fbprophet论文翻译:Forecasting at Scale
prophet论文翻译
- prophet论文翻译:Forecasting at Scale
- 1 Introduction
- 2 Features of Business Time Series
- 3 The Prophet Forecasting Model
-
- 3.1 The Trend Model
-
- 3.1.1 Nonlinear, Saturating Growth
- 3.1.2 Linear Trend with Changepoints
- 3.1.3 Automatic Changepoint Selection
- 3.1.4 Trend Forecast Uncertainty
- 3.2 Seasonality
- 3.3 Holidays and Events
- 3.4 Model Fitting
- 3.5 Analyst-in-the-Loop Modeling
- 4 Automating Evaluation of Forecasts
-
- 4.1 Use of Baseline Forecasts
- 4.2 Modeling Forecast Accuracy
- 4.3 Simulated Historical Forecasts
- 4.4 Identifying Large Forecast Errors
- 5 Conclusion
- References
-
- 附录1 R o l l i n g O r i g i n Rolling \ Origin Rolling Origin
prophet论文翻译:Forecasting at Scale
为啥要做这一篇翻译,因为在实际工作中用到了fbprophet,其次,prophet模型与我之间接触到的X13建模框架非常相似,差异在于具体的各成分的估计方法,比较好奇它如何估计出各个成分的;最后,prophet模型与我之前写过的一篇预测文章中都用到了皮尔增长曲线,且都对增长率进行了扩展,想看下他们的拓展方法。
论文下载地址: https://pan.baidu.com/s/11l0I0nTZWZSQX2usWCtDDg,提取码:ubo7
1 Introduction
提供了如下图所示的建立预测模型的架构:

上图是prophet的整体框架,整个过程分为四部分:Modeling、Forecast Evaluation、Surface Problems以及Visually Inspect Forecasts。从整体上看,这是一个循环结构,而这个结构又可以根据虚线分为分析师操纵部分与自动化部分,因此,整个过程就是分析师与自动化过程相结合的循环体系,也是一种将问题背景知识与统计分析融合起来的过程,这种结合大大的增加了模型的适用范围,提高了模型的准确性。按照上述的四个部分,prophet的预测过程为:
- Modeling:建立时间序列模型。分析师根据预测问题的背景选择一个合适的模型。
- Forecast Evaluation:模型评估。根据模型对历史数据进行仿真,在模型的参数不确定的情况下,我们可以进行多种尝试,并根据对应的仿真效果评估哪种模型更适合。
- Surface Problems:呈现问题。如果尝试了多种参数后,模型的整体表现依然不理想,这个时候可以将误差较大的潜在原因呈现给分析师。
- Visually Inspect Forecasts:以可视化的方式反馈整个预测结果。当问题反馈给分析师后,分析师考虑是否进一步调整和构建模型。
2 Features of Business Time Series
- 受节假日的影响;
- 具有一定的周期性,比如周末效应和季节效应;
- 时间序列的趋势增长率非固定。
3 The Prophet Forecasting Model
本段不想详细翻译了,简单概况一下:根据上述分析的时间序列特征,作者采用(Harvey & Peters 1990)中对时间序列的处理,即假设时间序列可以分解为趋势、循环和节假日以及随机干扰,其中趋势、循环成分和节假日都假设为时间的函数:
y ( t ) = g ( t ) + s ( t ) + h ( t ) + ϵ t y(t)=g(t)+s(t)+h(t)+\epsilon_t y(t)=g(t)+s(t)+h(t)+ϵt
其中: g ( t ) g(t) g(t)表示趋势成分, s ( t ) s(t) s(t)表示季节/周末等循环成分, h ( t ) h(t) h(t)表示节假日等事件成分,这部分类似于周期成分但又不同,比如春节,春节的话虽然一年一次,但是出现的阳历日期每一年是不一样的,所以其周期并不固定;
译者注:时间序列的这种分解方法比较古老了,估计各成分的方法也有很多种,比如X13中用线性滤波器以及迭代法来估计趋势循环成分,再比如可以用卡尔曼滤波来估计时间序列的各个成分,还有一种时间序列的分解方法是经验模态分解法(EMD),EMD分解出来的时间序列与上述的模型假设不同,其分解出来的各个成分没有物理意义,且分解几部分也是不确定的。
3.1 The Trend Model
提供了两种趋势建模:一种是假设趋势与时间是非线性关系,这里假设趋势皮尔生长曲线,另一种是假设趋势与时间是线性关系。
3.1.1 Nonlinear, Saturating Growth
假设趋势与时间是非线性关系,具体方程如下:
y ( t ) = C ( t ) 1 + e x p ( − k ( t − m ) ) y(t)=\frac{C(t)}{1+exp(-k(t-m))} y(t)=1+exp(−k(t−m))C(t)
其中,C是承载力,表示 y ( t ) y(t) y(t)能达到最大或最小的值, k k k是增长率, m m m是其他参数,用于曲线的左右平移。但是真实的数据往往是 k k k不是一个确定性的常数,而是一个随着时间变化的量,这里作者把 k k k扩展成了一个分段阶梯函数;后面的内容都是按文章翻译的:
通过定义允许增长率变化的变化点,我们将趋势变化纳入了增长模型;假设增长率在时刻 s j , j = 1 , . . . , S s_j,j=1,...,S sj,j=1,...,S,有 S S S个变化点,定义一个增长率调整向量 δ ⃗ ∈ R S \vec{\delta} \in R^S δ∈RS,其中 δ j \delta_j δj是时刻 s j s_j sj的增长率变化量,将所有时期的变化量加上期初的增量量,就得到 t t t时刻的增长率: k + ∑ j : t > s j δ j k+\displaystyle {\sum_{j:t>s_j}{\delta_j}} k+j:t>sj∑δj(译者注: ∑ j : t > s j \displaystyle {\sum_{j:t>s_j}} j:t>sj∑表示遍历 j j j的取值范围,然后找出满足条件: t > S j t>S_j t>Sj的 j j j,然后再按照这个index取出 δ j \delta_j δj做加法汇总,所以这么理解的话,这里文章应该有误,即选取 j j j的条件: t > S j t>S_j t>Sj应该包含等号,才能跟下文向量的表述结果一致,因此,这里将 k k k修正的表达式更改为: k + ∑ j : t ≥ s j δ j k+\displaystyle {\sum_{j:t \ge s_j}{\delta_j}} k+j:t≥sj∑δj).这可以通过定义一个向量 a ⃗ ( t ) ∈ { 0 , 1 } S \vec{a}(t)\in\{0,1\}^S a(t)∈{ 0,1}S,其中:
