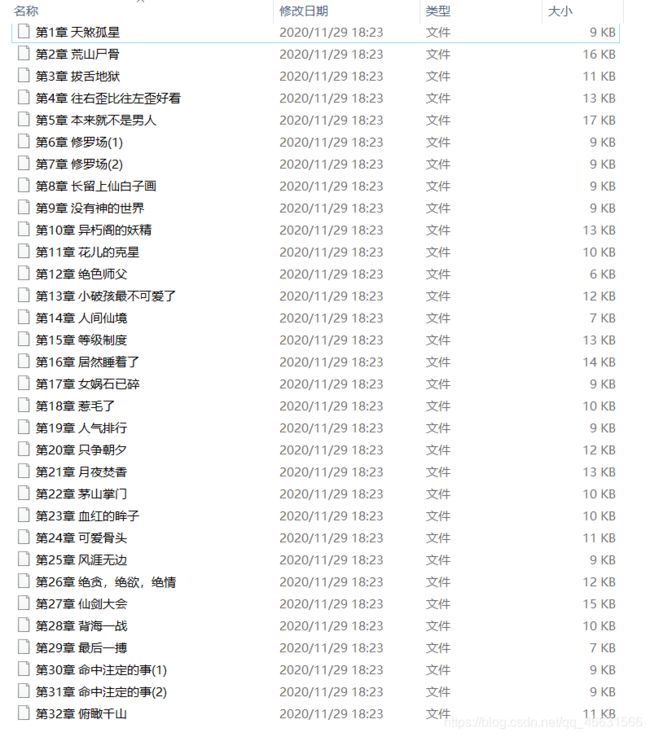
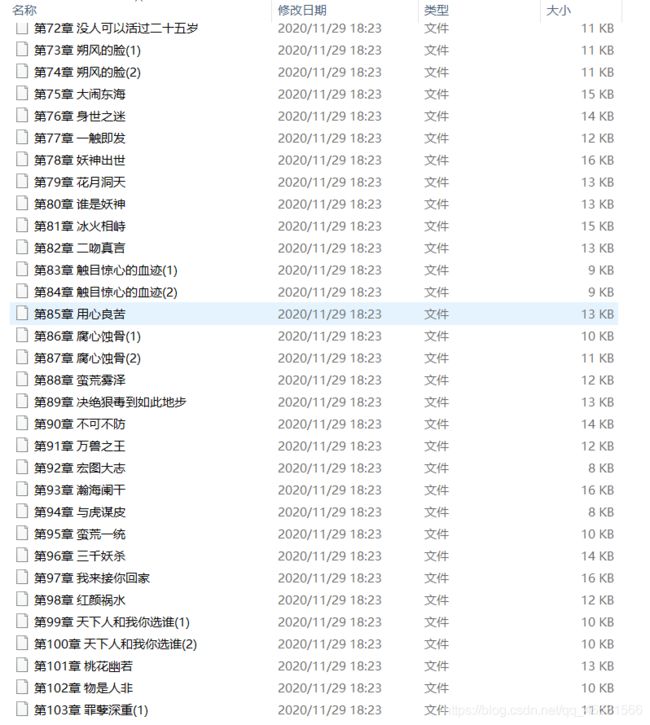
三、运行结果
截两张图供参考: