C语言学习
文章目录
- 1.HelloWord
- 2.语法规则
- 3.常,变量与数据类型
- 4.关于计算机的内存编址
- 5.计算机的补码
- 6.数据类型
- 7.格式输入和输出
-
- 7.1 printf 输出
- 7.2 scanf 输入
- 7.3 putchar() && getchar()
- 第七章总结
- 8. 类型转化
-
- 8.1 隐式转化
- 9. 运算符与表达式( operator && Express)
-
- 9.1 运算符的优先级和结合性
- 9.2 运算符分类
- 9.3 常见运算符及构成的表达式
-
- 9.3.1 赋值运算符与赋值表达式
- 9.3.2 算术运算符与算术表达式
- 9.3.3 关系运算符与关系表达式
- 9.3.4 逻辑运算符
- 9.3.5 条件运算符与条件表达式
- 顺序求值运算符(逗号运算符)
- 第9章小结
- 第八章 函数
-
- 8.1 C标准库及其库函数
-
- 8.1.1 库存在的意义是什么
- 8.1.2 如何收使用库函数
1.HelloWord
- 首次被 Dennis Ritchie 在《C语言程序设计》引用。C语言的诞生是 Dennis Ritchie 与 Ken Thompson 为了开发一款游戏而诞生, 也就是星际旅行。
- 输出打印HelloWorld:
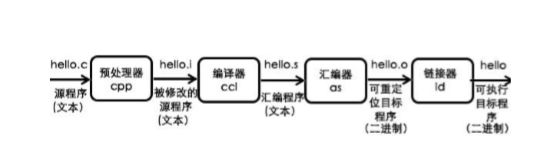
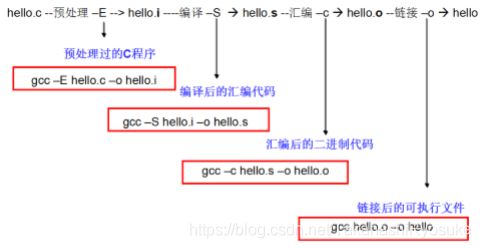
#include - 从源文件到可执行文件有以下步骤:
- 推荐先从学习Linux着手,透过现象看代码生成的本质:
- 预处理 - eg.处理头文件, 注释处理:
gcc -E main.c -o main.i - 编译 - eg.生成汇编文件;
gc -S main.i -o main.s - 汇编 - eg.生成二进制文件;
gcc -c main.s -o main.o - 链接 - eg. 链接库;
main.o -o hello
- 预处理 - eg.处理头文件, 注释处理:
2.语法规则
计算机在模仿自然语言的过程中,模仿的越相似,这门语言就越容易上手(一门叫Racket的语言相当容易上手),但是在模仿过程中并不能做到百分百模仿(也正是我们学习的原因)。所以我们需要规则来规范我们的表达,即使语法。
-
程序:
为了让计算机执行某些操作或解决某个问题而编写的一系列有序指令的集合 -
流程:
流程也就是算法,梳理流程就是整理出一套算法的过程。
3.常,变量与数据类型
- 变量:
int HP; //类型 变量命
通常,一个人的性别,身高,收入我们都需要声明一个变量来储存,声明过程中,我们在命名的同时(实际上是在给储存这一类型的内存命名,变量也就是这一段内存空间的别名),还需要声明类型(到底在内存中用多大的内存来储存这个变量)来进行限定,比如游戏里的血量。
- 关于命名,实际上是在给储存这一类型的内存命名,变量也就是这一段内存空间的别名。
- 声明类型,也就是我们到底在内存中需要用多大的内存来储存这个变量。
- 变量的命名通常是由数字0-9,字母a-z,A-Z,以及下划线_组成,且我们不以数字打头, 不使用保留关键字,也就是避讳,区分大小写,也不能出现空白字符。
- 通常取名会以驼峰命名法来增强可读性。eg. finalResult;
int A3b, a3b, ab3, a_b, _ab;
4.关于计算机的内存编址
在学习类型之前,建议先了解内存的一些基础知识来铺垫,然后再继续学习。

-
内存模型(32位)
1.最小寻址单位就是 1 Byte(1字节)。
2. 总共有2^32个单位地址(寻址空间),也就是寻址能力有多少根线(一般是地址总线,32跟线就是大约4GB),注意,寻址空间用位,寻址能力用字节,单位是不一样的,并不是直接转换。 -
关于CPU读写内存
CPU在读写内存数据时,首先需要指定储存单元的地址:
1.存储单元的地址(地址信息)
2.器件的选择,到底是 读 or 写(控制信息)
3.读写的数据(数据信息)
1. 地址总线:
2. 数据总线:
3. 控制总线:以下是读取流程:
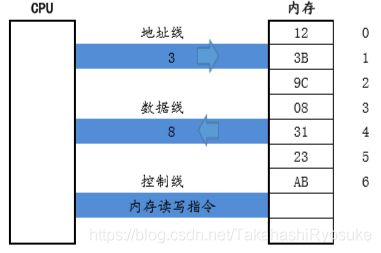
以下是写入流程:

关于CPU与内存的关系,我们可以简单的把CPU比作拿着刀的厨子,内存就是一个菜板,在汇编过程中,数据就是一块肉,厨子随时都握着刀在菜板上对肉进行操作。
5.计算机的补码
再次强调,此处依然是对数据类型的学习做铺垫。在上面提到了最小的寻址单位是1字节,那么关于1字节,最大能表述的数的范围是多少,到底能装多大的数据呢。
-
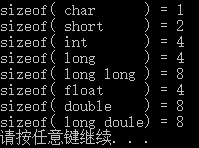
常用数据类型的占用内存大小:
char :1个字节
char*(即指针变量): 4个字节(64位为8字节)(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节 (64位为8个字节)
long long: 8个字节
unsigned long: 4个字节 -
补码的表示范围
每一套编码,都能带来一套新的表示范围,例如在编码之前的自然编码,表示范围是[-127,127]。而补码的表示范围是[-128,127]。我们在研究一套编码的同时,还应该注重编码之后的运算。相较于自然编码,补码的运算依然可以用正常的二进制进行计算,这也就是自然编码被淘汰的原因。 -
关于补码的实现这里就不过多阐述了。真正有意思的是补码的原理。
补码运用了一个叫做“模”的概念。

例如:假设当前时针指向 10 点,而准确时间是 6 点,调整时间可有以下两种拨 法:一种是倒拨 4 小时,即:10-4=6;另一种是顺拨 8 小时:10+8=12+6=6。在以 12 模的系统中,加 8 和减 4 效果是一样的,因此凡是减 4 运算,都可以用 加 8 来代替。对"模"而言,8 和 4 互为补数。 实际上以 12 模的系统中,11 和 1,10 和 2,9 和 3,7 和 5,6 和 6 都有这个特性。共同的特点是两者相加等于模。
对于计算机,其概念和方法完全一样。n 位计算机,设 n=8, 所能表示的最大 数是 11111111,若再加 1 成为 100000000(9 位),但因只有 8 位,最高位 1 自然丢 失。又回了 00000000,所以 8 位二进制系统的模为 28。在这样的系统中减法问题也 可以化成加法问题,只需把减数用相应的补数表示就可以了。
-
在C语言中,我们可以这样输出一个数字的二进制数:
void transBin(char ch) {
int i = 8;
while (i--) {
if ((1 << i)&ch)
printf("1");
else
printf("0");
if (i % 4 == 0)
printf(" ");
}
putchar(10);
}
int main() {
int count = 0;
for (char i = -128; i < 127; i++) {
count++;
printf("%d --> ", i); transBin(i);
}
printf("%d --> ", 127); transBin(127);
printf("一共输出了%d个数",count+1);
system("pause");
return 0;
}
- 小结一下:
1.补码中,符号位也可以参与运算,不需要单独标识。
2.补码中只包含一个0。
3.补码中,我们可以用加法来表示减法,乘法,甚至除法。
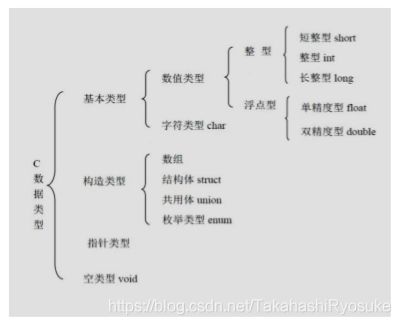
6.数据类型
前面把内存稍微理解一下以后,可以开始看数据类型了。前面我们说数据类型也就是我们到底在内存中需要用多大的内存来储存这个变量。在一个公司中,我是一个底层员工,我只需要管好我自己,张组长是一个组长,需要看好整个组,王总是公司老板,要运营整个公司,每个人负责的管辖范围的关系。
- 类型总览
- 关于C中获取类型大小:
我们可以通过sizeof来获取:
#include 结果如下(不同平台结果可能不同,单位:字节):
- 关于整型:
对于游戏来说,数据类型先择还是蛮重要的,瘦子撑不起胖衣服,胖子系不了瘦腰带,100的血量不能用8个字节去声明,这是浪费,更是耍流氓。
