大数据分块_硬核干货丨游戏大世界的超远视距处理手法,建议收藏!
| 导语 本文从浮点数精度、实时阴影、合批策略和剔除算法四方面阐述游戏大世界的超远视距处理的常用手法。

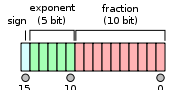
 16位半精度浮点数的有效位只有10位
16位半精度浮点数的有效位只有10位
 浮点数精度的偏差从数学上来看,在于使用有限的位来表达无穷多的数。从浮点数的设计和使用情形来看,浮点数的精度在实际使用情形中误差分布是不均匀的,
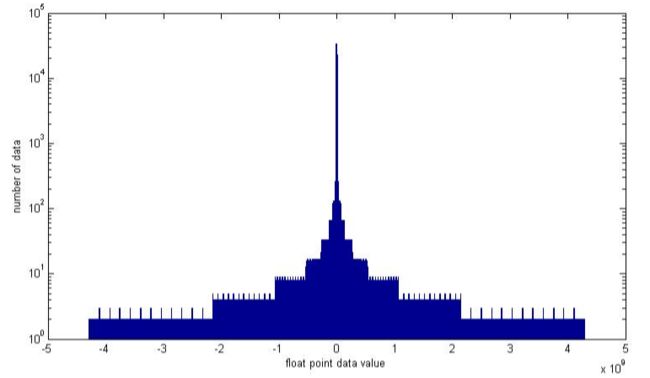
浮点数越大,它离0点越远,那么它在运算中所能保留的小数位就越少。 下图来源于知乎Jack Sun关于"计算机中的浮点数在数轴上分布均匀吗?"的回答,可以看到浮点数精度在0点周围集中的情况。
浮点数精度的偏差从数学上来看,在于使用有限的位来表达无穷多的数。从浮点数的设计和使用情形来看,浮点数的精度在实际使用情形中误差分布是不均匀的,
浮点数越大,它离0点越远,那么它在运算中所能保留的小数位就越少。 下图来源于知乎Jack Sun关于"计算机中的浮点数在数轴上分布均匀吗?"的回答,可以看到浮点数精度在0点周围集中的情况。
 所以浮点数精度解决方案总是和如何压缩它的所表达数域/向量域,一个很自然的处理方式就是使用局部坐标系。我们可以把世界划分成许多子Level或地图分块,每一个地图分块给定一个偏移基址,分块内部的位置信息使用的是该位置的
世界位置 - 基址位置 所表示,即为每个分块构建一个了一个和世界原点有基址偏移的局部坐标系,块内部的所有物体使用该局部坐标系表示和运算。当需要跨分块进行计算的时候,需要先做一步变换到世界空间,再进行余下的操作。 世界坐标系和分块的局部坐标系如下图所示:
所以浮点数精度解决方案总是和如何压缩它的所表达数域/向量域,一个很自然的处理方式就是使用局部坐标系。我们可以把世界划分成许多子Level或地图分块,每一个地图分块给定一个偏移基址,分块内部的位置信息使用的是该位置的
世界位置 - 基址位置 所表示,即为每个分块构建一个了一个和世界原点有基址偏移的局部坐标系,块内部的所有物体使用该局部坐标系表示和运算。当需要跨分块进行计算的时候,需要先做一步变换到世界空间,再进行余下的操作。 世界坐标系和分块的局部坐标系如下图所示:
 *关于位置精度问题的更详细的讨论,可以参考《游戏编程精粹4》,实现可以参考UE4。
Z Buffer精度问题 在绝大多数3D图形学和游戏数学开发的书本和文章里,我们看到的相机设置都会有一个近裁剪面,一个远裁剪面,只有位于这两者之间的物体才能会被渲染到屏幕上。对于一般游戏来说,我们的裁剪距离可能只有几十到上百米,但对于大世界来说,可视距离可能长大几公里。 对于以公里计的可视距离,渲染所用的Z Buffer精度同样深受浮点数的精度问题困扰。它的精度集中的分布在0点附近。先看看距离在0到1之间的时候1/z的精度分布:
*关于位置精度问题的更详细的讨论,可以参考《游戏编程精粹4》,实现可以参考UE4。
Z Buffer精度问题 在绝大多数3D图形学和游戏数学开发的书本和文章里,我们看到的相机设置都会有一个近裁剪面,一个远裁剪面,只有位于这两者之间的物体才能会被渲染到屏幕上。对于一般游戏来说,我们的裁剪距离可能只有几十到上百米,但对于大世界来说,可视距离可能长大几公里。 对于以公里计的可视距离,渲染所用的Z Buffer精度同样深受浮点数的精度问题困扰。它的精度集中的分布在0点附近。先看看距离在0到1之间的时候1/z的精度分布:
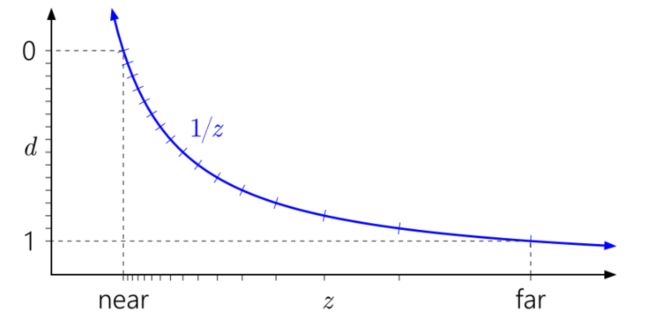 在此情形下远处的物体渲染容易出现Z Fight,会因渲染顺序而可能产生可视性的错误。对于Z Buffer的精度问题,常用的解决方是为z构造一个单调变换函数,使z的浮点数精度区间分布尽可能均匀。为此,Eugene Lapidous构造出了
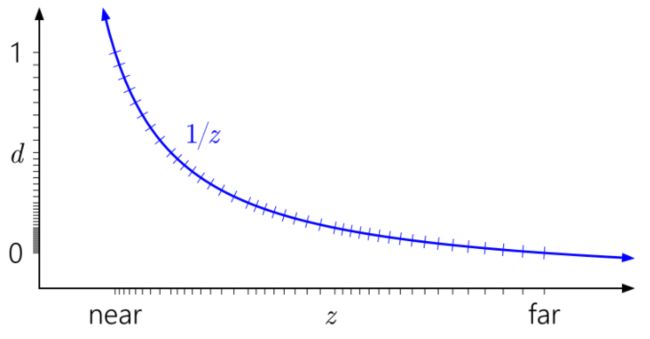
Reversed Z = 1-Z,这一算法只需一条指令,且对渲染来说也不过是把原来的LessEqual改为GreatEqual,精巧简洁。一个复杂的问题的解决,并不一定需要复杂的方案。 做为对比,使用Reversed Z之后的精度分布如下图所示:
在此情形下远处的物体渲染容易出现Z Fight,会因渲染顺序而可能产生可视性的错误。对于Z Buffer的精度问题,常用的解决方是为z构造一个单调变换函数,使z的浮点数精度区间分布尽可能均匀。为此,Eugene Lapidous构造出了
Reversed Z = 1-Z,这一算法只需一条指令,且对渲染来说也不过是把原来的LessEqual改为GreatEqual,精巧简洁。一个复杂的问题的解决,并不一定需要复杂的方案。 做为对比,使用Reversed Z之后的精度分布如下图所示:
 *Reversed z的原始论文,可以参考Eugene Lapidous的《Optimal Depth Buffer for Low-Cost Graphics Hardware》、Nvidia的Depth Precision Visualized。
*Reversed z的原始论文,可以参考Eugene Lapidous的《Optimal Depth Buffer for Low-Cost Graphics Hardware》、Nvidia的Depth Precision Visualized。
 CSM 大世界的第三个问题是关于实时阴影渲染,很容易出现锯齿、条纹和漏光问题。这一问题常见的解决方案是使用CSM。CSM的基本思想很简单,它不是使用一张Shadowmap来渲染整个场景,而是使用N张相同大小的Shadowmap来分别渲染视锥不同部分的阴影。其详细步骤如下:
CSM 大世界的第三个问题是关于实时阴影渲染,很容易出现锯齿、条纹和漏光问题。这一问题常见的解决方案是使用CSM。CSM的基本思想很简单,它不是使用一张Shadowmap来渲染整个场景,而是使用N张相同大小的Shadowmap来分别渲染视锥不同部分的阴影。其详细步骤如下:
1.把视锥在z方向上按Log距离分成几个个水平的区域。
2.按新的视锥分别计算每个区域的区域裁剪矩阵和阴影投影矩阵。
3.使用相同分辨率分别渲染这些区域的Shadowmap。
4.在物体渲染的时候根据当前像素所在区域选择对应的那张Shadowmap进行采样和过滤。
下面是CSM区域划分的图示: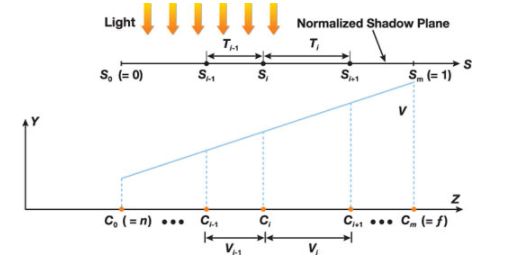 下面是渲染物体时的shadow depth buffer和最终结果的图示:
下面是渲染物体时的shadow depth buffer和最终结果的图示:
 注意到CSM对Shadowmap的算法和采样滤波器是无关的,所以它并不关心使用的是标准Shadowmap还是使用ESM,VSM,也不关心是否使用Filter来生成软阴影。 常用的CSM使用的是标准的Shadowmap和PCF滤波。
SDSM SDSM是原始CSM的改进版本,它在计算光锥区域的时候使用是可见的像素进行计算而不是视锥,这一方面可以使每级shadowmap的bias和scale更为恰当,从而使每一级shadowmap的z取值范围更小,也就自然保证了更高的精度;另一方面也可以使计算出来的[min,max] 用于Log划分的depth域值更准确。 SDSM和原始CSM相比,在最前面插入了两步:
注意到CSM对Shadowmap的算法和采样滤波器是无关的,所以它并不关心使用的是标准Shadowmap还是使用ESM,VSM,也不关心是否使用Filter来生成软阴影。 常用的CSM使用的是标准的Shadowmap和PCF滤波。
SDSM SDSM是原始CSM的改进版本,它在计算光锥区域的时候使用是可见的像素进行计算而不是视锥,这一方面可以使每级shadowmap的bias和scale更为恰当,从而使每一级shadowmap的z取值范围更小,也就自然保证了更高的精度;另一方面也可以使计算出来的[min,max] 用于Log划分的depth域值更准确。 SDSM和原始CSM相比,在最前面插入了两步:
1.渲染需要投影的所有物体,进到DepthTexture。
2.统计DepthTexture,得到Min,Max Depth或Depth分布直方图。
3.按Depth的分布直方图或Min ,Max Depth做为视锥的最范围,按Log或K-Mean Cluster分成几个个水平的区域。
4.按像素的Depth在相机空间的投影计算每个区域的区域裁剪矩阵,阴影投影矩阵。
余下两步的渲染和应用SM完全和标准CSM相同。 下图示意的是标准CSM和按Depth直方图划分层级的SDSM的区别: CSM--可见锯齿
CSM--可见锯齿
 CSM的各级分层结构
CSM的各级分层结构
 SDSM--走样改善
SDSM--走样改善
 SDSM的分层结构 *SDSM详细算法参考《Sample Distribution Shadow Maps》
CSM Scrolling 全场景的实时阴影渲染会增加许多的Drawcall,这对Drawcall敏感的游戏来说带来了巨大的CPU负担,CSM Scrolling是 Mike Acton在2012年Siggraph提出的一种有效的减少CSM Drawcall的技术。 其基本假设如下:
SDSM的分层结构 *SDSM详细算法参考《Sample Distribution Shadow Maps》
CSM Scrolling 全场景的实时阴影渲染会增加许多的Drawcall,这对Drawcall敏感的游戏来说带来了巨大的CPU负担,CSM Scrolling是 Mike Acton在2012年Siggraph提出的一种有效的减少CSM Drawcall的技术。 其基本假设如下:
1.世界上绝大部分投体物体都是静态不动的或发生移动的频率是非常低的。
2.相机运动缓慢且在帧间连续。
3.灯光和物体一样,其位置、方向基本不变或变化频率非常低。
在这样的条件下,可以把场景物体分为动态和静态两部分。算法步骤如下: 1.把静态物体渲染出来的Shadow Depth缓存起来。 2.通过相机位移和旋转值计算出当前帧这些静态物体在Shadowmap中所应该的位置,卷动他们到到正确的位置。 3.计算出当前相机新出现的静态物体并渲染其depth到缓存中。 4.把缓存的Shadow Depth复制给当前的Shadow Depth,并在其上绘制动态物体的Shadow Depth。 上述流程图示如下: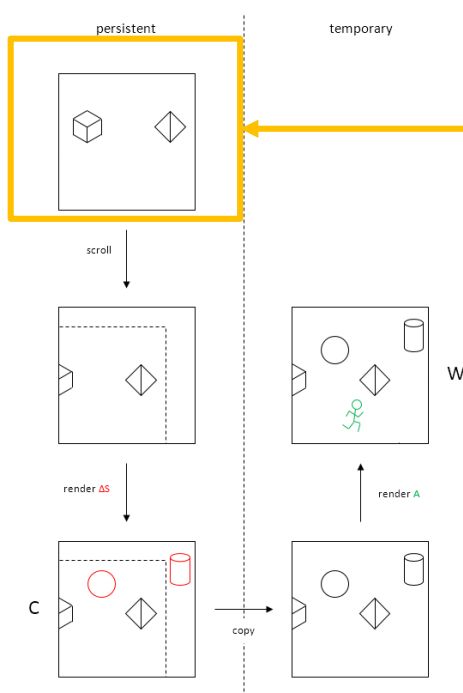 *CSM详细算法可以参考《Gpu Gems3》,csm Scrolling则可以参考Mike Acton的《CSM Scrolling An acceleration technique for the rendering of cascaded shadow maps》
*CSM详细算法可以参考《Gpu Gems3》,csm Scrolling则可以参考Mike Acton的《CSM Scrolling An acceleration technique for the rendering of cascaded shadow maps》
 渲染的本质是求解每个像素上的颜色和亮度,优化方面算上其依附的硬件工作机制,等于加上Cache命中和并行。其大概等同于:
渲染所有像素所需的总资源 + 资源组织和管理策略 + 算法及其派发策略 GPU一方面对渲染进行了封装,另一方面也使问题在某些程度上变成黑盒,从而更复杂化。GPU上的渲染管线被抽象为光栅化和着色两大部分,其中光栅化阶段使用三角形为基本单位,而着色阶段以像素为基本单位。如果算GPU,那么上述的Cache命中还可以再泛化一下:减少CPU和GPU之间的数据传输量和利用好移动GPU上的On Chips Memory。 在硬件资源确定的情况下,可用的计算量上限恒定,部分资源组织方式固定不可定制,部分算法及派发策略是选择题而不是填空题。搭配上固定的引擎和既定的光照着色模型,则资源组织和算法派发也基本上固定不变。前者决定算力上限,后者则确定引擎下限,两者配合可以通过测试,得到可以容纳的渲染资源总量的性能数据:
单帧可渲染的数据量。 文章余下来的两个部分探讨的是减少派发渲染的CPU消耗和如何减少单帧需要渲染的数据量的两个常用技术集:
渲染的本质是求解每个像素上的颜色和亮度,优化方面算上其依附的硬件工作机制,等于加上Cache命中和并行。其大概等同于:
渲染所有像素所需的总资源 + 资源组织和管理策略 + 算法及其派发策略 GPU一方面对渲染进行了封装,另一方面也使问题在某些程度上变成黑盒,从而更复杂化。GPU上的渲染管线被抽象为光栅化和着色两大部分,其中光栅化阶段使用三角形为基本单位,而着色阶段以像素为基本单位。如果算GPU,那么上述的Cache命中还可以再泛化一下:减少CPU和GPU之间的数据传输量和利用好移动GPU上的On Chips Memory。 在硬件资源确定的情况下,可用的计算量上限恒定,部分资源组织方式固定不可定制,部分算法及派发策略是选择题而不是填空题。搭配上固定的引擎和既定的光照着色模型,则资源组织和算法派发也基本上固定不变。前者决定算力上限,后者则确定引擎下限,两者配合可以通过测试,得到可以容纳的渲染资源总量的性能数据:
单帧可渲染的数据量。 文章余下来的两个部分探讨的是减少派发渲染的CPU消耗和如何减少单帧需要渲染的数据量的两个常用技术集:
- 合批(Batching)
- 剔除(Culling)
