13.2 Question Answering 问答系统意境级讲解
文章目录
- 一、QA1 匹配+抽取式问题
-
- 1、数据集
- 2、问题对文章的注意力 Query-to-context Attention
-
- 第一版
- 第二版
- VQA
-
- 单跳模型中的词引导空间注意
- 两跳模型中的空间注意
- 3、文章对问题的注意力 Context-to-query Attention
-
- R-Net
- Fusion Network
- 4、双向注意力
-
- BiDAF
- DCN
- QANET
- BERT
- 二、QA2 复杂的推理问题
-
- 1、Qangaroo 数据集
- 2、 Hoppot QA 数据集
- 3、DROP 数据集
- 方法
-
- 多跳匹配
-
- ReasoNet
- DFGN
- 多跳问答需要图结构吗?
-
- 图结构可能不是必须的
- 三、QA3 对话问答
-
- 数据集
-
- CoQA
- QuAC
- 办法
-
- FLOWQA
- BERT History Selection
- 参考
上半部分: 13.1Question Answering 问答系统意境级讲解_炫云云-CSDN博客
将学习更为复杂、各式各样的QA中Question问题的部分。
我们将会学习到三种由简及难的问题类型及其对应解法:
第一类:匹配+抽取式问题
第二类:复杂的推理问题
第三类:对话问答
一、QA1 匹配+抽取式问题
1、数据集

图 1 图 1 图1
在此,如图 1,举一个SQuAD中标准的示例,在机器读取文章后,根据问题中比较重要的词汇对文章进行匹配,即相同的词汇在文章和问题中均出现了,找出其出现段落。再在段落中进行答案的抽取。
那像这样的简单匹配抽取式问题该怎么用神经网络去做呢?
2、问题对文章的注意力 Query-to-context Attention
第一版

图 2 图 2 图2
一个经典的做法就是使用问题到文章的Attention机制,具体做法如上图,首先,预处理文章Knowledge source得到每个token的词向量表示,问题部分如法炮制,将问题浓缩成一个向量。接下来,实现匹配就用Attention,其实在此做Attention就是相当于将问题的向量与文章中每个token的词向量做相似度计算,也就是匹配。然后,将每一个Attention得到的权重参数与对应token相乘求和,也就是抽取,得到代表答案的一个向量。
Attention的计算:
5.1注意力机制 Attention is all you need
注意的是,这里加权求和不是用的蓝色计算attention的向量,而是用绿色的向量,这个向量也是蓝色模型抽取出来的另外一组vector。加权求和得到的结果再丢到answer模块中进行计算。如果是bAbI那种任务就是用classifier进行分类,如果是SQuAD则用predict来预测答案对应的时间步。

图 3 图 3 图3
具体模型有:End-to-end Memory Network这个模型的思路和上面讲的大概相同,橙色对应上面的绿色向量用来求和,蓝色对应上面的蓝色向量用来求权重,最后做的bAbI任务,所以是分类。
End-to-end Memory Network请看: 5.10 Memory Networks 记忆网络的应用与方法
第二版

图 4 图 4 图4
第二版将question分成多个vector,每一个vector都和source的embedding做attention,上图有三个question的vector,所以attention计算得到三组权重,然后求三组权重每个位置上的max,然后进行后面的操作。
模型VQA1,用了这个思想。
VQA

图 5 图 5 图5
注意看这里的question变成表征后有多个vector。图片经过CNN切割成多个小区域,然后也是分两组向量,分别计算权重和求和。
假设question抽取后有T个向量,然后做attention操作得到T组向量( C 1 . . . C T C_1...C_T C1...CT ),然后做max操作,然后进行分类计算。
首先概述了所提出的SMemVQA网络,如图5(a)所示。
网络的输入是一个由长度可变的问题序列和大小固定的图像组成的问题。
问题中的每个单词首先被表示为一个one-hot 向量。然后,每个one-hot 向量被嵌入到一个实数词向量中, V = { v j ∣ v j ∈ R N ; j = 1 , ⋯ , T } V=\left\{v_{j} \mid v_{j} \in \mathbb{R}^{N} ; j=1, \cdots, T\right\} V={ vj∣vj∈RN;j=1,⋯,T},其中 T T T为问题中的最大字数, N N N为嵌入空间的维数。长度小于 T T T的句子用特殊的 − 1 -1 −1值填充,嵌入到全零词向量中。
问题中的单词被用来计算视觉记忆的注意力,其中包含提取的图像特征。通过CNN对输入图像进行处理,提取空间位置网格上的高水平 M M M维度视觉特征。具体来说,我们用 S = { s i ∣ s i ∈ S=\left\{s_{i} \mid s_{i} \in\right. S={ si∣si∈ R M ; i = 1 , ⋯ , L } \left.\mathbb{R}^{M} ; i=1, \cdots, L\right\} RM;i=1,⋯,L} 来表示每个网格位置的空间CNN特征。本文使用GoogLeNet最后一层卷积层的空间特征输出作为图像的视觉特征。
每个位置的图像特征向量与词向量一起嵌入到一个共同的语义空间中。使用了两种不同的嵌入方法:注意嵌入 W A W_A WA和视觉论点嵌入 W E W_E WE。注意嵌入投射每个视觉特征向量,使其与问题词嵌入相结合产生该图像空间的注意权重。视觉论点嵌入检测问题中语义概念或对象的存在,并将嵌入结果与注意权重相乘,对所有位置求和,生成视觉论点向量 S a t t S_{att} Satt。
最后,将视觉论点向量与问题表示相结合,用于预测给定图像和问题的答案。
单跳模型中的词引导空间注意
第一跳的注意结构(图 5b)使用每个词向量分别提取记忆中相关的视觉特征,让每个单词选择一个相关区域可能会提供更细粒度的注意。单词向量 V V V和视觉特征 S S S之间的关联矩阵 C ∈ R T × L C \in \mathbb{R}^{T \times L} C∈RT×L中计算为
C = V ⋅ ( S ⋅ W A + b A ) T C=V \cdot\left(S \cdot W_{A}+b_{A}\right)^{T} C=V⋅(S⋅WA+bA)T
其中 W A ∈ R M N W_{A} \in \mathbb{R}^{M \ N} WA∈RM N中包含视觉特征 S S S的注意嵌入权值, b A ∈ R L N b_{A} \in \mathbb{R}^{L \ N} bA∈RL N中是偏项。该关联矩阵是每个单词嵌入和每个空间位置的视觉特征点积的结果,因此关联矩阵 C C C中的每个值度量了每个单词和每个空间的视觉特征之间的相似性。
空间注意权值 W a t t W_{a tt} Watt的计算方法是对相关矩阵 C C C取单词维度 T T T上的最大值,对每个空间位置选择最高的相关值,然后应用softmax函数
W a t t = softmax ( max i = 1 , ⋯ , T ( C i ) ) , C i ∈ R L W_{a t t}=\operatorname{softmax}\left(\max _{i=1, \cdots, T}\left(C_{i}\right)\right), C_{i} \in \mathbb{R}^{L} Watt=softmax(i=1,⋯,Tmax(Ci)),Ci∈RL
此时注意力权重 W a t t ∈ R L W_{a t t} \in \mathbb{R}^{L} Watt∈RL 对于问题所指的位置是高的,而对于其他地点是低的,权重之和等于1。例如,在图 5中所示的例子中,“篮子里有猫吗?”这个问题为篮子的位置产生了很高的注意力权重,因为篮子的词向量与该位置的视觉特征高度相关。论点嵌入 W E W_{E} WE投射了视觉特征 S S S,对某些语义概念产生高激活。例如,在图5中,它在包含猫的区域有高激活。然后将论点嵌入的结果乘以生成的注意权重 W a t t W_{a tt} Watt,求和得到选择的视觉“论点”向量 S a t t ∈ R N S_{a t t} \in \mathbb{R}^{N} Satt∈RN,
S a t t = W a t t ⋅ ( S ⋅ W E + b E ) S_{a t t}=W_{a t t} \cdot\left(S \cdot W_{E}+b_{E}\right) Satt=Watt⋅(S⋅WE+bE)
在图5中,这一步将在篮子位置积累猫的存在特征。
最后,利用该论点向量 S a t t S_{a t t} Satt 和问题嵌入 Q Q Q的总和来预测给定图像和问题的答案。对于问题表示 Q Q Q,选择词袋(BOW)。其他问题表示形式,如LSTM,也可以使用,但是,BOW的参数较少,但表现出了良好的性能。
Q = W Q ⋅ V + b Q Q=W_{Q} \cdot V+b_{Q} Q=WQ⋅V+bQ
其中 W Q ∈ R T W_{Q} \in \mathbb{R}^{T} WQ∈RT 表示单词向量 V V V的BOW权重 , b Q ∈ R N b_{Q} \in \mathbb{R}^{N} bQ∈RN 是偏置项。最后的预测 P P P是
P = softmax ( W P ⋅ f ( S a t t + Q ) + b P ) P=\operatorname{softmax}\left(W_{P} \cdot f\left(S_{a t t}+Q\right)+b_{P}\right) P=softmax(WP⋅f(Satt+Q)+bP)
其中 W P ∈ R K × N W_{P} \in \mathbb{R}^{K \times N} WP∈RK×N, b P ∈ R K b_{P} \in \mathbb{R}^{K} bP∈RK是偏置项。 K K K表示可能的预测答案个数。 f f f是激活函数。
在图5中,此步骤将在篮子位置附近为cat收集的论点添加到问题中,并且,由于没有找到猫,因此预测答案为“否”。在预测最终答案之前,注意力和论点计算步骤可以在另一跳中选择性地重复。
两跳模型中的空间注意
利用重复跳来促进更深的推断,在每一跳收集额外的论点。回想一下,将视觉论点向量 S a t t S_{a t t} Satt添加到第一个跳的问题表示 Q Q Q中,生成一个更新的问题向量。
O h o p 1 = S a t t + Q O_{h o p 1}=S_{a t t}+Q Ohop1=Satt+Q
在下一跳中,使用向量 O h o p 1 ∈ R N O_{h o p 1} \in \mathbb{R}^{N} Ohop1∈RN中替换单个单词向量 V V V,从记忆中提取与整个问题相关的额外视觉特征,并更新视觉论点。
第一跳的相关矩阵 C C C从问题中的每个词向量 V V V中提供细粒度的局部论点,而下一跳的相关向量 C h o p 2 C_{h op 2} Chop2从整个问题表示 Q Q Q中考虑全局论点。
相关向量 C hop 2 ∈ R L C_{\text {hop } 2} \in \mathbb{R}^{L} Chop 2∈RL :
C hop 2 = ( S ⋅ W E + b E ) ⋅ O hop 1 C_{\text {hop } 2}=\left(S \cdot W_{E}+b_{E}\right) \cdot O_{\text {hop } 1} Chop 2=(S⋅WE+bE)⋅Ohop 1
W E ∈ R M × N W_{E} \in \mathbb{R}^{M \times N} WE∈RM×N 是视觉特征 S S S的注意嵌入权重.与第一跳的论点嵌入权值共享.