a j ( t ) = { 1 t ≥ S j 0 t < S j a_j(t)=\begin{cases} 1\qquad & t \ge S_j \\ 0 \qquad & t \lt S_j \end{cases} aj(t)={ 10t≥Sjt<Sj
则第 t t t期调整后的增长率计算公式如下( 注意:文章中的向量均是指列向量):
k t = k + a t → ′ ⋅ δ → k_t=k+\overrightarrow {a_t}'·\overrightarrow{\delta} kt=k+at′⋅δ
举例说明:假设给定的时间序列长度为10,其中在第5( S 1 = 5 S_1=5 S1=5)和第7( S 2 = 7 S_2=7 S2=7)时刻出现增长率的结构突变,那么每一时刻的增长率计算如下:
| t | t ≥ S 1 t\ge S_1 t≥S1 | a 1 ( t ) a_1(t) a1(t) | t ≥ S 2 t \ge S_2 t≥S2 | a 2 ( t ) a_2(t) a2(t) |
|---|---|---|---|---|
| 1 | False | 0 | False | 0 |
| 2 | False | 0 | False | 0 |
| 3 | False | 0 | False | 0 |
| 4 | False | 0 | False | 0 |
| 5 | True | 1 | False | 0 |
| 6 | True | 1 | False | 0 |
| 7 | True | 1 | True | 1 |
| 8 | True | 1 | True | 1 |
| 9 | True | 1 | True | 1 |
| 10 | True | 1 | True | 1 |
当 t = i t=i t=i时,增长率 r i r_i ri为:
r i = k + a 1 ( i ) ⋅ δ 1 + a 2 ⋅ δ 2 = a ( i ) ⃗ ′ ⋅ δ ⃗ r_i=k+a_1(i)·\delta_1+a_2·\delta_2=\vec{ {a(i)}}'·\vec{\delta} ri=k+a1(i)⋅δ1+a2⋅δ2=a(i)′⋅δ
其中:
a ( i ) ⃗ = ( a 1 ( i ) a 2 ( i ) ) , δ ⃗ = ( δ 1 δ 2 ) \vec{ {a(i)}}= \begin{pmatrix} a_1(i) \\ a_2(i) \end{pmatrix},\vec{\delta}=\begin{pmatrix} \delta_1 \\ \delta_2 \end{pmatrix} a(i)=(a1(i)a2(i)),δ=(δ1δ2)
当 i = 5 i=5 i=5时:
r 5 = k + a 1 ( 5 ) ∗ δ 1 + a 2 ( 5 ) ∗ δ 5 = k + 1 ⋅ δ 1 + 0 ⋅ δ 2 = k + δ 1 r_5=k+a_1(5)*\delta_1+a_2(5)*\delta_5=k+1·\delta_1+0·\delta_2=k+\delta_1 r5=k+a1(5)∗δ1+a2(5)∗δ5=k+1⋅δ1+0⋅δ2=k+δ1
因为对曲线修正了增长率,可能破坏了曲线的连续可微性,由于改变增长率,可微性被破坏了,因此,这里需要调整下曲线,使得曲线仍然保持可微的性质,为什么要这么做呢,因为作者最后解决参数的方法是利用数值法 ,即对似然函数进行求导,所以,这里无论怎么变形,都要得到一个连续可导的函数,下面是文章中给出的修正因子:
γ j = ( s j − m − ∑ l < j γ l ) ( 1 − k + ∑ l < j δ l k + ∑ l ≤ j δ l ) \gamma_j=(s_j-m-\sum_{l
最后,分段逻辑增长函数可以写为:
g ( t ) = C ( t ) 1 + e x p ( − ( k + a t → ′ ⋅ δ → ) ) ⋅ ( t − ( m + a t → ′ ⋅ γ → ) ) (3) g(t)=\frac{C(t)}{1+exp(-(k+\overrightarrow {a_t}'·\overrightarrow{\delta}))·(t-(m+\overrightarrow {a_t}'·\overrightarrow{\gamma}))} \tag{3} g(t)=1+exp(−(k+at′⋅δ))⋅(t−(m+at′⋅γ))C(t)(3)
模型的另一组重要的参数是 C ( t ) C(t) C(t), C ( t ) C(t) C(t)表示在时刻 t t t的模型承载力,也就是增长曲线的极大值。分析师通常对市场可达到的最大值有一定的了解,可以设定不同时期的承载力。 也可以根据其他数据来推断承载能力,例如世界银行的人口预测。
这里介绍的逻辑增长模型是广义逻辑增长的一个特例,它只是S型曲线的一种。 将此趋势模型扩展到其他曲线族也很简单。
3.1.2 Linear Trend with Changepoints
为了预测不会出现饱和增长的问题,分段的恒定增长率模型提供了一个简化且常用的模型。 这里的趋势模型可以写为:
g ( t ) = ( k + a t → ′ ⋅ δ → ) ⋅ t + ( m + a t → ′ ⋅ γ → ) (4) g(t)=(k+\overrightarrow {a_t}'·\overrightarrow{\delta})·t+(m+\overrightarrow {a_t}'·\overrightarrow{\gamma}) \tag{4} g(t)=(k+at′⋅δ)⋅t+(m+at′⋅γ)(4)
其中 k k k是增长率, δ → \overrightarrow{\delta} δ是增长率调整量, γ j = − S j ⋅ δ j \gamma_j=-S_j·\delta_j γj=−Sj⋅δj, γ → \overrightarrow{\gamma} γ的作用也是为了曲线更平滑;
下面给出一个例子:已知时间序列长度为10,其中在 t = 5 t=5 t=5和 t = 7 t=7 t=7处产生了结构突变,增长率分别增加了0.3和0.45,即 S 1 = 5 , S 2 = 7 , δ → = [ 0.3 , 0.45 ] ′ S_1=5,S_2=7,\overrightarrow {\delta}=[0.3,0.45]' S1=5,S2=7,δ=[0.3,0.45]′,增长率 k k k的初始值为0.5,截距 m m m的初始值为0.02,求 γ → \overrightarrow {\gamma} γ、未修正的 g ( t ) g(t) g(t)和修正后的 g ( t ) g(t) g(t).