 Drawcall又被称为Batch,等价于一次D3D的DrawPrimitive*和Opengl的glDraw*的调用。Batch的消耗即派发渲染数据的开销,它来源于两个部分:渲染数据的切换成本和Draw*函数的调用成本。渲染数据的切换包括VertexBuffer、IndexBuffer、UniformBuffer(ConstBuffer)、Shader、Texture及各种API所定义的渲染状态。 关于Batch的消耗,早在10多年前,Nvidia就在GDC上曝过一组数据:
Drawcall又被称为Batch,等价于一次D3D的DrawPrimitive*和Opengl的glDraw*的调用。Batch的消耗即派发渲染数据的开销,它来源于两个部分:渲染数据的切换成本和Draw*函数的调用成本。渲染数据的切换包括VertexBuffer、IndexBuffer、UniformBuffer(ConstBuffer)、Shader、Texture及各种API所定义的渲染状态。 关于Batch的消耗,早在10多年前,Nvidia就在GDC上曝过一组数据:
 按30FPS算,1个1GHZ的CPU只用来提交Batch而不做任何其它事,大概每帧可提交830个。 渲染数据在一般游戏引擎中被抽象为两部分:几何拓扑数据(Geometry,Mesh/Skin)和材质数据(Material/MaterialInstance)。这样每一个Batch对应的是一个对,减少Batch即为如何减少这样的配对数量。 现在渲染API(D3D12/Vulkan/Opengl4.3/Metal2及之后)针对Batch的Draw*函数调用成本的优化在驱动层有了质的飞跃——MultiIndirectDraw出现后,配合GPU Driven RenderingPipeline使得游戏引擎的MainPass在个位数的Draw*调用成为可能。 另一方面,这些现代API的标准制订者同样注意到Batch数量做为渲染驱动的主要开销是不合常理的,所以它们也致力于减少了Draw*调用所带来的CPU开销。我们在Iphone11 Pro上使用UE4粗略的测过Batch性能,当Batch数量介于1800~2000之后,其带来的消耗增长是非线性的。 为什么在3D API诞生的前30年里,这一不合理却能被业界逆来顺受的容忍以致于一代又一代开发人员在做渲染优化的时候的第一件大事不是减少计算量而是舍本逐末绞尽脑汁地去降低Batch数量呢? * 关于每Batch消耗的具体数据,仅有Nvidia当年的《Batch Batch Batch》可参考,手机上纯净的Batch性能测试需要更多的数据支撑。 GPU Driven Renering Pipeline已经有过许多好的文章介绍,有兴趣的同学可以找找Siggraph 2015寒霜引擎在Real-Time Rendering Course上分享的《GPU-Driven Rendering Pipelines》来看详细的实现思想和具体数据。
渐进细节(Progress Mesh ,Lod) Lod是项古老的优化技术,它的基本思想是物体距离相机越远,则它所需渲染的面数就越少,材质越简单。如一座大房子在Lod0时地板、墙壁、灯具、门、窗户、吧台可能都由不同的材质组成,但它在Lod4的时候变成了只有一个墙砖材质。 LOD示例如下图:
按30FPS算,1个1GHZ的CPU只用来提交Batch而不做任何其它事,大概每帧可提交830个。 渲染数据在一般游戏引擎中被抽象为两部分:几何拓扑数据(Geometry,Mesh/Skin)和材质数据(Material/MaterialInstance)。这样每一个Batch对应的是一个对,减少Batch即为如何减少这样的配对数量。 现在渲染API(D3D12/Vulkan/Opengl4.3/Metal2及之后)针对Batch的Draw*函数调用成本的优化在驱动层有了质的飞跃——MultiIndirectDraw出现后,配合GPU Driven RenderingPipeline使得游戏引擎的MainPass在个位数的Draw*调用成为可能。 另一方面,这些现代API的标准制订者同样注意到Batch数量做为渲染驱动的主要开销是不合常理的,所以它们也致力于减少了Draw*调用所带来的CPU开销。我们在Iphone11 Pro上使用UE4粗略的测过Batch性能,当Batch数量介于1800~2000之后,其带来的消耗增长是非线性的。 为什么在3D API诞生的前30年里,这一不合理却能被业界逆来顺受的容忍以致于一代又一代开发人员在做渲染优化的时候的第一件大事不是减少计算量而是舍本逐末绞尽脑汁地去降低Batch数量呢? * 关于每Batch消耗的具体数据,仅有Nvidia当年的《Batch Batch Batch》可参考,手机上纯净的Batch性能测试需要更多的数据支撑。 GPU Driven Renering Pipeline已经有过许多好的文章介绍,有兴趣的同学可以找找Siggraph 2015寒霜引擎在Real-Time Rendering Course上分享的《GPU-Driven Rendering Pipelines》来看详细的实现思想和具体数据。
渐进细节(Progress Mesh ,Lod) Lod是项古老的优化技术,它的基本思想是物体距离相机越远,则它所需渲染的面数就越少,材质越简单。如一座大房子在Lod0时地板、墙壁、灯具、门、窗户、吧台可能都由不同的材质组成,但它在Lod4的时候变成了只有一个墙砖材质。 LOD示例如下图:
 对于一般的场景或角色模型来说,其Lod的可以是手工制作的,也可以是自动生成的。完全手工制作Lod对于大世界来说有巨大的美术工作量。事实上大世界关卡设计、玩法内容充填、美术资源制作和地编成本和其尺寸的平方成正比,所以Houdini + SD/SP的过程化或部分过程化生成是现在的热门课题。 物体Lod切换算法非常简单,一开始都是按距离来切换:
对于一般的场景或角色模型来说,其Lod的可以是手工制作的,也可以是自动生成的。完全手工制作Lod对于大世界来说有巨大的美术工作量。事实上大世界关卡设计、玩法内容充填、美术资源制作和地编成本和其尺寸的平方成正比,所以Houdini + SD/SP的过程化或部分过程化生成是现在的热门课题。 物体Lod切换算法非常简单,一开始都是按距离来切换:
1.计算物体包围盒到相机视点的距离D。
2.比较D和Lod所设置的显示距离L,从最高一级Lod往下查找,选择D>L的最高一级Lod。
