Retina U-Net论文简析
Contents
- Links
- Title
- Abstract
- 1.Introduction
- 2.Related work
- 3.Methods
-
- 3.1.Retina U-Net
-
- Retina Net
- Adding Semantic Segmentation Supervision
-
- 逐像素交叉熵损失(pixel-wide cross entropy)
- Dice系数损失(Dice coefficient loss)
- Weighted Box Clustering
- 4.Experiments
-
- 4.1.Backbone&Baselines
-
- Retina Net.
- Mask R-CNN.
- Faster R-CNN+.
- U-Faster R-CNN+.
- DetU-Net.
- 4.2. Training&Inference Setup
- 4.3.Evaluation
- 4.4.Lung nodule detection and categorization
-
- 4.4.1 Utilized data set
- 4.4.2 Results
- 4.5.Breast lesion detection and categorization
-
- 4.5.1 Utilized data set
- 4.5.2 Results
- 4.6.Toy Experiments
-
-
- 1.Distinguishing object shapes:
- 2.Learning discriminative object patterns:
- 3.Distinguishing object scales:
- 4.6.1 Utilized data set
- 4.6.2 Results
-
- 5.Conclusion
Links
paper: https://arxiv.org/pdf/1811.08661.pdf
github: https://github.com/pfjaeger/medicaldetectiontoolkit
Title

直译过来是说这个网络是对监督学习下医学目标检测的分割的简单开发,但是还有一个词embarrassingly(令人尴尬的),这就有点令人费解了。那就先读文章慢慢理解吧。
Abstract
作者比较了语义分割(semantic segmentation)和state-of-the-art detectors。
- semantic segmentation:通过预测pixel-level scores,再由特殊的启发式算法,映射到object-level scores。
- state-of-the-art:end-to-end(端到端)的单个物体scoring,但这是利用逐像素监督标注得到的。这点对医学图像分割尤其不利,因为医学的数据集都是建立在像素级别的。
作者提出的Retina U-Net:自然地融合了Retina Net这个one-stage detector和U-Net 结构,广泛用于医学图像语义分割。这个网络通过辅助的语义分割补充丢失的监督标记,而且不会引入之前提出的two-stage detectors的复杂性。作者还说这个网络强大的检测性能只有更复杂的two-stage同类才能与其媲美。
1.Introduction
主要提到了U-Net,object-level,粗略水平的检测,两种应用于object-level预测的方法(two-stage detectors和one-stage detectors)及作者的做法。
-
U-Net网络是一种语义分割算法,目前在临床中已形成了一种标准,这归功于医学图像通常是用像素级别的标注标识感兴趣目标的结果,它们也很好地应用于逐像素监督学习的分割场景。不仅如此,MRI和CT成像还能捕获3D空间的影像,包括空间中的物体分割,因此不需要区分(重叠的)实例。
-
尽管像放疗或肿瘤生长态势探测在临床上需要像素级别的检测,在大多情况下,粗略水平下的的检测和知道要探测的东西存在是有联系的。在评估object-level大小的模型时,这种联系在研究设计中得到了最佳反映。为了弥合(bridge)语义分割pixel-level的检测和object-level的评估,必须要引入特殊的启发式算法或是其他模型。
