一、数据爬取的代码
#encoding='utf-8'
from selenium import webdriver
import time
import re
import pandas as pd
import os
def close_windows():
#如果有登录弹窗,就关闭
try:
time.sleep(0.5)
if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("closeIcon"):
dr.find_element_by_class_name("jconfirm").find_element_by_class_name("closeIcon").click()
except BaseException as e:
print('close_windows,没有弹窗',e)
def get_current_region_job(k_index):
flag = 0
# page_num_set=0#每区获取多少条数据,对30取整
df_empty = pd.DataFrame(columns=['岗位', '地点', '薪资', '工作经验', '学历', '公司', '技能'])
while (flag == 0):
# while (page_num_set<151)&(flag == 0):#每次只能获取150条信息
time.sleep(0.5)
close_windows()
job_list = dr.find_elements_by_class_name("job-primary")
for job in job_list:#获取当前页的职位30条
job_name = job.find_element_by_class_name("job-name").text
# print(job_name)
job_area = job.find_element_by_class_name("job-area").text
salary = job.find_element_by_class_name("red").get_attribute("textContent") # 获取薪资
# salary_raw = job.find_element_by_class_name("red").get_attribute("textContent") # 获取薪资
# salary_split = salary_raw.split('·') # 根据·分割
# salary = salary_split[0] # 只取薪资,去掉多少薪
# if re.search(r'天', salary):
# continue
experience_education = job.find_element_by_class_name("job-limit").find_element_by_tag_name(
"p").get_attribute("innerHTML")
# experience_education_raw = '1-3年本科'
experience_education_raw = experience_education
split_str = re.search(r'[a-zA-Z =<>/"]{23}', experience_education_raw) # 搜索分割字符串
# print(split_str)
experience_education_replace = re.sub(r'[a-zA-Z =<>/"]{23}', ",", experience_education_raw) # 分割字符串替换为逗号
# print(experience_education_replace)
experience_education_list = experience_education_replace.split(',') # 根据逗号分割
# print('experience_education_list:',experience_education_list)
if len(experience_education_list)!=2:
print('experience_education_list不是2个,跳过该数据',experience_education_list)
break
experience = experience_education_list[0]
education = experience_education_list[1]
# print(experience)
# print(education)
company = job.find_element_by_class_name("company-text").find_element_by_class_name("name").text
skill_list = job.find_element_by_class_name("tags").find_elements_by_class_name("tag-item")
skill = []
for skill_i in skill_list:
skill_i_text = skill_i.text
if len(skill_i_text) == 0:
continue
skill.append(skill_i_text)
# print(job_name)
# print(skill)
df_empty.loc[k_index, :] = [job_name, job_area, salary, experience, education, company, skill]
k_index = k_index + 1
# page_num_set=page_num_set+1
print("已经读取数据{}条".format(k_index))
close_windows()
try:#点击下一页
cur_page_num=dr.find_element_by_class_name("page").find_element_by_class_name("cur").text
# print('cur_page_num',cur_page_num)
#点击下一页
element = dr.find_element_by_class_name("page").find_element_by_class_name("next")
dr.execute_script("arguments[0].click();", element)
time.sleep(1)
# print('点击下一页')
new_page_num=dr.find_element_by_class_name("page").find_element_by_class_name("cur").text
# print('new_page_num',new_page_num)
if cur_page_num==new_page_num:
flag = 1
break
except BaseException as e:
print('点击下一页错误',e)
break
print(df_empty)
if os.path.exists("数据.csv"):#存在追加,不存在创建
df_empty.to_csv('数据.csv', mode='a', header=False, index=None, encoding='gb18030')
else:
df_empty.to_csv("数据.csv", index=False, encoding='gb18030')
return k_index
def main():
# 打开浏览器
# dr = webdriver.Firefox()
global dr
dr = webdriver.Chrome()
# dr = webdriver.Ie()
# # 后台打开浏览器
# option=webdriver.ChromeOptions()
# option.add_argument('headless')
# dr = webdriver.Chrome(chrome_options=option)
# print("打开浏览器")
# 将浏览器最大化显示
dr.maximize_window()
# 转到目标网址
# dr.get("https://www.zhipin.com/job_detail/?query=Python&city=100010000&industry=&position=")#全国
dr.get("https://www.zhipin.com/c101010100/?query=Python&ka=sel-city-101010100")#北京
print("打开网址")
time.sleep(5)
k_index = 0#数据条数、DataFrame索引
flag_hot_city=0
for i in range(3,17,1):
# print('第',i-2,'页')
# try:
# 获取城市
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
close_windows()
# hot_city_list[i].click()#防止弹窗,改为下面两句
# element_hot_city_list_first = hot_city_list[i]
dr.execute_script("arguments[0].click();", hot_city_list[i])
# 输出城市名
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
print('城市:{}'.format(i-2),hot_city_list[i].text)
time.sleep(0.5)
# 获取区县
for j in range(1,50,1):
# print('第', j , '个区域')
# try:
# close_windows()
# hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
# 在这个for循环点一下城市,不然识别不到当前页面已经更新了
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
close_windows()
# hot_city_list[i].click()#防止弹窗,改为下面
dr.execute_script("arguments[0].click();", hot_city_list[i])
#输出区县名称
close_windows()
city_district = dr.find_element_by_class_name("condition-district").find_elements_by_tag_name("a")
if len(city_district)==j:
print('遍历完所有区县,没有不可点击的,跳转下一个城市')
break
print('区县:',j, city_district[j].text)
# city_district_value=city_district[j].text#当前页面的区县值
# 点击区县
close_windows()
city_district= dr.find_element_by_class_name("condition-district").find_elements_by_tag_name("a")
close_windows()
# city_district[j].click()]#防止弹窗,改为下面两句
# element_city_district = city_district[j]
dr.execute_script("arguments[0].click();", city_district[j])
#判断区县是不是点完了
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
print('点击后这里应该是区县', hot_city_list[1].text)#如果是不限,说明点完了,跳出
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
print('如果点完了,这里应该是不限:',hot_city_list[1].text)
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
if hot_city_list[1].text == '不限':
print('当前区县已经点完了,点击下一个城市')
flag_hot_city=1
break
close_windows()
k_index = get_current_region_job(k_index)#获取职位,爬取数据
# 重新点回城市页面,再次获取区县。但此时多了区县,所以i+1
close_windows()
hot_city_list = dr.find_element_by_class_name("condition-city").find_elements_by_tag_name("a")
close_windows()
# hot_city_list[i+1].click()#防止弹窗,改为下面两句
# element_hot_city_list_again = hot_city_list[i+1]
dr.execute_script("arguments[0].click();", hot_city_list[i+1])
# except BaseException as e:
# print('main的j循环-获取区县发生错误:', e)
# close_windows()
time.sleep(0.5)
# except BaseException as e:
# print('main的i循环发生错误:',e)
# close_windows()
time.sleep(0.5)
# 退出浏览器
dr.quit()
# p1.close()
if __name__ == '__main__':
main()
二、获取到的数据如图所示
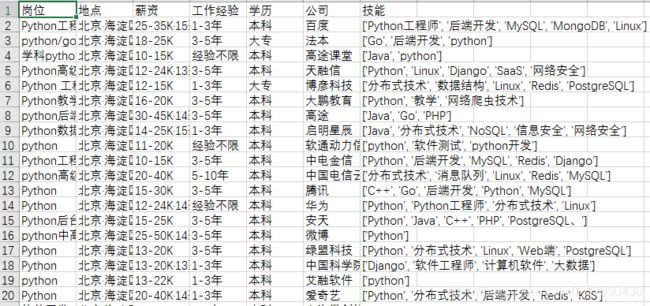
三、数据分析的代码
# coding=utf-8
import collections
import wordcloud
import re
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号
def create_dir_not_exist(path): # 判断文件夹是否存在,不存在-新建
if not os.path.exists(path):
os.mkdir(path)
create_dir_not_exist(r'./image')