空间注意权值 W a t t W_{a tt} Watt
W a t t 2 = softmax ( C hop 2 ) W_{a t t 2}=\operatorname{softmax}\left(C_{\text {hop } 2}\right) Watt2=softmax(Chop 2)
然后,第二跳中相关的视觉信息 S a t t 2 ∈ R N S_{a t t 2} \in \mathbb{R}^{N} Satt2∈RN:
S a t t 2 = W a t t 2 ⋅ ( S ⋅ W E 2 + b E 2 ) S_{a t t 2}=W_{a t t 2} \cdot\left(S \cdot W_{E_{2}}+b_{E_{2}}\right) Satt2=Watt2⋅(S⋅WE2+bE2)
3、文章对问题的注意力 Context-to-query Attention
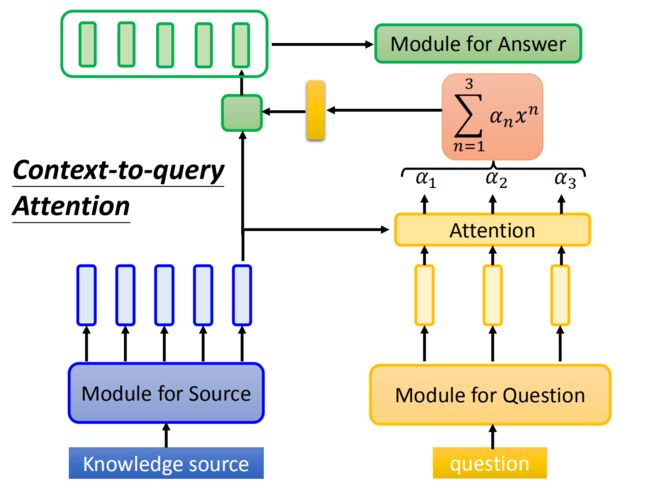
图 6 图 6 图6
当然,这两种方法都是问题去对文章做Attention,其实也可以反过来,用文章对问题做Attention。一样的计算方式,得到相乘累加的结果,如上图的黄色向量,再通过这个向量与文章token的词向量做某种方式的计算,在文献上有两者相加、点乘、拼接等等得到绿色的向量。最终,通过每一个文章的词向量得到的绿色向量序列得到最终的答案,典型的模型有R-Net、Fusion Network。
R-Net
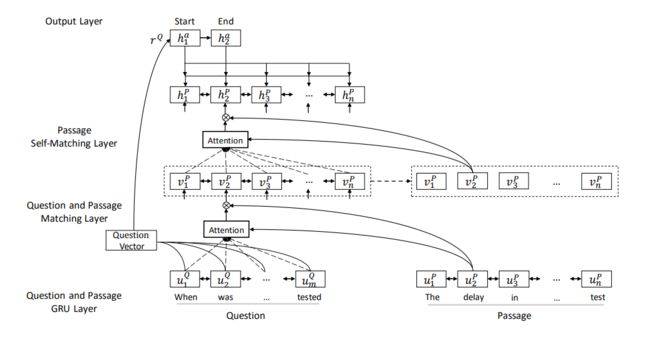
图 7 图 7 图7
图7给出了网络的结构2。
- 首先,采用BiRNN网络分别对问题和文章进行处理,得到 u 1 Q , … , u m Q u_{1}^{Q}, \ldots, u_{m}^{Q} u1Q,…,umQ 和 u 1 P , … , u n P u_{1}^{P}, \ldots, u_{n}^{P} u1P,…,unP,即
u t Q = BiRNN Q ( u t − 1 Q , [ e t Q , c t Q ] ) u t P = BiRNN P ( u t − 1 P , [ e t P , c t P ] ) \begin{aligned} u_{t}^{Q} &=\operatorname{BiRNN}_{Q}\left(u_{t-1}^{Q},\left[e_{t}^{Q}, c_{t}^{Q}\right]\right) \\ u_{t}^{P} &=\operatorname{BiRNN}_{P}\left(u_{t-1}^{P},\left[e_{t}^{P}, c_{t}^{P}\right]\right) \end{aligned} utQutP=BiRNNQ(ut−1Q,[etQ,ctQ])=BiRNNP(ut−1P,[etP,ctP])
e t Q , c t Q e_{t}^{Q}, c_{t}^{Q} etQ,ctQ 分别是词嵌入和字符嵌入。
- 然后,将问题和文章与基于注意力的门控循环网络进行匹配,得到文章的问题注意力表征 { v t P } t = 1 n \left\{v_{t}^{P}\right\}_{t=1}^{n} { vtP}t=1n。
v t P = RNN ( v t − 1 P , [ u t P , c t ] ) v_{t}^{P}=\operatorname{RNN}\left(v_{t-1}^{P},\left[u_{t}^{P}, c_{t}\right]\right) vtP=RNN(vt−1P,[utP,ct])
c t = att ( u Q , [ u t P , v t − 1 P ] ) c_{t}=\operatorname{att}\left(u^{Q},\left[u_{t}^{P}, v_{t-1}^{P}\right]\right) ct=att(uQ,[utP,vt−1P]) 是通过对 ( u Q ) \left(u^{Q}\right) (uQ) 计算的上下文向量:
s j t = v T tanh ( W u Q u j Q + W u P u t P + W v P v t − 1 P ) a i t = exp ( s i t ) / Σ j = 1 m exp ( s j t ) c t = Σ i = 1 m a i t u i Q \begin{array}{c} s_{j}^{t}=\mathrm{v}^{\mathrm{T}} \tanh \left(W_{u}^{Q} u_{j}^{Q}+W_{u}^{P} u_{t}^{P}+W_{v}^{P} v_{t-1}^{P}\right) \\ a_{i}^{t}=\exp \left(s_{i}^{t}\right) / \Sigma_{j=1}^{m} \exp \left(s_{j}^{t}\right) \\ c_{t}=\Sigma_{i=1}^{m} a_{i}^{t} u_{i}^{Q} \end{array} sjt=vTtanh(WuQujQ+WuPutP+WvPvt−1P)ait=exp(sit)/Σj=1mexp(sjt)ct=Σi=1maituiQ
每个问题注意力表征 v t P v_{t}^{P} vtP动态地合并了来自整个问题的聚合匹配信息。
为了确定文章那部分的重要性并关注与问题相关的部分,在输入 ( ∣ u t P , c t ∣ ) \left(\left|u_{t}^{P}, c_{t}\right|\right) (∣∣utP,ct∣∣) 中添加了另一个RNN门 :
g t = sigmoid ( W g [ u t P , c t ] ) [ u t P , c t ] ∗ = g t ⊙ [ u t P , c t ] \begin{array}{c} g_{t}=\operatorname{sigmoid}\left(W_{g}\left[u_{t}^{P}, c_{t}\right]\right) \\ {\left[u_{t}^{P}, c_{t}\right]^{*}=g_{t} \odot\left[u_{t}^{P}, c_{t}\right]} \end{array} gt=sigmoid(Wg[utP,ct])[utP,ct]∗=gt⊙[utP,ct]
[ u t P , c t ] ∗ \left[u_{t}^{P}, c_{t}\right]^{*} [utP,ct]∗ 代替 [ u t P , c t ] \left[u_{t}^{P}, c_{t}\right] [utP,ct].
- 在此基础上,将自注意力应用于从整个段落中收集论点并细化段落表示,然后将其输入输出层以预测答案跨度的边界.