1 字节 char unsigned: 0 - 255 ----------- 0 - 2^8-1
1 字节 char signed: -128 - 127 --------- -2^7 - 2^7-1
2 字节 short unsigned: 0 - 65535 ------ 0 - 2^16-1
2 字节 short signed: -32768 - 32767 – -2^15 - 215-1
4 字节 int unsigned: 0 - 255 -------------- 0 - 2^32-1-
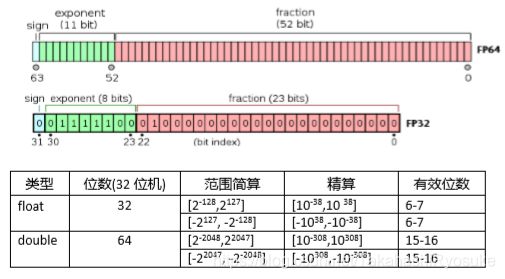
4 字节 int signed: -128 - 127 ------------ -2^-31 - 2^31-1 - 关于浮点型:

浮点数是由三个不分构成的:从左到右依次是符号(sign),阶码(Exponent),和尾数(Mantissa)。类似于100.23这个数,我们在S放入符号,P放入2,M放入0.10023,也就是0.10023 x 10^2,说变了就是类似于科学计数法。
浮点类型主要是精准度的问题,内存占比越大,小数后面越精准。
- 关于字符类型
在计算机的内存当中,只能够去存储数值类型。我们不能够直接的去储存一个字符。
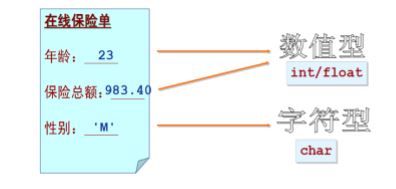
例如上图中,当一个数据类型是char类型时,且当这个char的数值是77时,我们在计算机中通过ASCII表来将它转换成‘M’(只能在现实的时候进行转化)。基本的ASCII字符集包括了 96 个可打印字符以及 32 个控制字符一共 128 个。
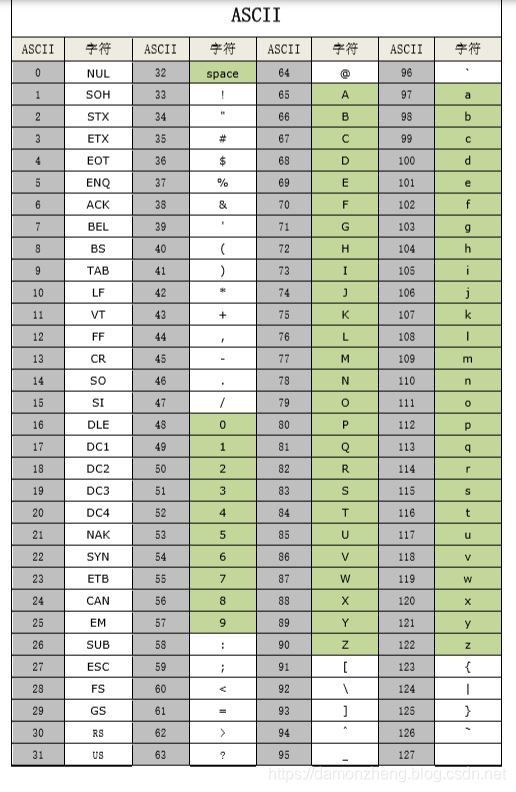
ASCII是一一对应的关系。0 - 31 就是控制字符,32 开始都是可打印字符。其中,32 对应空格,48 对应字符’0‘,49 对应字符’1‘,65 对应字符’A’,97 对应字符‘a’。
int main() {
unsigned char ch;
for (ch = 0; ch < 128; ch++) {
printf("%3d ->> %c\n",ch,ch); //如上文所提,只有在显示是才会转换,转换就在printf中实现的;
}
system("pause");
return 0;
}
所以在计算机中,我们在二进制的基础上架设了补码的概念,得到了能表示正负数的表示形式;然后我们又在这种形式的 0 - 127 上又架设了一对应的ACSII码的概念。计算机就是这么一步步在二进制上扩展开来的。
- 转义字符
就如同他的名字一样,其实它在语言层面已经有了一个字符的意义,已经被征用过了,但是我们又给了它一个别的意义。一般来说,转义字符都起到一个控制作用。

printf("I like "basketball".");
printf("I like \"basketball\".");
类似上面的例子,我们不得不在字符串中使用双引号来特质basketball,但是” “在C中已经有了字符串的意义,所以我们需要转义字符"来脱离被征用的意义 。
-
常量(Constant)
也就是从字面意思上去理解。变量是在程序中能变的量,常量也就是在程序中不可改变的量,通常以字面量(Literal)或者宏(Macro)的形式出现。主要是用于赋值或者参与计算,通常在做游戏中,我们会给一些不会改变的量声明常量类型,比如技能名字啊,地名啊。 -
字面量的用法:
int main(){
int age = 22;
age = age + 3;
//在这里,10,30也就是一种常量,通常参与运算
system("pause");
return 0;
}
- 关于宏的用法:
#define UltDam 43.5 //只需要同意在这里修改HP的值即可;
int main(){
float hp = 100.0 - UltDam;
printf("剩余血量%f",hp);
system("pause");
return 0;
}
还有一点,宏的处理是在预处理阶段进行处理的。
注意,常量也是有类型的哦!!!!!那么我们如何证明常量其实是有类型的呢?