γ → = [ − S 1 , − S 2 ] . ∗ δ → = − [ 5 , 7 ] ′ . ∗ [ 0.3 , 0.45 ] ′ = [ − 1.5 , − 3.15 ] ′ \overrightarrow{\gamma}=[-S_1,-S_2].*\overrightarrow {\delta}=-[5,7]'.*[0.3,0.45]'=[-1.5,-3.15]' γ=[−S1,−S2].∗δ=−[5,7]′.∗[0.3,0.45]′=[−1.5,−3.15]′;
n o t _ a d j u s t _ g ( t ) = ( k + a t → ′ ⋅ δ → ) ⋅ t + m not\_adjust\_g(t)=(k+ \overrightarrow {a_t}'·\overrightarrow{\delta})·t+m not_adjust_g(t)=(k+at′⋅δ)⋅t+m
a d j u s t _ g ( t ) adjust\_g(t) adjust_g(t)按(4)式计算,则计算结果如下表所示:
| t | a 1 ( t ) a_1(t) a1(t) | a 2 ( t ) a_2(t) a2(t) | a t → ′ ⋅ δ → \overrightarrow {a_t}'·\overrightarrow{\delta} at′⋅δ | a t → ′ ⋅ γ → \overrightarrow {a_t}'·\overrightarrow{\gamma} at′⋅γ | n o t _ a d j u s t _ g ( t ) not\_adjust\_g(t) not_adjust_g(t) | a d j u s t _ g ( t ) adjust\_g(t) adjust_g(t) |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0.52 | 0.52 |
| 2 | 0 | 0 | 0 | 0 | 1.02 | 1.02 |
| 3 | 0 | 0 | 0 | 0 | 1.52 | 1.52 |
| 4 | 0 | 0 | 0 | 0 | 2.02 | 2.02 |
| 5 | 1 | 0 | 0.3 | -1.5 | 4.02 | 2.52 |
| 6 | 1 | 0 | 0.3 | -1.5 | 4.82 | 3.32 |
| 7 | 1 | 1 | 0.75 | -4.65 | 8.77 | 4.12 |
| 8 | 1 | 1 | 0.75 | -4.65 | 10.02 | 5.37 |
| 9 | 1 | 1 | 0.75 | -4.65 | 11.27 | 6.62 |
| 10 | 1 | 1 | 0.75 | -4.65 | 12.52 | 7.87 |

3.1.3 Automatic Changepoint Selection
自动的选择突变点
突变点 S j S_j Sj可以由分析师指定,或者可以根据一组可能的点进行自动选择。通过指定 δ \delta δ的先验分布,可以很自然的根据公式(3)和(4)选出突变点;
我们通常会指定大量的突变点(例如,若干年的每一个月设置一个突变点),并使用先验分布: δ j 〜 L a p l a c e ( 0 ; τ ) δ_j〜Laplace(0;\tau) δj〜Laplace(0;τ)。 参数 τ \tau τ直接灵活的控制模型增长率的变化。 重要的是,稀疏的 δ δ δ对初始增长率 k k k没有影响,所以当 τ \tau τ为0时,模型退化为标准的皮尔曲线或线性增长曲线。
3.1.4 Trend Forecast Uncertainty
趋势预测的不确定性
(译者:文章中用到了一个缩写符号w. p. = with probability)
当用模型从历史数据外推预测时,模型将采用固定增长率。那么未来的预测就是一个确定性的点预测,怎么才能获取一个未来预测的概率分布呢, 我们通过扩展趋势的一般化模型估计预测趋势中的不确定性。 对时间序列中的趋势建模,通用模型如本文中所给的两个模型,都是假设长度为 T T T的时间序列历史数据中有S个突变点,每个突变点增长率的变化量都是一个服从Laplace分布的随机变量,即 δ j 〜 L a p l a c e ( 0 ; τ ) δ_j〜Laplace(0;\tau) δj〜Laplace(0;τ)。我们通过将 τ τ τ替换为从(现有)数据推断出的方差应用到过去的数据中来模拟变化率,从而得到将来的变化率。(We simulate future rate changes that emulate those of the past by replacing τ with a variance inferred from data. ),要做这个事情,完全可以在贝叶斯框架中,给定 τ \tau τ的先验分布,得到其后验分布,从而完成对 δ \delta δ的采样;否则话,我们可以用 λ \lambda λ的极大似然估计值:
λ = 1 S ∑ j = 1 S ∣ δ j ∣ \lambda= \frac{1}{S}\sum_{j=1}^{S}|\delta_j| λ=S1j=1∑S∣δj∣
未来的拐点随机出现,且分布与历史上拐点出现的频率一致,具体拐点的采样分布函数如下:
∀ j > T , { δ j = 0 w . p . T − S S , δ j ∼ L a p l a c e ( 0 , λ ) w . p . T S . \forall j>T,\begin{cases} \delta_j=0 w.p. \frac{T-S}{S},\\ \delta_j\sim Laplace(0,λ) w.p. \frac{T}{S}. \end{cases} ∀j>T,{ δj=0w.p.ST−S,δj∼Laplace(0,λ)w.p.ST.
