智能决策上手系列教程索引
在上一篇我们介绍了获取基本Html网页数据的方法。
零基础十分钟上手网络数据抓取-Python-爬虫
这一篇我们看一下更复杂的情况,爬取Boss直聘这个招聘网站的招聘信息,进而简单分析人工智能行业的招聘情况。
1. 理解页面
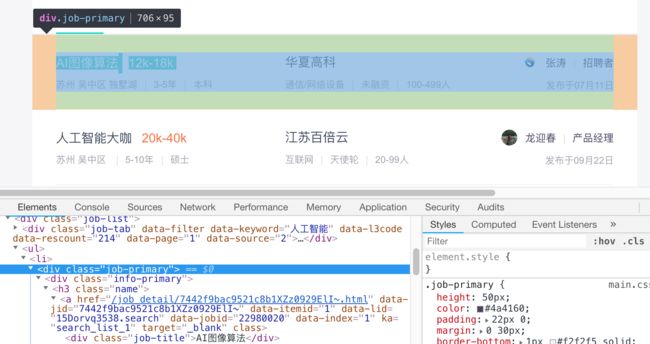
打开这个页面,这是Boss直聘网站苏州搜索“人工智能”职位得到的招聘职位列表,右键点击招聘职位名称(“AI图像算法”)然后【检查】打开Elements元素面板,如下图,注意当点击 如果我们在页面上【右击-显示网页源代码】可以看到竖向有两千多行的html标签代码,你可以在这里找到页面上看到的各个职位的对应文字,比如按【ctrl+F】搜索“华夏高科”就可以找到它。 使用阿里云天池的Notebook或者Anaconda的Jupyter Notebook都可以,编写以下代码,获取整个页面的html文件数据。 url是复制粘贴的浏览器地址,在这里中文部分自动变成了乱码,不用担心,一样可以使用。 运行这个代码,会output输出页面的标记代码,但你仔细看会发觉有什么不对,好像少了很多,而且会看到这个信息。 由于您当前网络访问页面过于频繁,可能存在安全风险,我们暂时阻止了您的本次访问,24小时将自动解除限制。 这表示服务器识别我们的请求是爬虫了! 还是在刚才的Boss直聘工作列表页面,右击检查之后,注意Elements元素面板边上还有【Network网络】面板,点开看上去如下图: Network网络面板包含了所有向服务器发出的请求的信息,如图所示,这一行 所以,浏览器向服务器发送的信息很多,除了基本的 我们改进一下代码: 再次运行,就可以得到完整的页面数据了。 改进后获取10页共300条招聘信息: 这里是有了几个新的知识点: 最终得到的Excel结果如下: 下面是利用上一篇文章介绍的Excel数据透视表方法绘制的统计图 注,300个职位数据规模还很小,而且由于Boss直聘的搜索问题,其中掺杂了大量的实际与人工智能无关的职位,我们的分析方法还是很原始很粗糙的,仅供参考。随着后续学习我们会逐步加深这方面的研究。 作为一个互联网或科技企业的你,一定很关注你当前的职位的分布情况吧,现在可以自己动手从Boss直聘网站的大数据上进行科学分析了! 如果要做更多的练习,还是推荐你花一点时间翻翻Html和Python的知识,不要有太大压力,用心阅读就可以,适当的时候可以跟着教程做做代码实验。 Html标签技术基础入门 如果您发现文章错误,请不吝留言指正; ENDdiv标记元素就对应一个招聘职位信息,就是我们要提取数据的基本单元。
2. 请求页面数据
url='https://www.zhipin.com/c101190400/h_101190400/?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page=1'
import requests
from bs4 import BeautifulSoup
html=requests.get(url)
print(html.text)
您暂时无法继续访问~
但是如果我们把网址复制到浏览器里,仍然可以正常打开的。这是为什么?
