yolov3预训练模型_YOLOV3目标检测算法的模型训练教程
1. 模型训练环境:
1) 系统:Ubuntu16.042) 显卡:TITAN XP3)CUDA:9.14) CUDNN:7.55) 运行内存32G6)pycharm7)anaconda2. 资源的下载:
基于darknet框架在Linux系统下训练YOLOV3数据集,下载darknet文件,链接: https://download.csdn.net/download/qq_41900772/11340101 。
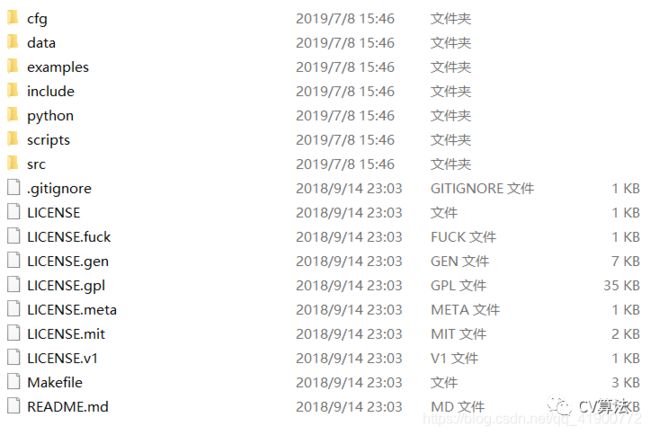
YOLOV3算法模型训练主要用到文件夹中的:cfg、data,以及后文中所建立的数据集。
文件夹中的各个文件夹的作用:
1)cfg:cfg文件夹中主要存放了网络训练所需要的网络配置文件2)data:主要存放了,网络测试所需测试图片、网络训练所需训练类别名文件(如:voc.names、coco.names)3)example:主要存放了可能会用到的一些函数评价接口。4)python:存放了网络对应的python接口。5)Makefile文件为训练所需的最重要的配置文件。3. VOC格式的数据集的制作
在主目录下建立文件夹VOC,在该文件夹下建立数据集。3.1 数据集目录:
1.VOCdevkit #根目录 1.1VOC2019 #不同年份的数据集,名称年份可以改 1.1.1Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等 1.1.2ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本 1.1.2.1Action(训练过程中用不到) 1.1.2.2Layout(训练过程中用不到) 1.1.1.3Main 1.1.1.4Segmentation(训练过程中用不到) 1.1.3JPEGImages #存放源图片 1.1.4SegmentationClass #存放的是图片,语义分割相关(训练过程中用不到) 1.1.5SegmentationObject #存放的是图片,实例分割相关(训练过程中用不到)3.2 制作数据集:1)根据上目录建立数据集2)加纳所有图片名称进行重排序3)将训练图片放入JPEGImages文件夹中4)采用Imagelabel工具对训练图片进行标注,生成xml文件5)将上一步所生成的xml文件放入(注意:图片与xml文件要一一对应)6)在Main文件夹下生成train.txt、test.txt两个文件,两个文件中为训练图片的名字7)将xml文件转换成txt格式文件
3.3 Main文件夹下的文件
根据xml文件生成与xml文件相对应的数据单序列,分为训练集与测试集,数据名要存放在Main文件夹下的.txt文件中以作备用
将以下代码放进python文档中,并把文档放在VOC2019文件下
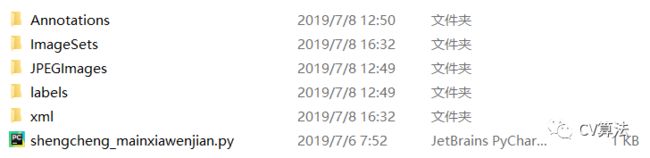
//文件名: shengcheng_Mai_wenjian.py import os import random trainval_percent = 0.1 train_percent = 0.9 xmlfilepath = 'Annotations' txtsavepath = 'ImageSets\Main' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) ftrainval = open('ImageSets/Main/test.txt', 'w') ftrain = open('ImageSets/Main/train.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) else: ftrain.write(name) ftrainval.close() ftrain.close()3.4 将.xml文件转换到.txt文件
从.xml文件到VOC2019文件夹中“label”文件夹中的.txt文件(标注图像的坐标及中心点信息),同时,在VOCdevkit同级文件夹下生成train.txt、test.txt两个文件,两个文件的内容为训练图片的路径(该步骤提取训练所需要的信息)
