Ubuntu16.04-安装TensorFlow-gpu版(详细)
一共需要4个组件
- TensorFlow
- Nvidia驱动
- CUDA
- cuDNN
TensorFlow-gpu版安装
贴上官网作为参考。
# 更新pip工具,如果是python3就用pip3
pip install --upgrade pip
# 默认安装当前最新的稳定版,python3同上
pip install tensorflow-gpu
此时可能会碰到下载缓慢的问题,可以更换pip源,亲测有效,修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐藏文件夹),加入:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
windows下,直接在user目录中创建一个pip目录,如:C:\Users\xx\pip,新建文件pip.ini。内容同上。
安装完成后进入python环境,导入库
import tensorflow as tf
可能会出现如下提示,这是缺少TensorRT有关库,不影响使用,也不影响GPU加速。
2020-06-05 21:38:11.007131: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library ‘libnvinfer.so.6’; dlerror: libnvinfer.so.6: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/cuda/lib64:/home/kadian/arm_move2/devel/lib:/opt/ros/kinetic/lib:/opt/ros/kinetic/lib/x86_64-linux-gnu
2020-06-05 21:38:11.007224: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library ‘libnvinfer_plugin.so.6’; dlerror: libnvinfer_plugin.so.6: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/cuda/lib64:/home/kadian/arm_move2/devel/lib:/opt/ros/kinetic/lib:/opt/ros/kinetic/lib/x86_64-linux-gnu
2020-06-05 21:38:11.007236: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:30] Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
输入代码查看版本,这个版本号很重要,后面安装GPU相关东西都需要与这个版本号对应。
print(tf.__version__)
![]()
这样tensorflow就安装好了。
nvidia驱动安装
nvidia驱动与cuda是有版本对应要求的,可以参考网址,建议直接去官网安装最新的驱动,版本基本都满足要求,选择自己GPU型号对应的驱动,下载很慢,我是到windows上用chrome 下的,速度凑合。
安装之前要卸载原来安装的驱动(如果有的话)。
# 如果原驱动是用apt-get安装的,就用第1种方法卸载。
#方法一: original driver installed by apt-get:
sudo apt-get remove --purge nvidia*
# 方法二:如果原驱动是用runfile安装的,就用–uninstall命令卸载。其实,用runfile安装的时候也会卸载掉之前的驱动,所以不手动卸载亦可。
#for case2: original driver installed by runfile:
sudo chmod +x *.run
sudo ./NVIDIA-Linux-x86_64-384.59.run --uninstall
之后执行 lsmod | grep nouveau ,如果有输出则需禁用nouveau驱动,编辑/etc/modprobe.d/blacklist.conf文件
sudo gedit /etc/modprobe.d/blacklist.conf
#在文本最后添加:
blacklist nouveau
options nouveau modeset=0
然后执行:
sudo update-initramfs -u
重启后执行
lsmod | grep nouveau
如果没有屏幕输出,说明禁用nouveau成功。