包围盒一般使用的是球体,但在更精确的场合,也有使用OBB的。 使用距离进行切换对于多分辨率的游戏来说往往有可见的跳变。所以现在更多的是把距离改为“包围盒投影在屏幕中的大小(屏占比)"来进行切换。 但Lod对于大世界来说还远远不够,试想当前视距内存在1万颗石头,则不管如何取它的Lod,它的Batch数量都不会低于1万。 *Progress Mesh生成的经典算法可参考hugues hoppe的《Progressive meshes》系列所提出的Quadric算法,其基本原理是通过计算和排序几何拓扑数据的突变代价,优先塌陷代价小的顶点,从而降低视觉突变的可能性。业界常用的Lod生成中间件为Simpolygon和Instalod。 静态合批(StaticBatching) 游戏场景中因许多物体使用相同的母材质、渲染状态相同、只是纹理不同。StaticBatch的基本想法是合并一些小纹理成为一张大纹理(AtlasTexture),然后合并引用这些小纹理的Mesh成为一个大的Mesh,利用合并后的纹理和Mesh来替代原来的这些小纹理和小Mesh进行渲染。 静态合批详细步骤如下:1.在编辑态或游戏打包时选取一组空间邻近的场景物体。
2.合并他们纹理为AtlasTexture,记录纹理在AtlasTexture中的Offset和Scale。
 3. 合并他们的为一个大的Mesh,根据它们所引用纹理在AtlasTexture中的Offset和Scale重新计算UV坐标。
3. 合并他们的为一个大的Mesh,根据它们所引用纹理在AtlasTexture中的Offset和Scale重新计算UV坐标。
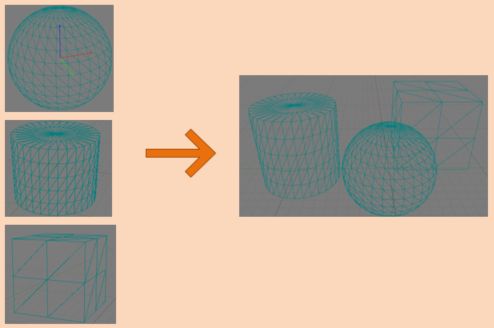 4. 创建一个新的物体引用2,3生成的Texture和Mesh替代步骤1中选中的这组物体。 静态合批可以解决Lod不能解决的跨物体合批的问题,但它也会带来一些额外的代价:
4. 创建一个新的物体引用2,3生成的Texture和Mesh替代步骤1中选中的这组物体。 静态合批可以解决Lod不能解决的跨物体合批的问题,但它也会带来一些额外的代价:
1.游戏安装包体的变大:按空间区域进行合并,不可避免的带来Texture和Mesh数据的冗余。
2.游戏运行时内存使用更高:基于和1同样的理由,Mesh和Texture的流式加载所需Lod和Mip等级的计算也会更无效率。
3.增加GPU消耗:合并之后的Mesh变大,会使Lod的切换更缓慢,剔除算法失效,从而使一帧内需要渲染的三角形数量增多,潜在的也带来额外的Overdraw。
动态合批(DynamicBatching) 动态合批和静态合批唯一的区别是它的执行的时机:静态合批执行的时机是在编辑器或游戏打包的时候;动态合批则是在游戏启动时或游戏运行时。 动态合批解决了静态合批游戏包体变大的问题,在一定程度上也缓解了内存浪费的问题。但它也带来了新的问题:加载时间变长:AtlasTexture Pack和Mesh Merge有额外的计算量。
静态实例化(Static Instance) 对于像石头、草、树木等大量重用的场景模型,使用静态或动态合批会带来数倍于原始模型的数据量的包体和内存开销。Instance技术专门针对这一应用场景所提出——它能在内存和包体和原始模型接近相等的情形下大大的降低Batch数量。 Static Instance的基本假设为:1.模型会被大量复用。
2.模型在场景中复用时只有少量参数(Instance Data)不一样,如刚体变换信息(位置缩放旋转)、少量的Shader参数。
Instance在现如今的渲染API中均有不同程度的支持。但Static Instance可以在没有API支持的情形下就能工作。 静态实例化常见的做法是把Instance Data放到额外的Vertex Stream中。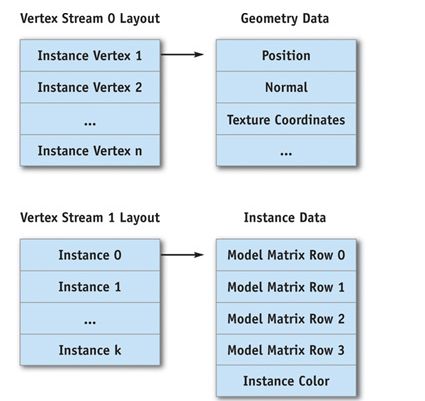 如上图所示,Vertex Stream0保存的是顶点所需的几何数据,Vertex Stream1保存的是Instance Data数据。这样在HLSL中做如下Vertex Input声明,用于访问几何数据和Instance Data。
如上图所示,Vertex Stream0保存的是顶点所需的几何数据,Vertex Stream1保存的是Instance Data数据。这样在HLSL中做如下Vertex Input声明,用于访问几何数据和Instance Data。
float4 position : POSITION; float3 normal : NORMAL; float4 model_matrix0 : TEXCOORD0; float4 model_matrix1 : TEXCOORD1; float4 model_matrix2 : TEXCOORD2; float4 model_matrix3 : TEXCOORD3; float4 instance_color : COLOR0;1.在编辑态或游戏打包时选取一组空间邻近的完全复用的物体。
2.合并它们的刚体变换数据和Shader参数为Instance Data并存盘。
3.创建一个Instance物体索引原始模型的Mesh、Material和刚创建好的InstanceData,使用Instance物体替换选中的这组物体。
4.Instance渲染时使用双VertexStream,VertexStream0为原始几何数据,VertexSteam1为InstanceData,在Shader中通过InstanceData访问每个实例自己的特有数据进行T&L变换及着色。
静态实例化虽然解决了内存和包体和内存问题,但它和静态合批一样增加了GPU的消耗,因为其合并范围内相同的物体而增大了单个模型的包围盒,故影响了Lod切换和不易剔除和静态合批完全一样。 *Static Instance算法分析可以参考Nvidia Gpu Gems 2的《Inside Geometry Instancing》,实现可以参考UE4 ISM的相关实现。 动态实例化(Dynamic Instance) 动态实例化和静态实例化的不同之处在于以下2点:1、运行时机:游戏运行时进行实时合并Instance
2、Instance Data存储方式:动态实例化的Instance Data一般存储在全局的UniformBuffer中或Texture中。
动态实例化的数据结构如下所示: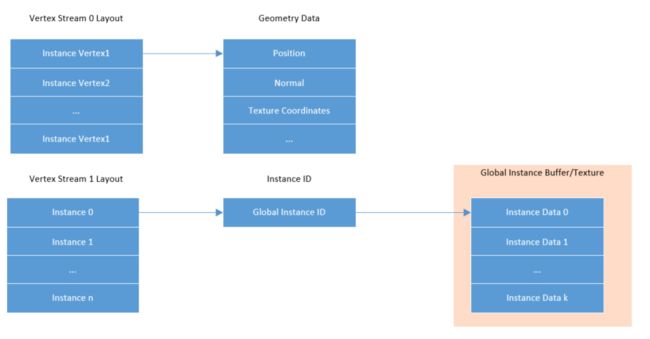 这样在HLSL中做如下Vertex Input声明,用于访问几何数据和Instance ID
这样在HLSL中做如下Vertex Input声明,用于访问几何数据和Instance ID
