导致溢出_JDK的BUG导致的内存溢出!反正我是没想到还能有续集
BUG到底是怎么修复的?
上周《我的程序跑了60多小时,就为了让你看一眼JDK的BUG导致的内存泄漏》这篇文章发布后。
有好几个同学都来问了我一些相关的问题。
比如这样的:

写上篇文章的时候,我的侧重点主要在 ConcurrentLinkedQueue(下文统一缩写 CLQ)存在过一个可能会导致内存泄漏的 BUG ,这个 BUG 的来龙去脉是怎样的,以及怎么通过可视化工具让我们感受到这个 BUG 的存在。
其实对于 BUG 在源码里面具体是怎样体现的,以及修改之后为什么就不会内存泄漏了并没有进行详细的解读。
开始的想法是,告诉大家有这个事情,如果有兴趣的可以直接去调试分析一下。
但是有的同学反映调试也看不明白啊。一个方法,在断点处一脸懵逼的进来,又一脸懵逼的出去。

苦思冥想没搞清楚,然后就来问我。
我发现一两句话也说不太清楚,于是把 Debug 的关键截图放到文档里面配以文字说明,才勉强能说的比较清楚一点,也不知道这位同学看明白了没。
但就拿这个文档来说:真的是暖男石锤了。
所以,文本主要是分享一个我自己调试的奇淫技巧,最后再做个 remove 方法的解读。
但是如果要深刻理解 CLQ 这个十分优秀、十分有想法的基于非阻塞方法实现的线程安全的队列,大家需要去看的是 offer、poll 方法。然后一个情况一个情况的去分析,自己拿着草稿本在上面写写画画。
我也妄想过通过这篇文章给你们把它讲的明明白白的,后来我发现这对我而言难度有点大。
最后再说一下如果你用 IDEA 调试时,大概率会碰到的一个巨坑。
好了,先把之前的这个坑给填上。
修复之后的 JDK8 到底怎么就避免了内存泄漏的问题了?
自定义CLQ
我们先看一下 CLQ 的数据结构。
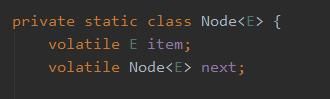
CLQ 的 Node 里面有一个 item(放的是存储的对象),还有一个 next 节点(指向的是当前 Node 的下一个节点)。
从数据结构来看,也知道这是一个单向链表了。
Java 程序员,就靠日志活着的。
所以我想通过日志的方式直接输出链表结构,这应该是最简单的演示方式了。
为了通过日志体现出数据变化的过程,我们先来一个自定义的 CLQ。
方法很简单,直接把 JDK 8 的 CLQ 复制出来一份,然后修改名称就可以,我们这里的名称是 whyConcurrentLinkedQueue(下文简写为 WhyCLQ):

搞一个测试用例跑一下:
然后你会发现报错了:
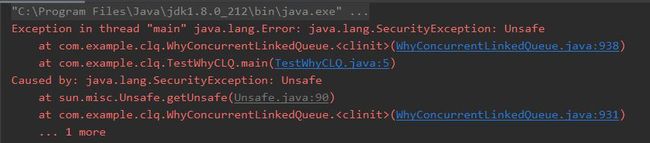
这个错误是关于 Unsafe 操作的,在代码的第 931 行:
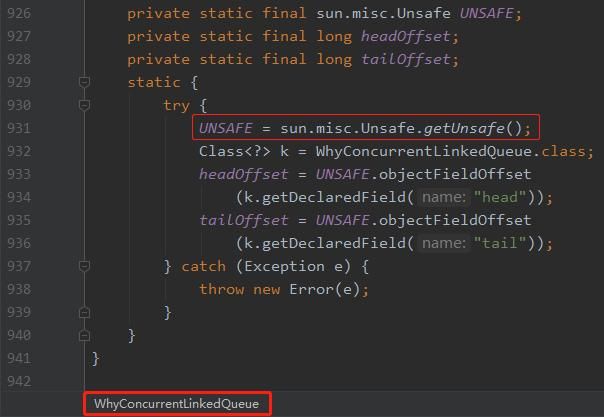
getUnsafe 方法的源码是这样的:
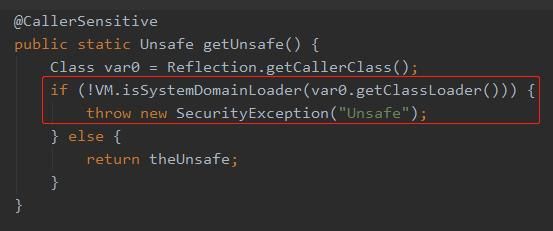
而这个方法里面就是判断当前类的类加载器是不是为 null:

这里抛出异常了,说明不是 null。也就会说当前类的加载器不是启动类加载器 BootstrapClassLoader。
我们知道,rt.jar 包下的类是需要 bootstrap 类加载器加载的。
诶,巧了。这个类就位于 rt.jar 包里面:
来,再复习一下双亲委派机制:

如果我们自定义了一个 CLQ ,那么这个类的类加载器是什么类加载器呢?
我们验证一下:

从 Debug 的截图可以看出当前类 WhyCLQ 的类加载器是 AppClassLoader。其父类加载器(parent)是 ExtClassLoader 类加载器。
不是 BootstrapClassLoader ,所以我们这里抛出了异常。
在介绍怎么解决这个异常之前,先简单的说一下 Unsafe。
这个类名称一听就是非常牛逼的。Unsafe,不安全。
感觉像是在钓鱼执法,表面上疯狂的在那给你摆手,说:别靠近我,别使用我,我很不安全。
实际上内心是这样的:
作为一个正常的男人,看到这个东西谁不想去调用一下,看看到底是怎么不安全的呢?
我们看一下《美团点评 2019 技术年货》里面是怎么描述的:

同时,看一下它相关的 API:

由于 Unsafe 不是文本重点,我就不展开说明了。如果你对 Unsafe 这个类掌握的还不深刻,建议你好好了解一下。如果你清楚的知道这个类的威力,在某些场景下可以达到意想不到的效果,它就是一枚银弹般的存在。
在《美团点评 2019 技术年货》里面有一小节是专门分享这个类的,有兴趣的朋友可以查看文末获取方式。
好了,知道抛出问题的原因了,我们自定义的 CLQ 就不能用了吗?
当然不是,别忘了,我们还有极其“流氓”的反射方法可以使用:

这样,我们自定义的 CLQ 就可以使用了。免费附赠你一个 Unsafe 的知识,不用谢。

接下来我们就可以在不修改源码逻辑的情况下,加入输出语句以方便调试。
比如我们需要这样清晰的输出日志:

所以在我们自定义的 CLQ 里面加一个打印链表结构的方法:
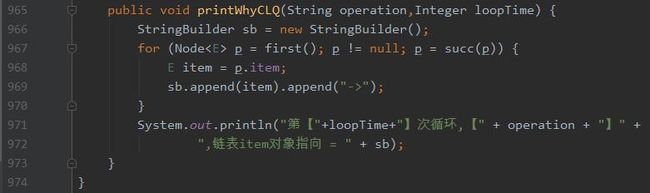
然后给我们的 remove 方法增加一个循环次数的入参,并在操作队列之前和之后调用我们打印链表结构的方法,就像下面这样式儿的:

其中的 printWhyCLQ 方法如下:
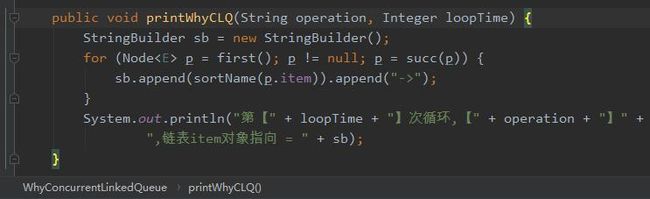
有的朋友肯定注意到了,我这个方法名称是 removeJDK8 。这个方法里面的逻辑就是 JDK8 的 CLQ 的 remove 方法。
你可以这么理解:我就是把 JDK8 的 CLQ 的 remove 方法的名称变成了 removeJDK8 。
为什么这样命名呢?
因为我要把 JDK7 对应的 remove 方法直接拿过来,放在同一个类里面方便调用,操作和上面的 JDK8 方法一致:

这样,我们就有一个自定义的 CLQ,里面包含 JDK7 和 JDK8 对应的 CLQ 的 remove 方法。
万事俱备,就差个 Demo 跑起来了:

在下面一小节中,我们对比一下修复前(JDK7)和修复后(JDK8)的输出日志,一切就会非常的明了。
修复前 vs 修复后
我们把 Demo 跑起来,看输出结果,进行对比:
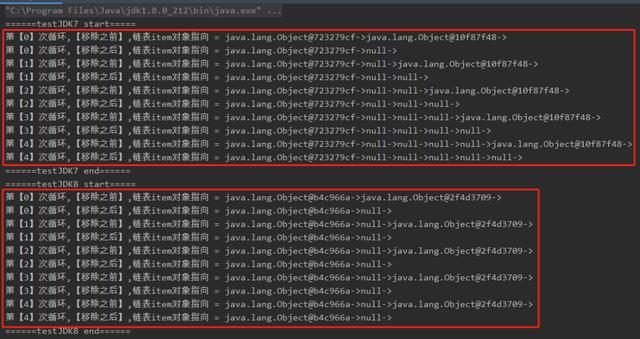
你仔细品这个输出结果,还需要我给你分析个啥玩意?

和 JDK8 的方法比起来,上面 JDK7 的方法执行完成后链表长度都长了一些。
JDK8 的方法执行完成后,链表长度最长也没有超过 3 个。
我们再看 JDK7,我拿一次循环出来分析:
这就是我上篇文章中说到的:一个节点中的 item 对象被置为 null 了,但是该节点,由于代码问题,并没有从链表中取下来,导致不能被回收。
而上篇文章中提到的“越来越慢”,由于可以直接的看到链表结构了,所以也很好解释了:

比如,我把 Demo 中 for 循环的次数修改为 100,运行之后,我们看最后一次循环的结果为:

remove 方法是从链表的头结点开始遍历链表,而我们每次需要移除的其实是最后一个节点,由于链表越来越长,所以遍历链表的时间越来越长。
所以导致我们上一篇的案例中每循环 10000 次,时间都会增加。

源码导读
接下来我们看一下 JDK8 的源码中的 remove(obj) 方法到底是怎么样工作的。
这个方法的目的就是从头结点开始遍历链表,然后判断每个 Node 里面的 item 是不是需要被删除的这个,如果是则删除,如果不是则继续遍历。
我想了很久这个地方怎么能把代码的执行流程说清楚呢?
除了 Debug 之外,因为 Debug 需要截非常多的图才可能说的清楚。
只有疯狂的输出日志了。
我们先看简单的分析一下 JDK8 对应的源码:
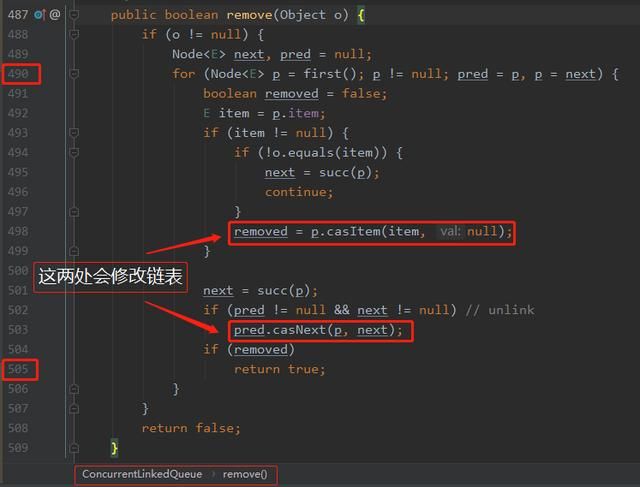
490 行是在对象被移除之前,我们可以在这里加一行输出语句打印当前的链表结构。
505 行是在对象被移除之后,我们可以在这里加一行输出语句打印删除操作完成之后的链表结构。
纵观整个方法,只有我标注的两个地方会去修改链表结构。所以,我们分别在这两处地方的前后输出相关日志,然后分析日志,就可以知道这个方法的工作流程了。
知道它的工作流程了,再返回去看代码,那还不是易如反掌的事儿?
这就是传说中的蛇皮走位,反向操作。