#define HP 100.0
#define Sex "M"
#define Weight 75
int main() {
//简要证明常量Constant也是有类型区分的;
printf("the size of HP is %d\n", sizeof(HP));
printf("the size of Sex is %d\n", sizeof(Sex));
printf("the size of Weight is %d\n", sizeof(Weight));
system("pause");
return 0;
}
输出结果如下:
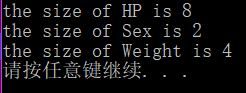
由此我们看到,常量的内存大小依然是不同的。有一点值得提醒,就是C并没有非常明确规定不同数据类型到底占多少个自觉,只是规定后一个数据类型一定比前一个数据类型所占内存要大(char < int < double)。
7.格式输入和输出
7.1 printf 输出
- printf(" 格式控制字符串", [输出表列] );
- printf 函数称为格式输出函数,其关键字最末一个字母 ‘f’ 即为 “ format ” (格式) 的意思。也就是按照用户制定的格式来进行打印输出。
- 关于控制字符串:
- ”%d“表示按十进制整形进行输出
- "%f"表示按实型数据进行输出
- "%c"表示按字符型输出
- [ ] 里的数据其实并没有变,输出一直是按照用户使用格式控制字符来输出的。
- [ ] 里的内容至少可以划分为两类:
- 第一类就是进行格式控制,格式控制要求跟输出是一一对应的。
- 第二类就是非格式控制字符,非格式字符将原样输出。
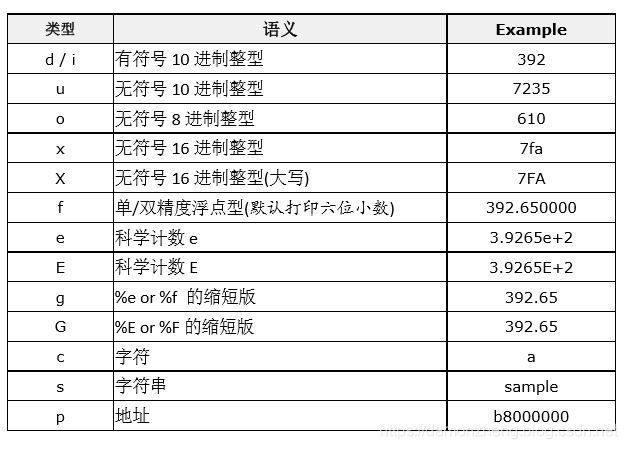
- 再来,其实格式控制符的完整版本可以表示为 “%[标志][输出最小宽度][.精度][长度]类型”
- 类型:以下的类型字符用以表示输出数据的类型:
- 宽度表示用十进制整数来输出的最小位数。若实际位数多于定义宽度则按照实际位数进行输出;若实际为数小于定义宽度,则以0或空格进行填补。
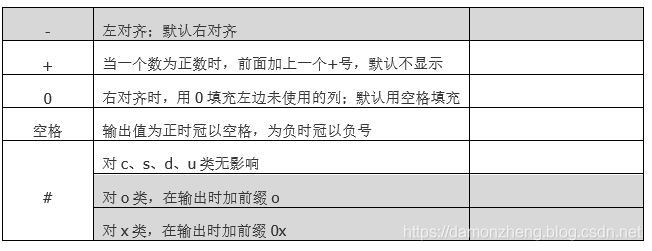
- 标志:

- 精度:
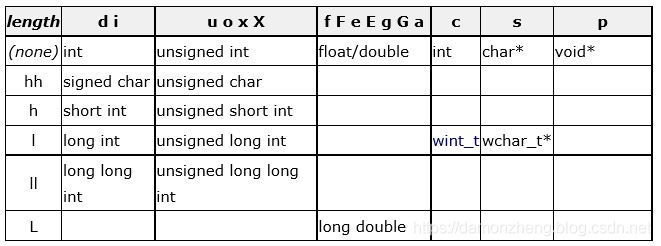
精度格式以 “.” 开头,后跟十进制整数:若输出数字,则表示最小数的位数;若输出是字符,则表示输出字符个数;实际位数大于所定义的精度数,则裁去超出部分。 - 长度:
7.2 scanf 输入
- scanf 函数的一般形式为:scanf(“格式控制字符串”, 地址列表)
int a, b;
scanf("%d%d"&a,&b);
与 printf 不同的是,scanf 是通过键盘输入进来的数据以格式化控制字符的要求来储存进 a 和 b 的内存地址。注意,与格式输出一样,在格式控制字符串里的非控制字符,我们需要原样输入。!!!!!最重要的一点,格式一定要匹配,否则结果将不可预计!!!!