它动态地从整个篇章中提取论点,并将与当前篇章词与问题信息相关的论点编码到篇章表征 h t P h_{t}^{P} htP中
h t P = BiRNN ( h t − 1 P , [ v t P , c t ] ) h_{t}^{P}=\operatorname{BiRNN}\left(h_{t-1}^{P},\left[v_{t}^{P}, c_{t}\right]\right) htP=BiRNN(ht−1P,[vtP,ct])
c t = att ( v P , v t P ) c_{t}=\operatorname{att}\left(v^{P}, v_{t}^{P}\right) ct=att(vP,vtP) 是通过 ( v P ) \left(v^{P}\right) (vP) 计算的上下文向量:
s j t = v T tanh ( W v P v j P + W v P ~ v t P ) a i t = exp ( s i t ) / Σ j = 1 n exp ( s j t ) c t = Σ i = 1 n a i t v i P \begin{array}{c} s_{j}^{t}=\mathrm{v}^{\mathrm{T}} \tanh \left(W_{v}^{P} v_{j}^{P}+W_{v}^{\tilde{P}} v_{t}^{P}\right) \\ a_{i}^{t}=\exp \left(s_{i}^{t}\right) / \Sigma_{j=1}^{n} \exp \left(s_{j}^{t}\right) \\ c_{t}=\Sigma_{i=1}^{n} a_{i}^{t} v_{i}^{P} \end{array} sjt=vTtanh(WvPvjP+WvP~vtP)ait=exp(sit)/Σj=1nexp(sjt)ct=Σi=1naitviP
[ v t P , c t ] \left[v_{t}^{P}, c_{t}\right] [vtP,ct] 也使用上面的门产出 [ u t P , c t ] ∗ \left[u_{t}^{P}, c_{t}\right]^{*} [utP,ct]∗
使用指针网络预测答案的开始和结束位置。
s j t = v T tanh ( W h P h j P + W h a h t − 1 a ) a i t = exp ( s i t ) / Σ j = 1 n exp ( s j t ) p t = arg max ( a 1 t , … , a n t ) \begin{array}{c} s_{j}^{t}=\mathrm{v}^{\mathrm{T}} \tanh \left(W_{h}^{P} h_{j}^{P}+W_{\mathrm{h}}^{a} h_{t-1}^{a}\right) \\ a_{i}^{t}=\exp \left(s_{i}^{t}\right) / \Sigma_{j=1}^{n} \exp \left(s_{j}^{t}\right) \\ p^{t}=\arg \max \left(a_{1}^{t}, \ldots, a_{n}^{t}\right) \end{array} sjt=vTtanh(WhPhjP+Whaht−1a)ait=exp(sit)/Σj=1nexp(sjt)pt=argmax(a1t,…,ant)
这里 h t − 1 a h_{t-1}^{a} ht−1a表示指针网络的最后一个隐藏状态。指针网络的输入是基于当前预测概率 a t a^{t} at的上下文向量
c t = Σ i = 1 n a i t h i P h t a = RNN ( h t − 1 a , c t ) \begin{array}{c} c_{t}=\Sigma_{i=1}^{n} a_{i}^{t} h_{i}^{P} \\ h_{t}^{a}=\operatorname{RNN}\left(h_{t-1}^{a}, c_{t}\right) \end{array} ct=Σi=1naithiPhta=RNN(ht−1a,ct)
此外,在问题表征上使用上下文向量来生成指针网络的初始隐藏向量。当预测开始位置时 , h t − 1 a h_{t-1}^{a} ht−1a表示指针网络初始隐藏状态。利用问题向量 r Q r^{Q} rQ作为指针网络的初始状态。 r Q = att ( u Q , V r Q ) r^{Q}=\operatorname{att}\left(u^{Q}, V_{r}^{Q}\right) rQ=att(uQ,VrQ)是一个基于参数 V r Q V_{r}^{Q} VrQ的上下文向量:
s j = v T tanh ( W u Q u j Q + W v Q V r Q ) a i = exp ( s i ) / Σ j = 1 m exp ( s j ) r Q = Σ i = 1 m a i u i Q \begin{array}{c} s_{j}=\mathrm{v}^{\mathrm{T}} \tanh \left(W_{u}^{Q} u_{j}^{Q}+W_{\mathrm{v}}^{Q} V_{r}^{Q}\right) \\ a_{i}=\exp \left(s_{i}\right) / \Sigma_{j=1}^{m} \exp \left(s_{j}\right) \\ r^{Q}=\Sigma_{i=1}^{m} a_{i} u_{i}^{Q} \end{array} sj=vTtanh(WuQujQ+WvQVrQ)ai=exp(si)/Σj=1mexp(sj)rQ=Σi=1maiuiQ
为了训练网络,通过预测的分布来最小化真实起始位置和结束位置的负对数概率之和。
Fusion Network
一种端到端架构:全感知融合网络(FusionNet)3。给定文本A和B, FusionNet将文本 B \mathrm{B} B中的信息融合到文本 A \mathrm{A} A中,并生成两组向量
U A = { u 1 A , … , u m A } , U B = { u 1 B , … , u n B } U_{A}=\left\{\boldsymbol{u}_{1}^{A}, \ldots, \boldsymbol{u}_{m}^{A}\right\}, \quad U_{B}=\left\{\boldsymbol{u}_{1}^{B}, \ldots, \boldsymbol{u}_{n}^{B}\right\} UA={ u1A,…,umA},UB={ u1B,…,unB}
下面,我们考虑文本 A \mathrm{A} A是context C \boldsymbol{C} C,文本 B \mathrm{B} B是question Q \boldsymbol{Q} Q的特殊情况。FusionNet的插图如图8所示。它由以下组件组成。

图 8 图 8 图8
- 输入向量。
首先,将 C C C和 Q Q Q中的每个单词转换为输入向量 w \boldsymbol{w} w。还包括12 -dim POS嵌入,8 -dim NER嵌入,以及上下文 C C C的标准化频率。
{ w 1 C , … , w m C } ⊂ R 900 + 20 + 1 , and { w 1 Q , … , w n Q } ⊂ R 900 \left\{\boldsymbol{w}_{1}^{C}, \ldots, \boldsymbol{w}_{m}^{C}\right\} \subset \mathbb{R}^{900+20+1} \text { , and }\left\{\boldsymbol{w}_{1}^{Q}, \ldots, \boldsymbol{w}_{n}^{Q}\right\} \subset \mathbb{R}^{900} { w1C,…,wmC}⊂R900+20+1 , and { w1Q,…,wnQ}⊂R900
- 全感知多层次的融合:词级
在多级融合中,分别考虑了词级和更高层次的融合。词级融合告知 C C C Q Q Q中有哪些词。如图8中的箭头(1)所示。首先,为 C C C中的每个单词创建一个特征向量 e m i \mathrm{em}_{i} emi,以指示该单词是否出现在问题Q中。其次,使用基于注意的嵌入 g i \boldsymbol{g}_{i} gi融合
g ^ i C = ∑ j α i j g j Q , α i j ∝ exp ( S ( g i C , g j Q ) ) , S ( x , y ) = ReLU ( W x ) T ReLU ( W y ) \hat{\boldsymbol{g}}_{i}^{C}=\sum_{j} \alpha_{i j} \boldsymbol{g}_{j}^{Q}, \quad \alpha_{i j} \propto \exp \left(S\left(\boldsymbol{g}_{i}^{C}, \boldsymbol{g}_{j}^{Q}\right)\right), \quad S(\boldsymbol{x}, \boldsymbol{y})=\operatorname{ReLU}(W \boldsymbol{x})^{T} \operatorname{ReLU}(W \boldsymbol{y}) g^iC=j∑αijgjQ,αij∝exp(S(giC,gjQ)),S(x,y)=ReLU(Wx)TReLU(Wy)
W ∈ R 300 × 300 W \in \mathbb{R}^{300 \times 300} W∈R300×300. 因为单词的历史本身就是输入向量,所以全意识的注意在这里并不适用。上下文的增强输入向量是 w ~ i C = [ w i C ; e m i ; g ^ i C ] \tilde{\boldsymbol{w}}_{i}^{C}=\left[\boldsymbol{w}_{i}^{C} ; \mathrm{em}_{i} ; \hat{\boldsymbol{g}}_{i}^{C}\right] w~iC=[wiC;emi;g^iC].
-
Reading.
在读取器中,使用一个 BiLSTM来形成 C \boldsymbol{C} C和 Q \boldsymbol{Q} Q 的低级和高级概念为 h l , h h ∈ R 250 \boldsymbol{h}^{l}, \boldsymbol{h}^{h} \in \mathbb{R}^{250} hl,hh∈R250。
h 1 C l , … , h m C l = BiLSTM ( w ~ 1 C , … , w ~ m C ) , h 1 Q l , … , h n Q l = BiLSTM ( w 1 Q , … , w n Q ) h 1 C h , … , h m C h = BiLSTM ( h 1 C l , … , h m C l ) , h 1 Q h , … , h n Q h = BiLSTM ( h 1 Q l , … , h n Q l ) \begin{aligned} \boldsymbol{h}_{1}^{C l}, \ldots, \boldsymbol{h}_{m}^{C l} &=\operatorname{BiLSTM}\left(\tilde{\boldsymbol{w}}_{1}^{C}, \ldots, \tilde{\boldsymbol{w}}_{m}^{C}\right), \quad \boldsymbol{h}_{1}^{Q l}, \ldots, \boldsymbol{h}_{n}^{Q l}=\operatorname{BiLSTM}\left(\boldsymbol{w}_{1}^{Q}, \ldots, \boldsymbol{w}_{n}^{Q}\right) \\ \boldsymbol{h}_{1}^{C h}, \ldots, \boldsymbol{h}_{m}^{C h} &=\operatorname{BiLSTM}\left(\boldsymbol{h}_{1}^{C l}, \ldots, \boldsymbol{h}_{m}^{C l}\right), \quad \boldsymbol{h}_{1}^{Q h}, \ldots, \boldsymbol{h}_{n}^{Q h}=\operatorname{BiLSTM}\left(\boldsymbol{h}_{1}^{Q l}, \ldots, \boldsymbol{h}_{n}^{Q l}\right) \end{aligned} h1Cl,…,hmClh1Ch,…,hmCh=BiLSTM(w~1C,…,w~mC),h1Ql,…,hnQl=BiLSTM(w1Q,…,wnQ)=BiLSTM(h1Cl,…,hmCl),h1Qh,…,hnQh=BiLSTM(h1Ql,…,hnQl)
- Question Understanding.