float4 position : POSITION; float3 normal : NORMAL; float4 instance_id : TEXCOORD0;float4 matrix_row0 = instance_buffer[instance_id * instance_data_size + 0]; float4 matrix_row1 = instance_buffer[instance_id * instance_data_size + 1]; float4 matrix_row2 = instance_buffer[instance_id * instance_data_size + 2]; float4 matrix_row3 = instance_buffer[instance_id * instance_data_size + 3];1.HPR不止可以用于显示,也可以用于加载和剔除优化。
2.HPR可以是真正意义上的多层结构而不是只代表单层,距离相机越远,则加载和显示的资源代理层级越高。
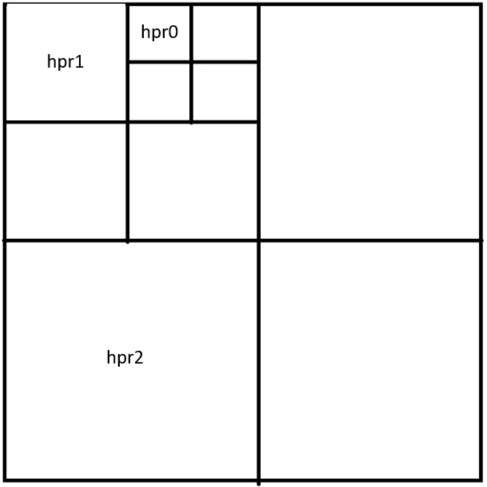 3.HPR的空间分割方式除了可以使用标准的距离划分之外,也可以考虑到遮挡情况和物体本身的聚合情况,使用
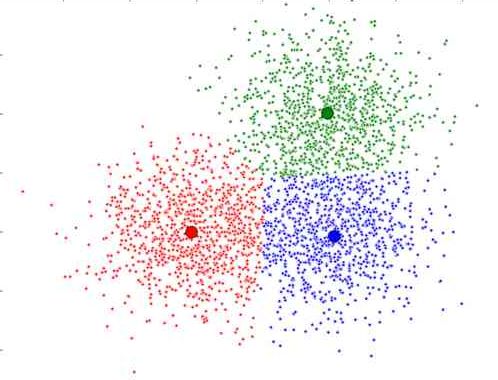
基于数据聚类进行空间分割如KMeans或GMM算法。这对物体的剔除会更为友好。聚类划分算法的运行结果如下图所示。
3.HPR的空间分割方式除了可以使用标准的距离划分之外,也可以考虑到遮挡情况和物体本身的聚合情况,使用
基于数据聚类进行空间分割如KMeans或GMM算法。这对物体的剔除会更为友好。聚类划分算法的运行结果如下图所示。
 4. HPR是用于表现远景的,所以它除了通用的LOD生成算法可用,它还很显然有以下优化可用:
4. HPR是用于表现远景的,所以它除了通用的LOD生成算法可用,它还很显然有以下优化可用:
- 清理掉所有封闭曲面中所包含的内表面和内部模型数据,如果不是FPS类游戏,半封闭曲面也同样可以做同样优化。
- 在已知HPR的切换距离和Fov的前提下,可以在生成HPR的时候离线计算出每个模型的屏占比,使用Screen Size Cull可以剔除掉视觉贡献过小的物体。
- 保留大平面和远处剪影,去掉非边界的小突起。
 Culling指的是在某一个处理步骤中去掉在显示时无贡献或贡献甚微的多边形,其目是减少渲染数据传输成本和渲染管线执行的GPU计算成本。本文内容里不会深入到剔除算法的具体实现方式,但会介绍每个算法的基本思想、算法的适用场合及算法在实际工程应用上的一些主要缺陷和可能的改进方式,以作为技术选型和实现之参考。因个人水平有限,错漏在所难免,望多指正。
Culling指的是在某一个处理步骤中去掉在显示时无贡献或贡献甚微的多边形,其目是减少渲染数据传输成本和渲染管线执行的GPU计算成本。本文内容里不会深入到剔除算法的具体实现方式,但会介绍每个算法的基本思想、算法的适用场合及算法在实际工程应用上的一些主要缺陷和可能的改进方式,以作为技术选型和实现之参考。因个人水平有限,错漏在所难免,望多指正。
Culling时机
通用的质量管理有一项基本的流程优化原则:在流程的越早阶段进行所需的质量保证,其所负担的成本越低,效益越高。这一原则同样适用于剔除优化: 越早阶段进行剔除,剔除的收益越大。 回顾一下简化后的经典的渲染资源处理流程: 上述流程中可用于Culling的时机为:
上述流程中可用于Culling的时机为:
- 更新阶段
- GPU的光栅化阶段之前
- GPU的光栅化阶段之后像素着色阶段之前
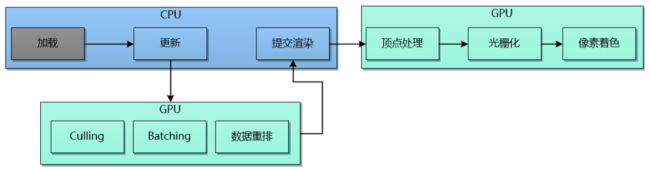 上述流程中把Culling全部移交给了GPU去执行,Culling时机则基本不变。因主机和PC平台支持异步ComputeShader的缘故,GPU Driven Pipeline的执行流程和在更新和提交渲染之间并不一定完全串行。
Culling的粒度 Culling算法作用的粒度包括:
上述流程中把Culling全部移交给了GPU去执行,Culling时机则基本不变。因主机和PC平台支持异步ComputeShader的缘故,GPU Driven Pipeline的执行流程和在更新和提交渲染之间并不一定完全串行。
Culling的粒度 Culling算法作用的粒度包括:
- 一个场景分块或物体分组
- 一个场景物体
- 一些三角形
- 一些像素
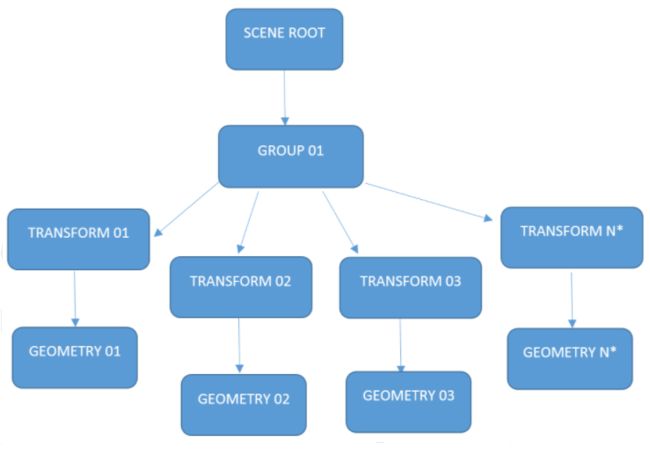 Quadtree按把场景按与地形所平行的平面,四等分场景,如此循环往复直至满足最大的拆分层级深度或是节点中的场景物体数量小于约定的最大叶节点物体数量才停止拆分。Quadtree的示意图如下所示
Quadtree按把场景按与地形所平行的平面,四等分场景,如此循环往复直至满足最大的拆分层级深度或是节点中的场景物体数量小于约定的最大叶节点物体数量才停止拆分。Quadtree的示意图如下所示
 Octree是Quadtree的3D扩展版本——它把场景按包围盒在X,Y,Z三轴上进行等分,这样一个节点就有2^3=8个子节点,如此循环往复直至满足最大的拆分层级深度或是节点中的场景物体数量小于约定的最大叶节点物体数量才停止拆分。Octree的示意图如下所示:
Octree是Quadtree的3D扩展版本——它把场景按包围盒在X,Y,Z三轴上进行等分,这样一个节点就有2^3=8个子节点,如此循环往复直至满足最大的拆分层级深度或是节点中的场景物体数量小于约定的最大叶节点物体数量才停止拆分。Octree的示意图如下所示:
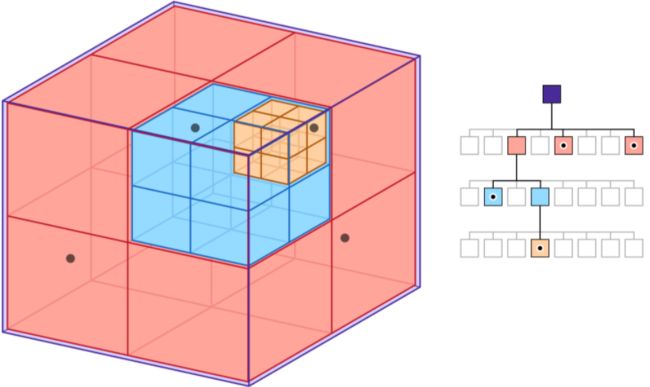 SoA的核心思想是把相同的数据存在一起,因为Culling本质上需要遍历场景,这样在做遍历访问的时候同类数据放在连续的内存中可以保证更高的Cache命中率,下图是SoA的一个示意图:
SoA的核心思想是把相同的数据存在一起,因为Culling本质上需要遍历场景,这样在做遍历访问的时候同类数据放在连续的内存中可以保证更高的Cache命中率,下图是SoA的一个示意图:
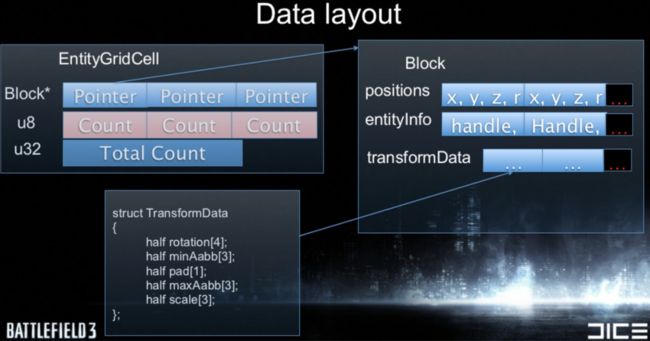 多提一句,ECS在性能上的收益大多也同样源于相同类型数据存储的连续性。。。
Culling算法 Culling算法的核心在于计算一个渲染数据集对最终画面渲染贡献量,当贡献量小于给定阈值时丢弃掉这部分数据,从而节省数据传输带宽和渲染所消耗的计算量。 下面开始介绍常见的Culling算法,为方便阅读,大抵以实用程度前后介绍。
Frustum Culling 视锥体(Frustum)确定了屏幕上的可见区域的范围。在相机的Fov和Aspect、近、远裁剪面共同确定了这一锥棱台的形状。使用这6个面进行物体的可见性Culling即为Frustum Culling。
多提一句,ECS在性能上的收益大多也同样源于相同类型数据存储的连续性。。。