因此,我们通过假设未来将看到与历史上出现次数同频率和大小的增速变化值。一旦获取到 λ \lambda λ的估计值,就可以利用上述对趋势的建模来模拟可能的未来趋势并且可以得到趋势的预测区间。
趋势增速的变化假设和历史同分布是一个比较强的假设,因此我们不期望预测区间有较高的精度。但是预测区间起码能说明预测的不确定性程度,尤其是可以从中看出是否过拟合。因为随着 τ \tau τ越大,拟合误差越小,然而,当做样本外预测时,这种增加变量的方法将导致更大的预测不确定性;
3.2 Seasonality
季节效应
构造一个周期函数,这个周期函数的自变量是时间 t t t,假设循环成分为 s ( t ) s(t) s(t),P = 365:25 for yearly data or P = 7 for weekly data,其傅里叶变换为:
s ( t ) = ∑ n = 1 N ( a n c o s ( 2 π n t P ) + b n s i n ( 2 π b t P ) ) s(t)=\sum_{n=1}^{N}{(a_ncos(\frac{2\pi nt}{P})+b_nsin(\frac{2\pi bt}{P}))} s(t)=n=1∑N(ancos(P2πnt)+bnsin(P2πbt))
估计循环成分,需要 2 N 2N 2N个参数: β = [ a 1 , b 1 , . . . , a N , b N ] T \beta=[a_1,b_1,...,a_N,b_N]^T β=[a1,b1,...,aN,bN]T,把傅里叶变换的基函数写作一个向量,那么傅里叶变换可以写作两个向量的点乘,这里给个例子,假设给定20个基函数(10个 c o s cos cos,10个 s i n sin sin),假设时间序列的周期为1年(即365天),则基函数向量可以写成如下行向量:
X ( t ) → = [ c o s ( 2 π ( 1 ) t 365 ) , . . . , s i n ( 2 π ( 10 ) t 365 ) ] \overrightarrow{X(t)}=[cos(\frac{2\pi(1)t}{365}),...,sin(\frac{2\pi(10)t}{365})] X(t)=[cos(3652π(1)t),...,sin(3652π(10)t)]
则季节循环成分可以写为:
s ( t ) = X ( t ) → ⋅ β → s(t)=\overrightarrow{X(t)}·\overrightarrow{\beta} s(t)=X(t)⋅β
文章中假设 β ∼ N o r m a l ( 0 , σ 2 ) β ∼ Normal(0, σ^2) β∼Normal(0,σ2) ,目的是给出季节性成分一个平滑的先验分布;
3.3 Holidays and Events
节假日和事件
假期和一些事件会给许多业务的时间序列预测带来了巨大的,可预测的冲击,并且通常不遵循周期性模式,即这些节假日出现的日期并不是间隔相同的日期,不是标准的周期性运动,因此,其效果不能通过平稳的周期很好地建模。 例如,美国的感恩节发生在11月的第四个星期四。 超级碗是美国最大的电视转播赛事之一,发生在1月或2月的星期日,因此很难通过编程方式宣布。世界上许多国家/地区都有农历假期。 特定假期对时间序列的影响通常年复一年,因此将其纳入预测很重要。
我们允许分析员提供过去和未来事件的自定义列表,由事件或假日的唯一名称标识,如表1所示。我们为country列了一个列,以便在全球假日之外保留一个针对特定国家的假日列表。对于给定的预测问题,我们结合了全球假日集和特定国家假日集。
通过假设假日的影响是独立的,将上述列表中的节假日并入到模型中是很简单的。对于每个假期 i i i,设 D i D_i Di作为该假期的过去和未来日期的集合,即 D i {D_i} Di包含了节假日 i i i的所有日期或受影响日期;对于具体某个时刻 t t t,用一个指数函数来表示该时刻是否属于某个节假日,并且给定一个参数 k i k_i ki来表示第 i i i个节假日的影响效应,就好季节效应一样,这里构造一个回归矩阵来实现这种来估计这些参数:
Z ( t ) = [ 1 ( t ∈ D 1 ) . . . 1 ( t ∈ D L ) ] Z(t) = [1(t \in D_1)... 1(t \in D_L)] Z(t)=[1(t∈D1)...1(t∈DL)]
构造的回归矩阵:
h ( t ) = Z ( t ) κ → (7) h(t) = Z(t)\overrightarrow{κ} \tag{7} h(t)=Z(t)κ(7)
跟季节效应类似, 假设 k k k的先验分布: κ ∼ N o r m a l ( 0 , ν 2 ) κ \sim Normal(0, ν^2) κ∼Normal(0,ν2).
译者注:其实就是引入了虚拟变量来估计节假日和事件型的影响;这里举一个例子说明模型如何引入节假日的,作者把每一时刻按是否是节假日进行分类,然后以一个one_hot编码的形式把节假日表示出来,以国内的节假日为例,假设只研究春节和国庆,如果给定一年的日度数据,那么每一天是否是节假日,是哪个节假日,可以用一个数字来表示,比如,不是节假日标注为0,是春节,标准为1,是国庆,标注为2,然后对这个时间序列做一个one hot编码,就得到了没个时刻的节假日表示;
| 日期 | 节假日类型 |
|---|---|
| 2020-02-22 | 0 |
| 2020-02-23 | 0 |
| 2020-02-24 | 1 |
| 2020-02-25 | 1 |
| 2020-10-01 | 2 |
| 2020-10-02 | 2 |
one hot编码为:
| 日期 | 非节假日 | 春节 | 国庆节 |
|---|---|---|---|
| 2020-02-22 | 1 | 0 | 0 |
| 2020-02-23 | 1 | 0 | 0 |
| 2020-02-24 | 0 | 1 | 0 |
| 2020-02-25 | 0 | 1 | 0 |
| 2020-10-01 | 0 | 0 | 1 |
| 2020-10-02 | 0 | 0 | 1 |
节假日的影响往往不仅仅就是节假日的那几天,可能节假日的前后一段事件都会受到影响。为了说明这一点,因此设置了一个参数,用于表示节假日影响范围的。
译者总结:
-
将时间序列采取加法模型分解为趋势+周期+事件影响+随机干扰,时间序列的分解方法,最常规的就是加法模型和乘法模型,prophet仅支持加法模型,在有些场景是必须对数据做变换,才可以利用加法分解模型;这里要说道说道加法模型和乘法模型的区别:
加法模型: y t = T t + C t + H o l i d a y t y_t=T_t+C_t+Holiday_t yt=Tt+Ct+Holidayt
乘法模型: y t = T t ∗ C t ∗ H o l i d a y t y_t=T_t*C_t*Holiday_t yt=Tt∗Ct∗Holidayt
对于乘法模型,所代表的物理意义是表示增长率可以分解为加法模型,为了说明,这里假设所涉及的数据都是非负,且只考虑趋势和循环成分:
y t = T t ∗ C t y t − 1 = T t − 1 ∗ C t − 1 ⇒ l o g y t = l o g T t + l o g C t ⇒ l o g y t − 1 = l o g T t − 1 + l o g C t − 1 ⇒ l o g y t − l o g y t − 1 = l o g T t − l o g T t − 1 + l o g C t − l o g C t − 1 ⇒ l o g y t y t − 1 = l o g T t T t − 1 + l o g C t C t − 1 y_t=T_t*C_t\\ y_{t-1}=T_{t-1}*C_{t-1}\\ \Rightarrow logy_t=logT_t+logC_t\\ \Rightarrow logy_{t-1}=logT_{t-1}+logC_{t-1}\\ \Rightarrow logy_t- logy_{t-1}=logT_t-logT_{t-1}+logC_t-logC_{t-1} \Rightarrow log \frac{y_t}{y_{t-1}}=log\frac{T_t}{T_{t-1}}+log\frac{C_t}{C_{t-1}} yt=Tt∗Ctyt−1=Tt−1∗Ct−1⇒logyt=logTt+logCt⇒logyt−1=logTt−1+logCt−1⇒logyt−logyt−1=logTt−logTt−1+logCt−logCt−1⇒logyt−1yt=logTt−1Tt+logCt−1Ct
即对数增长率可以分解为各成分的对数增长率之和,这个就是乘法模型的物理意义。 -
趋势构造了两个趋势表示方式,一个是皮尔生长曲线(logistic),一个是时间 t t t线性函数,并允许加入结构突变,目前结构突变只允许发生在增长率变量上,即logistic的增长率,和线性回归的斜率项,结构突变其实也可以发生在其他变量上,但要有对应的物理意义;
-
节假日效应作者用了一个虚拟变量来表示,且假设节假日的影响是一个常量,这个往往不符合现实,比如,国庆假,那10月1日的客流量和10月3日以及10月7日的效应其实是不一样的,即相同的节假日,对每一天的影响其实效应都有可能不同,这里作者直接假设为常数,合理性有待商榷;
-
文中的季节效应作者假设了是固定周期的效应,其实在现实中很对场景都是变频的,比如生产活动,在淡季时,可能是两周调休一次,而在旺季中,有可能是一周调休一次,如果预测生产或者与生产有关的变量时,固定频率就不合适;
-
在估计趋势成分时,作者对模型做了调整,以使得模型continue,这里不知道有没有必要,如果作者的求参算法是迭代法,用到了微分,那么要求函数平滑是合理的,但如果用的是随机抽样法,就对连续性和可微性没有要求;
3.4 Model Fitting
模型拟合
用矩阵 A A A表示趋势成分的增长率突变量,利用 Stan code 可以将模型简单的写出,并且利用 Stan’s L-BFGS 算法,可以求出最大后验估计,也可以估计出参数的后验分布后,预测时考虑这些参数的后验分布,从而获取预测值的分布;如下代码是求参时的模型设置:
m o d e l { / / P r i o r s : k ∼ n o r m a l ( 0 , 5 ) ; m ∼ n o r m a l ( 0 , 5 ) ; e p s i l o n ∼ n o r m a l ( 0 , 0.5 ) ; d e l t a ∼ d o u b l e _ e x p o n e n t i a l ( 0 , t a u ) ; b e t a ∼ n o r m a l ( 0 , s i g m a ) ; / / L o g i s t i c l i k e l i h o o d : y ∼ n o r m a l ( C . / ( 1 + e x p ( − ( k + A ∗ d e l t a ) . ∗ ( t − ( m + A ∗ g a m m a ) ) ) ) + X ∗ b e t a , e p s i l o n ) ; / / L i n e a r l i k e l i h o o d : y ∼ n o r m a l ( ( k + A ∗ d e l t a ) . ∗ t + ( m + A ∗ g a m m a ) + X ∗ b e t a , s i g m a ) ; } model\{\\ // Priors: \\ k ∼ normal(0, 5) ; \\ m ∼ normal(0, 5) ; \\ epsilon ∼ normal(0, 0.5) ;\\ delta ∼ double\_exponential(0, tau); \\ beta ∼ normal(0, sigma);\\ //Logistic \ likelihood:\\ \ y ∼ normal(C ./ (1 + exp(-(k + A * delta) .* (t - (m + A * gamma)))) + X * beta, epsilon);\\ // Linear \ likelihood:\\ y ∼ normal((k + A * delta) .* t + (m + A * gamma) + X * beta, sigma); \} model{ //Priors:k∼normal(0,5);m∼normal(0,5);epsilon∼normal(0,0.5);delta∼double_exponential(0,tau);beta∼normal(0,sigma);//Logistic likelihood: y∼normal(C./(1+exp(−(k+A∗delta).∗(t−(m+A∗gamma))))+X∗beta,epsilon);//Linear likelihood:y∼normal((k+A∗delta).∗t+(m+A∗gamma)+X∗beta,sigma);}