在问题理解中,应用了一个新的BiLSTM,包含了 h Q l , h Q h \boldsymbol{h}^{Q l}, \boldsymbol{h}^{Q h} hQl,hQh,以获得最终的问题表征 U Q U_{Q} UQ:
U Q = { u 1 Q , … , u n Q } = BiLSTM ( [ h 1 Q l ; h 1 Q h ] , … , [ h n Q l ; h n Q h ] ) U_{Q}=\left\{\boldsymbol{u}_{1}^{Q}, \ldots, \boldsymbol{u}_{n}^{Q}\right\}=\operatorname{BiLSTM}\left(\left[\boldsymbol{h}_{1}^{Q l} ; \boldsymbol{h}_{1}^{Q h}\right], \ldots,\left[\boldsymbol{h}_{n}^{Q l} ; \boldsymbol{h}_{n}^{Q h}\right]\right) UQ={ u1Q,…,unQ}=BiLSTM([h1Ql;h1Qh],…,[hnQl;hnQh])
其中 { u i Q ∈ R 250 } i = 1 n \left\{\boldsymbol{u}_{i}^{Q} \in \mathbb{R}^{250}\right\}_{i=1}^{n} { uiQ∈R250}i=1n 问题 Q \boldsymbol{Q} Q.的理解向量。
-
全感知多层次的融合:高级
通过对单词历史的充分关注,将问题 Q Q Q中的所有高级信息融合到上下文 C C C中。由于全感知注意评分函数被限制为对称的,需要为 C \boldsymbol{C} C和 Q \boldsymbol{Q} Q确定单词的共同历史
H o W i C = [ g i C ; c i C ; h i C l ; h i C h ] , H o W i Q = [ g i Q ; c i Q ; h i Q l ; h i Q h ] ∈ R 1400 \mathrm{HoW}_{i}^{C}=\left[\boldsymbol{g}_{i}^{C} ; \boldsymbol{c}_{i}^{C} ; \boldsymbol{h}_{i}^{C l} ; \boldsymbol{h}_{i}^{C h}\right], \mathrm{HoW}_{i}^{Q}=\left[\boldsymbol{g}_{i}^{Q} ; \boldsymbol{c}_{i}^{Q} ; \boldsymbol{h}_{i}^{Q l} ; \boldsymbol{h}_{i}^{Q h}\right] \in \mathbb{R}^{1400} HoWiC=[giC;ciC;hiCl;hiCh],HoWiQ=[giQ;ciQ;hiQl;hiQh]∈R1400
其中 g i \boldsymbol{g}_{i} gi是GloVe 嵌入, c i \boldsymbol{c}_{i} ci是CoVe嵌入。然后,通过全意识的注意力,融合从 Q Q Q到 C C C的低、高、和理解层次的信息。通过注意函数 S l ( x , y ) , S h ( x , y ) , S u ( x , y ) S^{l}(\boldsymbol{x}, \boldsymbol{y}), S^{h}(\boldsymbol{x}, \boldsymbol{y}), S^{u}(\boldsymbol{x}, \boldsymbol{y}) Sl(x,y),Sh(x,y),Su(x,y)计算不同组的注意权重,将低、高、理解概念结合起来。隐藏大小设置为 k = 250 k=250 k=250。
-
对词语历史的全感知注意力
当我们阅读上下文时,每个输入的单词都会逐渐转化为更抽象的表示,例如,从低级到高级的概念。总之,它们构成了我们脑海中每个单词的历史。对于人类来说,我们经常使用单词的历史,但我们往往忽视了它的重要性。
在神经结构中,将第 i i i 个单词 H o W i \mathrm{HoW}_{i} HoWi的历史定义为该单词生成的所有表示的连接。这可能包括单词嵌入,RNN中的多个中间和输出隐藏向量,以及在任何进一步的层中相应的表示向量。为了将单词的历史整合到广泛的神经模型中,使用全感知注意力。
使用注意力将信息从一个物体融合到另一个物体上。考虑文本 A \mathrm{A} A和 B \mathrm{B} B中的单词的两组隐藏向量: { h 1 A , … , h m A } , { h 1 B , … , h n B } ⊂ R d \left\{\boldsymbol{h}_{1}^{A}, \ldots, \boldsymbol{h}_{m}^{A}\right\},\left\{\boldsymbol{h}_{1}^{B}, \ldots, \boldsymbol{h}_{n}^{B}\right\} \subset \mathbb{R}^{d} { h1A,…,hmA},{ h1B,…,hnB}⊂Rd。它们的相关历史是,
{ H o W 1 A , … , H o W m A } , { H o W 1 B , … , H o W n B } ⊂ R d h \left\{\mathrm{HoW}_{1}^{A}, \ldots, \mathrm{HoW}_{m}^{A}\right\},\left\{\mathrm{HoW}_{1}^{B}, \ldots, \mathrm{HoW}_{n}^{B}\right\} \subset \mathbb{R}^{d_{h}} { HoW1A,…,HoWmA},{ HoW1B,…,HoWnB}⊂Rdh
d h ≫ d d_{h} \gg d dh≫d. 通过对 A中每一个 h i A \boldsymbol{h}_{i}^{A} hiA 使用注意力将B融入到A。- 计算注意力得分 S i j = S ( h i A , h j B ) ∈ R S_{i j}=S\left(\boldsymbol{h}_{i}^{A}, \boldsymbol{h}_{j}^{B}\right) \in \mathbb{R} Sij=S(hiA,hjB)∈R , 对于每一个 h j B \boldsymbol{h}_{j}^{B} hjB 在 B \mathrm{B} B 中。
- 形成注意力权重 α i j \alpha_{i j} αij : α i j = exp ( S i j ) / ∑ k exp ( S i k ) \alpha_{i j}=\exp \left(S_{i j}\right) / \sum_{k} \exp \left(S_{i k}\right) αij=exp(Sij)/∑kexp(Sik).
- 将 h i A \boldsymbol{h}_{i}^{A} hiA与汇总信息连接起来, h ^ i A = ∑ j α i j h j B \hat{\boldsymbol{h}}_{i}^{A}=\sum_{j} \alpha_{i j} \boldsymbol{h}_{j}^{B} h^iA=∑jαijhjB.
在全感知注意中,用单词的历史来代替注意力分数的计算。
S ( h i A , h j B ) ⟹ S ( H o W i A , H o W j B ) S\left(\boldsymbol{h}_{i}^{A}, \boldsymbol{h}_{j}^{B}\right) \Longrightarrow S\left(\mathrm{HoW}_{i}^{A}, \mathrm{HoW}_{j}^{B}\right) S(hiA,hjB)⟹S(HoWiA,HoWjB)
这会完全意识到对每个单词的完全理解。为了充分利用注意中的单词历史,需要一个适当的注意评分函数 S ( x , y ) S(\boldsymbol{x}, \boldsymbol{y}) S(x,y)。一个常用的函数是乘法注意
S i j = ( H o W i A ) T U T V ( H o W j B ) S_{i j}=\left(\mathrm{HoW}_{i}^{A}\right)^{T} U^{T} V\left(\mathrm{HoW}_{j}^{B}\right) Sij=(HoWiA)TUTV(HoWjB)
其中 U , V ∈ R k × d h U, V \in \mathbb{R}^{k \times d_{h}} U,V∈Rk×dh,和 k k k是注意力隐藏的大小。然而,怀疑两个大的矩阵直接交互会使神经模型更难训练。因此,约束矩阵 U T V U^{T} V UTV为对称的,可以分解成 U T D U U^{T} D U UTDU,因此
S i j = ( H o W i A ) T U T D U ( H o W j B ) S_{i j}=\left(\mathrm{HoW}_{i}^{A}\right)^{T} U^{T} D U\left(\mathrm{HoW}_{j}^{B}\right) Sij=(HoWiA)TUTDU(HoWjB)
其中 U ∈ R k × d h , D ∈ R k × k U \in \mathbb{R}^{k \times d_{h}}, D \in \mathbb{R}^{k \times k} U∈Rk×dh,D∈Rk×k 和 D D D是一个对角矩阵。对称形式保留了在不同的 H o W i A , H o W j B \mathrm{HoW}_{i}^{A}, \mathrm{HoW}_{j}^{B} HoWiA,HoWjB之间给予高注意力分数的能力。此外,将非线性与对称形式结合在一起,从而在单词历史的不同部分之间提供更丰富的交互。注意力得分的最终公式是
S i j = f ( U ( H o W i A ) ) T D f ( U ( H o W j B ) ) S_{i j}=f\left(U\left(\mathrm{HoW}_{i}^{A}\right)\right)^{T} D f\left(U\left(\mathrm{HoW}_{j}^{B}\right)\right) Sij=f(U(HoWiA))TDf(U(HoWjB))
f ( x ) = max ( 0 , x ) . f(x)=\max (0, x) . f(x)=max(0,x).
