transformer模型_Transformer模型细节理解及Tensorflow实现
Transformer模型使用经典的Encoder-Decoder架构,在特征提取方面抛弃了传统的CNN、RNN,而完全基于Attention机制,在Attention机制上也引入了Self-Attention和Context-Attention,下面结合Transformer架构图和Tensorflow实现了解一下Transformer

一、Transformer架构简说
Transformer是Encoder-Decoder架构,因此先整体分为Encoder、Decoder两部分
Encoder由6个相同的层组成,每层包含如下两部分:
第一部分:Multi-Head Attention多头注意力层
第二部分:Feed Forward全连接层
以上两部分都包含Residual Connection残差连接、Add&Norm数据归一化
Decoder也有6个相同的层组成,每层包含如下三部分:
第一部分:Masked Multi-Head Attention 经Sequence Mask处理的多头注意力层
第二部分:Multi-Head Attention
第三部分:Feed Forward全连接层
以上两部分都包含Residual Connection残差连接、Add&Norm数据归一化
二、Transformer模型细节理解
1、Encoder部分的输入是Input Embedding + Positional Embedding,Decoder部分的输入是Output Embedding + Positional Embedding,在MachineTranslation任务中,Input Embedding对应了输入的待翻译文本,Output Embedding对应了翻译后的文本
2、Encoder部分的Multi-Head Attention是self attention,对应输入的Q,k,V均相同是Input Embedding + Positional Embwedding,Decoder部分的Masked Multi-Head
Attention是self attention,对应的Q,K,V相同都是Output Embedding + Positional
Embedding,Decoder部分的Multi-Head Attention是Context attention,其中K,V相同来自于Encoder的输出memory,Q来自于Docoder词层的OutputEmbedding + Positional Embedding
3、Attention区别
self-attention和context-attention划分的区别是Attention衡量的是一个序列对自身的Attention权重还是一个序列对另一个序列的Attention权重,self-attention即计算自身的Attention权重,而Context-attention计算的是Encoder序列对Decoder序列的Attention权重;
ScaledDot-Product Attention和Multi-Head Attention划分是根据Attention权重计算方式,除了这些还有多种Attention权重计算方式,如下图所示

这里简单说一下Transformer中使用的Scaled Dot-Product Attention和Multi-Head
Attention
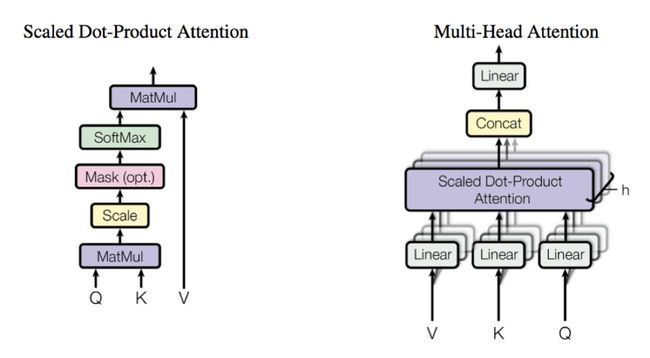
ScaledDot-Product Attention:通过Q,K矩阵计算矩阵V的权重系数

Multi-HeadAttention:多头注意力是将Q,K,V通过一个线性映射成h个Q,K,V,然后每个都计算Scaled Dot-Product Attention,最后再合起来,Multi-HeadAttention目的还是对特征进行更全面的抽取
4、Residual Connection残差连接原理及作用,先通过下图认识一下残差连接

如上图网络某层对输入x作用后输出是F(x),那么增加残差连接即是在原来F(x)上加上x,输出变成了F(x)+x,即+x操作即是残差连接,残差连接的作用是通过+x,在网络反向传播的时候会多出一个常数项1,防止梯度消失
5、masked区别
Transformer中有两种mask,一种是padding mask,一种是sequence mask
(1) Padding mask:每次批次输入序列的长度是不一样的,需要对序列进行对齐操作,具体做法以seq_length为标准,对大于seq_length的序列进行截断,对小于seq_length序列进行填充,但填充部分我们又不希望其被注意,因此填充部分为0,可以在填充位置加上一个负无穷大的数,这样经过softmax后便趋向于0
(2) Sequence mask:sequencemask是为了使得decodeer不能看到未来的解码信息,因为在transformer中,输出序列是训练的时候是全部一下子全部传入网络中的,不似RNN那种递归的形式,因此对于一个序列来说,在t时刻我们解码输出只应该依赖于t时刻之前的输出,而不应该看到t时刻之后的输出,如果看到了那就不需要解码了,因此我们需要将传入的解码数据进行sequence mask操作。具体操作是产生一个矩阵,矩阵的上三角全为1,对角线以及下三角全为0,再将该矩阵作用在Q,K产生的矩阵上便达到了对后续序列mask
在transformer中,Encoder中的Multi-Head Attention和Decoder中的Masked Multi-
HeadAttention以及Multi-Head Attention中都有Padding mask,Sequence mask只出现在Decoder的Masked Multi-Head Attention中
三、核心单元Tensorflow实现
下面通过Tensorflow中的代码看一下核心单元的具体实现,解释请看代码注释
1、Encoder
def encode(self, xs, training=True): ''' Returns memory: encoder outputs. (N, T1, d_model) ''' with tf.variable_scope("encoder", reuse=tf.AUTO_REUSE): x, seqlens, sents1 = xs # embedding: 计算word embedding和position embedding,使用word embedding+position embedding作为输入 enc = tf.nn.embedding_lookup(self.embeddings, x) # (N, T1, d_model) enc *= self.hp.d_model**0.5 # scale enc += positional_encoding(enc, self.hp.maxlen1) # dropout防止过拟合处理 enc = tf.layers.dropout(enc, self.hp.dropout_rate, training=training) # Blocks: num_blocks=6,Encoder部分叠加6层(multihead_attention+Feed Forward) # 注意Encoder部分的attention是self attention,因此query,key,value都等于输入enc # muultihead_attention函数参数num_heads=8,共计算八个attention # causality=False表明此处对Attention的mask操作是padding mask for i in range(self.hp.num_blocks): with tf.variable_scope("num_blocks_{}".format(i), reuse=tf.AUTO_REUSE): # self-attention enc = multihead_attention(queries=enc, keys=enc, values=enc, num_heads=self.hp.num_heads, dropout_rate=self.hp.dropout_rate, training=training, causality=False) # feed forward: 前向传播 enc = ff(enc, num_units=[self.hp.d_ff, self.hp.d_model]) memory = enc return memory, sents12、Decoder