我们利用正则化来控制列表1中的参数 τ \tau τ和 σ \sigma σ,用于防止过拟合,但是可能没有足够的历史数据来通过交叉验证选择最佳正则化参数。 正则化参数给出了默认值,这组默认值适用于大部分场景,同时,也允许模型开发者参与到参数优化中来。
3.5 Analyst-in-the-Loop Modeling
分析师如何建模
做预测的分析师通常对他们所预测的数量有广泛的领域知识,但统计知识有限。在Prophet模型规范中,有几个地方分析师可以更改模型以应用他们的专业知识和外部知识,而不需要了解任何底层统计数据。
- 承载力:分析师拥有相关领域的知识,知道要预测的标的的极大值/极小值。
- 突变点:可以直接指定变更点的日期,如产品变更日期。
- 节假日和季节性:分析师根据经验,指定哪些节假日有影响,他们可以直接输入相关的节假日所在的日期和周期长度。
- 平滑参数:通过调整 τ τ τ,分析员可以从一系列不同趋势增长模型中进行选择,比如是否包含突变点,突变点的个数等。季节性和假日平滑参数 ( σ , ν ) (σ,ν) (σ,ν)允许分析人员告诉模型未来的历史季节变化。
有了良好的可视化工具,分析师可以使用这些参数来改进模型。当在历史数据上绘制模型模型的预测和真实值对比时,很快就可以看出是否遗漏了结构突变点。 τ τ τ参数是一个参数,可以用来增加或减少趋势灵活性,而 σ σ σ是另一个参数,用来增加或减少季节性成分的强度。可视化为高效的人为调整模型提供了许多其他机会:是线性趋势或逻辑增长,识别季节性的周期长度,以及是否应该异常一些异常点。所有这些干预措施都可以在没有统计专业知识的情况下进行,是分析师应用其个人见解或其专业知识的重要方法。
预测文献通常将数据挖掘而做出来的模型与人类专家使用其所学的任何过程产生的判断预测(也称为管理预测)区分开来,后者往往适用于特定的时间序列。每种方法都有其优点。统计预测(数据挖掘)需要较少的领域知识和来自人类预测者的努力,而且它们可以很容易地扩展到许多预测。判断性预测可以包含更多信息,并对不断变化的条件作出更大的反应,但可能需要分析师的密集工作(Sanders 2005)。
我们提供的分析师循环建模法(analyst-in-the-loop) ,提供了一种建模的替代方法,它试图通过在必要时集中分析员的精力改进模型,而不是关注统计模型上,用于融合统计模型和分析师的经验判断。我们发现我们的方法与循环的"transform-visualize model" (Wickham&Grolemund(2016)提出)非常相似,其中人类的知识在经过多次模型的迭代改进后,融合到了模型之中。
大规模的预测依赖于自动化,但判断性预测在许多应用中显示出很高的准确性(Lawrence et al。2006年)。我们提出的方法允许分析师通过一小部分直观的模型参数和选项对预测进行判断,同时保留在必要时依靠全自动统计预测的能力。在撰写本文时,我们只有一些经验性的证据可以证明准确度可能有所提高,但我们期待着未来的研究能够评估出分析师在提升模型精度的作用。
大规模的“anylyst-in-the-loop”能力在很大程度上取决于对预测质量的自动评估和良好的可视化工具。现在,我们将介绍如何自动的进行预测评估,以识别与分析师输入最相关的预测。
4 Automating Evaluation of Forecasts
自动评估预测精度
4.1 Use of Baseline Forecasts
使用基准模型预测作为对照
评价预测方法时,与一组基准模型做比较是一个重要的方法。我们更喜欢使用简单的预测方法,这些模型可以对数据做出比较强的假设,但在对未来的预测时会更加合理。我们发现了最简单的模型往往比较有用(例如最后时刻的值和样本平均值作为预测)和第2节所述的其他预测方法。
4.2 Modeling Forecast Accuracy
模型的预测精度
预测是在一定的时间范围内进行的,我们称之为 H H H。我们关注的是对未来一段时间的预测,我们的预测场景往往是对未来30天,90天、180天或者365天做预测。因此,对于任何有每日观测的预报,我们可以得到日度预测值,与之而来的是每个预测点的误差。我们需要定义一个衡量预测误差的指标。另外,清楚模型在预测过程中精确度,则在实际业务中,就知道是否可以相信模型的预测值。
设 y ^ ( t ∣ T ) \hat{y}(t|T) y^(t∣T)表示基于截止到T时刻的信息,对 t t t时刻做出的预测,预测值和真实值的差距用 d ( y , y ′ ) d(y,y') d(y,y′)表示,其中, y y y表示真实值, y ′ y' y′表示预测值,常用的评价指标有mae,mse,mape等,假设未来预测的最大长度为H,历史样本的最大时间为T,则定义预测精度:
φ ( T , h ) = d ( y ^ ( T + h ∣ T ) , y ( T + h ) ) h ∈ [ 1 , H ] φ(T,h) = d(\hat{y}(T + h|T),y(T + h))\\ h \in [1,H] φ(T,h)=d(y^(T+h∣T),y(T+h))h∈[1,H]
为了研究预测精度随着对未来预测日期长度 h h h的变化,需要对误差项进行建模,这里对误差建立ARMA模型,ARIMA的参数采取1阶自回归模型,即:
y ( t ) = α + β ( t − 1 ) + v ( t ) v ( t ) ∼ N o r m a l ( 0 , σ v 2 ) y(t)=\alpha+\beta(t-1)+v(t)\\ v(t)\sim Normal(0,\sigma_v^2) y(t)=α+β(t−1)+v(t)v(t)∼Normal(0,σv2)
参数 σ v 2 \sigma_v^2 σv2可以通过历史数据估计出来。然而这种方法必须把模型的形式设置正确,否则误差估计是不对的,但是在实践中往往很难保证模型的设置是正确的。
我们倾向于采取非参数发估计期望的预测误差,这适用于各种模型。这种方法类似于采取交叉验证对独立的样本进行样本外的预测,然后估计样本外的误差分布,每一个预测步长 h h h都对应一系列的预测误差,因此,可以取误差期望作为该预测步长的预测精度:
ξ ( h ) = E [ φ ( T , h ) ] (8) \xi(h) = E[φ(T, h)] \tag{8} ξ(h)=E[φ(T,h)](8)