- 低级融合: h ^ i C l = ∑ j α i j l h j Q l , α i j l ∝ exp ( S l ( H o W i C , H o W j Q ) ) \hat{\boldsymbol{h}}_{i}^{C l}=\sum_{j} \alpha_{i j}^{l} \boldsymbol{h}_{j}^{Q l}, \quad \alpha_{i j}^{l} \propto \exp \left(S^{l}\left(\mathrm{HoW}_{i}^{C}, \mathrm{HoW}_{j}^{Q}\right)\right) h^iCl=∑jαijlhjQl,αijl∝exp(Sl(HoWiC,HoWjQ)).
- 高级融合: h ^ i C h = ∑ j α i j h h j Q h , α i j h ∝ exp ( S h ( H o W i C , H o W j Q ) ) \hat{\boldsymbol{h}}_{i}^{C h}=\sum_{j} \alpha_{i j}^{h} \boldsymbol{h}_{j}^{Q h}, \quad \alpha_{i j}^{h} \propto \exp \left(S^{h}\left(\mathrm{HoW}_{i}^{C}, \mathrm{HoW}_{j}^{Q}\right)\right) h^iCh=∑jαijhhjQh,αijh∝exp(Sh(HoWiC,HoWjQ)).
- 理解级融合: u ^ i C = ∑ j α i j u u j Q , α i j u ∝ exp ( S u ( H o W i C , H o W j Q ) ) \hat{\boldsymbol{u}}_{i}^{C}=\sum_{j} \alpha_{i j}^{u} \boldsymbol{u}_{j}^{Q}, \quad \alpha_{i j}^{u} \propto \exp \left(S^{u}\left(\mathrm{HoW}_{i}^{C}, \mathrm{HoW}_{j}^{Q}\right)\right) u^iC=∑jαijuujQ,αiju∝exp(Su(HoWiC,HoWjQ)).
这种多层次的注意力机制在考虑所有层次信息的同时,独立捕获不同层次的信息。应用一种新的BiLSTM得到完全融合 Q Q Q中信息的 C C C表征:
{ v 1 C , … , v m C } = BiLSTM ( [ h 1 C l ; h 1 C h ; h ^ 1 C l ; h ^ 1 C h ; u ^ 1 C ] , … , [ h m C l ; h m C h ; h ^ m C l ; h ^ m C h ; u ^ m C ] ) \left\{\boldsymbol{v}_{1}^{C}, \ldots, \boldsymbol{v}_{m}^{C}\right\}=\operatorname{BiLSTM}\left(\left[\boldsymbol{h}_{1}^{C l} ; \boldsymbol{h}_{1}^{C h} ; \hat{\boldsymbol{h}}_{1}^{C l} ; \hat{\boldsymbol{h}}_{1}^{C h} ; \hat{\boldsymbol{u}}_{1}^{C}\right], \ldots,\left[\boldsymbol{h}_{m}^{C l} ; \boldsymbol{h}_{m}^{C h} ; \hat{\boldsymbol{h}}_{m}^{C l} ; \hat{\boldsymbol{h}}_{m}^{C h} ; \hat{\boldsymbol{u}}_{m}^{C}\right]\right) { v1C,…,vmC}=BiLSTM([h1Cl;h1Ch;h^1Cl;h^1Ch;u^1C],…,[hmCl;hmCh;h^mCl;h^mCh;u^mC])
- Fully-Aware Self-Boosted Fusion
现在使用自增强融合来考虑环境中的遥远部分,如图8中的箭头(3)所示。再一次,通过对文字历史的充分关注来实现这一点。确定了单词的历史
H o W i C = [ g i C ; c i C ; h i C l ; h i C h ; h ^ i C l ; h ^ i C h ; u ^ i C ; v i C ] ∈ R 2400 \mathrm{HoW}_{i}^{C}=\left[\boldsymbol{g}_{i}^{C} ; \boldsymbol{c}_{i}^{C} ; \boldsymbol{h}_{i}^{C l} ; \boldsymbol{h}_{i}^{C h} ; \hat{\boldsymbol{h}}_{i}^{\mathrm{Cl}} ; \hat{\boldsymbol{h}}_{i}^{\mathrm{Ch}} ; \hat{\boldsymbol{u}}_{i}^{C} ; \boldsymbol{v}_{i}^{C}\right] \in \mathbb{R}^{2400} HoWiC=[giC;ciC;hiCl;hiCh;h^iCl;h^iCh;u^iC;viC]∈R2400
然后我们进行全意识的注意, v ^ i C = ∑ j α i j s v j C , α i j s ∝ exp ( S s ( H o W i C , H o W j C ) ) \hat{\boldsymbol{v}}_{i}^{C}=\sum_{j} \alpha_{i j}^{s} \boldsymbol{v}_{j}^{C}, \alpha_{i j}^{s} \propto \exp \left(S^{s}\left(\mathrm{HoW}_{i}^{C}, \mathrm{HoW}_{j}^{C}\right)\right) v^iC=∑jαijsvjC,αijs∝exp(Ss(HoWiC,HoWjC)).
最终的上下文表示:
U C = { u 1 C , … , u m C } = BiLSTM ( [ v 1 C ; v ^ 1 C ] , … , [ v m C ; v ^ m C ] ) U_{C}=\left\{\boldsymbol{u}_{1}^{C}, \ldots, \boldsymbol{u}_{m}^{C}\right\}=\operatorname{BiLSTM}\left(\left[\boldsymbol{v}_{1}^{C} ; \hat{\boldsymbol{v}}_{1}^{C}\right], \ldots,\left[\boldsymbol{v}_{m}^{C} ; \hat{\boldsymbol{v}}_{m}^{C}\right]\right) UC={ u1C,…,umC}=BiLSTM([v1C;v^1C],…,[vmC;v^mC])
{ u i C ∈ R 250 } i = 1 m \left\{\boldsymbol{u}_{i}^{C} \in \mathbb{R}^{250}\right\}_{i=1}^{m} { uiC∈R250}i=1m 是 C \boldsymbol{C} C.理解向量
在FusionNet的这些组件之后,创建了理解向量 U C U_{C} UC,用于上下文 C C C,它与问题 Q Q Q完全融合。对于 Q Q Q问题,也有向量 U Q U_{Q} UQ。
机器理解
SQuAD 的答案总是上下文中的一个跨度。FusionNet的输出是两者的理解向量
C and Q , U C = { u 1 C , … , u m C } , U Q = { u 1 Q , … , u n Q } \boldsymbol{C} \text { and } \boldsymbol{Q}, U_{C}=\left\{\boldsymbol{u}_{1}^{C}, \ldots, \boldsymbol{u}_{m}^{C}\right\}, U_{Q}=\left\{\boldsymbol{u}_{1}^{Q}, \ldots, \boldsymbol{u}_{n}^{Q}\right\} C and Q,UC={ u1C,…,umC},UQ={ u1Q,…,unQ}
然后使用它们来查找上下文中的答案span。首先,通过 u Q = ∑ i β i u i Q \boldsymbol{u}^{Q}=\sum_{i} \beta_{i} \boldsymbol{u}_{i}^{Q} uQ=∑iβiuiQ,得到单个概括的问题理解向量,其中 β i ∝ exp ( w T u i Q ) \beta_{i} \propto \exp \left(\boldsymbol{w}^{T} \boldsymbol{u}_{i}^{Q}\right) βi∝exp(wTuiQ)和 w \boldsymbol{w} w是可训练向量。然后用总结问题理解向量 u Q \boldsymbol{u}^{Q} uQ,
P i S ∝ exp ( ( u Q ) T W S u i C ) P_{i}^{S} \propto \exp \left(\left(\boldsymbol{u}^{Q}\right)^{T} W_{S} \boldsymbol{u}_{i}^{C}\right) PiS∝exp((uQ)TWSuiC)
其中 W S ∈ R d × d W_{S} \in \mathbb{R}^{d \times d} WS∈Rd×d 是一个可训练矩阵. 为了在跨度结束时使用跨度开始的信息, 通过GRU将跨度开始的上下文理解向量与 u Q \boldsymbol{u}^{Q} uQ结合起来
v Q = GRU ( u Q , ∑ i P i S u i C ) \boldsymbol{v}^{Q}=\operatorname{GRU}\left(\boldsymbol{u}^{Q}, \sum_{i} P_{i}^{S} \boldsymbol{u}_{i}^{C}\right) vQ=GRU(uQ,i∑PiSuiC)
其中 u Q \boldsymbol{u}^{Q} uQ 作为记忆和 ∑ i P i S u i C \sum_{i} P_{i}^{S} \boldsymbol{u}_{i}^{C} ∑iPiSuiC 作为输入,最后,使用 v Q \boldsymbol{v}^{Q} vQ得到结束位置
P i E ∝ exp ( ( v Q ) T W E u i C ) P_{i}^{E} \propto \exp \left(\left(\boldsymbol{v}^{Q}\right)^{T} W_{E} \boldsymbol{u}_{i}^{C}\right) PiE∝exp((vQ)TWEuiC)
在训练过程中,我们最大限度地提高真实跨度的对数概率
∑ k ( log ( P i k s S ) + log ( P i k e E ) ) \sum_{k}\left(\log \left(P_{i_{k}^{s}}^{S}\right)+\log \left(P_{i_{k}^{e}}^{E}\right)\right) k∑(log(PiksS)+log(PikeE))
i k s , i k e i_{k}^{s}, i_{k}^{e} iks,ike是 k k k -th实例的答案span。
预测在约束条件 0 ≤ i e − i s ≤ 15 0 \leq i^{e}-i^{s} \leq 15 0≤ie−is≤15下,答案跨度 i s , i e i^{s}, i^{e} is,ie是最大的 P i s S P i e E P_{i^{s}}^{S} P_{i^{e}}^{E} PisSPieE
4、双向注意力
既然上面提到question和passage可以相互做attention,于是把这两种方法结合起来就变成了一个新模型,代表模型有BIDAF,DCN,QANET。
BiDAF
双向注意流(BIDAF)4网络,这是一个分层的多阶段体系结构(图 9)。BIDAF网络包括字符级、单词级和文章嵌入。并使用双向注意流获得查询感知上下文表征。该注意机制对以前流行的注意进行改进。
- 首先,注意层没有将上下文段落融合成一个固定大小的向量。相反,每个时间步的注意力都被计算出来,并且每个时间步的注意向量,以及来自前一层的表征,都被允许流向后续的建模层。这减少了早期融合造成的信息损失。
- 第二,使用无记忆注意机制。通过时间迭代计算注意,但每个时间步长的注意仅是当前时间步长的查询和上下文段落的函数,并不直接依赖于前一个时间步长的注意。这种简化导致了注意层和建模层之间的劳动分工。它迫使注意层集中于学习查询和文章之间的注意力,并使建模层集中于学习上下文表征(注意层的输出)。它还允许每个时间步骤的注意力不受前一个时间步骤不正确的影响。
- 第三,在查询到文章和文章到查询两个方向上都使用注意机制,相互提供互补的信息。

图 9 图 9 图9
图9中,机器理解模型由六层组成
-
Character Embedding Layer
字符转为随机初始化的向量 ,作为CNN的一维输入,使用最大池化,为每个单词获得一个固定大小的向量,其维度为CNN的输入通道的数目。
-
Word Embedding Layer
预训练模型提供
字符和单词嵌入向量的连接被传递到双层 Highway Network,输出是两个 d d d维矩阵:用于上下文 X ∈ R d × T \mathbf{X} \in \mathbb{R}^{d \times T} X∈Rd×T和用于查询 Q ∈ R d × J \mathbf{Q} \in \mathbb{R}^{d \times J} Q∈Rd×J。
-
Contextual Embedding Layer.