- 关于 scanf,还有一个值得注意的是当需要输入字符时,应采取以下形式:
char aa ='a'; char bb = 'b';
scanf("%c %c",&aa,&bb);
因为在我们输入字符时容易在多个字符中间打入空格或是tab键,空格也是字符,所以在存储数据时,往往会把空格一起存入内存中。加入空额可以避免这一情况,而且,可以加入多个空格,在 scanf 时只会被视为一个空格:
char aa ='a'; char bb = 'b';
scanf("%c %c",&aa,&bb);
与上一个等价。但是!!!!!!!!重点里的重点,由于大多数人现在都很喜欢 VS,我也不列外,自从开始学习 Unity 以后,更是什么都使用VS,这里就会有一个问题了。VS 中我们使用 scanf_s 来代替 scanf,如果输入的数据不参杂任何的字符,那么两者基本没有太大的区别,但是只要有字符的出现,那么 scanf_s 就不能按照 scanf 的用法来了。正确用法应该是 :
scanf_s("%c %c", aa, 1, bb, 1);
scanf在使用接受字符数据时,并不会检查其边界,这样很容易产生内存泄漏问题。而 scanf_s 就是针对这一问题而诞生的产物。在输入字符时,我们需要提供一个数字来表示我们期望读取的最大字符位数。
7.3 putchar() && getchar()
- 这个的用法还是蛮简单的,就不过多阐述了,实践出真理类型:
char test01;
test01 = getchar(); //输入一个char,例如e;
putchar(test01); //输出一个char,若上一个输入e,这里将得到输出 e。
我常用的用法就是 putchar(10),换一行,比 printf("\n") 简单一点总感觉。不过使用 putchar(“\n”)也是一样的。
第七章总结
有一点忘记研究了,就是以下形式:
int a = printf("12345");
printf("%d",a);
实际上a的值就是 printf 中输出字符串的位数,也就是 预宽:
int a = printf("%10d",11111);
printf("\n%d\n", a);
这里的输出就可以看出来:

8. 类型转化
类型的转化分为两种:
1.隐式转化
2.强制转化
8.1 隐式转化
隐式转化是在语言实现层面上比较难的一点,隐式转化在使用过程中其实是自动帮我们完成的,并不需要人为的参与。但是我们还是应该来了解一下到底是如何实现的,对我们理解计算机内部规则还是很有帮助的。
- 隐式转化又分为三类。
- 整型提升(Integer Promotion):
char, short, int等类型在一起运算时,首先提升到int类型。原理就是符号扩充。实践出真理,怎么去求证这一过程呢:
char ch = 2;
int ln = 3;
short sh = 4;
printf("the size of ch ->> %d\n", sizeof(ch)); //得到1;
printf("the size of ln ->> %d\n", sizeof(ln)); //得到4;
printf("the size of sh ->> %d\n", sizeof(sh)); //得到2;
printf("the size of it when we calculate it ->> %d\n", sizeof(ch + ln + sh)); //得到4
关于实现的原理,上面提到是符号扩充。什么是符号扩充呢:
- 其实从名字我们就可以得出结论,就是把符号扩充出去。一个土豪包了一辆火车,char号。可是这个 char 是只有 1 个客箱的公交车,而 int 有 4 个客箱,所以土豪重新换成了包 int 号火车, 当把 char 里的乘客从最后一节客厢依次放进 int 里时,前面还有 3 个客箱是空着的,但是 int 也不可以停车去拉别人呀,所以每一节车厢我们都会显示 “ 已满员 ”。当把一个char放入int里时,所有在char符号位以前的bit都会以char的符号为来填补。这样做是为了保证数值的正确性。
