大数据,大数据,首先表示数据量非常大,一般至少是T级或者P级数据。数据量太大,就会遇到两个最直接的问题:数据如何存储?数据如何处理?
一、数据如何存储
大数据平台的数据存储文件系统是HDFS:Hadoop 分布式文件存储系统。
传统的文件存储系统是在单机上的,不能跨越不同的机器。现在常用的解决方案是一台机器上挂很多的NAS存储, 但是这种方案成本太高,数据量太大之后整个投入将变得非常昂贵。
所以,是否可以考虑,有一种新的文件系统,可以连接成千上万台机器,把数据平均分散存储到这些机器上,并且提供统一的管理方式。这种文件系统就是分布式文件存储系统。采用分布式文件系统后,当用户想读取一个文件,其实文件是存储在集群中很多机器上的,但是用户不需要关系到底是哪些机器,以及如果其中一台机器出现问题数据如何仍旧保持可读取等问题,这些HDFS都会在底层设计上解决。这个可以类似于我们在传统单机机器上读取一个文件,也不会关心文件分散在什么磁道什么扇区上一样,这些问题文件系统和操作系统会在底层处理。
现在可以理解,大数据生态的底层技术,就是HDFS,将数据分布存储在很多机器上,对外提供统一的管理。
二、数据如何处理
数据存储的问题解决后,接下来就是如何处理这些数据,毕竟存储数据的核心目的还是要让数据能够使用起来,而使用数据就要分析、计算和加工数据。
大数据由于数据量太大,如果采用传统的单台服务器的模式处理,则效率太低,通常一个计算可能需要几天甚至几周的时间。如何提高数据的处理效率?最简单的方法就是采用分布式,和HDFS思想一致,把一个计算任务进行分解,分解为很多独立的小的计算任务,然后将这些小的计算任务安排到很多机器上处理,这样就大大提升了整个数据处理的时间。
分布式计算, 要考虑几点:资源的合理分配,避免有些服务器资源繁忙有些服务器空闲;异常的可用性处理,避免一台机器故障导致整个数据处理受到影响;机器之间的通信机制,确保数据可在多台机器上交换完成复杂计算等。
从对数据的处理时效要求来看,可以将大数据处理分为两个领域,一个是批量处理,一个是实时处理。
1、批量处理:
Hadoop的第一代计算引擎是:MapReduce,Spark、Tez 是目前流行的第二代计算引擎;
1.1、MapReduce
MapReduce的核心原理其实从名称就可以看出,就是Map和Reduce。思想上就是先把一个大的计算逻辑进行分解,然后将这些分解的结果进行汇总,即先分解任务,分工处理后再汇总结果。一个Map加一个Reduce就是一个Job,对于一个很复杂的逻辑,其实可以分解为很多Job,所有的Job连起来实现复杂逻辑。但MapReuce最大的问题就是仍旧不够快(相比较传统的计算方式是很快了,但是还是达不到人们期望的程度),慢的原因主要是因为Map的中间结果要写文件,所有的Map结束后才能调起Reduce。如果语句复杂,则会有很多的Map输出中间结果数据到文件中,数据之间也不共享,那么大量的时间都浪费到读写磁盘I/O的延时和数据传输的通信开销上。
这里有一段描述,对MapReduce的处理过程描述的比较详细:
MapReduce是一种解决问题的程序开发模式,开发人员需要先分析待处理问题的解决流程,找出其中可以平行处理的部分,也就是那些能够被切成小段分开来处理的文件,再将这些能够采用平行处理的需求写成Map程序。
然后就可以使用大量服务器来执行Map程序,并将待处理的庞大文件切割成很多的小份文件,由每台服务器分别执行Map程序来处理分配到的那一小段文件,接着再将每一个Map程序分析出来的结果,透过Reduce程序进行合并,最后则汇整出完整的结果。
1.2、Spark
Spark是第二代分布式计算引擎,它是基于内存Cache,让Map和Reduce之间的界限更模糊,数据交换更灵活,通过更少的磁盘读写,更方便的描述复杂算法,取得更高的吞吐量,同时更易于程序编写。
Spark提供了一个全面的、统一的框架用于管理各种不同性质的数据集(文本数据、图表数据)和数据源(批量数据、实时流数据)。Spark允许程序开发者使用有向无环图开发复杂的多步数据管道,而且支持跨有向无环图的内存数据共享,以便不同的作业可以共同处理同一份数据。
Spark的高效,主要体现在运行、开发和集成方面:
- Spark的运行高效,主要体现在内存使用方面。Spark将中间结果保存在内存中而不是将其写入到磁盘中,当需要多次处理同一数据集时,优势非常明显。Spark是尽量将数据更多的写入到内存中,但是也支持剩余部分存储硬盘,所以是可以用于处理大于集群内存容量综合的数据集的。