所以,按照我们上面的分析,在自定义的 CLQ 里面加入输出语句如下:
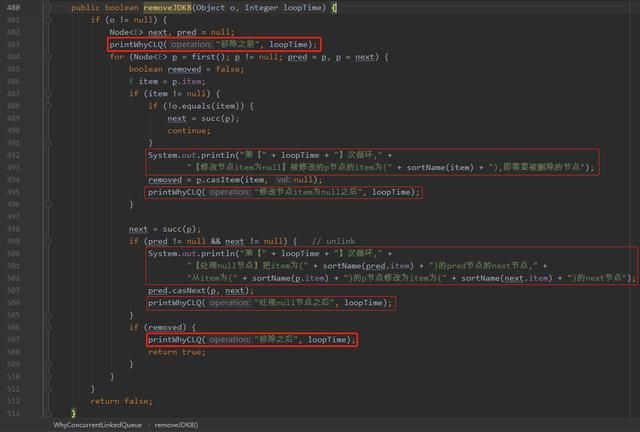
其中的 sortName 方法是为了把 java.lang.Object@xxx 截取为 @xxx,精简输出:
上面的 removeJDK8 方法除了输出语句之外,其他的代码逻辑和 JDK8 的对应方法一模一样。
我们还是用这个示例代码:

跑起来分析日志:

日志很多,但是细细分析下来流程非常的清晰,你可以在草稿本上画一画。
我带着大家分析前两个循环,一共 10 行日志,我们一行行的分析,注意我们下面画的图仅体现了 node 里面的 item 元素:

第【0】次循环,【移除之前】,链表item对象指向 = @723279cf->@10f87f48->
从测试代码中可以知道,被删除之前我们确实是有两个节点:

所以根据日志画图如下:

第【0】次循环,【修改节点item为null】被修改的p节点的item为(@10f87f48),即需要被删除的节点

第【0】次循环,【修改节点item为null之后】,链表item对象指向 = @723279cf->null->
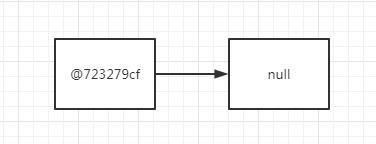
第【0】次循环,【移除之后】,链表item对象指向 = @723279cf->null->
其实移除之后,就是把节点的 item 修改为 null 之后,所以结构和上面还是一样的:
第【0】次循环就分析完了。可以看到现在的链表里面有一个 item 为 null 的元素,它还在链上,所以不会被回收。
接下来,我们分析一下第【1】次循环。
第【1】次循环,【移除之前】,链表item对象指向 = @723279cf->null->@10f87f48->
由于进入下次循环,所以会先执行 add 方法,所以现在的链表结构变成了这样:
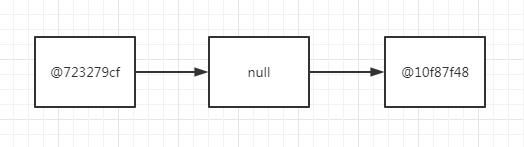
第【1】次循环,【处理null节点】把item为(@723279cf)的pred节点的next节点,从item为(null)的p节点修改为item为(@10f87f48)的next节点
pred 节点里面的 item 就是 @723297cf。
p 节点里面的 item 就是 null。
next 节点里面的 item 就是 @10f87f48。