create_dir_not_exist(r'./image/city')
data = pd.read_csv('数据.csv', encoding='gb18030')
data_df = pd.DataFrame(data)
print("\n查看是否有缺失值\n", data_df.isnull().sum())
data_df_del_empty = data_df.dropna(subset=['岗位'], axis=0)
# print("\n删除缺失值‘岗位'的整行\n",data_df_del_empty)
data_df_del_empty = data_df_del_empty.dropna(subset=['公司'], axis=0)
# print("\n删除缺失值‘公司'的整行\n",data_df_del_empty)
print("\n查看是否有缺失值\n", data_df_del_empty.isnull().sum())
print('去除缺失值后\n', data_df_del_empty)
data_df_python_keyword = data_df_del_empty.loc[data_df_del_empty['岗位'].str.contains('Python|python')]
# print(data_df_python_keyword)#筛选带有python的行
# 区间最小薪资
data_df_python_keyword_salary = data_df_python_keyword['薪资'].str.split('-', expand=True)[0]
print(data_df_python_keyword_salary) # 区间最小薪资
# Dataframe新增一列 在第 列新增一列名为' ' 的一列 数据
data_df_python_keyword.insert(7, '区间最小薪资(K)', data_df_python_keyword_salary)
print(data_df_python_keyword)
# 城市地区
data_df_python_keyword_location_city = data_df_python_keyword['地点'].str.split('·', expand=True)[0]
print(data_df_python_keyword_location_city) # 北京
data_df_python_keyword_location_district = data_df_python_keyword['地点'].str.split('·', expand=True)[1]
print(data_df_python_keyword_location_district) # 海淀区
data_df_python_keyword_location_city_district = []
for city, district in zip(data_df_python_keyword_location_city, data_df_python_keyword_location_district):
city_district = city + district
data_df_python_keyword_location_city_district.append(city_district)
print(data_df_python_keyword_location_city_district) # 北京海淀区
# Dataframe新增一列 在第 列新增一列名为' ' 的一列 数据
data_df_python_keyword.insert(8, '城市地区', data_df_python_keyword_location_city_district)
print(data_df_python_keyword)
data_df_python_keyword.insert(9, '城市', data_df_python_keyword_location_city)
data_df_python_keyword.insert(10, '地区', data_df_python_keyword_location_district)
data_df_python_keyword.to_csv("data_df_python_keyword.csv", index=False, encoding='gb18030')
print('-------------------------------------------')
def draw_bar(row_lable, title):
figsize_x = 10
figsize_y = 6
global list1_education, list2_education, df1, df2
plt.figure(figsize=(figsize_x, figsize_y))
list1_education = []
list2_education = []
for df1, df2 in data_df_python_keyword.groupby(row_lable):
list1_education.append(df1)
list2_education.append(len(df2))
# print(list1_education)
# print(list2_education)
# 利用 * 解包方式 将 一个排序好的元组,通过元组生成器再转成list
# print(*sorted(zip(list2_education,list1_education)))
# print(sorted(zip(list2_education,list1_education)))
# 排序,两个列表对应原始排序,按第几个列表排序,注意先后位置
list2_education, list1_education = (list(t) for t in zip(*sorted(zip(list2_education, list1_education))))
plt.bar(list1_education, list2_education)
plt.title('{}'.format(title))
plt.savefig('./image/{}分析.jpg'.format(title))
# plt.show()
plt.close()
# 学历
draw_bar('学历', '学历')
draw_bar('工作经验', '工作经验')
draw_bar('区间最小薪资(K)', '14个热门城市的薪资分布情况(K)')
# -----------------------------------------
# 根据城市地区求均值
list_group_city1 = []
list_group_city2 = []
for df1, df2 in data_df_python_keyword.groupby(data_df_python_keyword['城市地区']):
# print(df1)
# print(df2)
list_group_city1.append(df1)
salary_list_district = [int(i) for i in (df2['区间最小薪资(K)'].values.tolist())]
district_salary_mean = round(np.mean(salary_list_district), 2) # 每个区县的平均薪资 round(a, 2)保留2位小数