通过从粗略水平级别提取预测信息到实现end-to-end的object scoring,大多目前的目标检测都基于FPN(feature pyramid network)。
- 现有两种方法应用于object-level检测,一是two-stage detectors:无论第一种物体是什么类都与背景相区别,随着边界框回归生成大小可变的候选框,然后候选框重采样为大小固定的网格以确定分类比例的不变性。二是one-stage detectors:在粗略水平可立即分类出物体的类别。但这种在粗略水平检测会导致信息的丢失,这又与医学领域相对level较小的数据集的数据得到有效训练的需求相悖。
作者表明,充分利用可用的语义分割标注可以使医学图像上的检测性能显著提升。此外,作者认为two-stage detectors中的重采样操作在医学领域中并无帮助,因为与自然图像不同,是语义编码信息描述了比例的变化,而非物体和相机间的距离变化。
作者的做法是通过高分辨率补充FPN自下而上的部分(以学习语义分割),通过在U-Net的decoder部分的粗略水平上的两个子网络来改进U-Net(以允许end-to-end的object-scoring)。
作者通过两个数据集评估自己的模型。一个是LIDC-IDRI【Lung-CT】(一个公开的数据集),另一个是Diffusion-MRI(一个内部的数据集)。
这篇论文有以下的contributions:
-
一种简单有效且侧重于医学图像中的应用,可用于通过语义分割训练识别标注。
-
对流行的object detectors(无论在2D还是3D)进行了深入分析。
-
一种名为weighted box clustering的算法,可用于在2D和3D中合并同一图像的不同检测结果。
-
这是一个全面的框架。
2.Related work
许多two-stage detectors学习通过基于proposal的分割,但是,作者质疑这种做法,因为它没有充分地利用语义分割监督。有如下原因:
-
仅在裁剪的候选区上评估mask loss,也就是说,周围区域的前后梯度不反向传播。
-
proposal region(候选区)和ground truth mask通常被重采样为大小固定的网格(RoIAlign)。
-
只有正例的候选区被用于mask loss,这会导致对候选区表现的依赖。
-
mask loss的梯度不会流过整个模型,而只从相应的pyramid(金字塔)级向上流动。
而在one-stage领域,Uhrig等人在SSD上进行语义分割并用于实例分割,这与作者的做法很类似,其中分割输出在后处理中分配给候选框。Zhang等人也提出了类似的结构,但是是使用边界框标注创建的masks,以弱监督方式学习分割。
与用于特征提取的自下而上的主干网络相反,作者遵循了FPN的方法,即有自上而下(decoder)的路径使得不同尺度的语义都能丰富地展示。
作者还用一些例子强调了额外的语义分割监督的重要性。
3.Methods
3.1.Retina U-Net
Retina Net
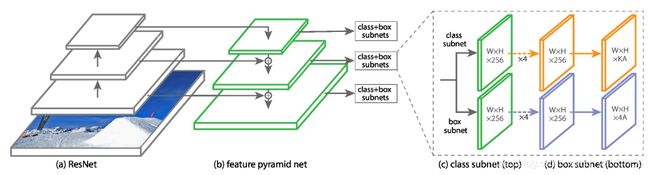
如上图所示,Retina Net是一个基于FPN的、简单的one-stage的检测网络。其中两个sub-networks分别在金字塔等级P3-P6上进行分类和边界框回归。这里Pj表示第j个解码器级别的特征映射,其中j随着分辨率的降低而增加。由于考虑到医学图像中小对象的存在,作者将sub-networks操作向一个金字塔级别转移到P2-P5,因为在更高分辨率的级别中产生了大量密集位置。
这样的结构类似于对称的U-Net结构,作者把它称作U-FPN。
作者在sub-networks的cl(分类)中把sigmoid non-linearity换成softmax(可解决由于3D图像中的非重叠目标而导致的类别互斥性),对于3D的实现,第一个网络的feature maps数量降低到64(可降低GPU内存开销)。
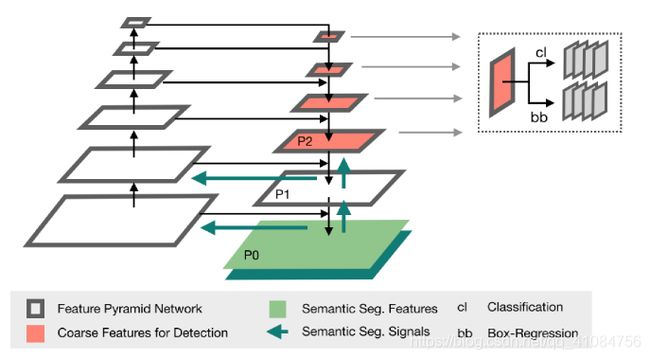
Adding Semantic Segmentation Supervision
添加了语义分割监督。在图中,可以看到绿色的箭头就是将Semantic Seg.的Signals通过P1和P0添加到top-down的path中,而且Signals还会跳接到bottom-up path中。