这个模型很灵活,但是可以强加一些简单的假设。首先,假设误差函数关于 h h h连续,因为我们期望在日期相近的时间里,预测误差也尽量的相似;其次,假设误差函数随着预步长 h h h的增加而增加(但不是严格递增),在实践操作中,我们选择了如下非线性回归来拟合误差曲线:局部线性回归?(a local regression (Cleveland & Devlin 1988)) 或者 保序回归isotonic regression (Dykstra 1981) as flexible non-parametric models of error curves。
为了产生历史预测误差来估计这个模型,我们使用了一个我们称之为仿真历史预测(simulated historical forecasts)的程序。
4.3 Simulated Historical Forecasts
仿真的历史预测
我们希望拟合公式(8)中的预期误差模型,以便做模型选择和评估。不幸的是,很难使用交叉验证,因为时间序列的时序特性,决定了观测值是不可交换的,我们不能简单地随机划分数据。
我们使用模拟历史预测(SHFs),在历史的不同截止时间点生成 K K K个预测,预测的时间点是在历史数据内,因此可以评估总误差。该思路来源于经典的“滚动原点”(rolling origin,请参见附件1的说明)预测评估法(Tashman 2000),但仅使用一小截日期序列(一部分历史数据),而不是对每个历史日期都做预测。使用较少模拟日期的主要优点(rolling origin法每个日期都会产生一个预测)是因为它可以节省计算时间,同时,给出的精度相关性较低。
如果我们在过去的这些时间点使用这种预测方法,SHF会模拟我们在预测时会犯的错误。如图3和图4中SHF的示例。这种方法的优点是简单,易于向分析师和决策者解释,并且对于生成对预测误差的洞察力而言也相对没有争议。使用SHF方法评估和比较不同的预测模型时,要注意两个主要问题。
首先,我们做出的模拟预测越多,他们的误差估计就越相关。这里考虑一种极端情况,即每天都做模拟预测,鉴于每天增加的信息量,预测不太可能发生太大变化,而且从一天到第二天的误差几乎相同。另一方面,如果我们进行的模拟预测很少,那么对历史预测误差的观察就更少了,根据我们的模型选择作为一种启发式方法,对于预测范围H,我们通常每 H / 2 H/2 H/2 个周期进行一次模拟预测。尽管误差测相关性不会对我们对模型准确性的估计带来偏差,但这样做也没什么益处,并且还需浪费时间来计算。
译者注:作者根据时间序列的历史数据构造了一个移动时间窗,这个移动时间窗包含两部分内容,前部分是train集,后部分是test集,train集用于训练模型,test集用于测试模型,那么这个时间窗的移动步长也是一个参数(cutoff的间隔),所以这段内容作者在讲述如何设置这个时间窗的移动步长,如果移动步长太小,假设极端情况下,每一个时间点,移动一次,那么这两次做出来的样本外误差是高度相关的,作者认为尽管相关性不会造成预测精度的估计偏差,但是会浪费计算时间,因此,作者建议时间窗的移动步长要大一点,但是过大了,会导致时间窗的个数减少,可用于分析的样本外误差数据就少了,因此,这里他们建议时间窗的移动步长应该是样本外预测长度的一半,假设未来做100天的预测,那么时间窗的移动步长应该设置为50
其次,有了更多的数据,预测方法就可以做得更好或更差。当模型设定不正确或过拟合时,历史样本越多,误差越大,例如使用样本均值来预测含有趋势增长的时间序列。图7显示了我们对函数 ξ ( h ) ξ(h) ξ(h)的估计,即用局部回归法,给出的图3和图4中的时间序列,在整个预测期间的预期平均绝对百分比误差(mape); 误差估计是使用9个模拟的预测日期进行的,从第一年开始每季度做一次。prophet在所有预测范围内的预测误差都较低。prophet模型参数用的是默认值,调参可能会进一步提高预测精度。
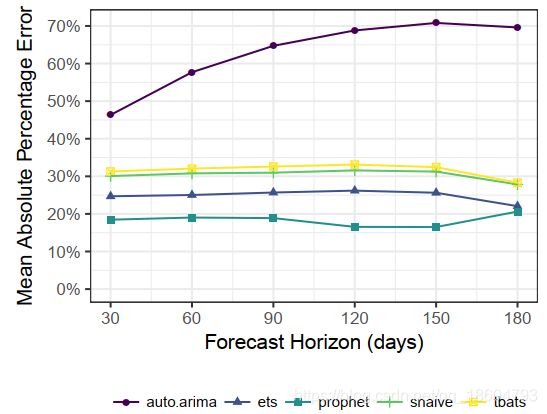
在可视化预测时,我们更喜欢使用点而不是直线来表示历史数据,因为这些数据代表了非插值的预测误差。然后,我们用线把每个预测误差连接起来。 对于SHF,可视化可以帮助找出哪些模型在哪些长度的预测误差比较大,既可以是时间序列(如图3所示),也可以在SHF上汇总(如图7所示)。
4.4 Identifying Large Forecast Errors
识别较大的预测误差
当分析师的预测太多而无法手动检查每个预测时,重要的是能够自动识别可能有问题的预测。自动识别不良预测可以使分析师最有效地利用有限的时间,并利用他们的专业知识来纠正问题。 SHF可以通过多种方式用于找出预测中可能存在的问题。
- 当预测相对于基线有较大误差时,可能是因为模型设置错误。分析师可以需要调整趋势模型或季节性模型。
- 当所有的预测值对特定日期预测误差都很大时,表示这一天可能是离群值。分析师可以识别异常值并将其删除。
- 当某方法的SHF误差从一个水平急剧增加到另一个水平时,可能表明数据的生成过程已发生改变。添加结构突变点或分别为不同的阶段建模。
有些病态的预测问题无法轻易纠正,但是我们遇到的大多数问题都是可以通过指定结构突变点以及除去异常值来纠正的。一旦该预测值被标记,就可以用于审核和可视化展示,那么这些问题就很容易识别和纠正。
5 Conclusion
结论
大规模预测的一个主要问题是,不同知识背景的分析师要做的预测场景可能远远超过其手动可以做的范围。我们预测系统的第一部分是我们通过对Facebook上的各种数据进行多次迭代开发而形成的建模框架。我们使用了一个简单的模块化回归模型,该模型通常可以在给定默认参数情况下表现很好,并且允许分析师选择与其预测问题相关的组件,并根据需要轻松的进行调整。第二个部分是计算预测误差与跟踪系统,让分析师可以找出 那些应该手动检查的预测值,帮助提升模型预测预测精度。这很关键,该组件使分析人员能够确定何时需要对模型进行调整,或者什么时候应该使用完全不同的模型。并且,一个操作简单、可调整的模型和可扩展的精度监控体系相结合,使大量分析人员能够预测大量不同的时间序列(也即我们定义的大规模预测)。
References
Byrd, R. H., Lu, P. & Nocedal, J. (1995), ‘A limited memory algorithm for bound constrained optimization’, SIAM Journal on Scientific and Statistical Computing 16(5), 1190–1208.