将以下代码放在python文档中,并把文档放在与VOCdevkit同级目录下。
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join from multiprocessing import Pool sets=[('2019', 'train'), ('2019', 'test')] classes = ['logo','number','face'] def convert(size, box): dw = 1./size[0] dh = 1./size[1] x = (box[0] + box[1])/2.0 y = (box[2] + box[3])/2.0 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(year, image_id): in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for year, image_set in sets: if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)): os.makedirs('VOCdevkit/VOC%s/labels/'%(year)) image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() list_file = open('%s_%s.txt'%(year, image_set), 'w') for image_id in image_ids: list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id)) convert_annotation(year, image_id) list_file.close()执行完上程序后,在VOC2019文件夹中会生成一个“label”文件夹,文件夹中会得生成.txt文件,同时,会在VOCdevkit同级文件夹下生成2019_train.txt、2019_test.txt两个文件,两个文件的内容为训练图片的路径
将程序中的classes改为自己的类别名儿,将xml、txt文件的路径该为自己的路径(在Windows系统下路径下使用“\”、Linux系统下的路径用“/”)
3.5 制作数据集总结
按照VOC数据集的结构搭建好框架后,将训练图片、对应xml文件以及以上两个程序,放到相应位置,修改好程序中相应信息,进行执行程序并检查相应的文件生成情况,检查无误,数据集制作完成。接下来进行训练过程中相关配置文件的配置工作。
----------------------至此,数据集制作完成---------------------------
4. 接下来进行文件的配置
文件配置过程需要进行配置的文件:
Makefikle文件配置(最重要) voc.data(数据集文件配置)文件配置、 voc.names(训练过程中的类别名儿,在voc.data文件中调用)文件配置、 yolov3.cfg文件配置4.1 Makefile文件配置
Linux中Makefile文件配置工作非常重要。在Linux中使用Mousepad编译器或者pycharm编译器打开,不要使用默认的gcc编译器打开。打开后界面如下图所示:
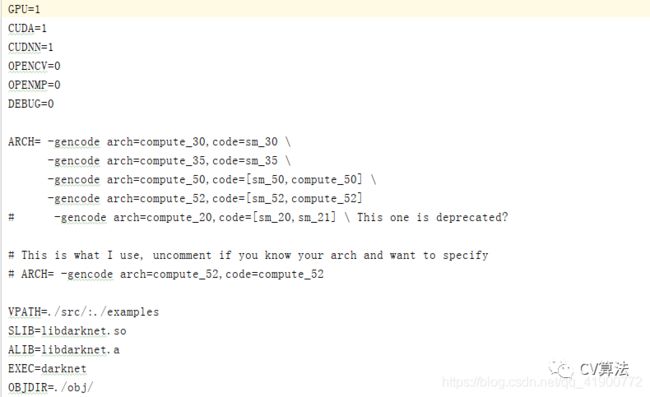
YOLOV3中,在Makefile文件配置时根据自己设备情况进行配置,配置前四行即可,GPU、CUDA、CUDNN、OPENCV(2/3版本置1),其他不需要修改。Makefile文件配置完成后再主目录下右键打开终端,输入命令:make,回车完成编译。
4.2 voc.data文件配置
打开cfg文件夹下的voc.data文件,打开文件后界面如下:

在该文件中内容主要包括:
classese:类别数量 train:路径为voc数据集文件夹下的2019_train.txt文件的路径 test:路径为voc数据集文件夹 下的2019_test.txt文件的路径 names:为data文件夹下的voc.names backup:为主目录下backup文件夹(主要用来存放训练生成的.weights文件(模型)和.backup文件(用于训练过程中断后继续训练时所用文件)) eval:为voc评价标准4.3 voc.names文件配置