在图中的灰色箭头表示会在该层预测,而P0、P1这两层不预测,这使得在理论时间内参数的数量不变。
segmentation loss是根据P0logits计算的,它用到了逐像素交叉熵损失(分别检查每个像素,将类预测与热编码目标向量进行比较),还用到了Dice loss(在类别极不平衡的分割任务中能很稳定地训练)。(这两个都是医学分割中常用的损失函数)
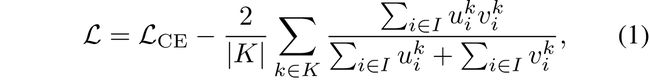
其中,u是网络的softmax输出,v是ground truth的一个one hot编码。u和v都是大小为I x K的矩阵(i∈I是training batch中的像素数量,k∈K是类别)。
逐像素交叉熵损失(pixel-wide cross entropy)
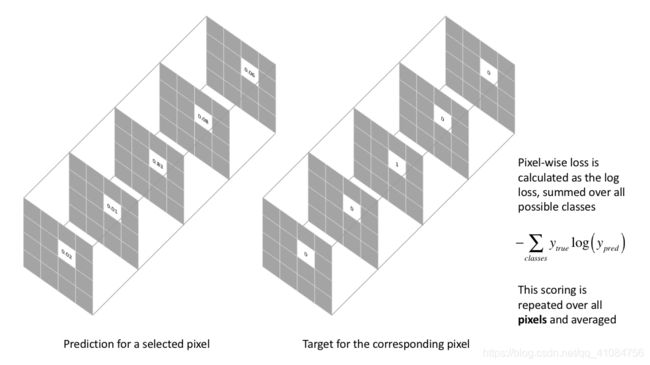
逐像素交叉熵损失**单独评估每个像素矢量的类预测,然后对所有像素求均值,**我们可以认为图像中的像素被平等的学习了。但是由于医学图像的高分辨率,常出现类别不平衡的问题,所以,训练会被像素较多的类主导,对于较小的物体很难学到它的特征,网络的有效性会被降低。
Dice系数损失(Dice coefficient loss)
dice系数源于二分类,本质上是为了衡量两个样本的重叠部分。范围为[0,1],1表示完全重叠。它的计算公式是:
D i c e = 2 ∣ A ∩ B ∣ ∣ A ∣ + ∣ B ∣ Dice=\frac{2\left | A\cap B \right |}{\left | A \right |+\left | B \right | } Dice=∣A∣+∣B∣2∣A∩B∣
其中,|A∩B|表示集合A、B之间的共同元素,|A|、|B|分别表示A、B集合中的元素个数。其中,分子的系数为2是由于分母存在重复计算A和B之间共同元素。
Dice loss:
为了形成可以最小化的损失函数,我们将简单地使用1-Dice。这种损失函数被称为 soft dice loss,因为我们直接使用预测概率而不是使用阈值或将它们转换为二进制mask。
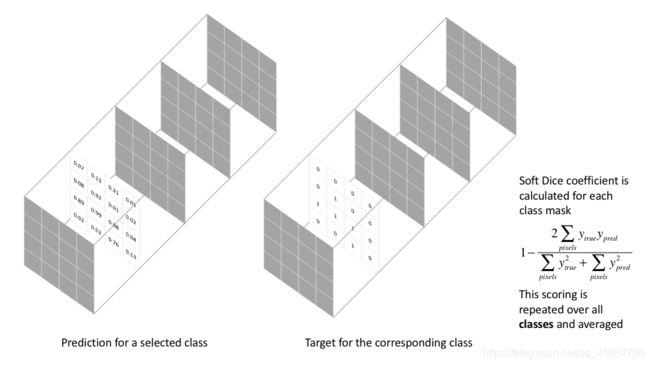
dice loss比较适用于样本极度不均的情况,一般的情况下,使用 dice loss 会对反向传播造成不利的影响,容易使训练变得不稳定。
Weighted Box Clustering
由于医学图像的高分辨率及3D成像(MRI),需要对patch crops进行训练,从而需要在可用GPU内存限制与batch size和patch size之间权衡。
为了合并对目标检测的预测结果,作者提出了weighted box clustering(WBC),加权框聚类:这个算法与非极大值抑制算法(NMS)类似,根据IoU阈值进行聚类的预测,而非选择得分最高的候选框。
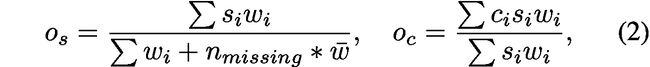
其中,os表示每个预测框的加权置信分数,oc表示每个坐标的加权平均值,i是聚类的下标,s是置信度分数,c是坐标。n missing表示对集群没有贡献一个框的视图的权重。
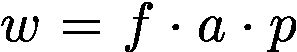
w是加权因子,包含:
重叠因子f:预测框与得分最高的框(softmax confidence)之间的重叠权重。
区域a:表明较大的框有较高的权重。
patch中心因子p:以patch中心的正态分布密度分配分数。
4.Experiments
4.1.Backbone&Baselines
在这项研究中,作者将Retina U-Net与一组one-stage和two-stage物体检测器比较。为了公平地比较,所有的模型都用同一个框架(Pytorch)实现。都使用基于ResNet50的FPN作为共同的特征提取器。由于医学图像的目标相对较小,因此使用anchor都以4为因子,即对应金字塔{P2,P3,P4,P5}的anchor大小为{4²,8²,16²,32²}(2D)。而在3D中,anchor cube的大小设为{1,2,4,8}(沿z轴通常有较低的分辨率)。
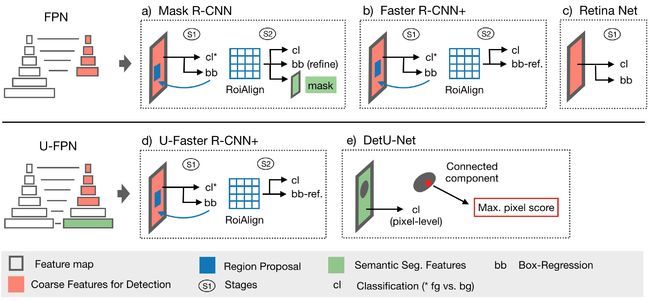
Retina Net.
