pandas有两个很重要的的数据结构:Series和DataFrame,今天先学习Series的用法。
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。

1.png
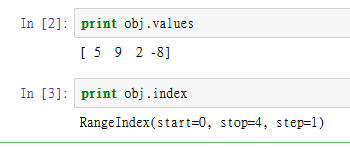
从结果可以看出Series的字符串表现形式为:索引在左边,值在右边。在上面的例子中我并没有为数据指定具体索引,它会自动创建一个0到N-1(N为数据的长度)的整数型索引。
2.png
3.png

4.png
5.png
6.png

7.png
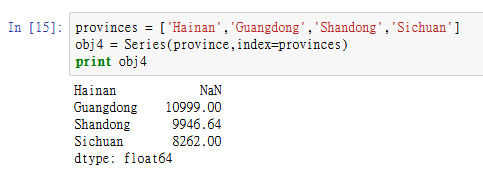
8.png
在上面的例子中,province中与provinces索引相匹配的3个值会被找出来并放到相对应的位置上,但是我给的"Hainan"在province中找不到,所以其结果为NaN(即“非数字”(not a number),在pandas中,它用于表示缺失或NA值)。

9.png

10.png
Series最重要的一个功能是:它在算术运算中会自动对齐不同索引的数据。
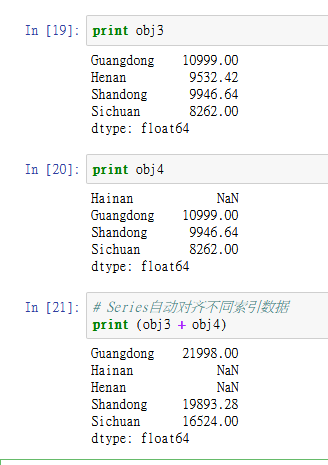
11.png

12.png
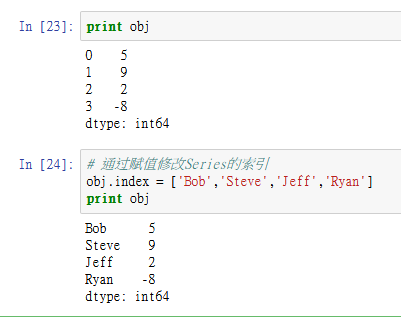
13.png
附源码:
# coding: utf-8
# In[1]:
import pandas as pd
from pandas import Series,DataFrame
obj = Series([5,9,2,-8])
print obj
# In[2]:
print obj.values
# In[3]:
print obj.index
# In[4]:
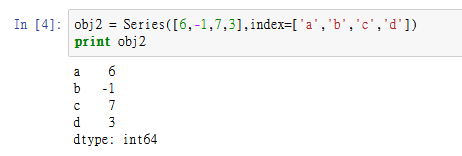
obj2 = Series([6,-1,7,3],index=['a','b','c','d'])
print obj2
# In[5]:
# 通过索引查找具体值
print obj2['b']
# In[6]:
# 替换值
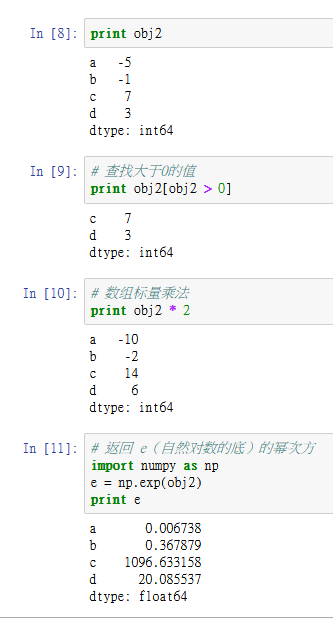
obj2['a'] = -5
print obj2
# In[7]:
# 通过索引查找一组值
print obj2[['a','b','c']]
# In[8]:
print obj2
# In[9]:
# 查找大于0的值
print obj2[obj2 > 0]
# In[10]:
# 数组标量乘法
print obj2 * 2
# In[11]:
# 返回 e(自然对数的底)的幂次方
import numpy as np
e = np.exp(obj2)
print e
# In[12]:
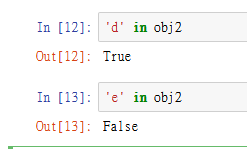
'd' in obj2
# In[13]:
'e' in obj2
# In[14]:
# Series与字典的用法
province = {'Guangdong':10999,'Shandong':9946.64,'Sichuan':8262,'Henan':9532.42}
obj3 = Series(province)
print obj3
# In[15]:
provinces = ['Hainan','Guangdong','Shandong','Sichuan']
obj4 = Series(province,index=provinces)
print obj4
# In[16]:
# 检测缺失数据
pd.isnull(obj4)
# In[17]:
# 检测不缺失的数据
pd.notnull(obj4)
# In[18]:
# Series检测缺失数据
obj4.isnull()
# In[19]:
print obj3
# In[20]:
print obj4
# In[21]:
# Series自动对齐不同索引数据
print (obj3 + obj4)
# In[22]:
# Series对象本身及其索引的name属性
obj4.name = 'population'
obj4.index.name = 'province'
print obj4
# In[23]:
print obj
# In[24]:
# 通过赋值修改Series的索引
obj.index = ['Bob','Steve','Jeff','Ryan']
print obj