Python默认发送的请求和浏览器发送的请求是有不同的。最主要的不同就是浏览器发送的请求除了http地址之外还包含了看不到的header头信息。3. 认识请求头 Request header

?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page=1就是我们代码里面发送的那个请求,点击它,可以看到它的更多信息:
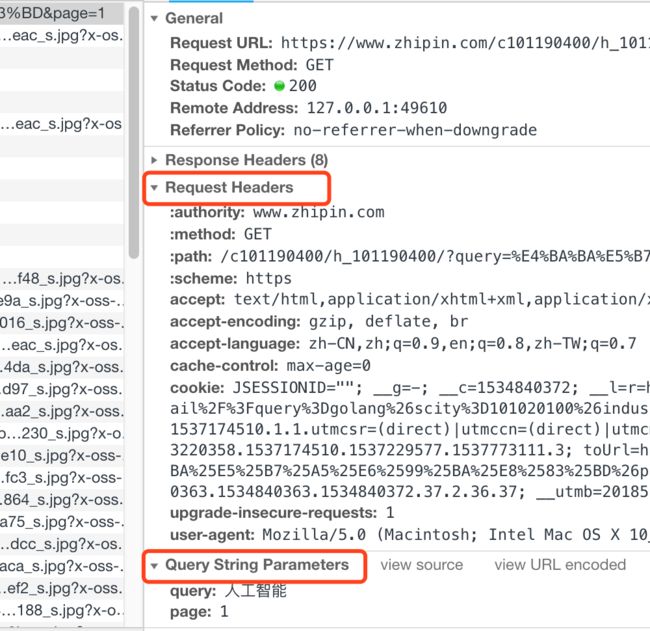
Request URL地址,还发送了Request Headers请求头和Query String Parameters查询字符串参数。
Query String Parameters很简单,其实就是我们地址栏最后?问号后面的部分?query=人工智能&page=1。
Request Headers请求头包含了很多信息,非常复杂,我们这里不逐个解释了,你可以稍后自己在里面搜索到相关教程,这里只重点解释其中三个。
User-agent用户代理字段,就是你使用的浏览器,默认情况Python发出的Request里面的这个信息是缺失的,所以服务器就发现你不是正常浏览器而是爬虫了。Referer(图中没有)来路,就是说这个链接从哪个页面点击打开的,有些时候服务器会检查你的request请求是否来自其他正常页面链接点击而不是爬虫。Cookie小甜饼,这个就复杂了,因为这个是每个网站服务器自己记录在你的浏览器的信息(是的,他们的服务器能操纵你的浏览器!),所以人家想记录什么就记录什么,最常见的是记录你的用户账户名和密码(一般会只记录你的编号就好了),这样你每次向服务器发送request的时候,服务器就能从header的cookie里面找到你的记录,知道是你在发送请求而不是其他人。
4. 添加请求头
url='https://www.zhipin.com/c101190400/h_101190400/?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page=1'
headers={
'user-agent':'Mozilla/5.0'
}
import requests
from bs4 import BeautifulSoup
html=requests.get(url,headers=headers)
print(html.text)
这里主要是添加了headers={...}对象(一对大括号包裹),headers对象只有一个user-agent字段属性,用冒号隔开它的值Mozilla/5.0(这里我们偷懒只留了开头Mozila火狐浏览器的信息)5. 循环获取更多内容
url='https://www.zhipin.com/c101020100/h_101020100/?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page='
headers={
'user-agent':'Mozilla/5.0'
}
page=1
hud=['职位名','薪资1','薪资2','职位名','地点','经验','学历','公司行业','融资阶段','公司人数','发布日期','发布人']
print('\t'.join(hud))
import requests
from bs4 import BeautifulSoup
import time
for n in range(1,11):
html=requests.get(url+str(page),headers=headers)
page+=1