使用BiLSTM学习单词之间的交互信息。因此,从词向量 X \mathbf{X} X中获得 H ∈ R 2 d × T \mathbf{H} \in \mathbb{R}^{2 d \times T} H∈R2d×T,并从查询词向量 Q \mathbf{Q} Q中获得 U ∈ R 2 d × J \mathbf{U} \in \mathbb{R}^{2 d \times J} U∈R2d×J。注意, H \mathbf{H} H和 U \mathbf{U} U的每个列向量都是$ 2d $ 维。
值得注意的是,该模型的前三层是不同粒度的查询和文章的计算特征,类似于计算机视觉领域中CNN的多阶段特征计算。
-
Attention Flow Layer.
该层输入是文章 H \mathbf{H} H和查询 U \mathbf{U} U的向量表示。该层的输出是文章词的查询感知向量表示 G {\mathbf{G}} G。
在这一层中,从两个方向计算注意:从文章到查询以及从查询到文章。
首先计算一个共享相似度矩阵 S ∈ R T × J \mathbf{S} \in \mathbb{R}^{T \times J} S∈RT×J。其中 S t j \mathbf{S}_{t j} Stj表示第 t t t 个文章词和第 j j j 个查询词之间的相似性。相似度矩阵由
S t j = α ( H : t , U : j ) ∈ R \mathbf{S}_{t j}=\alpha\left(\mathbf{H}_{: t}, \mathbf{U}_{: j}\right) \in \mathbb{R} Stj=α(H:t,U:j)∈R
α \alpha α 是可训练的标量函数, H : t \mathbf{H}_{: t} H:t是 H \mathbf{H} H的第 t t t 列向量, U : j \mathbf{U}_{: j} U:j是 U \mathbf{U} U的第 j j j 列向量,其中
α ( h , u ) = w ( S ) ⊤ [ h ; u ; h ⊙ u ] \alpha(\mathbf{h}, \mathbf{u})=\mathbf{w}_{(\mathbf{S})}^{\top}[\mathbf{h} ; \mathbf{u} ; \mathbf{h} \odot \mathbf{u}] α(h,u)=w(S)⊤[h;u;h⊙u]w ( S ) ∈ R 6 d \mathbf{w}_{(\mathbf{S})} \in \mathbb{R}^{6 d} w(S)∈R6d 是参数, ⊙ \odot ⊙ 意味着元素乘法。 [ ; ] [;] [;] 跨行向量串联。现在使用 S \mathbf{S} S来获得两个方向上的注意和注意上下文向量。
-
Context-to-query Attention. 图9中绿色模块
C2Q 对于文章词,计算查询词的权重 ,即查询词重要程度的加权和。让 a t ∈ R J \mathbf{a}_{t} \in \mathbb{R}^{J} at∈RJ 表示查询词上 对第 t t t 个文章词的注意权值,
a t = softmax ( S t : ) ∈ R J \mathbf{a}_{t}=\operatorname{softmax}\left(\mathbf{S}_{t:}\right) \in\mathbb{R}^{J} at=softmax(St:)∈RJ
然后每个参与的查询向量是 U ~ : t = ∑ j a t j U : j . \tilde{\mathbf{U}}_{: t}=\sum_{j} \mathbf{a}_{t j} \mathbf{U}_{: j} . U~:t=∑jatjU:j.因此 U ~ \tilde{\mathbf{U}} U~是包含整个文章参与的$ 2d $ 查询向量。 -
Query-to-context Attention. 图9中橙色模块
Q2C 注意表示与查询相关的文章中最重要单词的加权和,因此对回答查询至关重要。
获得对文章词的注意权重
b = softmax ( max c o l ( S ) ) ∈ R T \mathbf{b}=\operatorname{softmax}\left(\max _{c o l}(\mathbf{S})\right) \in \mathbb{R}^{T} b=softmax(colmax(S))∈RT
其中最大函数 ( max c o l ) \left(\max _{c ol}\right) (maxcol)跨列执行。那么注意上下文向量为
h ~ = ∑ t b t H : t ∈ R 2 d \tilde{\mathbf{h}}=\sum_{t} \mathbf{b}_{t} \mathbf{H}_{: t} \in \mathbb{R}^{2 d} h~=t∑btH:t∈R2d
h ~ \tilde{\mathrm{h}} h~在列中平铺 T T T次,从而给出 H ~ ∈ R 2 d × T \tilde{\mathbf{H}} \in \mathbb{R}^{2 d \times T} H~∈R2d×T。最后,将文章嵌入和上下文向量组合在一起生成 G \mathbf{G} G,其中每个列向量可以被认为是每个文章词的查询感知表征。定义了 G \mathbf{G} G
G : t = β ( H : t , U ~ : t , H ~ : t ) ∈ R d G \mathbf{G}_{: t}=\boldsymbol{\beta}\left(\mathbf{H}_{: t}, \tilde{\mathbf{U}}_{: t}, \tilde{\mathbf{H}}_{: t}\right) \in \mathbb{R}^{d_{\mathbf{G}}} G:t=β(H:t,U~:t,H~:t)∈RdG
β \boldsymbol{\beta} β是一个可训练的向量函数,它融合了它的(三个)输入向量, d G d_{\mathbf{G}} dG是 β \boldsymbol{\beta} β函数的输出维数 (i.e., d G = 8 d ). \text { (i.e., } d_{\mathbf{G}}=8 d \text { ). } (i.e., dG=8d ). 。虽然 β \boldsymbol{\beta} β函数可以是任意可训练的神经网络,如多层感知器,也可以是
β ( h , u ~ , h ~ ) = [ h ; u ~ ; h ∘ u ~ ] \boldsymbol{\beta}(\mathbf{h}, \tilde{\mathbf{u}}, \tilde{\mathbf{h}})=[\mathbf{h} ; \tilde{\mathbf{u}} ; \mathbf{h} \circ \tilde{\mathbf{u}}] β(h,u~,h~)=[h;u~;h∘u~]
-
-
Modeling Layer.
建模层的输入是 G \mathbf{G} G,它对文章单词的查询感知表示进行了编码。建模层的输出捕获以查询为条件的文章词之间的交互。
使用两层双向LSTM,每个方向的输出大小为 d d d。因此,得到了一个矩阵 M ∈ R 2 d × T \mathbf{M} \in \mathbb{R}^{2 d \times T} M∈R2d×T中,它被传递到输出层来预测答案。 M \mathbf{M} M的每个列向量期望包含关于单词的关于整个文章段落和查询的上下文信息。
-
Output Layer.