在该文件中下训练时类的名称。
4.4 yolov3.cfg配置
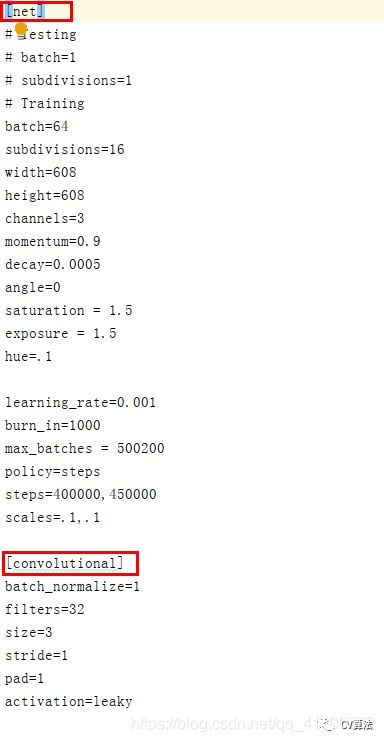
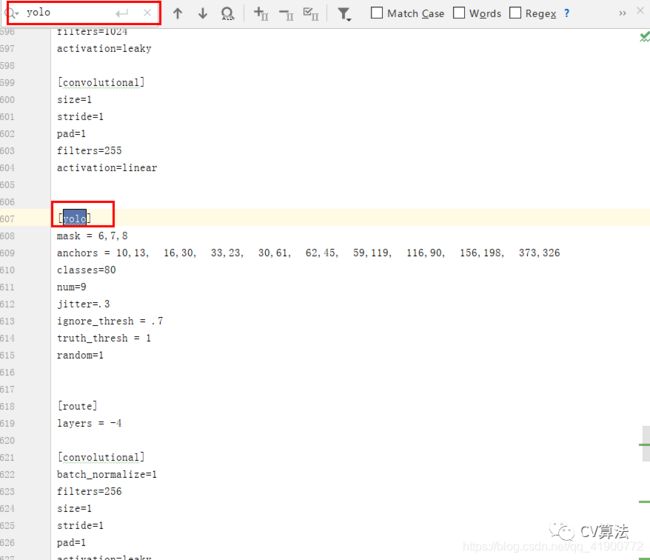
该文件中主要包括了三部分:网络(net)层、convolutional(卷积)层、yolo层。在文件配置时需要配置net和yolo层的信息,
1)net配置: 训练过程中将testing下两行注释掉(如果测试时将training下两行注释掉)batch、subdivisions的值根据自己的需要进行修改 (注意:当GPU显存比较小时将subdivisions调大batch/subdivisions的值为训练时一次传入训练的图片) 其他的之不需要配置2)yolo配置 打开文件后按Ctrl+F键进行搜索yolo,会搜出3个yolo,所以yolo部分需要修改3次(每次修改都有相同)yolo上边的filter改为“3*(5+类别数)”yolo下边classes改为自己的类别数,random为多尺度训练,如果GPU显存很小将其置为0。3个yolo出均需修改。3)使用k-means可以适当修改anchors值以满足自己训练的需要至此,文件配置完成。接下来开始训练。5. 训练
5.1模型的保存
训练时默认:迭代次数小于1000时毎迭代100次保存一次模型,迭代次数大于等于1000时毎一万次保存一次模型,保存的模型结果保存在主目录下的backup文件夹下,同时,会保存.backup模型(该模型为:当训练中断时,若想要继续接着上次训练可以使用这个模型),若想修改毎多少次保存一次模型的次数,可以在DarkNet主目录下examples/detector.c文件中进行修改
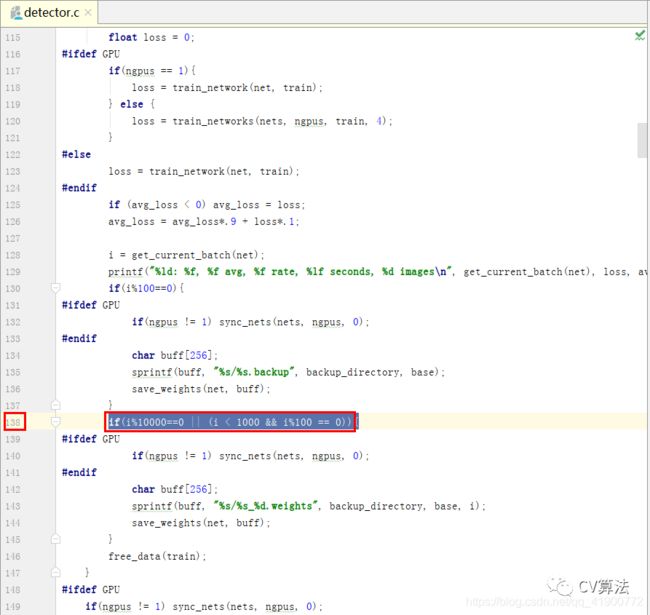
修改完成后,在DarkNet主目录下鼠标右键打开终端输入命令:make,回车进行重新编译
5.2训练
5.2.1.使用预训练模型训练数据(效果较不使用预训练模型要好)
预训练是在ImageNet上按分类的方式进行预训练160轮,使用SGD优化方法,初始学习率0.1,每次下降4倍,到0.0005时终止。除了训练224x224尺寸的图像外,还是用448x448尺寸的图片。
初次训练模型需要使用darknet53.conv.74作为预训练模型,之后在次训练新数据可以使用已经训练完的模型作为预训练模型
在DarkNet主目录下打开终端输入训练命令进行训练。
1. 不保存训练日志的训练命令: ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74解析: 1)在DarkNet主目录下编译完成,则DarkNet框架训练环境搭建完成。可以使用命令:“./darknet” 2)detector为训练文件(底层c程序) 3)train表示该命令为训练命令(当测试时输入测试命令将train改为test) 4)cfg/voc.data:表示配置的数据集的参数文件(注意路径) 5)cfgyolov3-voc.cfg:表示配置的网络参数文件(注意路径) 6)scripts/darknet53.conv.74:表示训练所需要的预训练模型(注意路径)2. 保存训练日志的训练命令: ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74 | tee train_yolov3-voc.log解析: 1)在DarkNet主目录下编译完成,则DarkNet框架训练环境搭建完成。可以使用命令:“./darknet” 2)detector为训练文件(底层c程序) 3)train表示该命令为训练命令(当测试时输入测试命令将train改为test) 4)cfg/voc.data:表示配置的数据集的参数文件(注意路径) 5)cfgyolov3-voc.cfg:表示配置的网络参数文件(注意路径) 6)scripts/darknet53.conv.74:表示训练所需要的预训练模型(注意路径) 7)| tee train_yolov3-voc.log:表示训练时保存日志文件(保存在DarkNet主目录下)3. 