Python - 深度学习系列22 - Electra并行处理修改
说明
场景是实体识别。原来做的一版是逐条预测的,效率太低,这里改为并行预测的。
内容
1 处理流程
对于每一个文档(从一句话到一大篇文章),我们要先进行切割句子,目标是生成短句(SS),这个将是模型处理的入参。
约定,每个文档以字典列表[{'doc_id':xxx, 'content':xxx}, ...]的方式输入,统一转化为df后再进行处理。如果本身就是表格状的,那么直接就转为df0
| doc_id | content |
|---|---|
| xxx | xxxx |
进行处理。
首先,根据doc_id进行循环,每个content被分割为若干短句 df1
| doc_id | ss | ss_hash |
|---|---|---|
| xxx | xxx | xxx |
df1被暂存,主要需要其中的doc_id和ss_hash。
然后将df1根据ss_hash去重,仅保留ss_hash和ss字段,形成新的df2
然后将df2送入模型,模型根据ss的长度进行循环,每次处理某一长度的ss,最后形成df3
| ss_hash | result |
|---|---|
| xxx | xxx |
最后将df3的结果形成字典,匹配到df2上(根据ss_hash),称为df4。将df4按照doc_id汇总求和就得到了最终的结果。
| doc_id | result |
|---|---|
| xxx | xxx |
其中的并行化的关键在与批量处理同长度的短句。
Note: 这部分梳理好之后也放到规则集模板里,下次就可以直接调用了。
2 具体过程
2.1 导包
import FuncDict as fd
import pandas as pd
cur_func_dict = fd.FuncDict1('parallel_electra', pack_fpath='./funcs/',lmongo=fd.func_lmongo)
import funcs as fs
cur_func_dict.fs = fs
from IPython.display import HTML
import time
import tqdm
2.2 读取数据
- 在文件夹下有1000个pkl文件
the_path = './test_0_1000/manual_data/'
# 获取前n个文件名 - 这次手工就全量读入了
cur_batch_flist = fs.get_batch_file(the_path,'query_result_', 2000)
cur_batch_flist1 = [x.replace('.pkl','') for x in cur_batch_flist]
data_list = fs.get_batch_pkl(cur_batch_flist1, the_path, fs)
df_list = []
for the_data in data_list:
tem_df = pd.DataFrame(list(the_data), columns = ['id','content_a','content_b'])
df_list.append(tem_df)
df0 = pd.concat(df_list, ignore_index=True)
其中df0就是要处理的原始数据框,本来应该只有一个content的,但是这次手工处理是个例外,暂时不管。之后重新命名以后跑两次就好了。本次处理的数据大约57万条。

因为有两次计算,所以原始数据保留一份(都算完后再合并)

2.3 拆分短句
# 处理第一次计算
cur_df0 = df0_1
the_df = cur_df0.copy()
# 参数设置
# 认为公司名不少于4个字(人名可能就是2)
keep_min_len = 2
keep_max_len = 100
# 一次并行处理的短句,根据显存而定
batch_size =4000
target='company'
start = time.time()
# 将文本切开
the_df['content_list'] = the_df['content'].apply(fs.txt_etl)
end = time.time()
print('takes %.2f' %(end-start))
---
takes 3.80
大约使用4秒,将原来的长字符串切分为了短句
2.4 将宽表整合为长表,这步最慢
doc_id_list = []
ss_list = []
start = time.time()
for i in range(len(the_df)):
the_dict = dict(the_df.iloc[i])
# 不允许缺失
the_doc_id = the_dict['doc_id']
content_list = the_dict['content_list']
content_list1 = [x for x in content_list if len(x)>=keep_min_len and len(x) < keep_max_len]
tem_doc_id_list = [the_doc_id] * len(content_list1)
doc_id_list += tem_doc_id_list
ss_list += content_list1
end = time.time()
print('takes %.2f' %(end-start))
---
takes 53.23
2.5 对短句进行处理
因为要解析的是公司名/人名,所以对短句进一步清洗
start = time.time()
df1 = pd.DataFrame()
df1['doc_id'] = doc_id_list
df1['ss'] = ss_list
# 对短句再进行一次筛选
df1['ss'] = df1['ss'].apply(fs.extract_str_like_company_human)
df1['ss_hash'] = df1['ss'].apply(fs.md5_trans)
end = time.time()
print('takes %.2f' %(end-start))
---
takes 13.13
2.6 进一步筛选短句
这次计算公司名,所以可以进一步筛选
start = time.time()
# 对公司来说有特征词
sel = (df1['ss'].apply(len) >3) & (df1['ss'].apply(fs.str_contains_words))
end = time.time()
print('takes %.2f' %(end-start))
---
takes 17.78
最后保留数据
# 最后可能有数据的文档及短句
df2 = df1[sel][['doc_id', 'ss_hash']].copy()
# df2留着挂最后的结果
df2.shape
---
(1244248, 2)
df2 = df2.drop_duplicates()
df2.shape
(1243764, 2)
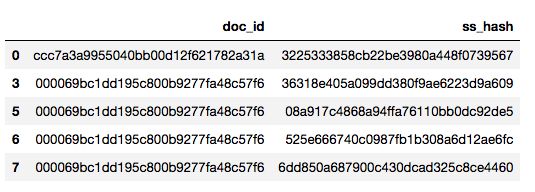
2.7 生成模型要处理的df
重复的ss可以去掉,没必要重复处理
# 需要解析的根据ss_hash去重
df3 = df1[sel][['ss_hash','ss']].drop_duplicates(['ss_hash']).copy()
# 最后根据长度循环
df3['ss_len']= df3['ss'].apply(len)
# 以长度为键值存字典
ss_res_dict = {
}
for i in range(keep_min_len,keep_max_len):
ss_res_dict[i] = df3[df3['ss_len']==i]['ss']
# 列表中的每一项都是模型要批量处理的
all_length_ss_list = []
for k in list(ss_res_dict.keys()):
cur_ss = ss_res_dict[k]
# 考虑到显存/内存,会对数据进行多一次的切分(如果有超长的会被切为n段)
cur_ss_list = fs.split_series_by_interval(cur_ss, batch_size)
all_length_ss_list += cur_ss_list
2.8 模型参数设置
这些都是和训练时一样的设置
# 模型初始设置
path_name = './'
model_checkpoint = path_name + 'model/model_v0/'
label_list = ['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-T', 'I-T']
max_len = 200
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForTokenClassification
# Setting up the device for GPU usage
from torch import cuda
device = 'cuda' if cuda.is_available() else 'cpu'
print('device available', device)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
assert isinstance(tokenizer, transformers.PreTrainedTokenizerFast)
# 预载入(device=cpu)
model = AutoModelForTokenClassification.from_pretrained(model_checkpoint, num_labels=len(label_list))
from functools import partial
tencoder = partial(tokenizer.encode,truncation=True, max_length=max_len, is_split_into_words=True, return_tensors="pt")
---
device available cuda
2.9 循环处理
对每个列表调用一次模型的并行处理,这里可以看到CPU和GPU的差距
cur_ss_list = all_length_ss_list
res_dict = {
}
for i in tqdm.tqdm(range(len(cur_ss_list))):
handle_s = cur_ss_list[i]
tem_res_dict = fs.ner_batch_predict(model = model, device = 'cuda',handle_s=handle_s,tencoder=tencoder,
label_list=label_list,fs=fs, verbose = True)
res_dict.update(tem_res_dict)
2.9.1 CPU处理
CPU处理时间会随着对象的大小而变化。