图c)Retina Net的实现与Retina U-Net中的相同。
Mask R-CNN.
图a)需要对3D进行微调:在RPN中的feature map降到64(可降低GPU内存开销),3D-RoIAlign的poolsize对classification head设置为(7,7,3),对mask head设置为(14,14,5)。positive候选框的IoU降到0.3。
Faster R-CNN+.
图b)为了挑出从Mask R-CNN中通过分割监督获得的性能增益,作者对toy data sets进行ablation(消融),并禁用mask-loss。从而有效地将模型减少到更快的R-CNN结构(除了RoIAlign操作,用+表示)。
因为Mask R-CNN大致是在Faster R-CNN上增加了分割。消融实验类似于控制变量。因为作者提出了一种方案,同时改变了多个条件/参数,他在接下去的消融实验中,会一一控制一个条件/参数不变,来看看结果,看到底是哪个条件/参数对结果的影响更大。
U-Faster R-CNN+.
图d)通过在U-FPN上部署Faster R-CNN来探索two-stage中额外语义分割的性能。
DetU-Net.
图e)使用UFPN实现类似U-Net的baseline,通过用1x1的卷积从P0中提取softmax预测,用于识别所有前景类的连通分量,通过连通分量画边界框(体),并将每个分量和类别的最高sofxmax概率指定为目标的得分。为了降低噪声,每个图像仅考虑5个(3D15个)最大分量。
4.2. Training&Inference Setup
- 2D:slice-wise处理
- 2Dc:±3张相邻切片作为附加输入
- 3D:体积卷积
- softmax probability解决分类损失的类不平衡。
- Adam优化、0.0001的learning rate、5折交叉验证(train60%、val20%、test20%)、2Dbatchsize为20(3D为8)。
- 为防止过拟合,2D、3D都采用数据增强。
- 为了补偿小数据集的不稳定数据,通过执行测试时镜像以及根据验证度选出5个最高得分的多个模型进行测试。
- 通过对得分和坐标进行加权聚类,来合并来自全部成员(ensemble-members)和重叠区的预测框。
- 应用非极大值抑制(NMS)的自适应来合并从2D到3D框的预测:将所有切片的框投影到一个平面中,同时保留切片原点信息。应用NMS时,只有与最高得分框的切片直接或间接相连的框才被视为匹配。将所有匹配的最小最大切片编号指定为预测立方体的z坐标的结果。
4.3.Evaluation
使用mAP(平均精确度)评估实验。在IoU=0.1的阈值处的相对较低匹配交叉点处确定mAP。
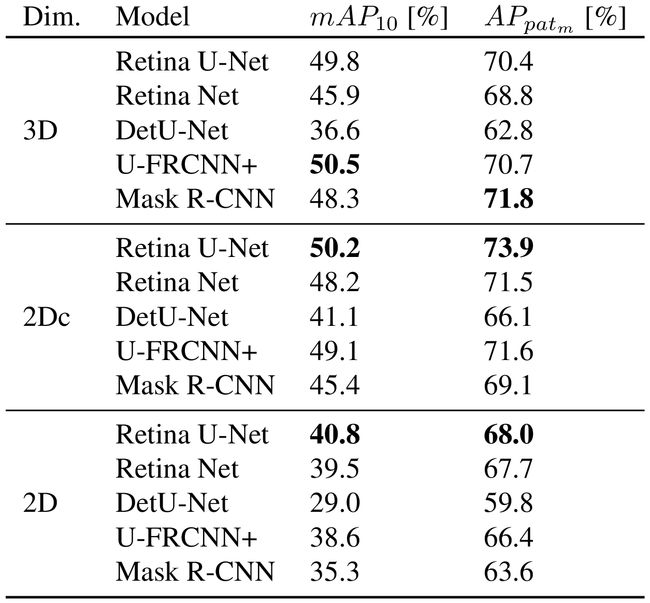
4.4.Lung nodule detection and categorization
肺结节的检测与分类,检测病变是良性还是恶性。细粒度分类有望在不断增长的数据集和图像分辨率的背景下获得相关性。
4.4.1 Utilized data set