def decode(self, ys, memory, training=True): ''' memory: encoder outputs. (N, T1, d_model) Returns logits: (N, T2, V). float32. y_hat: (N, T2). int32 y: (N, T2). int32 sents2: (N,). string. ''' with tf.variable_scope("decoder", reuse=tf.AUTO_REUSE): decoder_inputs, y, seqlens, sents2 = ys # embedding: 和Encoder部分输入大体一致,也是word embedding+position embedding dec = tf.nn.embedding_lookup(self.embeddings, decoder_inputs) # (N, T2, d_model) dec *= self.hp.d_model ** 0.5 # scale dec += positional_encoding(dec, self.hp.maxlen2) dec = tf.layers.dropout(dec, self.hp.dropout_rate, training=training) # Blocks: num_blocks=6,Decoder部分叠加6层(Masked multihead attention+multihead_attention+Feed Forward) # Masked multihead attention是self attention,因此query,key,value都等于输入enc # num_heads=8,其中causality=True表明此处除了有padding mask还有sequence mask # 第二个multihead attention部分是self attention,其中query=舒睿enc、key,value为Encoder部分输出memory for i in range(self.hp.num_blocks): with tf.variable_scope("num_blocks_{}".format(i), reuse=tf.AUTO_REUSE): # Masked self-attention (Note that causality is True at this time) dec = multihead_attention(queries=dec, keys=dec, values=dec, num_heads=self.hp.num_heads, dropout_rate=self.hp.dropout_rate, training=training, causality=True, scope="self_attention") # Vanilla attention dec = multihead_attention(queries=dec, keys=memory, values=memory, num_heads=self.hp.num_heads, dropout_rate=self.hp.dropout_rate, training=training, causality=False, scope="vanilla_attention") ### Feed Forward: 前向传播 dec = ff(dec, num_units=[self.hp.d_ff, self.hp.d_model]) # Final linear projection (embedding weights are shared) weights = tf.transpose(self.embeddings) # (d_model, vocab_size) logits = tf.einsum('ntd,dk->ntk', dec, weights) # (N, T2, vocab_size) y_hat = tf.to_int32(tf.argmax(logits, axis=-1)) return logits, y_hat, y, sents23、Multi-Head Attention
def multihead_attention(queries, keys, values, num_heads=8, dropout_rate=0, training=True, causality=False, scope="multihead_attention"): '''Applies multihead attention. See 3.2.2 queries: A 3d tensor with shape of [N, T_q, d_model]. keys: A 3d tensor with shape of [N, T_k, d_model]. values: A 3d tensor with shape of [N, T_k, d_model]. num_heads: An int. Number of heads. dropout_rate: A floating point number. training: Boolean. Controller of mechanism for dropout. causality: Boolean. If true, units that reference the future are masked. scope: Optional scope for `variable_scope`. Returns A 3d tensor with shape of (N, T_q, C) ''' d_model = queries.get_shape().as_list()[-1] with tf.variable_scope(scope, reuse=tf.AUTO_REUSE): # Linear projections: 在进行Scaled Dot-Product Attention前先对Q,K,V做一个线性变换 Q = tf.layers.dense(queries, d_model, use_bias=False) # (N, T_q, d_model) K = tf.layers.dense(keys, d_model, use_bias=False) # (N, T_k, d_model) V = tf.layers.dense(values, d_model, use_bias=False) # (N, T_k, d_model) # Split