2.9.2 GPU处理
显存不爆的话,GPU每次处理时间几乎是恒定的。

评估下来,处理这150个列表元素,CPU花费的时间估计在1500秒(按平均十秒), GPU花费时间3秒(平均0.02)。原来单发模型下每条文档要处理0.3秒。前面的数据处理开销我们认为有200秒,数据就按50万条估计。
| 模式 | 平均每文档时间 |
|---|---|
| 单发 | 0.3s |
| 并发CPU | 0.0034s |
| 并发GPU | 0.0004s |
使用显卡使得模型预测在处理过程中完全不是瓶颈。
2.10 将结果合并到df2,并按文档输出
2.10.1 先按ss_hash将模型预测结果匹配过来
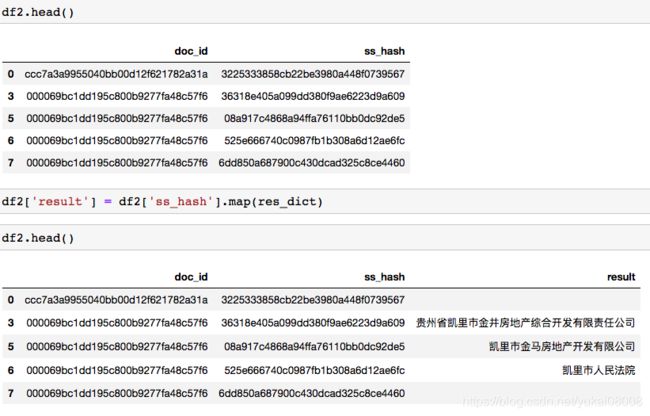
2.10.2 按长度筛选
我自己写了一个区间判断的函数,这样就不用安装Interval包了。
# 设定保留区间
keep_min_len = 4
keep_max_len = 100
# 默认左闭右开
keep_interval = fs.set_interval_judge(xleft = keep_min_len, xright = keep_max_len, fs = fs)
df2.shape
---
(1243764, 3)
df4 = df2.dropna()
# str.strip()就是把这个字符串头和尾的空格,以及位于头尾的\n \t之类给删掉。
sel4 = df4['result'].apply(lambda x: str(x).strip()).apply(len).apply(keep_interval)
sel4.sum()
---
698142
df_res = df4[sel4].copy()

2.10.3 合并输出
df_res['result'] = df_res['result'] +','
start = time.time()
df_res1 = df_res.groupby(['doc_id'])['result'].sum().reset_index()
end = time.time()
print('takes %.2f' %(end-start))
---
takes 42.27

3 总结
- 1 并行化比单条处理快100倍
- 2 使用显卡计算,比CPU至少快20倍
- 3 下一步再做一些规范化就可以封装了
- 4 接口调用时方式会有变化。第一次请求会收到一个回执,但可能要过若干分钟要用回执才能取结果。(一次吞吐10万条级别比较合适)
- 5 如果真的请求量特别大,可以把ss的结果保存在数据库里,作为字典,大部分时候拆解成短句,用ss_hash查询就好了,不需要反复计算。