CBAM简介及pytorch实现
CBAM简介及pytorch实现
- 1.CBAM块简介
-
- 1.1 Channel Attention Module(CAM)
- 1.2 Spatial Attention Module(SAM)
- 2.pytorch实现代码
- 3.netron可视化
- 参考文献
1.CBAM块简介
在YOLO-V4的接触过程中,注意到了CBAM1这个注意力机制模块。
看了下CBAM官方pytorch实现,稍显繁琐,在此基础上略作改进。
本人关于YOLO_V4 的介绍见YOLO_V4 入手贴。
此块非常简洁,即一个channel attention块串上一个spatial attention块。
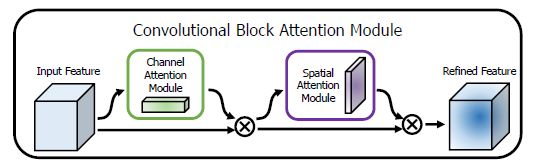
1.1 Channel Attention Module(CAM)
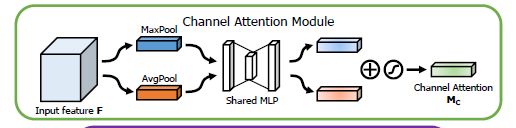
channel attention块的实现由maxpool+MLP、avgpool+MLP并行处理后相加,再通过一个sigmoid,输出各层权重系数:Mc。最后通过element_wise dot实现channel attention输出。
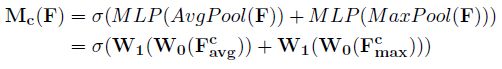
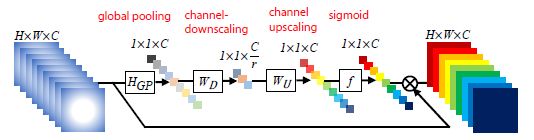
本人在实现此层时,参考了RCAN中的Channel attention Layer(CALayer),即没有使用MLP,而是通过Conv1*1实现down_scaling和up_scaling。RCAN中CALayer结构如下:
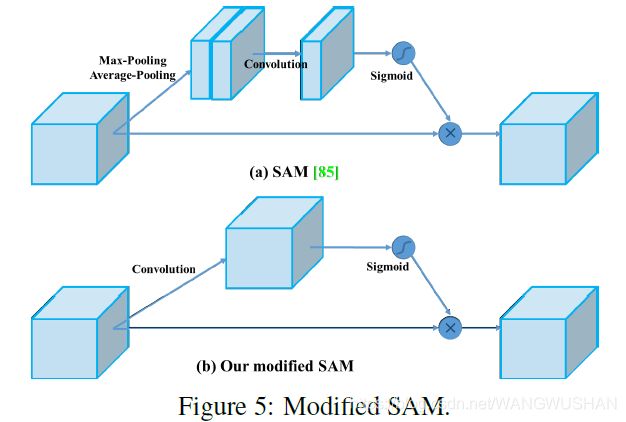
1.2 Spatial Attention Module(SAM)


这个就相对更简单了。沿着channel方向分别求Max和Avg,各得到size为batch1H*W的feature map,再在channel方向(即 dim 1)进行concat,然后通过卷积层将channel深度变为1,最后进行sigmoid(),得到spatial attention权重Ms。
在YOLOv4paper中将SAM层中的max/avg操作去掉,只通过conv将spatial_wise attention变为point_wise attention。
2.pytorch实现代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class CALayer(nn.Module): # Channel Attention (CA) Layer
def __init__(self, in_channels, reduction=16, pool_types=['avg', 'max']):
super().__init__()
self.pool_list = ['avg', 'max']
self.pool_types = pool_types
self.in_channels = in_channels
self.Pool = [nn.AdaptiveAvgPool2d(
1), nn.AdaptiveMaxPool2d(1, return_indices=False)]
self.conv_ca = nn.Sequential(
nn.Conv2d(in_channels, in_channels //
reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction,
in_channels, 1, padding=0, bias=True)
)
def forward(self, x):
for (i, pool_type) in enumerate(self.pool_types):
pool = self.Pool[self.pool_list.index(pool_type)](x)
channel_att_raw = self.conv_ca(pool)
if i == 0:
channel_att_sum = channel_att_raw
else:
channel_att_sum += channel_att_raw
scale = F.sigmoid(channel_att_sum)
return x * scale
class SALayer(nn.Module): # Spatial Attention Layer
def __init__(self):
super().__init__()
self.conv_sa = nn.Sequential(
nn.Conv2d(2, 1, 3, 1, 1, bias=False),
nn.BatchNorm2d(1, momentum=0.01),
nn.Sigmoid()
)
def forward(self, x):
x_compress = torch.cat(
(torch.max(x, 1, keepdim=True)[0], torch.mean(x, dim=1, keepdim=True)), dim=1)
scale = self.conv_sa(x_compress)
return x * scale
class CBAM(nn.Module):
def __init__(self, in_channels, reduction=2, pool_types=['avg', 'max']):
super().__init__()
self.CALayer = CALayer(
in_channels, reduction, pool_types)
self.SALayer = SALayer()
def forward(self, x):
x_out = self.CALayer(x)
x_out = self.SALayer(x_out)
return x_out
3.netron可视化
如输入tensor维度为 1 ∗ 6 ∗ 32 ∗ 32 1*6*32*32 1∗6∗32∗32:
if __name__ == '__main__':
import netron
x = torch.rand((1, 6, 32, 32))
cbam = CBAM(6, reduction=2)
o = cbam(x)
onnx_path = "D:\\onnx_model_name.onnx"
torch.onnx.export(cbam, x, onnx_path, opset_version=11)
netron.start(onnx_path)
可视化结果为:

当然也可以像RCAN中介绍的那样,添加shortcut,将其转为一个residual block。

参考文献
- CBAM: Convolutional Block Attention Module
- https://github.com/luuuyi/CBAM.PyTorch/blob/master/model/resnet_cbam.py
- RCAN:Image Super-Resolution Using Very Deep Residual Channel Attention Networks
- YOLOv4 paper
CBAM: Convolutional Block Attention Module ↩︎