and concat: 将8个multi-heads线性变换后的Q,K,V各自做concat操作 Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, d_model/h) K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, d_model/h) V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, d_model/h) # Attention: Scaled Dot-Product Attention操作,causality区别是否进行sequence mask outputs = scaled_dot_product_attention(Q_, K_, V_, causality, dropout_rate, training) # Restore shape: 对8个multi-heads输出attention结果做concat操作 outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, d_model) # Residual connection: 残差连接操作 outputs += queries # Normalize: 归一化操作 outputs = ln(outputs) return outputs4、Scale-Dot-Product-Attention
def scaled_dot_product_attention(Q, K, V, causality=False, dropout_rate=0., training=True, scope="scaled_dot_product_attention"): '''See 3.2.1. Q: Packed queries. 3d tensor. [N, T_q, d_k]. K: Packed keys. 3d tensor. [N, T_k, d_k]. V: Packed values. 3d tensor. [N, T_k, d_v]. causality: If True, applies masking for future blinding dropout_rate: A floating point number of [0, 1]. training: boolean for controlling droput scope: Optional scope for `variable_scope`. ''' with tf.variable_scope(scope, reuse=tf.AUTO_REUSE): d_k = Q.get_shape().as_list()[-1] # dot product outputs = tf.matmul(Q, tf.transpose(K, [0, 2, 1])) # (N, T_q, T_k) # scale outputs /= d_k ** 0.5 # key masking: 对Q,K,outputs做padding mask操作 outputs = mask(outputs, Q, K, type="key") # causality or future blinding masking: 下面mask操作是sequence mask操作 if causality: outputs = mask(outputs, type="future") # softmax outputs = tf.nn.softmax(outputs) attention = tf.transpose(outputs, [0, 2, 1]) tf.summary.image("attention", tf.expand_dims(attention[:1], -1)) # query masking:最后对输出再做一次padding mask操作 outputs = mask(outputs, Q, K, type="query") # dropout outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=training) # weighted sum (context vectors) outputs = tf.matmul(outputs, V) # (N, T_q, d_v) return outputs5、Feed Forward
def ff(inputs, num_units, scope="positionwise_feedforward"): '''position-wise feed forward net. See 3.3 inputs: A 3d tensor with shape of [N, T, C]. num_units: A list of two integers. scope: Optional scope for `variable_scope`. Returns: A 3d tensor with the same shape and dtype as inputs ''' with tf.variable_scope(scope, reuse=tf.AUTO_REUSE): # Inner layer: 做两次前向传播全连接操作 outputs = tf.layers.dense(inputs, num_units[0], activation=tf.nn.relu) # Outer layer outputs = tf.layers.dense(outputs, num_units[1]) # Residual connection: 全连接层也做一次残差连接 outputs += inputs # Normalize: 归一化操作 outputs = ln(outputs)6、Positional Embedding
def positional_encoding(inputs, maxlen, masking=True, scope="positional_encoding"): '''Sinusoidal Positional_Encoding. See 3.5 inputs: 3d tensor. (N, T, E) maxlen: scalar. Must be >= T masking: Boolean. If True, padding positions are set to zeros. scope: Optional scope for `variable_scope`. returns 3d tensor that has the same shape as inputs. ''' E = inputs.get_shape().as_list()[-1] # static N, T = tf.shape(inputs)[0], tf.shape(inputs)[1] # dynamic with tf.variable_scope(scope, reuse=tf.AUTO_REUSE): # position indices position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1]) # (N, T) # First part of the PE function: sin and cos argument position_enc = np.array([ [pos / np.power(10000, (i-i%2)/E) for i in range(E)] for pos in range(maxlen)]) # Second part, apply the cosine to even columns and sin to odds. position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1 position_enc = tf.convert_to_tensor(position_enc, tf.float32) # (maxlen, E) # lookup outputs = tf.nn.embedding_lookup(position_enc, position_ind) # masks if masking: outputs = tf.where(tf.equal(inputs, 0), inputs, outputs) return tf.to_float(outputs)7、Mask