Culling算法 Culling算法的核心在于计算一个渲染数据集对最终画面渲染贡献量,当贡献量小于给定阈值时丢弃掉这部分数据,从而节省数据传输带宽和渲染所消耗的计算量。 下面开始介绍常见的Culling算法,为方便阅读,大抵以实用程度前后介绍。
Frustum Culling 视锥体(Frustum)确定了屏幕上的可见区域的范围。在相机的Fov和Aspect、近、远裁剪面共同确定了这一锥棱台的形状。使用这6个面进行物体的可见性Culling即为Frustum Culling。
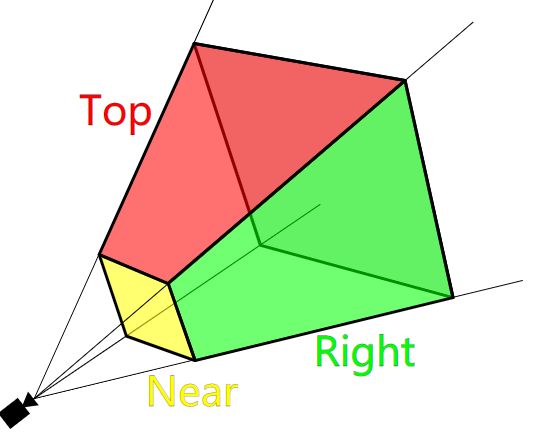 和Lod计算类似,Frustum Culling一般使用的包围盒为Sphere或AABB,但也有使用OBB的,OBB更贴近物体,对剔除掉非轴向的长条形物体尤为有效。以下为Frustum Culling执行的示意图
和Lod计算类似,Frustum Culling一般使用的包围盒为Sphere或AABB,但也有使用OBB的,OBB更贴近物体,对剔除掉非轴向的长条形物体尤为有效。以下为Frustum Culling执行的示意图
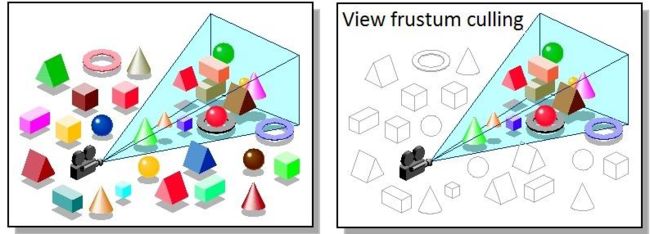 左图为开启Frustum Culling之前,可以看到所有物体都被提交给渲染管线;右图为开启Frustum Culling之后,只有和视锥体相交的这些彩色的物体通过了Culling测试,未通过测试的黑白线框所标示物体就不会被提交给渲染管线,从而节点了传输带宽及后续的渲染计算量。 Frustum Culling计算量和参与Culling的物体数量成正比,算法时间复杂度为O(n)。而对一个正常的FPP/TPP游戏来说,其在Frustum内的可见集大多数时候都会小于全体数据集的50%,所以Frustum Culling带来的收益至少是可以去掉一半以上的不可见物体,其发生时机也在于所有数据开始传输和渲染之前,故适用于所有类型的游戏应用场景。 Frustum Culling对于大世界来说,因为物体数量众多,使用传统分层的场景结构(Graph 或Tree)要比直接使用线性数组要处理的数据总量会小许多,从而更有效率。
Distance Culling Distance Culling的思想非常简单:当物体离相机超过设定的距离阈值,就把物体从可见列表中剔除。 Distance Culling执行时和Frustum Culling不同,Frustum Culling剔除掉的是完全看不到的物体,所以不需要做任何过渡性处理,但Distance Culling一般需要做淡入淡出处理以防止物体消失和出现时的画面跳变。 Distance Culling适合处理半透物体、镂空物体、草丛、贴花等面积大,Overdraw严重的物体,因为这些物体虽然包围盒很大,但是其在稍远一点,对最终画面的贡献微弱却消耗不低,在平衡画面表现和性能开销之后可酌情对上述物体开启。
Screen Size Culling Screen Size Culling和Distance Culling类似,它所用的阈值不是距离而是物体包围盒在屏幕上的投影面积。即它的思想是:当物体最终在屏幕上的投影面积小于事先设定好的阈值,就把物体从可见物体中删除。Screen Size Culling和Distance Culling一样在物体出现和被剔除时会存在画面跳变,所以同样需要做淡入淡出处理。 Screen Size Culling在实际应用过程中的适用于所有物体,它能快速使投影面积小的物体从画面中消失。对于物体密度高、小物体多的场景,它的收益高的往往超乎想象。虽然在复杂时间复杂度方面它和Distance Culling和Frustum Culling一样都是O(n),但在单个物体所需的计算量方面这两者都远小于Frustum Culling。虽然Screen Size Culling从理论上来说可以和Distance Culling相互替换,但这要求每个物体去个性化设置这些数据,可用性不佳,故二者往往是叠加使用,用于不同分类物体的剔除。
PVS PVS的全称是Potentially Visible Set的缩写,意为潜在可见集。PVS的基本思想为:离线的把场。 景划分成许多个块,这些分块的划分可能是均匀的3D网格,也能是自适应大小的3D网格。完成网格划分之后会计算网格之间的可见性或场景中每个物体对当前网格的可见集并存盘,PVS即得名于此。在游戏运行时读取存盘的可见性数据,根据当前相机所在的网格及它的可见网格(或物体)集来剔除掉不可见的物体,实现Culling功能。 下图所示的蓝色网格即为UE4的PVS分块: PVS是典型的空间换时间的两步式的算法:对实时渲染程序而言,它在离线生成时的时间可以忽略不计,在运行时它只需要查询当前网格的可见性,故算法时间复杂度是O(1)。PVS的缺点是会消耗大量的内存,它存储可见集的空间复杂度是O(m*n),其中m表示网格数量,n表示的是物体或网格的数量(取决于存储的是网格可见性还是物体可见性)。 试以存储物体可见集为例,场景大小为10km*10km ,网格大小为10m*10m,则就算只生成一层网格,其数量为100万 ,场景中共计30万个物体,物体使用32位索引做唯一标识,每个网格使用数组存储其可见性,则总的PVS数据集大小可能高达1T。 当然我们可以使用诸如红黑树之类的数据结构来存储可见集数据,但这样PVS在运行时的算法时间复杂度将不再是O(1)而是O(log n)。 注意到PVS存储的空间复杂度来源于网格数量和它所存储的可见性数据总量的和。对其优化可以来自于以下这些方面:
左图为开启Frustum Culling之前,可以看到所有物体都被提交给渲染管线;右图为开启Frustum Culling之后,只有和视锥体相交的这些彩色的物体通过了Culling测试,未通过测试的黑白线框所标示物体就不会被提交给渲染管线,从而节点了传输带宽及后续的渲染计算量。 Frustum Culling计算量和参与Culling的物体数量成正比,算法时间复杂度为O(n)。而对一个正常的FPP/TPP游戏来说,其在Frustum内的可见集大多数时候都会小于全体数据集的50%,所以Frustum Culling带来的收益至少是可以去掉一半以上的不可见物体,其发生时机也在于所有数据开始传输和渲染之前,故适用于所有类型的游戏应用场景。 Frustum Culling对于大世界来说,因为物体数量众多,使用传统分层的场景结构(Graph 或Tree)要比直接使用线性数组要处理的数据总量会小许多,从而更有效率。