第【1】次循环,【处理null节点之后】,链表item对象指向 = @723279cf->@10f87f48->
第【1】次循环,【修改节点item为null】被修改的p节点的item为(@10f87f48),即需要被删除的节点
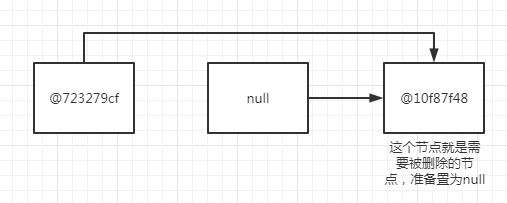
第【1】次循环,【修改节点item为null之后】,链表item对象指向 = @723279cf->null->
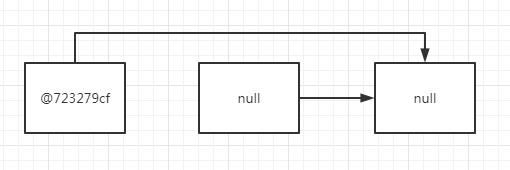
第【1】次循环,【移除之后】,链表item对象指向 = @723279cf->null->
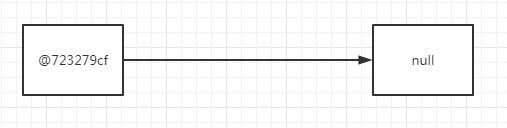
第【1】次循环完成后又回到了第【0】次循环完后的样子。
中间的那个 item 为 null 的节点去哪了呢?
因为这是个单向链表,从头节点已经不能遍历到这个节点了。所以等待它的命运将是被回收,所以也就不会内存溢出了。
到这里,我觉得这个问题算是回答清楚了吧?
关于 remove(obj) 我就分享到这里。
实话实话,这个方法对于 CLQ 并不是非常的重要,我们一般使用场景也比较少。
我写这节主要是两个目的。
一是回答读者的提问,因为毕竟是看了我的文章引发出来的问题,我有义务回答。
二是分享一下这种自己 copy 一个类出来,然后只加入输出语句的调试方式。这个调试方法老读者肯定知道了,我在写 ArrayList 的时候也用过,写 Dubbo 负载均衡算法的时候也用过。当你被一步步 debug 带晕的时候,你可以试一试这种方式,先整体再局部。比如本文的 CLQ,多线程调试 CLQ 的情况下,我觉得日志的输出对于你理解它的精髓非常的有帮助。
还是之前说过的,如果要深刻理解 CLQ 这个十分优秀、十分有想法的基于非阻塞方法实现的线程安全的队列,大家需要去看的是 offer、poll 方法。然后一个情况一个情况的去分析,看看它是怎么避免频繁 CAS 的,自己拿着草稿本在上面写写画画。
我也妄想过通过这篇文章给你们把它讲的明明白白的,后来我发现这对我而言难度有点大。
我在这里给大家指个路,看哪几种情况:
- 单线程下的 offer。
- 单线程下的 poll。
- 多线程下的一个线程 offer ,一个线程 poll。offer 比 poll 快。
- 多线程下的一个线程 offer ,一个线程 poll。offer 比 poll 慢。
就这四种情况,玩去吧。
一种非常优秀的思想,非常牛逼的实现,我希望你能静下心来坚持过半小时。

IDEA DEBUG 模式的巨坑
看了我上面的介绍,准备静下心来看第一种情况:单线程下的 offer。
如果你用 IDEA 的 Debug 调试 CLQ 的 offer 方法,半个小时后你心态应该就会炸裂:

你有可能会碰到的一个巨坑,比如我们的测试代码是这样的:
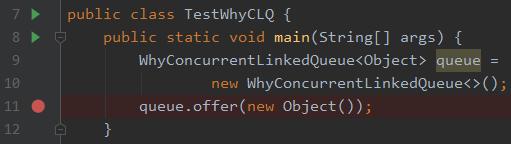
非常简单,在队列里面添加一个元素。
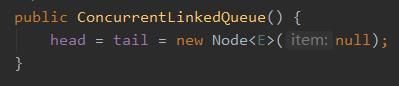
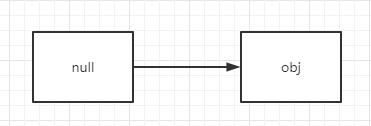
由于初始化的情况下 head=tail=new Node(null):
所以在 add 方法被调用之后的链表结构里面的 item 指向应该是这样的:
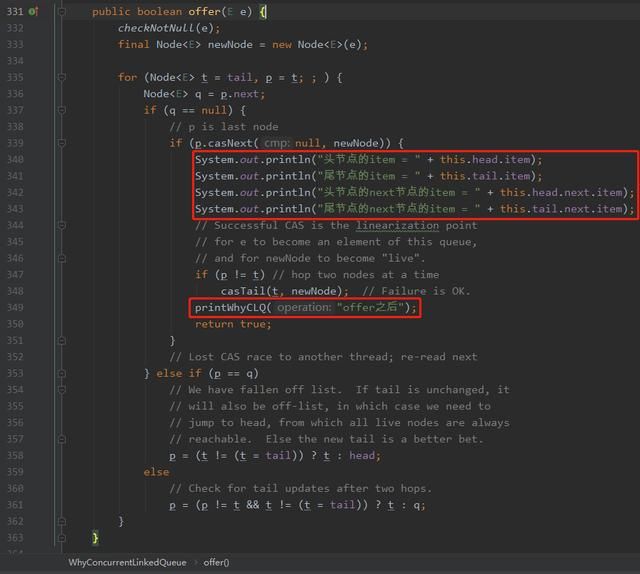
我们在 offer 方法里面加入几个输出语句:
执行之后的日志是这样的:
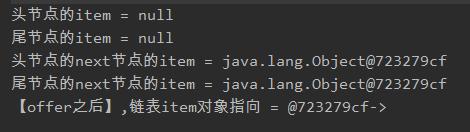
为什么最后一行输出,【offer之后】输出的日志不是 null->@723279cf 呢?
因为这个方法里面会调用 first 方法,获取真正的头节点,即 item 不为 null 的节点:
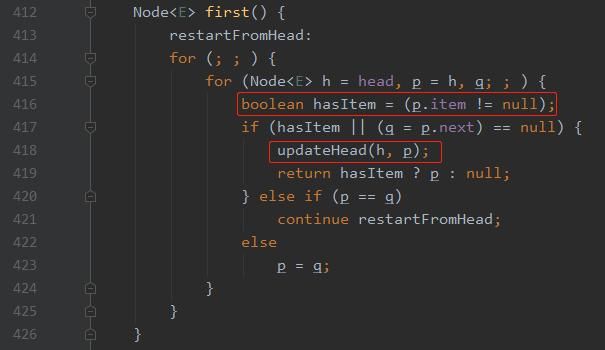
到这里都一切正常。但是,当你用 debug 模式操作的时候就不太一样了:

头节点的 item 不为 null 了!而头节点的下一个节点为 null,所以抛出空指针异常。
单线程的情况下代码直接运行的结果和 Debug 运行的结果不一致!这不是遇到鬼了吗。

我在网上查了一圈,发现遇到鬼的网友还不少。
最终找到了这个地方:
https://stackoverflow.com/questions/55889152/why-my-object-has-been-changed-by-intellij-ideas-debugger-soundlessly
这个哥们遇到的问题和我们一模一样:
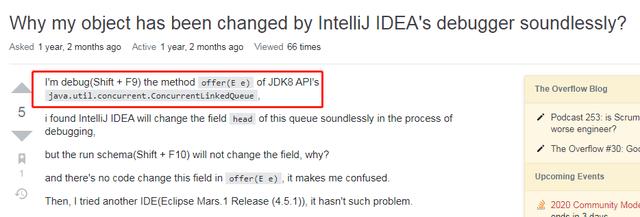
这个问题下面只有一个回答:

你知道回答这个问题的哥们是谁吗?
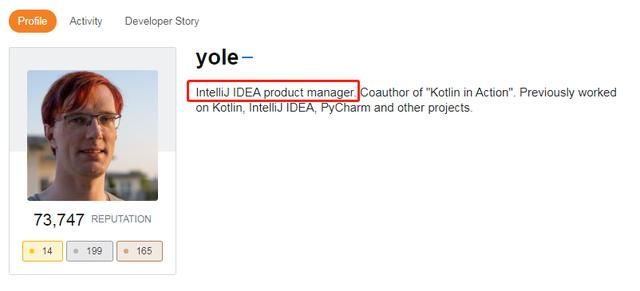
IDEA 的产品经理,献上我的 respect。

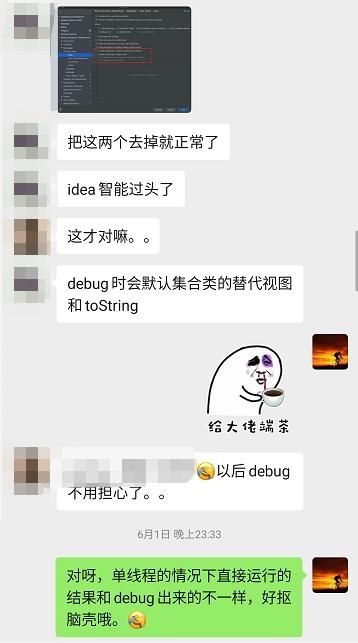
最后的解决方案就是关闭 IDEA 的这两个配置:

因为 IDEA 在 Debug 模式下会主动的帮我们调用一次 toString 方法,而 toString 方法里面,会去调用迭代器。
而 CLQ 的迭代器,会触发 first 方法,这个里面和之前说的,会修改 head 元素:
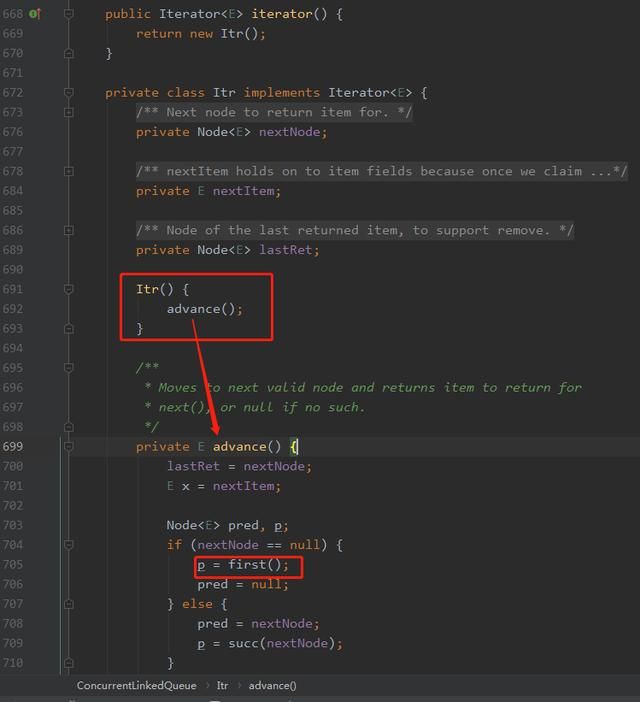
一切,都真相大白了。
之前,我认为是玄学。而现在,没有什么是玄学,我们要相信科学。
我身边也有朋友碰到过这个问题,如果不知道这个坑,非常的抠脑壳,很容易就“怀疑人生”了:

最后说一句
才疏学浅,难免会有纰漏,如果你发现了错误的地方,由于本号没有留言功能,还请你在后台留言指出来,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。
我是 why,一个被代码耽误的文学创作者,不是大佬,但是喜欢分享,是一个又暖又有料的四川好男人。