把之前下的驱动文件放到自己记得的地方,因为待会要关闭图形化界面,用命令行找到驱动文件并安装。
首先关闭图形化界面:
sudo service lightdm stop
屏幕会黑掉,按Ctrl-Alt+F1进入命令行界面,输入用户名和密码登录即可。
cd到驱动文件的目录,执行
#给驱动run文件赋予执行权限:
sudo chmod +x NVIDIA-Linux-x86_64-384.59.run
#换成自己的文件名,后面的参数非常重要,不可省略,不然会陷入登录循环
sudo ./NVIDIA-Linux-x86_64-384.59.run –no-opengl-files
然后会出现几个选项,我记得我是no,yes,no,具体问题不记得了,影响据说不大。
安装完成后在命令行输入:sudo service lightdm start ,然后按Ctrl-Alt+F7即可恢复到图形界面。
输入命令nvidia-smi,出现GPU列表则安装成功。
CUDA安装
首先查看tensorflow2.1对应的版本,可以参考官网(翻到最下面),这里贴出来目前的版本对应关系。
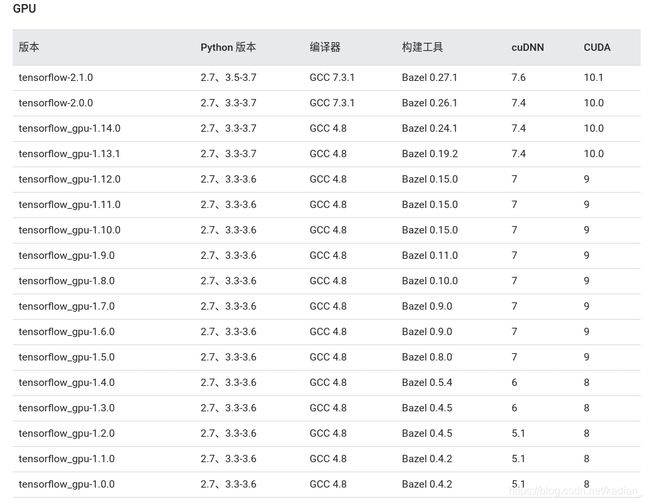
然后上官网下载对应版本,点右下角Legacy Releases选择版本,然后安装对应系统的runfile,网上建议runfile,然后会提示你如何下载和安装。
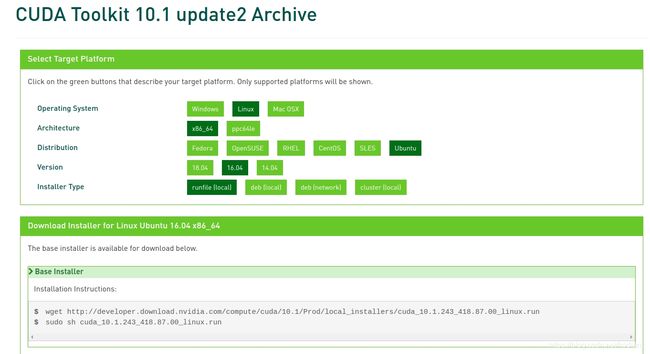
每个版本安装界面会不一样,总之不要安装driver,因为已经安装过了,其余都组件都安装就行。
然后设置下环境变量
sudo gedit ~/.bashrc
#在最下面添加:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
#注意这里可以不写cuda几点几,因为上面安装cuda的时候把cuda-10.1的文件链接到了/usr/local/cuda/,
#以后下新版本的时候会自动覆盖链接到/cuda,就不用重新设环境变量了,
#也可以把原cuda文件删掉,用 ln -s 源文件 目标文件 手动链接,注意要用绝对路径
source ~/.bashrc #使设置生效
完成后可执行 nvcc --version 查看cuda版本,执行上述nvidia-smi也可查看,但不一定准确,比如我安的10.1 ,它显示的10.2。
cuDNN安装
首先说明下cudnn的安装方式其实就是把下载下来的文件放到刚才安的cuda-版本号里,cudnn和cuda的结构都是一致的,把cudnn里的东西放到对应地方即可。值得注意的是要放在/usr/local/cuda-版本号里,不要放在/usr/local/cuda里。
去官网下载你需要的cudnn,下载的时候需要注册账号。选择对应你cuda版本的cudnn下载,标题有说明,for CUDA几点几,然后选择cuDNN Library for Linux。
下载完成后将cuDNN中的一些文件放到cuda-版本号对应的一些地方,执行;
#解压,注意更换自己的文件名
tar -xvf cudnn-10.1-linux-x64-v7.6.5.32.tgz
#移动相应文件到cuda-版本号,注意更换自己的文件名
cp cuda/include/cudnn.h /usr/local/cuda-10.1/include/
cp cuda/lib64/libcudnn* /usr/local/cuda-10.1/lib64
chmod a+r /usr/local/cuda-10.0/include/cudnn.h /usr/local/cuda-10.0/lib64/libcudnn*
测试CUDA:
cd /usr/local/cuda-10.1/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
会输出显卡信息:
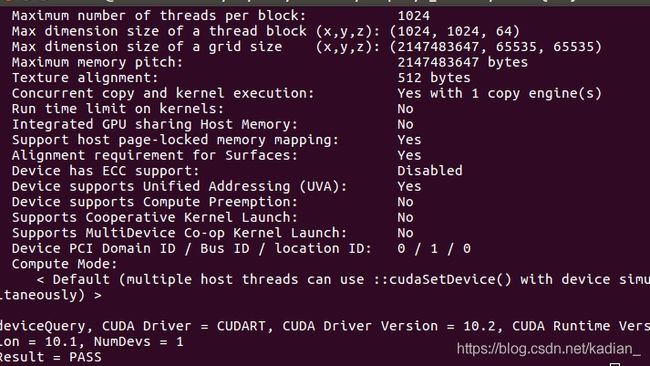
测试
测试tensorflow gpu加速。
进入python
import tensorflow as tf
tf.test.is_gpu_available()
返回日志信息,gpu信息和True就证明可以。
还可以跑一下MNIST手写数字测试下。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)

运行时执行 nvidia-smi可以查看GPU使用情况:

可以看到有调用GPU加速,成功!
参考
https://www.cnblogs.com/microman/p/6107879.html
https://blog.csdn.net/hancoder/article/details/86634415