使用GPU、不保存训练日志的训练命令: ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74 -gpus 0,1,... | tee train_yolov3-voc.log解析: 1)在DarkNet主目录下编译完成,则DarkNet框架训练环境搭建完成。可以使用命令:“./darknet” 2)detector为训练文件(底层c程序) 3)train表示该命令为训练命令(当测试时输入测试命令将train改为test) 4)cfg/voc.data:表示配置的数据集的参数文件(注意路径) 5)cfgyolov3-voc.cfg:表示配置的网络参数文件(注意路径) 6)scripts/darknet53.conv.74:表示训练所需要的预训练模型(注意路径) 7)-gpus 0,1:使用多GPU进行训练模型时添加改程序,可指定特定GPU进行训练网络,即:当设备拥有n个GPU时,可以同时使用GPU进行加速训练n个网络。4. 使用GPU、保存训练日志的训练命令: ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74 -gpus 0,1.....解析: 1)在DarkNet主目录下编译完成,则DarkNet框架训练环境搭建完成。可以使用命令:“./darknet” 2)detector为训练文件(底层c程序) 3)train表示该命令为训练命令(当测试时输入测试命令将train改为test) 4)cfg/voc.data:表示配置的数据集的参数文件(注意路径) 5)cfgyolov3-voc.cfg:表示配置的网络参数文件(注意路径) 6)scripts/darknet53.conv.74:表示训练所需要的预训练模型(注意路径) 7)-gpus 0,1:使用多GPU进行训练模型时添加改程序,,可指定特定GPU进行训练网络,即:当设备拥有n个GPU时,可以同时使用GPU进行加速训练n个网络。
5.2.2 训练日志参数的介绍

1)Region 82(94/106):表示cfg文件中yolo-layer的索引值,三个值,82/94/106 2)Avg IOU:表示在训练过程中预测的bounding box与标注的bounding box的交并比(两个框的相交/两个框的并),该值期望越大越好,目标值为1 3)Class:表示标注物体的分类准确率,该值期望越大越好,目标期望值为1 4)obj:表示预测有目标的概率,该值期望越大越好,目标值为1 5)No obj:表示预测没有目标的概率,该值期望越小越好,目标期望值为0 6).5R:表示以IOU=0.5为阈值时被召回(recall)。recall=检出的正样本/实际的正样本 7).75R:表示以IOU=0.75为阈值时被召回(recall) 8)count:表示正样本的数量![]()
1)20277:表示当前训练的迭代次数 2)0.038915:表示训练总的Loss损失 3)0.42692 avg:表示平均Loss,该值期望越低越好,一般该值低于0.060730 avg就可以终止训练了。 4)0.000100 rate:代表当前的学习率,是在.cfg文件中定义的。(因为本人已经训练,训练过程中未截图,所以该图借鉴了他人的图,本人训练时学习率为0.001) 5)0.302128 seconds:表示当前批次训练花费的总时间(batch/subdivisions) 6)162216 images:表示到目前所参与训练的总的图片数量5.2.3 当avg低于0.06时即可停止训练了
Linux系统下在训练时的当前终端按下Ctrl+c进行停止训练
5.2.3训练停止后想接着上次训练接着训练
接着上次训练接着训练,在DarkNet主目录下鼠标右键打开终端,输入以下命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup回车,即可接着上次的训练继续训练。解释:
该条命令同前边介绍的训练命令只是将预训练权重改为上次训练时保存在DarkNet主目录下的backup文件夹下的yolov3-voc.backup文件
5.3 训练日志可视化
输入保存训练日志训练命令训练后,在DarkNet主目录下会生成train_yolov3-voc.log(.log)的训练日志文件。使用visualization_train_yolov3-voc_log.py(存放在与训练日志文件同级目录下) Python脚本程序度训练日志文件进行可视化,运行程序后会得到loss变化曲线和Avg IOU曲线