list_group_city2.append(district_salary_mean)
list_group_city2, list_group_city1 = (list(t) for t in
zip(*sorted(zip(list_group_city2, list_group_city1), reverse=False)))
#
# print(list_group_city1)
# print(list_group_city2)
plt.figure(figsize=(10, 50))
plt.barh(list_group_city1, list_group_city2)
# 坐标轴上的文字说明
for ax, ay in zip(list_group_city1, list_group_city2):
# 设置文字说明 第一、二个参数:坐标轴上的值; 第三个参数:说明文字;ha:垂直对齐方式;va:水平对齐方式
plt.text(ay, ax, '%.2f' % ay, ha='center', va='bottom')
plt.title('14个热门城市的各区县招聘工资情况(K)')
plt.savefig('./image/14个热门城市的各区县招聘工资情况(K).jpg')
# plt.show()
plt.close()
# -----------------------------------------
# 根据城市分组排序,
list_group_city11 = []
list_group_city22 = []
list_group_city33 = []
list_group_city44 = []
for df_city1, df_city2 in data_df_python_keyword.groupby(data_df_python_keyword['城市']):
# print(df_city1)#市
# print(df_city2)
list_group_district2 = [] # 区县列表
district_mean_salary2 = [] # 工资均值列表
for df_district1, df_district2 in df_city2.groupby(data_df_python_keyword['地区']):
# print(df_district1)#区县
# print(df_district2)#工作
list_group_district2.append(df_district1) # 记录区县
salary_list_district2 = [int(i) for i in (df_district2['区间最小薪资(K)'].values.tolist())] # 工资列表
district_salary_mean2 = round(np.mean(salary_list_district2), 2) # 每个区县的平均薪资 round(a, 2)保留2位小数
district_mean_salary2.append(district_salary_mean2) # 记录区县的平均工作的列表
district_mean_salary2, list_group_district2 = (list(tt) for tt in zip(
*sorted(zip(district_mean_salary2, list_group_district2), reverse=True)))
plt.figure(figsize=(10, 6))
plt.bar(list_group_district2, district_mean_salary2)
# 坐标轴上的文字说明
for ax, ay in zip(list_group_district2, district_mean_salary2):
# 设置文字说明 第一、二个参数:坐标轴上的值; 第三个参数:说明文字;ha:垂直对齐方式;va:水平对齐方式
plt.text(ax, ay, '%.2f' % ay, ha='center', va='bottom')
plt.title('14个热门城市的各区县招聘工资情况_{}(K)'.format(df_city1))
plt.savefig('./image/city/14个热门城市的各区县招聘工资情况_{}(K).jpg'.format(df_city1))
# plt.show()
plt.close()
# ----------------------------------------------------
skill_all = data_df_python_keyword['技能']
print(skill_all)
skill_list = []
for i in skill_all:
# print(type(i))
print(i)
# print(i.split(", | ' | \[ | \] | \" | "))
result = re.split(r'[,\' \[, \] ]', i)
print(result)
# if type(i) == list:
skill_list = skill_list + result
print('++++++++++++++++++++++++++++++++')
# print(skill_list)
list_new = skill_list
# 词频统计
word_counts = collections.Counter(list_new) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(30) # 获取前10最高频的词
# print (word_counts_top10) # 输出检查
# print (word_counts_top10[0][0]) # 输出检查
# 生成柱状图
list_x = []
list_y = []
for i in word_counts_top10:
list_x.append(i[0])
list_y.append(i[1])
print('list_x', list_x[1:])
print('list_y', list_y[1:])
plt.figure(figsize=(30, 5))
plt.bar(list_x[1:], list_y[1:])
plt.savefig('./image/技能栈_词频_柱状图.png')
# plt.show()
plt.close()
list_new = " ".join(list_new) # 列表转字符串,以空格间隔
# print(list_new)
wc = wordcloud.WordCloud(
width=800,
height=600,
background_color="#ffffff", # 设置背景颜色
max_words=50, # 词的最大数(默认为200)
max_font_size=60, # 最大字体尺寸
min_font_size=10, # 最小字体尺寸(默认为4)
# colormap='bone', # string or matplotlib colormap, default="viridis"
colormap='hsv', # string or matplotlib colormap, default="viridis"