输出层是特定于任务的。这里,描述QA任务的输出层。
QA任务要求模型找到段落的子短语来回答查询。这个短语是通过预测该短语在段落中的开始和结束索引而衍生出来的。计算开始索引在整个段落的概率分布
p 1 = softmax ( w ( p 1 ) ⊤ [ G ; M ] ) \mathbf{p}^{1}=\operatorname{softmax}\left(\mathbf{w}_{\left(\mathbf{p}^{1}\right)}^{\top}[\mathbf{G} ; \mathbf{M}]\right) p1=softmax(w(p1)⊤[G;M])
其中 w ( p 1 ) ∈ R 10 d \mathbf{w}_{\left(\mathbf{p}^{1}\right)} \in \mathbb{R}^{10 d} w(p1)∈R10d中是一个可训练权向量。对于答案短语的结束索引,将 M \mathbf{M} M传递到另一个双向LSTM层,并获得 M 2 ∈ R 2 d × T \mathbf{M}^{2} \in \mathbb{R}^{2 d \times T} M2∈R2d×T。然后,使用 M 2 \mathbf{M}^{2} M2以类似的方式获得结束索引的概率分布:
p 2 = softmax ( w ( p 2 ) ⊤ [ G ; M 2 ] ) \mathbf{p}^{2}=\operatorname{softmax}\left(\mathbf{w}_{\left(\mathbf{p}^{2}\right)}^{\top}\left[\mathbf{G} ; \mathbf{M}^{2}\right]\right) p2=softmax(w(p2)⊤[G;M2])- Training.
将训练损失(最小化)定义为真实开始和结束指数的负对数概率和预测分布,在所有的例子中平均:
L ( θ ) = − 1 N ∑ i N log ( p y i 1 1 ) + log ( p y i 2 2 ) L(\theta)=-\frac{1}{N} \sum_{i}^{N} \log \left(\mathbf{p}_{y_{i}^{1}}^{1}\right)+\log \left(\mathbf{p}_{y_{i}^{2}}^{2}\right) L(θ)=−N1i∑Nlog(pyi11)+log(pyi22)
θ \theta θ 是模型中所有可训练权值的集合, N N N是数据集中的示例数, y i 1 y_{i}^{1} yi1和 y i 2 y_{i}^{2} yi2分别是第 i i i 个示例的真正起始索引和结束索引, p k \mathbf{p}_{k} pk表示向量 p \mathbf{p} p的第 k k k 个值。- Test.
答案跨度 ( k , l ) (k, l) (k,l),其中 k ≤ l k \leq l k≤l的最大值为 p k 1 p l 2 \mathbf{p}_{k}^{1} \mathbf{p}_{l}^{2} pk1pl2,可以用动态规划在线性时间内计算。
DCN
DCN5是动态共同注意网络
图 10展示了DCN的结构。我们首先描述了文档和问题的编码器,然后是共同注意机制和产生答案跨度的动态解码器。

图 10 图 10 图10
-
文档和问题的编码器
( x 1 Q , x 2 Q , … , x n Q ) \left(x_{1}^{Q}, x_{2}^{Q}, \ldots, x_{n}^{Q}\right) (x1Q,x2Q,…,xnQ) 为问题单词序列, ( x 1 D , x 2 D , … , x m D ) \left(x_{1}^{D}, x_{2}^{D}, \ldots, x_{m}^{D}\right) (x1D,x2D,…,xmD) 为文档单词序列。使用LSTM编码:
d t = LSTM enc ( d t − 1 , x t D ) q t = LSTM enc ( q t − 1 , x t Q ) . d_{t}=\operatorname{LSTM}_{\text {enc }}\left(d_{t-1}, x_{t}^{D}\right)\\ q_{t}=\operatorname{LSTM}_{\text {enc }}\left(q_{t-1}, x_{t}^{Q}\right) . dt=LSTMenc (dt−1,xtD)qt=LSTMenc (qt−1,xtQ).
得到文档编码矩阵 D = [ d 1 … d m d ∅ ] ∈ R ℓ × ( m + 1 ) D=\left[d_{1} \ldots d_{m} d_{\varnothing}\right] \in \mathbb{R}^{\ell \times(m+1)} D=[d1…dmd∅]∈Rℓ×(m+1),还添加了一个哨兵向量 d ∅ d_{\varnothing} d∅,它允许模型不关注输入中的任何特定单词。得到问题编码矩阵 Q ′ = [ q 1 … q n q ∅ ] ∈ R ℓ × ( n + 1 ) Q^{\prime}=\left[\begin{array}{lll}q_{1} & \ldots & q_{n} & q_{\varnothing}\end{array}\right] \in \mathbb{R}^{\ell \times(n+1)} Q′=[q1…qnq∅]∈Rℓ×(n+1),还添加了一个哨兵向量 q ∅ q_{\varnothing} q∅.为了使得问题编码空间和文档编码空间之间不一样,在问题编码之上引入一个非线性投影层。
Q = tanh ( W ( Q ) Q ′ + b ( Q ) ) ∈ R ℓ × ( n + 1 ) Q=\tanh \left(W^{(Q)} Q^{\prime}+b^{(Q)}\right) \in \mathbb{R}^{\ell \times(n+1)} Q=tanh(W(Q)Q′+b(Q))∈Rℓ×(n+1) -
共同注意机制

图 11 图11 图11
一种同时关注问题和文档的共同注意机制,并最终融合两种注意语境。图11提供了共同注意机制的说明。
首先计算相似度矩阵,其中包含所有文档词对和问题词对的相似度得分:
L = D ⊤ Q ∈ R ( m + 1 ) × ( n + 1 ) L=D^{\top} Q \in \mathbb{R}^{(m+1) \times(n+1)} L=D⊤Q∈R(m+1)×(n+1)
相似度矩阵按行标准化,为问题中的每个单词在整个文档中产生 A Q A^{Q} AQ的注意权重;按列标准化,为文档中的每个单词在问题中产生 A D A^{D} AD的注意权重:
A Q = softmax ( L ) ∈ R ( m + 1 ) × ( n + 1 ) A D = softmax ( L ⊤ ) ∈ R ( n + 1 ) × ( m + 1 ) A^{Q}=\operatorname{softmax}(L) \in \mathbb{R}^{(m+1) \times(n+1)} \\ A^{D}=\operatorname{softmax}\left(L^{\top}\right) \in \mathbb{R}^{(n+1) \times(m+1)} AQ=softmax(L)∈R(m+1)×(n+1)AD=softmax(L⊤)∈R(n+1)×(m+1)
接下来,根据问题的每个单词计算文档的总结或注意上下文向量。
C Q = D A Q ∈ R ℓ × ( n + 1 ) C^{Q}=D A^{Q} \in \mathbb{R}^{\ell \times(n+1)} CQ=DAQ∈Rℓ×(n+1)
类似地, 根据文档中的每个单词计算问题的总结 Q A D Q A^{D} QAD。
根据文档的每个单词计算前一个注意上下文的总结 C Q A D C^{Q} A^{D} CQAD。这两种操作可以并行进行,如下式所示。对 C Q A D C^{Q} A^{D} CQAD运算的一种可能的解释是将问题编码映射到文档编码空间。
C D = [ Q ; C Q ] A D ∈ R 2 ℓ × ( m + 1 ) C^{D}=\left[Q ; C^{Q}\right] A^{D} \in \mathbb{R}^{2 \ell \times(m+1)} CD=[Q;CQ]AD∈R2ℓ×(m+1)
定义 C D C^{D} CD,一个问题和文档的相互依赖的表征,作为共同注意上下文。使用符号 [ a ; b ] [a ; b] [a;b]用于水平连接向量 a a a和 b b b。
最后一步是通过双向LSTM将时间序列信息融合到共同注意语境中:
u t = B i LSTM ( u t − 1 , u t + 1 , [ d t ; c t D ] ) ∈ R 2 ℓ u_{t}=\mathrm{Bi}\operatorname{LSTM}\left(u_{t-1}, u_{t+1},\left[d_{t} ; c_{t}^{D}\right]\right) \in \mathbb{R}^{2 \ell} ut=BiLSTM(ut−1,ut+1,[dt;ctD])∈R2ℓ
定义 U = [ u 1 , … , u m ] ∈ R 2 ℓ × m U=\left[u_{1}, \ldots, u_{m}\right] \in \mathbb{R}^{2 \ell \times m} U=[u1,…,um]∈R2ℓ×m,这为选择哪个区间可能是最好的答案提供了基础,作为共同注意编码。
-
动态指针解码器
由于SQuAD的性质,生成答案跨度的方法是通过预测跨度的起点和终点。但是,给定一个问题-文档对,文档中可能存在几个直观的答案区间,每个区间对应一个局部最大值。使用一种迭代技术,通过预测起点和预测终点来交替选择一个答案跨度。这种迭代过程允许模型从初始的局部极大值中恢复到对应于不正确的答案区间。
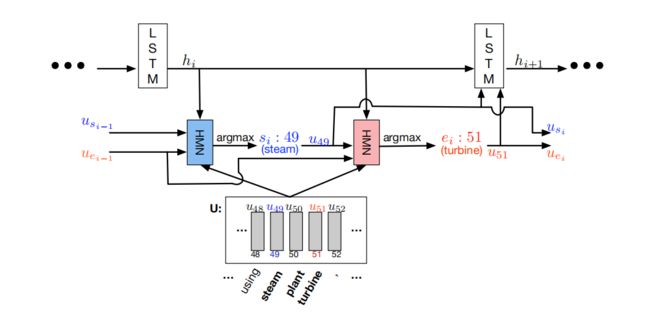
图 12 图 12 图12图12展示了Dynamic Decoder,其状态由lstm产生。在每次迭代中,解码器根据与当前起始和结束位置估计相对应的共同注意编码更新其状态,并通过多层神经网络产生新的起始和结束位置。
设 h i , s i h_{i}, s_{i} hi,si和 e i e_{i} ei分别表示LSTM的隐藏状态、起始位置估计和第 i i i步 结束位置的估计。LSTM状态更新:
h i = LSTM d e c ( h i − 1 , [ u s i − 1 ; u e i − 1 ] ) h_{i}=\operatorname{LSTM}_{d e c}\left(h_{i-1},\left[u_{s_{i-1}} ; u_{e_{i-1}}\right]\right) hi=LSTMdec(hi−1,[usi−1;uei−1])
其中 u s i − 1 u_{s_{i}-1} usi−1和 u e i − 1 u_{e_{i-1}} uei−1是先前共同注意编码 U U U的起始和结束位置的估计。已知当前隐藏状态 h i h_{i} hi、之前的起始位置 u s i − 1 u_{s_{i-1}} usi−1和之前的结束位置 u e i − 1 u_{e_{i-1}} uei−1,估计当前的起始位置和结束位置。
s i = argmax t ( α 1 , … , α m ) e i = argmax t ( β 1 , … , β m ) \begin{array}{l} s_{i}=\underset{t}{\operatorname{argmax}}\left(\alpha_{1}, \ldots, \alpha_{m}\right) \\ e_{i}=\underset{t}{\operatorname{argmax}}\left(\beta_{1}, \ldots, \beta_{m}\right) \end{array} si=targmax(α1,…,αm)ei=targmax(β1,…,βm)
其中 α t \alpha_{t} αt和 β t \beta_{t} βt表示文档中第 t t t个单词对应的开始分数和结束分数。 用单独的神经网络计算 α t \alpha_{t} αt和 β t \beta_{t} βt。这些网络具有相同的架构,但不共享参数。使用 Highway Maxout Network (HMN)来计算 α t \alpha_{t} αt,使用这种模型背后的直觉是,QA任务由多种问题类型和文档主题组成。这些变化可能需要不同的模型来估计答案的跨度。Maxout提供了一种跨多个模型集中使用的方法。
α t = H M N start ( u t , h i , u s i − 1 , u e i − 1 ) \alpha_{t}=\mathrm{HMN}_{\text {start }}\left(u_{t}, h_{i}, u_{s_{i-1}}, u_{e_{i-1}}\right) αt=HMNstart (ut,hi,usi−1,uei−1)
这里, u t u_{t} ut是对应于文档中 t t t th单词的共同注意编码。HMN start _{\text {start}} start如图13所示。结束分数 β t \beta_{t} βt的计算方法类似于开始分数 α t \alpha_{t} αt,但是使用单独的HMN end _{\text {end}} end。

图 13 图13 图13
HMN 计算:
HMN ( u t , h i , u s i − 1 , u e i − 1 ) = max ( W ( 3 ) [ m t ( 1 ) ; m t ( 2 ) ] + b ( 3 ) ) r = tanh ( W ( D ) [ h i ; u s i − 1 ; u e i − 1 ] ) m t ( 1 ) = max ( W ( 1 ) [ u t ; r ] + b ( 1 ) ) m t ( 2 ) = max ( W ( 2 ) m t ( 1 ) + b ( 2 ) ) \begin{aligned} \operatorname{HMN}\left(u_{t}, h_{i}, u_{s_{i-1}}, u_{e_{i-1}}\right) &=\max \left(W^{(3)}\left[m_{t}^{(1)} ; m_{t}^{(2)}\right]+b^{(3)}\right) \\ r &=\tanh \left(W^{(D)}\left[h_{i} ; u_{s_{i-1}} ; u_{e_{i-1}}\right]\right) \\ m_{t}^{(1)} &=\max \left(W^{(1)}\left[u_{t} ; r\right]+b^{(1)}\right) \\ m_{t}^{(2)} &=\max \left(W^{(2)} m_{t}^{(1)}+b^{(2)}\right) \end{aligned} HMN(ut,hi,usi−1,uei−1)rmt(1)mt(2)=max(W(3)[mt(1);mt(2)]+b(3))=tanh(W(D)[hi;usi−1;uei−1])=max(W(1)[ut;r]+b(1))=max(W(2)mt(1)+b(2))
r ∈ r ℓ r \in \mathbb{r}^{\ell} r∈rℓ是带参数 W ( D ) ∈ R ℓ × 5 ℓ W^{(D)} \in \mathbb{R}^{\ell \times 5 \ell} W(D)∈Rℓ×5ℓ的当前状态的非线性投影, m t ( 1 ) m_{t}^{(1)} mt(1) 是第一个maxout 输出层的输出, m t ( 2 ) m_{t}^{(2)} mt(2) 是第二个maxout 输出层的输出, m t ( 1 ) m_{t}^{(1)} mt(1) , m t ( 2 ) m_{t}^{(2)} mt(2)
喂给最终maxout 输出层,其参数 W ( 3 ) ∈ R p × 1 × 2 ℓ W^{(3)} \in \mathbb{R}^{p \times 1 \times 2 \ell} W(3)∈Rp×1×2ℓ, b ( 3 ) ∈ R p b^{(3)} \in \mathbb{R}^{p} b(3)∈Rp 。 P是每个maxout层的池化大小。max运算计算张量的第一个维度上的最大值。图13,在第一个最大输出层和最后一个最大输出层之间有高速连接。
- 为了训练该网络,将所有迭代的起始点和结束点的累积softmax交叉熵最小化。当对起始位置的估计和对结束位置的估计都不再改变时,或者当达到最大迭代次数时,迭代过程停止。
QANET
模型包含五个主要组件6:一个嵌入层,一个嵌入编码器层,一个文章查询关注层,一个模型编码器层和一个输出层,如图 14所示。
与其他方法的主要区别如下:对于嵌入和编码器,只使用卷积和自注意机制,抛弃了大多数现有的rnn。
因此,模型要快得多,因为它可以并行处理输入标记。注意,卷积和自注意的组合,明显优于单独的自注意,会带来 F 1 {~F} 1 F1增益
卷积的使用还允许利用卷积网络中常见的正则化方法,如dropout。

图 14 图 14 图14
-
Input Embedding Layer.
将每个词 w w w的词嵌入和字符嵌入连接起来,得到每个词 w w w的嵌入 x w x_{w} xw。词嵌入在训练过程中是固定的,从 p 1 = 300 p_{1}=300 p1=300 GloVe 预训练初始化。所有词汇表外的单词都被映射到
< UNK >令牌。每个字符表示为维数 p 2 = 200 p_{2}=200 p2=200的可训练向量,
每个单词的长度要么被截断,要么被填充到 16. 16 . 16.取矩阵每一行的最大值来得到每个单词的固定大小的向量表示。
最后,这一层的给定单词 x x x的输出是连接 [ x w ; x c ] ∈ R p 1 + p 2 \left[x_{w} ; x_{c}\right] \in \mathbf{R}^{p_{1}+p_{2}} [xw;xc]∈Rp1+p2.其中 x w x_{w} xw和 x c x_{c} xc分别是 x x x的字符嵌入的卷积输出和单词嵌入的卷积输出。
采用了highway network。
-
Embedding Encoder Layer.
编码器层由以下基本构造块组成:
卷积层 × # + \times \#+ ×#+ self-attention 层+ 前馈层。如图14右上角所示
使用深度可分离卷积而不是传统的卷积,因为它的记忆效率更高,泛化效果更好。卷积核大小为7,数量 d = 128 d=128 d=128,如图14右边 block内的conv层数为4。
self-attention-layer,采用多头注意力机制: Transformer意境级讲解_炫云云
这些基本操作(conv/self-attention/ffn)都被放置在一个剩余块中,如图1右下方所示。
对于一个输入 x x x和一个给定的操作 f f f,输出为 f ( f( f( layernorm ( x ) ) + x (x))+x (x))+x,表示每个块从输入到输出有一个完整的标识路径,其中layernorm表示层归一化。
需要注意的是,这一层的输入是一个维度为 p 1 + p 2 = 500 p_{1}+p_{2}=500 p1+p2=500的向量,对于每个单词,这个向量通过一维卷积立即映射到 d = 128 d=128 d=128。这一层的输出也是一个维度 d = 128 d=128 d=128。
-
Context-Query Attention Layer.
使用 C C C和 Q Q Q来表示已编码的文章和查询。
首先计算文章与查询词之间的相似度,得到一个相似度矩阵 S ∈ R n × m S \in \mathbf{R}^{n \times m} S∈Rn×m。
然后通过应用softmax函数对 S S S的每一行进行归一化,得到一个矩阵 S ˉ \bar{S} Sˉ。然后文章到查询注意值被计算为 A = S ˉ ⋅ Q T ∈ R n × d A=\bar{S} \cdot Q^{T} \in \mathbf{R}^{n \times d} A=Sˉ⋅QT∈Rn×d。此处使用的相似函数为三线性函数:
f ( q , c ) = W 0 [ q , c , q ⊙ c ] f(q, c)=W_{0}[q, c, q \odot c] f(q,c)=W0[q,c,q⊙c]
还使用查询到文章注意,通过softmax函数计算 S S S的列归一化矩阵 S ˉ ‾ \overline{\bar{S}} Sˉ,查询到文章的注意值为
B = S ˉ ⋅ S ˉ ‾ T ⋅ C T B=\bar{S} \cdot \overline{\bar{S}}^{T} \cdot C^{T} B=Sˉ⋅