1)visualization_train_yolov3-voc_log.py程序如下所示:
import pandas as pd import matplotlib.pyplot as plt import os # ==================可能需要修改的地方=====================================# g_log_path = "train_yolov3-voc.log" # 此处修改为你的训练日志文件名 # ==========================================================================# def extract_log(log_file, new_log_file, key_word): ''' :param log_file:日志文件 :param new_log_file:挑选出可用信息的日志文件 :param key_word:根据关键词提取日志信息 :return: ''' with open(log_file, "r") as f: with open(new_log_file, "w") as train_log: for line in f: # 去除多gpu的同步log if "Syncing" in line: continue # 去除nan log if "nan" in line: continue if key_word in line: train_log.write(line) f.close() train_log.close() def drawAvgLoss(loss_log_path): ''' :param loss_log_path: 提取到的loss日志信息文件 :return: 画loss曲线图 ''' line_cnt = 0 for count, line in enumerate(open(loss_log_path, "rU")): line_cnt += 1 result = pd.read_csv(loss_log_path, skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))], error_bad_lines=False, names=["loss", "avg", "rate", "seconds", "images"]) result["avg"] = result["avg"].str.split(" ").str.get(1) result["avg"] = pd.to_numeric(result["avg"]) fig = plt.figure(1, figsize=(6, 4)) ax = fig.add_subplot(1, 1, 1) ax.plot(result["avg"].values, label="Avg Loss", color="#ff7043") ax.legend(loc="best") ax.set_title("Avg Loss Curve") ax.set_xlabel("Batches") ax.set_ylabel("Avg Loss") def drawIOU(iou_log_path): ''' :param iou_log_path: 提取到的iou日志信息文件 :return: 画iou曲线图 ''' line_cnt = 0 for count, line in enumerate(open(iou_log_path, "rU")): line_cnt += 1 result = pd.read_csv(iou_log_path, skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))], error_bad_lines=False, names=["Region Avg IOU", "Class", "Obj", "No Obj", "Avg Recall", "count"]) result["Region Avg