JAVA编程实现hdfs功能常见的问题
【报错】org.apache.hadoop.security.AccessControlException: Permission denied: user=yuanZmy, access=WRITE,
这样的报错说明自己在hdfs的根目录的权限不足,解决方法参见如下博客:
【https://blog.csdn.net/qq_24520639/article/details/53726393】
【https://blog.csdn.net/lunhuishizhe/article/details/50489849】
在windows上运行java访问hdfs需要准备的前提条件:
- (默认你的版本是3.x版本)将下面百度网盘链接里的hadoop-3.1.0的文件夹下载下载,放在一个目录下,然后配置环境变量(系统变量):
链接:https://pan.baidu.com/s/1JlT-oBOCIsWcRJxJvi9Hpg
提取码:3hx6

然后在path下添加如下内容:
%HADOOP_HOME%\bin
- 为了保证能访问hdfs,即通过:hadoop01:9870能访问到这个界面:
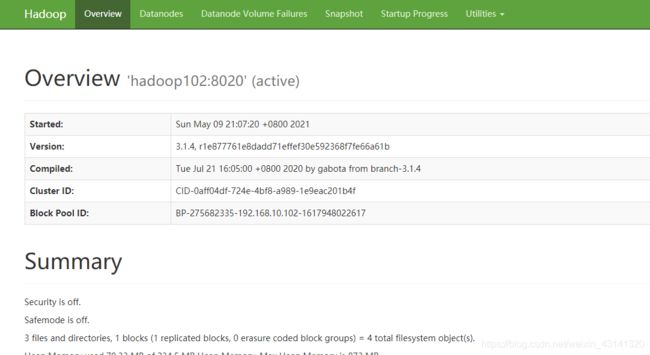
需要在C:\Windows\System32\drivers\etc路径下,将集群的所有节点的ip+主机名的格式将所有的结点添加进来,比如我的:
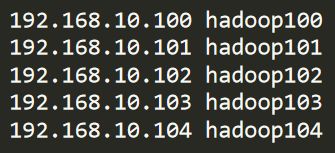
因为我用的是自己电脑上的虚拟机搭建的集群,所以添加的就全是192.168开头的ip,如果是云服务器添加公网ip为好。 - 还是环境变量,添加
HADOOP_USER_NAME,值为hadoop(这个值与自己的服务器的用户名一致),如下:

- 在main主函数中需要添加如下内容(如果没有添加造成问题了,可以添加然后看看是否解决问题)
Configuration conf = new Configuration();
conf.set("fs.defaultFS",HDFS);
conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
conf.set("dfs.client.use.datanode.hostname","true");
【报错】Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try

这种错误是集群只有3个或者更少结点的时候由于重负载造成,将如下的内容添加到hdfs-site.xml文件中:
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enablename>
<value>truevalue>
property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policyname>
<value>NEVERvalue>
property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.best-effortname>
<value>falsevalue>
property>
参考:
【https://smartechie.com/solved-failed-to-replace-a-bad-datanode-on-the-existing-pipeline-due-to-no-more-good-datanodes-being-available-to-try/】
【https://blog.csdn.net/TheManOfCoding/article/details/79512754】
【报错】Filesystem closed

这个时候可以查看一下自己的FileSystem对象创建与关闭的顺序,首先看看我的代码:

貌似是正常的,但是我还有一句:this.exists(remoteDir),这个exists函数的内容如下:
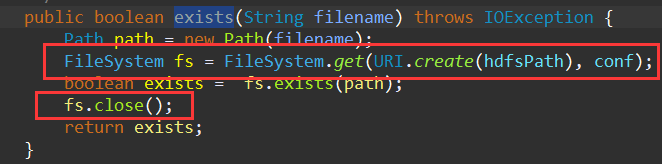
发现这里也创建了一个FileSystem对象,函数的结束的地方调用了fs.close()。
【出错原因】:io通信有关,然后都出现在操作Hadoop的FileSystem那段代码。创建FileSystem的时候读取配置"fs.%s.impl.disable.cache",默认为false,所以第二次走了缓存, FileSystem的URI相同的话,一定只创建一个FileSystem。涉及到多线程访问,而exists函数中创建的filesystem对象已经调用了filesystem.close()方法,这个时候外部的filesystem对象还在操作filesystem,所以报错。
【解决方法1】:调换FileSystem fs = FileSystem.get(URI.create(hdfspath), conf);的位置:
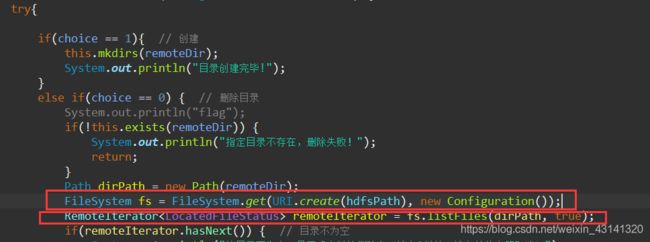
【解决方法2】:代码同步(用synchronized、lock这些都行)
【解决方法3】:通过代码禁用缓存
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl.disable.cache", "true");
【解决方法4】:
<property>
<name>fs.hdfs.impl.disable.cachename>
<value>truevalue>
property>
【reference】
如何在控制台打印日志
在自己的maven项目中找到src/main/resources路径:
在该路径下新建一个log4j.properties文件,里面的内容为:
# Set root logger level to DEBUG and its only appender to A1.
log4j.rootLogger=DEBUG, A1
# A1 is set to be a ConsoleAppender.
log4j.appender.A1=org.apache.log4j.ConsoleAppender
# A1 uses PatternLayout.
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
重新运行代码就可以打印出来了
【reference】
运行mapreduce实例(如果不输出日志)控制台无任何报错信息,hdfs输出文件夹为空
在控制台输出的logs信息有如下几处关键的地方:
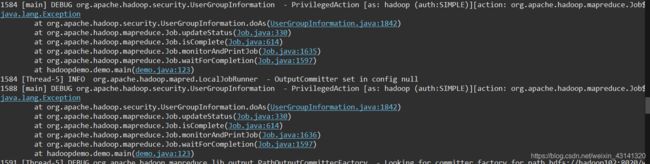

上面这个截图没有完整,右边还有一些信息如下:
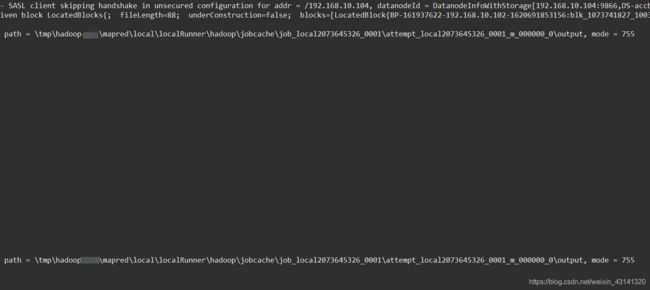

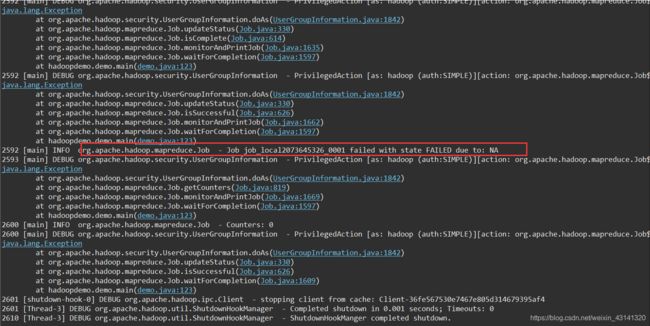
我将mapreduce文件和main文件分开的,上面的内容是main文件运行的日志,下面记录一下mapreduce代码文件里的日志输出:
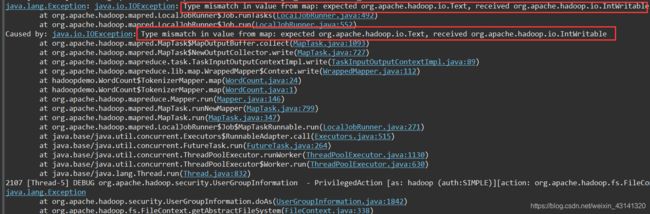
看到这里其实基本上心里有数了,应该是map和reduce阶段的数据类型不匹配造成的。修改如下:
我修改之前的main函数代码:
Job job = Job.getInstance(conf, "word count");
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(inputpath));
FileOutputFormat.setOutputPath(job, new Path(outputpath));
job.waitForCompletion(true);
修改之后的:
Job job = Job.getInstance(conf, "word count");
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
if(tool.exists(HDFS + hdfspath + "output")) tool.rmrDir(HDFS + hdfspath + "output");
FileInputFormat.addInputPath(job, new Path(HDFS + hdfspath + "input"));
FileOutputFormat.setOutputPath(job, new Path(HDFS + hdfspath + "output"));
job.waitForCompletion(true);
【reference1】
【reference2】