- Spark的开发高效,主要体现在其提供了更多的高级API(MR只支持Map和Reduce),大大提升开发者的生产力。
-
Spark的集成高效,主要体现在Spark生态系统中还包括其他附加库。这些库有Spark Streaming、Spark SQL、Spark MLib、Spark GraphX,基本可以解决90%的用户需求,集成一个原生的库比集成一个其他的平台要容易且高效的多。
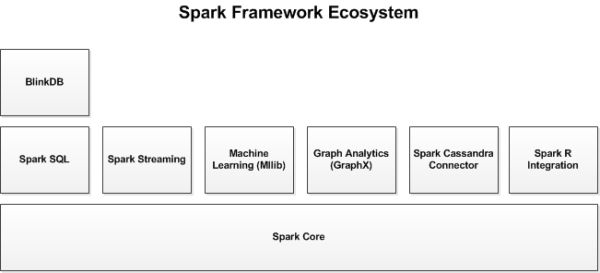 Spark框架中的库
Spark框架中的库
RDD(resilient distributed dataset:弹性分布式数据集)是Spark框架中的核心概念。它是一个特殊的集合(类似数据库中的视图),支持多种数据源,有容错机制,可以被缓存,支持并行操作,一个RDD代表一个分区里的数据集。RDD是不可变的,可以用转换(Transformation)修改RDD,但是整个转换返回的是一个新的RDD,原RDD不发生任何改变。
RDD支持两种类型的操作:
- 装换(Transformation):属于延迟计算(惰性计算),当一个RDD转换成另一个RDD时并没有立即转换,仅仅是记住了数据集的操作逻辑。
- 执行(Action):触发Spark作业的运行,真正触发转换算子的运行。
1.3、Hive
由于MapReduce是一个底层计算框架,要完成一个数据的分析工作,还是要进行一定的编码。所以在计算框架上,需要有更高层、更抽象的语言层来描述算法和数据处理流程,将编码变得更加通用,使用更简单直观的语言编写程序。目前Hadoop中比较流行的有Pig和Hive。
- Pig:用脚本方式描述MapReduce
- Hive:用SQL方式描述MapReduce
原理是把脚本和SQL翻译为MapReduce程序,交给计算引擎计算。
Hive的使用场景是数据仓库,基于Hadoop做一些数据清洗(ETL)、报表、数据分析,本质上是一个面向读、面向分析的SQL工具。但不适合做数据高频繁、高时效的插入、更新、删除。
Hive On Spark是从Hive on MapReduce演进而来,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算,充分利用Spark的快速执行能力来缩短HiveQL的响应时间,提高Hive查询的性能,为已经部署了Hive或者Spark的用户提供了更加灵活的选择。
与SparkSQL的区别
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案。Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL。这是Spark官方Databricks的项目,Spark项目本身主推的SQL实现。Hive On Spark比SparkSQL稍晚。Hive原本是没有很好支持MapReduce之外的引擎的,而Hive On Tez项目让Hive得以支持和Spark近似的Planning结构(非MapReduce的DAG)。所以在此基础上,Cloudera主导启动了Hive On Spark。这个项目得到了IBM,Intel和MapR的支持(但是没有Databricks)。结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序。
2、实时处理
实时处理目前最流行的两个平台是Storm和Spark Streaming,后续文章完善此部分内容。
- Storm
- Spark Streaming
还有一些是关于数据如何高效使用的,例如HBase等平台,提供KV数据存储。但KV数据结构的缺点是:无法处理复杂计算,无法JOIN,无法聚合,没有强一致性保证。
和大数据相关的服务组件还有:
- Mahout:是分布式机器学习库
- Protobuf:是数据交换的编码和库
- ZooKeeper:是高一致性的分布存取协同系统
- Yarn:调度系统
后续再继续学习补充!
参考文章:
知乎Xiaoyu Ma : 如何用形象的比喻描述大数据的技术生态?
InfoQ : 用Apache Spark进行大数据处理
IThome : 上手Hadoop不可不知的關鍵概念