Carpenter, B., Gelman, A., Hoffman, M., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M. A., Guo, J., Li, P. & Riddell, A. (2017), ‘Stan: A probabilistic programming language’, Journal of Statistical Software 76(1).
Chang, W., Cheng, J., Allaire, J., Xie, Y. & McPherson, J. (2015), shiny: Web Application
Framework for R. R package version 0.11.
URL: http://CRAN. R-project. org/package= shiny
Cleveland, W. S. & Devlin, S. J. (1988), ‘Locally weighted regression: an approach to regression analysis by local fitting’, Journal of the American Statistical Association 83(403), 596–610.
De Gooijer, J. G. & Hyndman, R. J. (2006), ‘25 years of time series forecasting’, International Journal of Forecasting 22(3), 443–473.
De Livera, A. M., Hyndman, R. J. & Snyder, R. D. (2011), ‘A state space framework for automatic forecasting using exponential smoothing methods’, Journal of the American Statistical Association 106(496), 1513–1527.
Dykstra, R. L. (1981), ‘An isotonic regression algorithm’, Journal of Statistical Planning and Inference 5(4), 355–363.
Gardner, E. S. (1985), ‘Exponential smoothing: the state of the art’, Journal of Forecasting
4, 1–28.
Harvey, A. C. & Shephard, N. (1993), Structural time series models, in G. Maddala, C. Rao & H. Vinod, eds, ‘Handbook of Statistics’, Vol. 11, Elsevier, chapter 10, pp. 261–302.
Harvey, A. & Peters, S. (1990), ‘Estimation procedures for structural time series models’, Journal of Forecasting 9, 89–108.
Hastie, T. & Tibshirani, R. (1987), ‘Generalized additive models: some applications’, Journal of the American Statistical Association 82(398), 371–386.
Hutchinson, G. E. (1978), ‘An introduction to population ecology’.
Hyndman, R. J., Khandakar, Y. et al. (2007), Automatic time series for forecasting: the forecast package for R, number 6/07, Monash University, Department of Econometrics
and Business Statistics.
Hyndman, R. J., Koehler, A. B., Snyder, R. D. & Grose, S. (2002), ‘A state space framework for automatic forecasting using exponential smoothing methods’, International Journal of Forecasting 18(3), 439–454.
Lawrence, M., Goodwin, P., O’Connor, M. & Onkal,¨ D. (2006), ‘Judgmental forecasting: a review of progress over the last 25 years’, International Journal of Forecasting 22(3), 493 – 518.
Sanders, N. (2005), ‘When and how should statistical forecasts be judgementally adjusted?’, Foresight 1(1), 5 – 7.
Tashman, L. J. (2000), ‘Out-of-sample tests of forecasting accuracy: an analysis and review’, International journal of forecasting 16(4), 437–450.
Tashman, L. J. & Leach, M. L. (1991), ‘Automatic forecasting software: a survey and
evaluation’, International Journal of Forecasting 7, 209–230.
Wickham, H. & Grolemund, G. (2016), ‘R for data science’.
附录1 R o l l i n g O r i g i n Rolling \ Origin Rolling Origin
当需要为数据选择最合适的预测模型或方法时,预测人员通常将可用样本分为两部分:样本内(也称为“训练集”)和保留样本(或样本外,或“测试集”)。然后用样本内数据对模型进行估计,并使用样本外的数据计算预测误差,从而达到评估模型预测性能的目的。
如果这样的程序仅执行一次,则称为“固定原点”评估。但是,时间序列可能包含异常值或水平移位,并且仅由于此原因,较差的模型可能会比更合适的模型表现更好。为了加强对模型的评估,使用了一种称为“滚动原点”的方法。
滚动原点是一种评估技术,根据该技术可以连续更新预测原点,并根据每个原点生成预测(Tashman 2000)。该技术可以获取时间序列的几个预测误差,从而更好地了解模型的性能。如何执行此操作有不同的选择。
H o w c a n t h i s b e d o n e ? How \ can \ this \ be \ done? How can this be done?
假设时间序列长度为25,初始样本内长度为15,即Origin=15,样本外预测长度为3,则Origin可以从15取到22,共形成8组样本内-样本外预测数据集,如下图,白色表示样本内,灰色表示样本外预测,可以理解对预测区间按一个时间窗进行滑动,滑动步长为1,其实滑动步长也可以作为一个参数;这样我们可以求8组样本的平均预测误差,来比较不同模型的平均预测误差,从而可以进行模型选择。
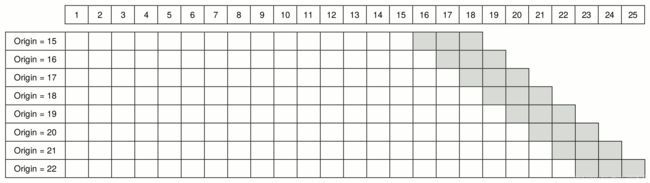
从8个子样本生成成预测的另一个选择是从第17个历史样本开始预测,而不是从原来第15个开始(见下图)。在这种情况下,该过程一直持续到时间点22,即生成前面最后三个步骤的预测,然后随着预测范围的减小而继续。因此,提前两步预测是从原点23产生的,而只有一步预测是从原点24产生的。结果得到8个一步预测、7个二步预测和6个三步预测。这可以被视为具有非恒定持留率样本大小的Rolling Origin。这在小样本的情况下非常有用,因为我们没有多余的观测数据。

最后,在上述两种情况下,我们都增加了样本内的数据量。然而,出于某些研究目的,我们可能需要保持样本内数据长度不变,比如就是需要用过去100个历史数据,预测未来10步。下图显示了这种情况。在这种情况下,在每次迭代中,我们在序列的末尾添加一个观测值,并从序列的开头删除一个观测值(深灰色单元格)。