IOU"] = result["Region Avg IOU"].str.split(": ").str.get(1) result["Region Avg IOU"] = pd.to_numeric(result["Region Avg IOU"]) result_iou = result["Region Avg IOU"].values # 平滑iou曲线 for i in range(len(result_iou) - 1): iou = result_iou[i] iou_next = result_iou[i + 1] if abs(iou - iou_next) > 0.2: result_iou[i] = (iou + iou_next) / 2 fig = plt.figure(2, figsize=(6, 4)) ax = fig.add_subplot(1, 1, 1) ax.plot(result_iou, label="Region Avg IOU", color="#ff7043") ax.legend(loc="best") ax.set_title("Avg IOU Curve") ax.set_xlabel("Batches") ax.set_ylabel("Avg IOU") if __name__ == "__main__": loss_log_path = "train_log_loss.txt" iou_log_path = "train_log_iou.txt" if os.path.exists(g_log_path) is False: exit(-1) if os.path.exists(loss_log_path) is False: extract_log(g_log_path, loss_log_path, "images") if os.path.exists(iou_log_path) is False: extract_log(g_log_path, iou_log_path, "IOU") drawAvgLoss(loss_log_path) drawIOU(iou_log_path) plt.show()2)运行程序后得到loss变化曲线和Avg IOU曲线图
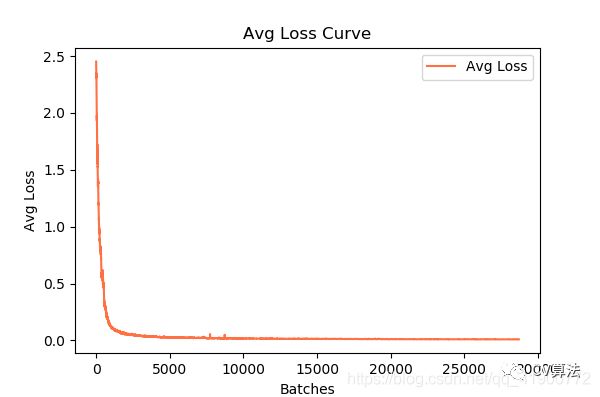
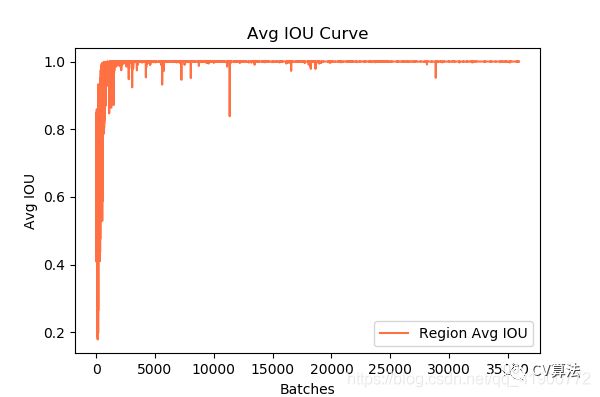
5.4 训练完后,对模型进行微调微调继续训练新数据样本
初次训练模型时需要下载预训练模型:darknet53.conv.74训练完后,在DarkNet主目录下的backup文件夹下会生成训练模型,当下次训练新数据时,使用上次已经训练过的模型作为预训练模型继续训练,需要对训练的模型进行微调。
1)使用-clear对模型进行微调
通过模型训练出的backup或者final.weights文件代替预训练模型darknet53.conv.74,并在训练命令的末尾加上-clear命令,这样模型的训练会从初始状态开始,
./darknet cfg/yolo.data cfg/yolo.cfg backup/model_pre.backup -clear这样重新训练的模型就是在原模型微调的基础上训练的结果,这样模型的收敛速度较快,迭代次数将从0开始计算.
2)不使用-clear对模型进行微调
不用-clear命令,训练则不会从初始状态开始,读取原模型的backup或者weights的时候也会读取其中的迭代次数及learning rage.比如原模型的迭代次数微40000次,最终的学习率为0.00001,那么新模型训练的时候也会从40000次开始迭代,并从0.00001的学习率开始,那么此时就需要修改cfg文件的max_batches以及learning rate .
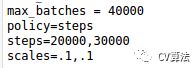
那么新模型如果想迭代30000次,并有初始0.001的学习率你需要修改max_batches和steps:

本文训练过程借鉴了:
https://blog.csdn.net/qq_34806812/article/details/81459982
https://blog.csdn.net/hunterhe/article/details/89923092