Distance Culling Distance Culling的思想非常简单:当物体离相机超过设定的距离阈值,就把物体从可见列表中剔除。 Distance Culling执行时和Frustum Culling不同,Frustum Culling剔除掉的是完全看不到的物体,所以不需要做任何过渡性处理,但Distance Culling一般需要做淡入淡出处理以防止物体消失和出现时的画面跳变。 Distance Culling适合处理半透物体、镂空物体、草丛、贴花等面积大,Overdraw严重的物体,因为这些物体虽然包围盒很大,但是其在稍远一点,对最终画面的贡献微弱却消耗不低,在平衡画面表现和性能开销之后可酌情对上述物体开启。
Screen Size Culling Screen Size Culling和Distance Culling类似,它所用的阈值不是距离而是物体包围盒在屏幕上的投影面积。即它的思想是:当物体最终在屏幕上的投影面积小于事先设定好的阈值,就把物体从可见物体中删除。Screen Size Culling和Distance Culling一样在物体出现和被剔除时会存在画面跳变,所以同样需要做淡入淡出处理。 Screen Size Culling在实际应用过程中的适用于所有物体,它能快速使投影面积小的物体从画面中消失。对于物体密度高、小物体多的场景,它的收益高的往往超乎想象。虽然在复杂时间复杂度方面它和Distance Culling和Frustum Culling一样都是O(n),但在单个物体所需的计算量方面这两者都远小于Frustum Culling。虽然Screen Size Culling从理论上来说可以和Distance Culling相互替换,但这要求每个物体去个性化设置这些数据,可用性不佳,故二者往往是叠加使用,用于不同分类物体的剔除。
PVS PVS的全称是Potentially Visible Set的缩写,意为潜在可见集。PVS的基本思想为:离线的把场。 景划分成许多个块,这些分块的划分可能是均匀的3D网格,也能是自适应大小的3D网格。完成网格划分之后会计算网格之间的可见性或场景中每个物体对当前网格的可见集并存盘,PVS即得名于此。在游戏运行时读取存盘的可见性数据,根据当前相机所在的网格及它的可见网格(或物体)集来剔除掉不可见的物体,实现Culling功能。 下图所示的蓝色网格即为UE4的PVS分块: PVS是典型的空间换时间的两步式的算法:对实时渲染程序而言,它在离线生成时的时间可以忽略不计,在运行时它只需要查询当前网格的可见性,故算法时间复杂度是O(1)。PVS的缺点是会消耗大量的内存,它存储可见集的空间复杂度是O(m*n),其中m表示网格数量,n表示的是物体或网格的数量(取决于存储的是网格可见性还是物体可见性)。 试以存储物体可见集为例,场景大小为10km*10km ,网格大小为10m*10m,则就算只生成一层网格,其数量为100万 ,场景中共计30万个物体,物体使用32位索引做唯一标识,每个网格使用数组存储其可见性,则总的PVS数据集大小可能高达1T。 当然我们可以使用诸如红黑树之类的数据结构来存储可见集数据,但这样PVS在运行时的算法时间复杂度将不再是O(1)而是O(log n)。 注意到PVS存储的空间复杂度来源于网格数量和它所存储的可见性数据总量的和。对其优化可以来自于以下这些方面:
- 网格在划分过程中会考虑到当前网格中是否存在场景物体,那些不存在物体的网格则会被丢弃掉。这样可以减少网格的总数量。某些实现还会限制网格只能生成在接近地形的平面上或潜在的玩家可行走区域进一步减少网格数量。
- 网格划分考虑自适应几类大小而不是均分,在空旷的地方生成大的网格,在城市、孔洞区域生成更小的网格以用于减少网格总量
- 把PVS当作粗略的剔除算法,只存低层级的Scene Graph或Octree的节点的可见性而不是存物体或网格本身的可见性。如只存Octree第3级的可见性,则可见集总大小只有512个。
- 把PVS当作精确的剔除算法,但只存周围区域的可见性(如只存1平方公里内的物体可见性,则上例同样的物体密度和网格密度,PVS数据总大小可能只有10M左右)。
- 对PVS数据开始流式加载,因为视角移动缓慢且连续,流式加载可以缓解PVS的内存占用,但其无法减少游戏包体的大小
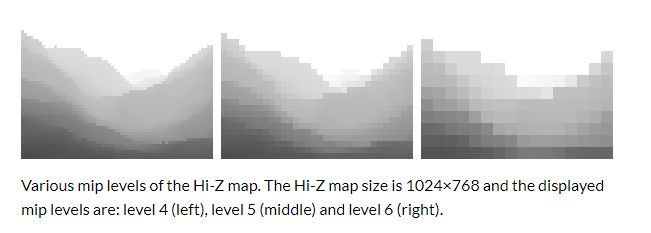
读取上一帧的Z Buffer或使用延迟管线当前帧Pre-Z Buffer,生成其Mipmap ,即Hi-Z Map(或Pyramid Z Buffer)。在Mipmap取值的时候和普通Mipmap使用的双线性或其它均值分布Filter不同,它的Filter是取四个像素中的最大值(Reversed-Z 则取最小值)。这样采样的目的是为了防止错误的剔除。Hi-Z map示意如下图所示:

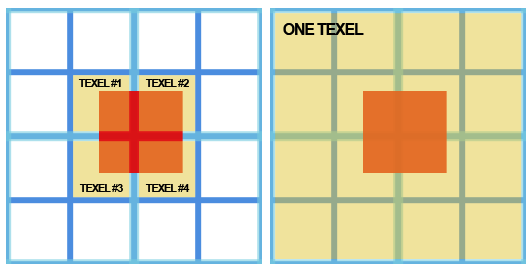
通过上一帧的ViewProjection矩阵,我们可以把物体的包围盒投影到屏幕空间,使用根据物体包围盒的大小,选取合适的Hi-Z map对应的mipmap使得包围盒投影后占一个像素大小,方便后续剔除处理的时候,只需采样周围2 x 2 的Hi-Z map像素就足以进行深度剔除。包围盒一般可使用AABB或OBB。使用Hi-Z进行剔除示意如下:
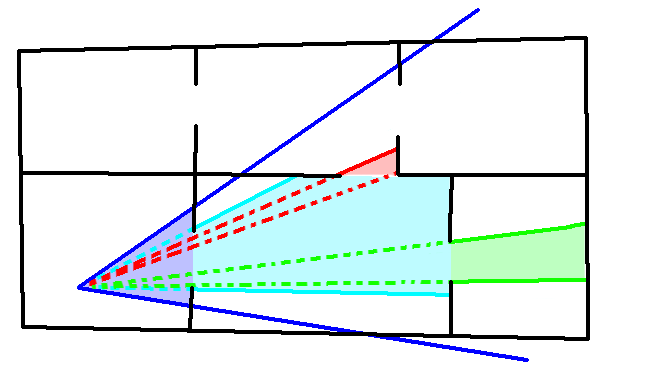
 在执行完Hi-Z剔除之后,数据可以回读取CPU端进行渲染提交,也可以使用GPU-Driven模式直接修改渲染Buffer本身从而减少GPU->CPU数据传输的开销。 使用上一帧Z buffer进行剔除有一个较为明显的问题是处理不了相机的高速移动和转动。如果使用的是CPU端回读Hi-Z剔除结果的方案,则数据回读也可能带来卡顿,使用异步回读则可能带来更多帧的延迟,从而使剔除失效的情况增加。无法处理相机高速运动的问题不光是Hi-Z的问题,接下来所述及的两个遮挡剔除算法同样被这个问题所困扰。
Software Occlusion Culling 接下来介绍的两种都是遮挡剔除算法,从被工程上提出和使用的顺序来看,应该先介绍硬件的遮挡查询(Hardware Occlusion Culling,HOC)再介绍软件遮挡查询。但因为从已有的无论PC还是手机项目的使用的效果来看,软件遮挡查询(SOC)在性能上都显著优于HOC,故在此介绍顺序如是反转。 SOC的基本方法为:
在执行完Hi-Z剔除之后,数据可以回读取CPU端进行渲染提交,也可以使用GPU-Driven模式直接修改渲染Buffer本身从而减少GPU->CPU数据传输的开销。 使用上一帧Z buffer进行剔除有一个较为明显的问题是处理不了相机的高速移动和转动。如果使用的是CPU端回读Hi-Z剔除结果的方案,则数据回读也可能带来卡顿,使用异步回读则可能带来更多帧的延迟,从而使剔除失效的情况增加。无法处理相机高速运动的问题不光是Hi-Z的问题,接下来所述及的两个遮挡剔除算法同样被这个问题所困扰。