random_state=20, # 设置有多少种随机生成状态,即有多少种配色方案
# mask=plt.imread("mask2.gif"), # 读取遮罩图片!!
font_path='simhei.ttf'
)
my_wordcloud = wc.generate(list_new)
plt.imshow(my_wordcloud)
plt.axis("off")
# plt.show()
wc.to_file('./image/技能栈_词云.png') # 保存图片文件
plt.close()
四、学历分析

五、工作经验分析
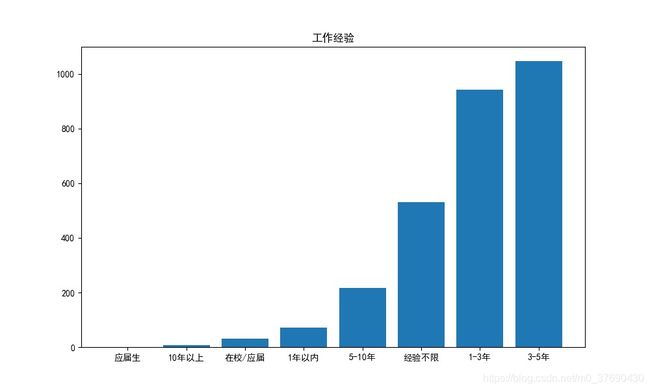
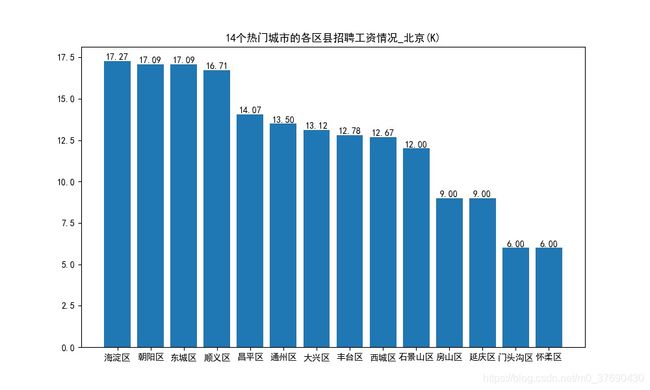
六、14个热门城市的各区县招聘薪资情况

七、各城市各区县的薪资情况
北京
上海
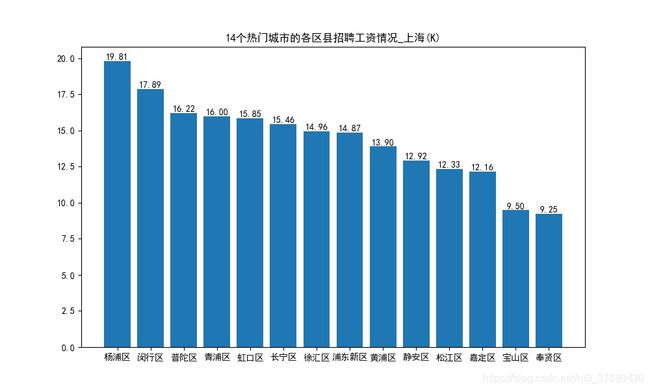
其余12个城市不再展示,生成代码都一样
八、技能栈


到此这篇关于Python数据分析之Python和Selenium爬取BOSS直聘岗位的文章就介绍到这了,更多相关Python和Selenium爬取BOSS直聘内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!