使用公开数据集LIDC-ICRI(1035个肺部CT扫描)。使用数字1-5表示恶性的可能性等级。良性标记(1-2,n=1319)、恶性标记(3-5,n=494)。CT扫描重采样为0.7x0.7x1.25mm,大致对应于数据集的平均分辨率。训练时,patches大小为288x288(2D),128x128x64(3D)。
4.4.2 Results
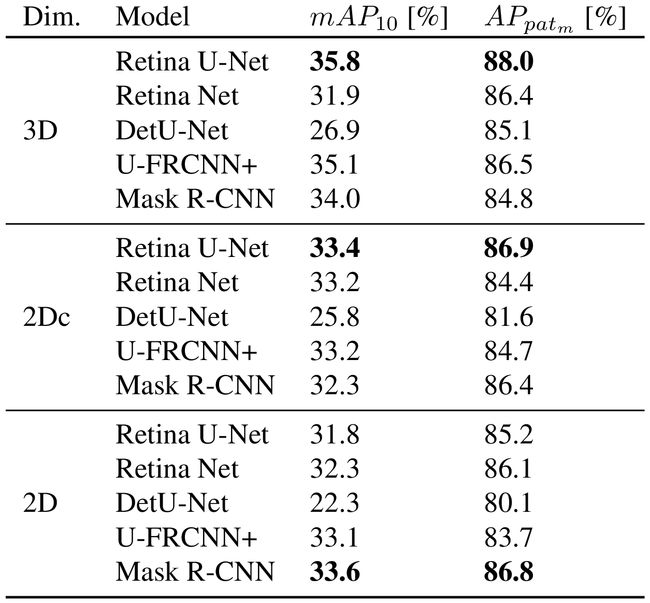
4.5.Breast lesion detection and categorization
乳房病变检测。
4.5.1 Utilized data set
使用的数据集是在331名患者的扩散MRI内部数据集上进行的,这些患者在之前的乳房X线照相术中有可能患病的风险。良性标注n=141,恶性标注n=190。图像重采样为1.25x1.25x3mm。训练时,patches大小为160x160(2D),160x160x56(3D)。
4.5.2 Results
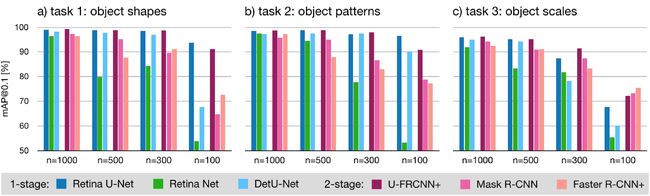
4.6.Toy Experiments
这一系列的toy experiments主要是来处理医学上对象分类的子任务,如区分尺度,形状和强度。更具体是为了研究在有限的训练数据下完全分割监督的重要性。这里有三个子任务,且每个任务逐渐减少训练数据量:
1.Distinguishing object shapes:
检测和区分两类物体的形状。a)图:第一类是由直径为20像素的圆形组成,第二类是由20像素的圆形和直径为4像素的中心组成,类似于甜甜圈状。预计完全语义监督将在此任务中产生显着的性能提升,特别是在小数据中。

2.Learning discriminative object patterns:
这个任务与前一任务相同,图a)除了中心孔没有从甜甜圈的segmentation masks中切除。这需要模型拾取判别模式(孔),而不是通过mask的形状明确指出它。
在医学图像的背景下,这种设置可以被认为是更真实的。
3.Distinguishing object scales:
检测和区分两类物体的尺度。图b)第一类由直径为19像素的圆组成,第二类由直径为20像素的圆组成。类信息完全以对象比例编码,因此在目标框坐标中编码。预计语义监督不会带来重大收益。
4.6.1 Utilized data set
使用的两个数据集均为由人工生成的320x320的2D图像组成,1000个用于训练,500个用于验证,另外1000个用于测试。
4.6.2 Results
5.Conclusion
1.输入维度上利用语义分割的重要性,并与流行的目标检测模型进行了细致的比较,特别强调了有上下联系的有限训练数据。
2.在公开可用的LIDC-IDRI肺CT数据集以及内部的乳房病变MRI数据集中,Retina U-Net产生的检测性能优于没有完全分割监督的模型。
3.正如标题所说,Retina U-Net,在其令人尴尬的简单的架构中利用监督的语义分割来解决医学图像较大而目标较小的问题。