2.混合提升:
- 当运算中最大范围为double时,则转化为double;
- 当运算中最大范围为float时,则转化为float;
- 当运算中最大范围为longlong时,则转化为longlong;
- 当运算中最大范围为int时,则转化为int;
- 当运算中有char short时,则一并转化为int;
- 还有一个是赋值转化:
赋值时不需要提升谁,如果把小数赋值给整数,则剔除小数部分;若把整数赋值给小数,则加上小数点。
- 接下来再看看强制转化:
隐式转化很多时候是有缺陷的,很多时候,语言的隐式转化不能够满足我们日常所需,这时候我们就需要强制转化来帮助我们了。就好比我们的日常生活中,我们受道德和法律两层制约来管理我们自己,我们默认要遵从道德规范,当道德规范约束不了时,就需要法律的制裁了,所以通常来说,当我们需要强制转化时,往往是我们的设计不够规范严谨导致的:
(类型)待转表达式
int ln = 10;
int ln2 = 3;
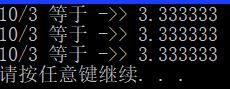
printf("10/3 等于 ->> %f\n", 10/3.0);
printf("10/3 等于 ->> %f\n", (float)ln / ln2);
printf("10/3 等于 ->> %f\n", ln / (float)ln2);
以上三种表达式输出一致:
如上,如果我们想要一个 float 类型输出,那么我们其实在 一开始的变量声明就出了问题,导致我们在输出结果时必须强制类型转换成 float, 所以当我们强制转换时,应该反思我们的设计在哪里存在不合理。我们应该:
float ln = 10.0f;
int ln2 =3;
// or
int ln = 10;
float ln2 = 3.0f;
- 题外话,这里有一个知识点,叫做修正值。在有的编译平台里,浮点数并不是一个很准确的数,特别是0.3或是0.7这两个数,当我们如下输出时:
double tmp = 0.7;
printf("%d",(int)(temp*10));
输出的结果并不一定是7,而可能是6,当tmp是0.3时,输出很可能是2。这是因为浮点数的储存可能并不精准,譬如0.3,实际储存的是0.299999,0.7则是0.699999。这个时候就可应用一个修正值来操作:
double tmp = 0.7;
printf("%d",(int)((temp+0.000001)*10));
这个0.000001就是一个修正值。不过在VS平台上试了一下,浮点数0.1-0.9基本上没什么问题。
之前有看到过一道面试题,让比较一个浮点数和零的值的大小,这就是在考察一个修正值的概念了。我们通常说一个值多大,往往是包含了一个修正值的范围,比如0.2999999到3.000001,我们都叫做3,所以当比较浮点数和零的大小时:
double tmp;
printf("请输入一个浮点数:");
scanf_s("%lf", &tmp);
if (tmp > 0 - 0.000001 && tmp < 0 + 0.000001) {
printf("tmp == 0\n");
}
else {
printf("tmp != 0\n");
}
9. 运算符与表达式( operator && Express)
学习了类型,变量和常量之后,就需要学习运算符来对他们进行运算啦!一个表达式就是由操作数和运算符构成的,其中操作数本身也可以是一个表达式,在每一个表达式的后面加一个;(分号)结尾。
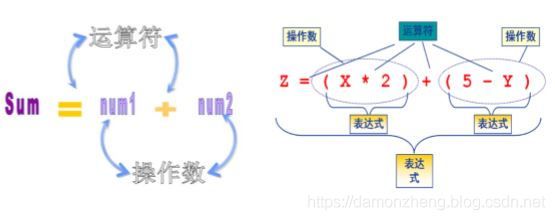
9.1 运算符的优先级和结合性
和小学学的差不多:
- 先乘除;
- 后加减;
- 括号优先级最高。
唯一去舍去的就是运算从左到右依次运行,计算机是可以从右往左计算的。其中,赋值运算“ = ”就是最常见的从右往左运算。记住一句话,任何表达式都是有值的。当一个表达式是一个赋值运算时,这一整条表达式的值就是赋值运算符左边的值:
(a = b)
这一句(a = b) 就是一条表达式,这个表达式的值就是a; 举一个很不常见的例子:
a = b = c = d = e = 2;
按照平时理解,我们就是从左往右,来一个个等于,或者是从右往左运算一个个等于。其实不是的,赋值运算都是从右往左一个个赋值:
- 把5赋值给e,然后 e = 5 是一个表达式,值是5;
- 把 e = 5 这个表达式的值赋值给d,那么d = (e = 5) 这个表达式的值就是 5;
- 以此类推。。。
这就是结合性。
不同优先级的运算符,运算次序按优先级由高到低执行;同意优先级的运算符,运算次序按接回方向的规定执行。
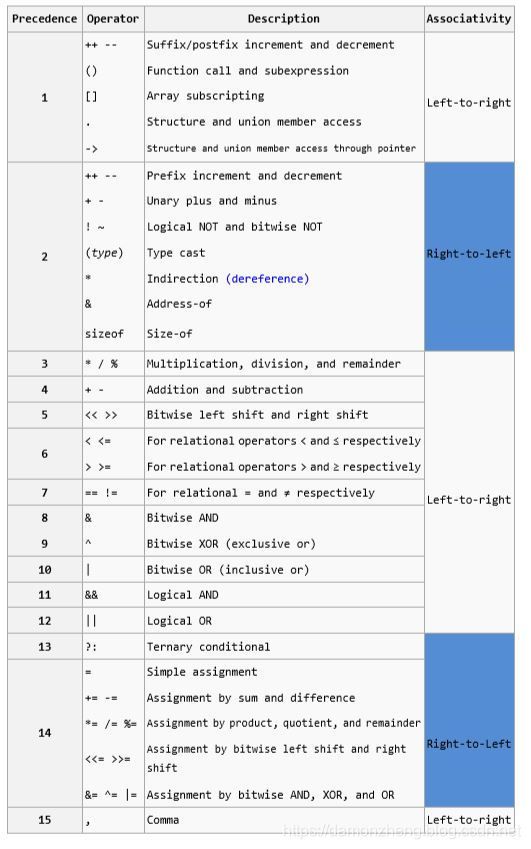
9.2 运算符分类
计算机中还按照操作的数的个数将其分为3类,单目运算符,双目运算符和三目运算符:
- 单目运算符操作数只有一个:a++;
- 双目运算符操作数有两个:a+b;
- 三目运算符也是唯一一个三目运算符:a>b ? c : d 三个操作数分别是:a>b, c, d。
9.3 常见运算符及构成的表达式
还是那句话,表达式既有类型,也是有值的
9.3.1 赋值运算符与赋值表达式
赋值运算符加上操作数,就构成了赋值表达式,以下列表是赋值运算符:
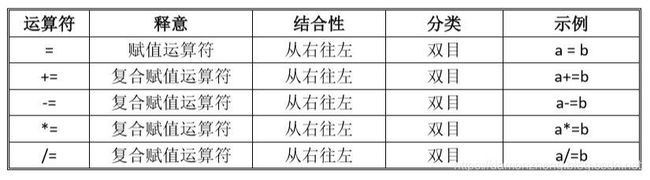
其中有以下需要注意的:
- 把右侧表达式的值赋值给左侧的变量,表达式的值是等于左值的;
- 运算符两侧类型比一致时,要进行类型转换;
- 赋值表达式可嵌套, eg. a=b=c=d;
- 复合赋值运算符是一种简洁的需要。
9.3.2 算术运算符与算术表达式
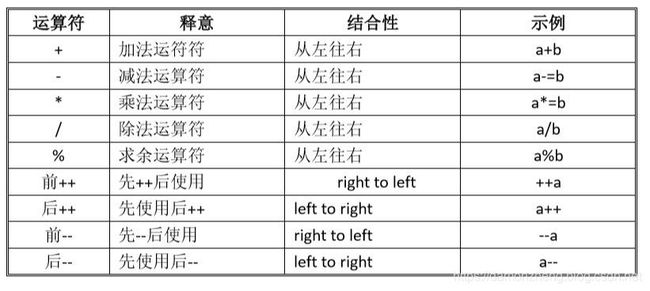
- 这里着重讨论一下求余运算符 % :
- 符号始终等同于被求余的数,也就是左边的那一个;
- 它有洁癖,必须是两个整型才能求余,因为如果是浮点数求余的话,我们实际上是除得尽的,比如10.0/3,结果就是3.333333。但是10/3我们是除不尽的,所以我们才需要求余运算。
求余还可以表示一种整除关系,比如,请求出0-100中,可以被3整除的数:
for (int i = 0; i <= 100; i++) {
if (i % 3 == 0) {
printf("%d\n", i);
}
}
求余还可以用于位数分离上,比如对 1234 进行位数分离:
int a = 1234;
int ones, tens, hunds, thous;
thous = a / 1000;
hunds = a / 100 % 10;
tens = a / 10 % 10;
ones = a % 10;
- ++ 与 --:
意思就是自加,自减。容易混淆的是前++/–和后++/–:
- 当++ 和 – 自己独自构成表达式时,前后时没有区别的;
- 当构成的表达式参与了其他表达式的构成与运算时:1.后++,先使用,去构成表达式或计算 ,完结以后,自增1。2.前++,就先完成自增1,再构成表达式。
这里有一个例子:
int a = 5;
int b = 10;
printf("%d\n",a+++b);
这里的结果时15,所以时 a++ + b。然而原理和优先级没有关系,而问题在编译原理上,叫做“ 大嘴 ”:在翻译文本时,编译器发现a+, 认为其时一个加法运算符,于是继续读取下一个,发现上一个+后面不是操作数,于是把两个+就合在了一起,然后参与下一个表达式运算。
9.3.3 关系运算符与关系表达式
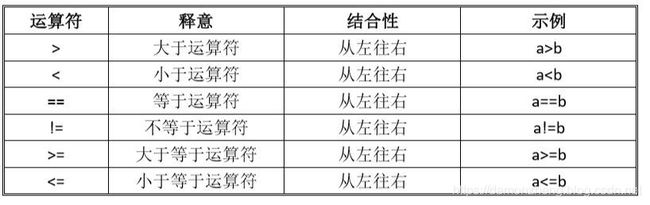
这个应该掌握起来还好,就不做太多说明。主要就是,正如上面所说的,任何表达式都是有值的,那么关系表达式也不例外。关系表达式无非就是说明一种关系成立或是不成立,那么这个表达式的值就是运算结果,成立就是 1, 不成立就是 0.