def mask(inputs, queries=None, keys=None, type=None): """Masks paddings on keys or queries to inputs inputs: 3d tensor. (N, T_q, T_k) queries: 3d tensor. (N, T_q, d) keys: 3d tensor. (N, T_k, d) e.g., >> queries = tf.constant([[[1.], [2.], [0.]]], tf.float32) # (1, 3, 1) >> keys = tf.constant([[[4.], [0.]]], tf.float32) # (1, 2, 1) >> inputs = tf.constant([[[4., 0.], [8., 0.], [0., 0.]]], tf.float32) >> mask(inputs, queries, keys, "key") array([[[ 4.0000000e+00, -4.2949673e+09], [ 8.0000000e+00, -4.2949673e+09], [ 0.0000000e+00, -4.2949673e+09]]], dtype=float32) >> inputs = tf.constant([[[1., 0.], [1., 0.], [1., 0.]]], tf.float32) >> mask(inputs, queries, keys, "query") array([[[1., 0.], [1., 0.], [0., 0.]]], dtype=float32) """ padding_num = -2 ** 32 + 1 # 其中type=k/q都是padding mask,type=feature是sequence mask if type in ("k", "key", "keys"): # Generate masks masks = tf.sign(tf.reduce_sum(tf.abs(keys), axis=-1)) # (N, T_k) masks = tf.expand_dims(masks, 1) # (N, 1, T_k) masks = tf.tile(masks, [1, tf.shape(queries)[1], 1]) # (N, T_q, T_k) # Apply masks to inputs paddings = tf.ones_like(inputs) * padding_num outputs = tf.where(tf.equal(masks, 0), paddings, inputs) # (N, T_q, T_k) elif type in ("q", "query", "queries"): # Generate masks masks = tf.sign(tf.reduce_sum(tf.abs(queries), axis=-1)) # (N, T_q) masks = tf.expand_dims(masks, -1) # (N, T_q, 1) masks = tf.tile(masks, [1, 1, tf.shape(keys)[1]]) # (N, T_q, T_k) # Apply masks to inputs outputs = inputs*masks elif type in ("f", "future", "right"): diag_vals = tf.ones_like(inputs[0, :, :]) # (T_q, T_k) tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k) masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(inputs)[0], 1, 1]) # (N, T_q, T_k) paddings = tf.ones_like(masks) * padding_num outputs = tf.where(tf.equal(masks, 0), paddings, inputs) else: print("Check if you entered type correctly!") return outputs8、Add&Norm
def ln(inputs, epsilon = 1e-8, scope="ln"): '''Applies layer normalization. See https://arxiv.org/abs/1607.06450. inputs: A tensor with 2 or more dimensions, where the first dimension has `batch_size`. epsilon: A floating number. A very small number for preventing ZeroDivision Error. scope: Optional scope for `variable_scope`. Returns: A tensor with the same shape and data dtype as `inputs`. ''' # Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据 # 我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区 # Batch Normalization: BN的主要思想就是:在每一层的每一批数据上进行归一化 with tf.variable_scope(scope, reuse=tf.AUTO_REUSE): inputs_shape = inputs.get_shape() params_shape = inputs_shape[-1:] mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True) beta= tf.get_variable("beta", params_shape, initializer=tf.zeros_initializer()) gamma = tf.get_variable("gamma", params_shape, initializer=tf.ones_initializer()) normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) ) outputs = gamma * normalized + beta return outputs
在看让我看到你哦,别偷偷摸摸的在看 