soup = BeautifulSoup(html.text, 'html.parser')
for item in soup.find_all('div','job-primary'):
shuchu=[]
shuchu.append(item.find('div','job-title').string) #职位名
xinzi=item.find('span','red').string
xinzi=xinzi.replace('k','')
xinzi=xinzi.split('-')
shuchu.append(xinzi[0]) #薪资起始数
shuchu.append(xinzi[1]) #薪资起始数
yaoqiu=item.find('p').contents
shuchu.append(yaoqiu[0].string if len(yaoqiu)>0 else 'None') #地点
shuchu.append(yaoqiu[2].string if len(yaoqiu)>2 else 'None') #经验
shuchu.append(yaoqiu[4].string if len(yaoqiu)>4 else 'None') #学历
gongsi=item.find('div','info-company').find('p').contents
shuchu.append(gongsi[0].string if len(gongsi)>0 else 'None') #公司行业
shuchu.append(gongsi[2].string if len(gongsi)>2 else 'None') #融资阶段
shuchu.append(gongsi[4].string if len(gongsi)>4 else 'None') #公司人数
shuchu.append(item.find('div','info-publis').find('p').string.replace('发布于','')) #发布日期
shuchu.append(item.find('div','info-publis').find('h3').contents[3].string) #发布人
print('\t'.join(shuchu))
time.sleep(1)
'-'.join(hud)将列表集合['aa','bb','cc']合并成字符串'aa-bb-cc'。我们用\t拼合成最后输出shuchu的内容。集合.append(a),把a加入到集合最后面,之前是[b,c]的话就会变成[b,c,a]。我们用这个办法逐个的把数据添加到集合的每个单元中。字符串.split('-'),和join相反,split是把字符串切成很多单元,再组成集合,小括号内就是分隔符号,比如'aa-bb-cc'分割之后就成为`['aa','bb','cc']。import time和time.sleep(1),每次请求之后停止休息1秒,避免频繁发送请求被Boss直聘服务器屏蔽。如果我们请求的频率远超过正常人点击频率,那么很可能被服务器看出是爬虫,进而不再理睬我们的请求,也不会发送数据给我们。

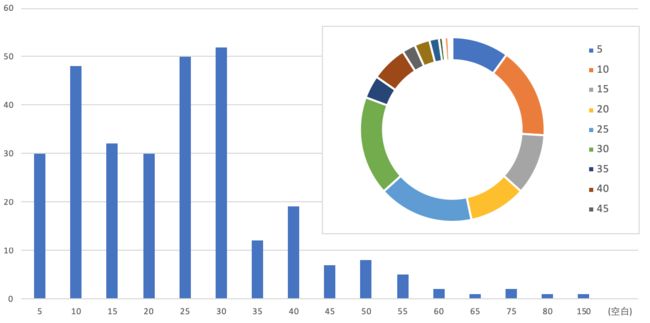
6. 后续学习资源
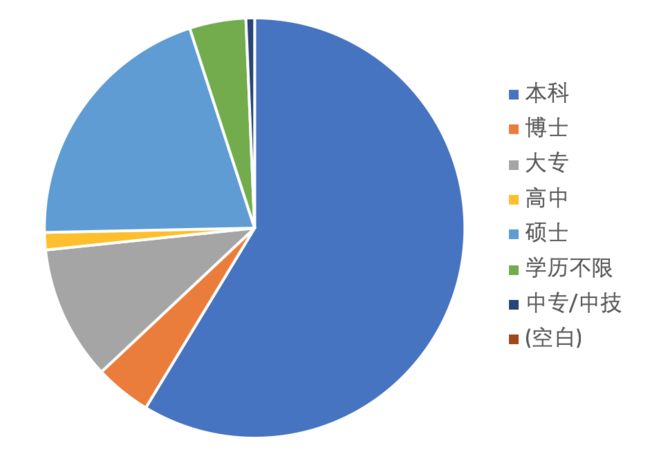
换一个城市,换一个行业,尝试更多的可能,从分析图表中总结规律,推测趋势。
Python基础入门教程
BeautifulSoup中文官方文档传送门
智能决策上手系列教程索引
每个人的智能决策新时代
如果您觉得有用,请点喜欢;
如果您觉得很有用,欢迎转载~