需要注意的是以下情况:
int a = 5; int b = 6;
if (a = b) {
//若一个人手滑把 == 写成了 =;
printf("a == b\n");
}else{
printf("a != b\n");
}
若是一个人手滑把 == 写成了 =, 那么这个还是能编译通过,且输出打印 a == b; 原因是因为,条件语句时,只要条件表达式不为 0, 那么就判定为真。之前我们也讨论过,赋值运算符将右边的值赋值给左边,赋值表达式的值等于赋值运算符左边的值。所以 a = b 这个表达式的值就是 6, 所以判断为真。
9.3.4 逻辑运算符
以下是逻辑运算符的列表

逻辑运算符的解析如下表:
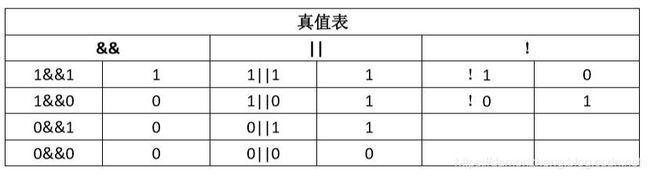
以以下示例为例:
if(5 && 3){
printf("xxxx\n");
}else{
printf("oooo\n");
}
共分为以下步骤:
- 将&&两边的操作数逻辑化,非0为真, 0 为假;
- 因为 5 为非0, 3 为非0 , 所以整个表达式为真,打印 xxxx;
有一点需要注意的式,!运算的优先级要比 &&,|| 要高。
一般来说当我们求输出0-100所有能被3整除的数时,我们会这样写:
for (int i = 0; i <= 100; i++) {
if (i % 3 == 0) {
printf("%d 可以被 3 整除\n",i);
}
}
现在我们就可以这样写:
for (int i = 0; i <= 100; i++) {
if (!(i % 3)) {
printf("%d 可以被 3 整除\n", i);
}
}
接下来还有一个现象需要探讨,就是短路现象:和物理电学里的短路类似,就是由于电阻原因,电流只走一边走了。代码里一样,实列如下:
int a = 4; int b = 5;
if ((a > 5) || (b = 6)) {
printf("b = %d\n", b);
}
else {
printf(" b = %d\n", b);
}
当判断 a > 5 时,判断为假,于是继续逻辑化 b = 5,所以这是 b 被赋予了新值。当我们把 a > 5 改成 a < 5 时,判断为真, 由于是 || 运算, 所以一边为真,既是为真, 所以将不会再继续逻辑化 b = 6, 所以 b 并没有被赋予新值。由此可见,短路现象的本质其实就是一种效率的提升。
9.3.5 条件运算符与条件表达式

条件运算符也是因为简介的需要所诞生的。本质就是 if…else 的形式。若问好前的表达式为真,那么整个表达式的值就是 : 右边的值;若为假,整个表达式的值则是问好右边的值:
int a;
a = 5 > 4 ? 1 :0 ;
printf("a 的值是 %d\n", a);
此时得输出为:
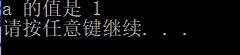
注意,条件运算符的结合性,运算起来是从右往左运算的:
int result;
int a = 4; int b = 5; int c = 6; int d = 7;
result = a > b ? a : b > c ? c : d;
printf("result 的值是 %d\n", result);

但是在实际测试时,发现C可能对条件运算符也有运用短路现象来优化条件运算的情况:
int a = 10, b = 2;
int c = 3, d = 4;
5 > 3 ? a : ++c ? 1 : 2;
printf("%d\n", c);
此时输出为:

此时c变量并没有进行自加运算,但是当我们把5 > 3改写成 5 < 3 时, 输出为:
![]()
由此可见,当条件成立时,只会计算第一个表达式,当条件不成立时,只会运算第二个表达式。
顺序求值运算符(逗号运算符)

逗号运算符的优先级非常低,甚至低于赋值运算符。当一个表达式中只存在逗号运算符时,整个表达式的值等于最后一个逗号右边的值:
int result = (1 + 1, 2 + 2, 3 + 3, 4 + 4, 5 + 5);
printf("result 的值是 %d\n", result);
![]()
第9章小结
优先级中,算术 > 关系 > 逻辑, 不过逻辑中有一个不服气,那就是非 !,跟非一样的,还有一个sizeof。sizeof是一个关键字,并不是函数。还有一个规律就是,单目 > 双目 > 三目,不过也是有一些例外的。平时我们加括号 sizeof( char ) 只是为了一个区分优先级的作用。在逻辑运算表达式中,程序会先将逻辑运算符两边的操作数逻辑化,再进行逻辑运算。
第八章 函数
- 可以提高程序的开发效率
- 提高了代码的重用性
- 使程序变得更加简洁而清新
- 有利于程序维护
库就是对函数的在一次升级,将多个有用的函数打包到一起,变成了库。
8.1 C标准库及其库函数
8.1.1 库存在的意义是什么
库存在的意义就是为了防止重复造轮子。重复现成的,可用的,已经证实很好用的东西就是造轮子。
8.1.2 如何收使用库函数
我们用到那个函数,就需要包含那个函数的头文件。
函数一般包含三要素,函数名,函数参数,函数返回值。