爬虫快速入门(二):动态页面抓取
上一篇文章简单介绍了静态网页的爬取,今天和大家分享一些动态网页爬取的技巧。什么是动态网页呢,举个很常见的例子,当我们在浏览网站时,随着不断向下滑动网页,当前页面会不断刷新出新的内容,但浏览器址栏上的URL却始终没有变化。这种由JavaScript动态生成的页面,当我们通过浏览器查看它的网页源代码时,往往找不到页面上显示的内容。
抓取动态页面有两种常用的方法,一是通过JavaScript逆向工程获取动态数据接口(真实的访问路径),另一种是利用selenium库模拟真实浏览器,获取JavaScript渲染后的内容。但selenium库用起来比较繁琐,抓取速度相对较慢,所以第一种方法日常使用较多。
在做JS逆向前,我们首先要学会用浏览器抓包。以Chrome 浏览器为例,打开网易新闻主页

右键查看网页源码与按F12打开开发者工具看到的源代码是不一样的,而且当我们下拉页面时,开发者工具中的源代码还在不断增加,这才是JS渲染后的源代码,也是当前网站显示内容的源代码。

如上图所示,抓包时主要使用Network这个选项卡,当按F5刷新页面后,下方的显示框中会出现很多包,我们可以用上方Filter栏对这些包进行归类。

这里主要使用XHR、JS这两类,例如选中XHR,点击过滤后的第一个包,显示界面如下,右侧会出现一排选项卡,其中Headers下包含当前包的请求消息头、响应消息头;Preview是对响应消息的预览,Response是服务器响应的代码。
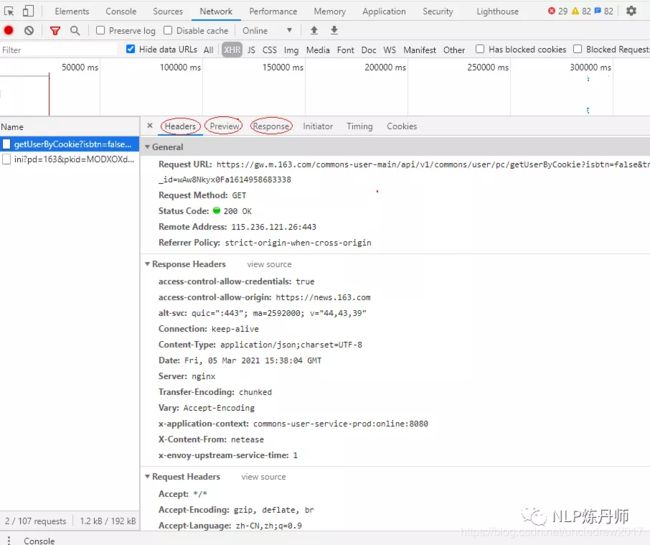
了解了这些之后,我们依次点击XHR、JS下的所有包,通过Preview来预览当前包的响应信息,寻找我们想要的结果。例如我们在下面这个包找到了文章列表,通过Headers找到了Request URL,这才是我们真正应该请求的路径。
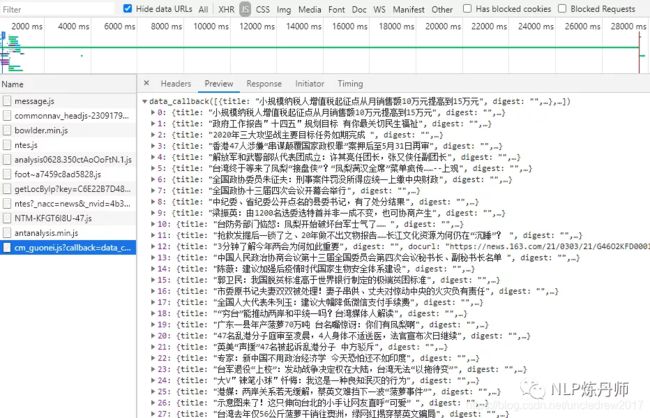

当翻滚页面时,发现JS下又多了下面这几个包以及新的Request URL,与之前的对比,可以很容易的找到一个通用的URL。分析到这,我们可以开始写代码了。
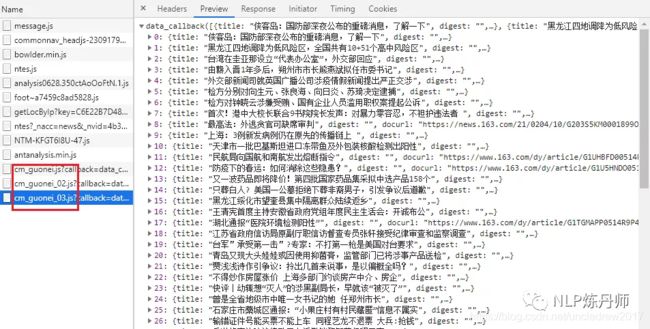
直接上代码
import requests
from bs4 import BeautifulSoup
import json
import re
import multiprocessing
import xlwt
import time
def netease_spider(headers, news_class, i):
if i == 1:
url = "https://temp.163.com/special/00804KVA/cm_{0}.js?callback=data_callback".format(news_class)
else:
url = 'https://temp.163.com/special/00804KVA/cm_{0}_0{1}.js?callback=data_callback'.format(news_class, str(i))
pages = []
try:
response = requests.get(url, headers=headers).text
except:
print("当前主页面爬取失败")
return
start = response.index('[')
end = response.index('])') + 1
data = json.loads(response[start:end])
try:
for item in data:
title = item['title']
docurl = item['docurl']
label = item['label']
source = item['source']
doc = requests.get(docurl, headers=headers).text
soup = BeautifulSoup(doc, 'lxml')
news = soup.find_all('div', class_='post_body')[0].text
news = re.sub('\s+', '', news).strip()
pages.append([title, label, source, news])
time.sleep(3)
except:
print("当前详情页面爬取失败")
pass
return pages
def run(news_class, nums):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36'}
tmp_result = []
for i in range(1, nums + 1):
tmp = netease_spider(headers, news_class, i)
if tmp:
tmp_result.append(tmp)
return tmp_result
if __name__ == '__main__':
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('网易新闻数据')
sheet.write(0, 0, '文章标题')
sheet.write(0, 1, '文章标签')
sheet.write(0, 2, '文章来源')
sheet.write(0, 3, '文章内容')
news_calsses = {
'guonei', 'guoji'}
nums = 3
index = 1
pool = multiprocessing.Pool(30)
for news_class in news_calsses:
result = pool.apply_async(run, (news_class, nums))
for pages in result.get():
for page in pages:
if page:
title, label, source, news = page
sheet.write(index, 0, title)
sheet.write(index, 1, label)
sheet.write(index, 2, source)
sheet.write(index, 3, news)
index += 1
pool.close()
pool.join()
print("共爬取{0}篇新闻".format(index))
book.save(u"网易新闻爬虫结果.xls")
这里爬取了国内和国际两个板块,每个板块取向下滚动3次的所有文章,并通过文章详情页的链接爬取文章内容,最终爬到了289篇文章。
需要注意的是爬取频率过快会导致访问失败,建议每爬取一次sleep会儿,另外亲测把线程数调大也很有用。有条件的可以加个ip代理池,之前用过免费的,基本上没几个能用的ip,还是得氪金啊。全部代码及数据已上传到github,链接在这里GitHub
本文同步于微信公众号“NLP炼丹师”,感兴趣的同学可扫码关注,获取更多内容。