Software Occlusion Culling 接下来介绍的两种都是遮挡剔除算法,从被工程上提出和使用的顺序来看,应该先介绍硬件的遮挡查询(Hardware Occlusion Culling,HOC)再介绍软件遮挡查询。但因为从已有的无论PC还是手机项目的使用的效果来看,软件遮挡查询(SOC)在性能上都显著优于HOC,故在此介绍顺序如是反转。 SOC的基本方法为:
选中一些物体做为遮挡体,使用CPU端执行的软件光栅化渲染器做Depth Only的渲染,即只渲染出一张和当前屏幕等比的一张小分辨率的Depth Map(如320 * 180)。同样使用CPU端的软件光栅化渲染器光栅化待渲染物体的包围盒,据其与相对于第一步所生成的Depth Map比较以返回可见性。
SOC的流程示意图如下所示: SOC的执行过程完全在CPU完成,一般它会是运行在一个或一些单独的线程里。其实现的关键在于如何执行更有效的软件光栅化渲染器、判别出最有价值的遮挡体集合、包围盒在做遮挡查询的时候需使用保守光栅化以避免在小分辨率Depthmap中出现误剔除。 SOC的光栅化部分是比较典型的计算密集型应用,一般都会使用SSE或Neon等向量指令集进行加速。
Hardware Occlusion Culling HOC和SOC类似,只不过它的执行是在GPU端而不是CPU端——现存的渲染API大多已支持硬件遮挡查询。HOC相比SOC,其遮挡体的会带来额外的Batch,从而带来额外的消耗,对于复杂场景或大场景来说,其查询的效率很多时候会超过渲染这些数据本身的消耗,现在已很少在项目中看到其实装。
Portal Culling Portal Culling在卡神的Quake时代就已经存在且可以自动生成了。其基本思想和Frusutm Culling基本上一致,它通过构造类似视锥体的棱台来做裁剪,不同的是视锥的上下左右平面来源是Fov和Aspect,而Portal的上下左右平面来源于场景中的孔洞。正因如此,它的应用场景也受限于纯室内或从室内看室外(或相反的情形),但不适合开阔的野外场景。 Portal的示意如下所示:
SOC的执行过程完全在CPU完成,一般它会是运行在一个或一些单独的线程里。其实现的关键在于如何执行更有效的软件光栅化渲染器、判别出最有价值的遮挡体集合、包围盒在做遮挡查询的时候需使用保守光栅化以避免在小分辨率Depthmap中出现误剔除。 SOC的光栅化部分是比较典型的计算密集型应用,一般都会使用SSE或Neon等向量指令集进行加速。
Hardware Occlusion Culling HOC和SOC类似,只不过它的执行是在GPU端而不是CPU端——现存的渲染API大多已支持硬件遮挡查询。HOC相比SOC,其遮挡体的会带来额外的Batch,从而带来额外的消耗,对于复杂场景或大场景来说,其查询的效率很多时候会超过渲染这些数据本身的消耗,现在已很少在项目中看到其实装。
Portal Culling Portal Culling在卡神的Quake时代就已经存在且可以自动生成了。其基本思想和Frusutm Culling基本上一致,它通过构造类似视锥体的棱台来做裁剪,不同的是视锥的上下左右平面来源是Fov和Aspect,而Portal的上下左右平面来源于场景中的孔洞。正因如此,它的应用场景也受限于纯室内或从室内看室外(或相反的情形),但不适合开阔的野外场景。 Portal的示意如下所示:
 小结 :以上8种Culling技术剔除的粒度是最细只能到物体级别。接下来介绍的的剔除算法为三角形或三角形簇级别,但因其计算量大,且如果在CPU端实现的话资源会拆的非常碎从而不利于制作流程优化,故仅适用于GPU Driven Rendering Pipeline。
Mesh Cluster Culling 在Mesh Shader出来之前,Mesh Cluster Culling就已经成型,它把要渲染的Mesh拆成一些空间上邻近的三角形簇,把一个球型Mesh分簇的示意图如下所示,每种颜色表示一个Cluster。
小结 :以上8种Culling技术剔除的粒度是最细只能到物体级别。接下来介绍的的剔除算法为三角形或三角形簇级别,但因其计算量大,且如果在CPU端实现的话资源会拆的非常碎从而不利于制作流程优化,故仅适用于GPU Driven Rendering Pipeline。
Mesh Cluster Culling 在Mesh Shader出来之前,Mesh Cluster Culling就已经成型,它把要渲染的Mesh拆成一些空间上邻近的三角形簇,把一个球型Mesh分簇的示意图如下所示,每种颜色表示一个Cluster。
 然后针对这些三角形族进行实施剔除算法,如Sceen Size Culling ,Hi-Z Culling和Backface Culling。其中Backface Culling用于剔除模型背向相机的一面。对上例的球体来说,Backface Culling能总是能减掉一半的面。 下例是Backface Culling的示例:
然后针对这些三角形族进行实施剔除算法,如Sceen Size Culling ,Hi-Z Culling和Backface Culling。其中Backface Culling用于剔除模型背向相机的一面。对上例的球体来说,Backface Culling能总是能减掉一半的面。 下例是Backface Culling的示例:
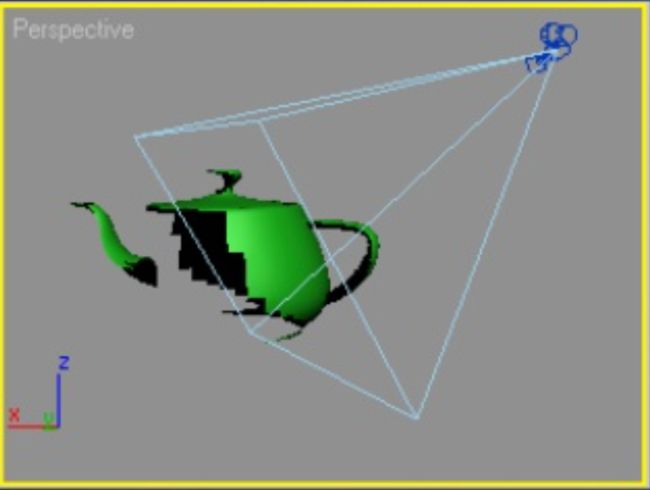 下图是逐三角形Screen Size Culling的示例:
下图是逐三角形Screen Size Culling的示例:
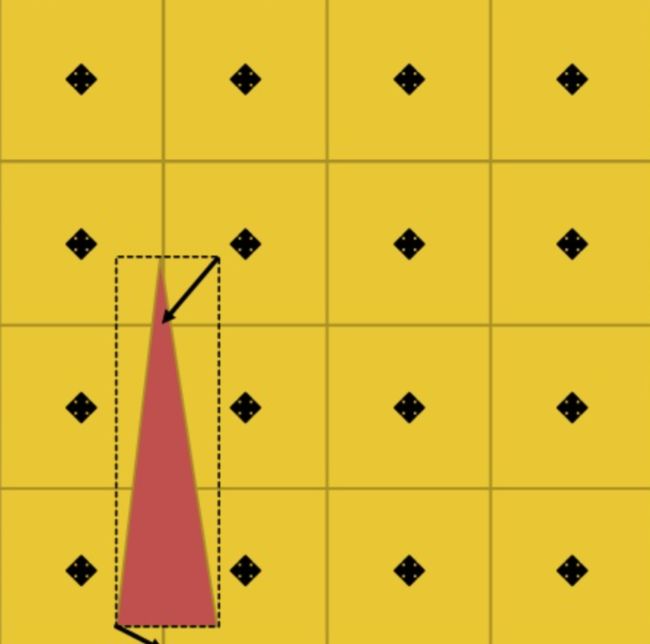 Mesh Cluster Culling的一个优化是使用Cone来加速计算Backface。如下图黑线所示的一个Cluster,计算Cone的Normal 和ViewDirection的夹角可以一次剔除掉一簇三角形。
Mesh Cluster Culling的一个优化是使用Cone来加速计算Backface。如下图黑线所示的一个Cluster,计算Cone的Normal 和ViewDirection的夹角可以一次剔除掉一簇三角形。
 总结: 除上述软件实现的Culling算法之外,硬件层面也还有Viewport Culling ,Early-Z/HSR/Forward PixelKill等算法。软件层面也还有用于剔除Alpha Test密集的区域的Pre-Z。
总结: 除上述软件实现的Culling算法之外,硬件层面也还有Viewport Culling ,Early-Z/HSR/Forward PixelKill等算法。软件层面也还有用于剔除Alpha Test密集的区域的Pre-Z。

 如何做用户运营体系的推导思考
如何做用户运营体系的推导思考

Automl框架katib浅析

算力时代将至——我们是否已经做好准备
