1 前言
Redis是一种基于健值对(key-value)的NoSql数据库,有String,set,hash,zset,list,GEO等多种数据结构和算法组成,redis采用的内存处理方式和多路复用的io模型使得单线程模型的redis结构还能保持很高的读写能力。因此在实际的项目开发中,redis的应用场景非常广泛。
Redis大多以集群的方式应用在各个项目中,在搭建redis分布式集群的时候首先要考虑的是如何将数据按照一定的区分规则映射到对应的节点上,每个节点的数据都是总数据的一部分,所有的节点合成一份总的数据,每个节点的数据相互独立,没有重复的数据。

分区的方式有很多种,如采用顺序分区的Hbase,好处就是数据是顺序的,并且分区的规则可以根据业务来指定;也有很多采用hash分区的,例如redis,好处就是离散性好。
文章主要讲解一下hsah分区的一些情况。先看下redis的分区规则。
2 Redis数据分区
Redis采用的是虚拟槽分区,redis规定了16383个整数槽,首先所有的健都会hash到对应的槽内。规定添加到redis集群的节点都负责其中的一部分槽点的数据。

其中k值采用CRC16(k)&16383的计算规则将键映射到对应的槽上。我们可以思考一下redis的分区规则有哪些特点;
首先,分区的规则是根据keys来进行映射,keys是一种用户行为,那么keys对应的分区,通俗来讲keys应该对应哪个redis 节点不再是程序应该考虑的事情,只需要按照映射规则来判断即可,分区跟业务进行解耦,在扩容的缩容操作的时候减少了数据的迁移;
另外,节点,槽点,keys之间存在了一种映射关系,可以很好的支持数据路由和在线收缩等使用场景;
而且redis的分区规则是内存的一个逻辑模块,不需要像原来的关系数据库使用外部挂件进行分区,例如mysql分区通常还会通过mycat进行操作。
2.1 Redis扩容和缩容操作
redis集群可以在保证对外服务不中断的情况进行灵活的扩容和缩容操作。前面一节讲到的redis数据分区规则,redis节点的数据是按照数据slot区分的,那么redis的扩容和缩容可以理解为数slot的切换和移动。
2.1.1 Redis增加扩容

在一个redis集群中添加一个新的节点,节点添加成功之后对新增节点分配槽点,其他节点将对应槽点的数据发送到新增节点上。此过程分为两个步骤:
准备新加入集群的节点,并将新的节点加入到集群中去;
为新节点分配槽点并且迁移槽和数据。
2.1.2 Redis减少扩容
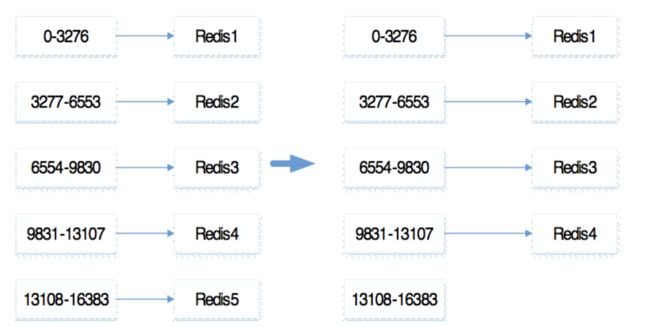
如图4所示,节点5下线,集群检测到节点5下线之后会进行减少扩容。首先是判断是否存在节点下线,如图5表示节点安全下线的流程图:
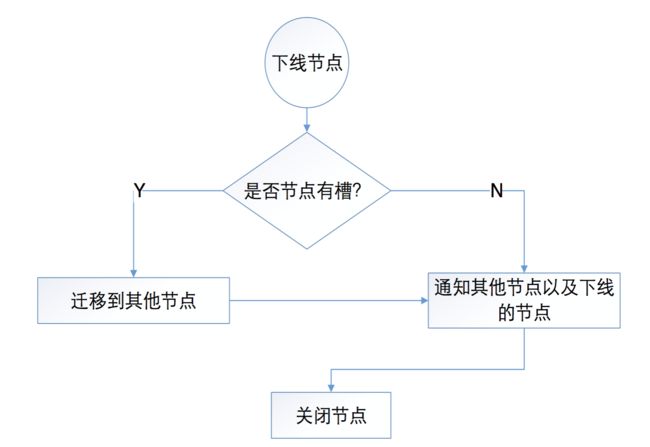
如图所示,关于节点下线的流程主要有两个条件,节点是否有槽,如果有槽则需要进行数据迁移,如果没有就直接下线。
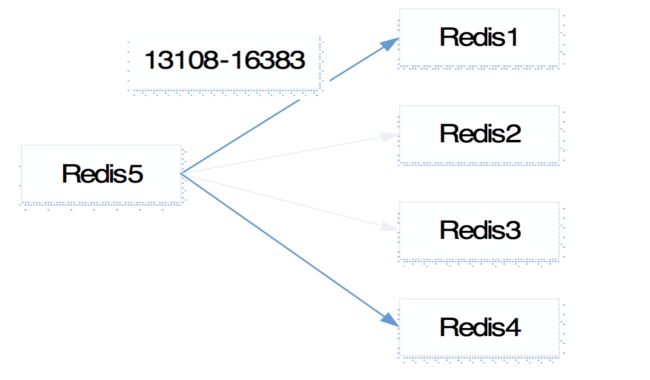
看下有槽的节点数据迁移是怎么样执行的,如图6所示,将redis5的节点数据分到其他节点上,数据迁移成功之后通知其他节点redis5这个节点下线。
3、一致性hash算法
3.1 Hash取模算法
hash取模算法是是跟据需要路由得到键值进行hash产生一个hsah数值,然后根据服务器的数量进行取模操作,例如我们是以uuid为唯一值来确定集群中的数据是唯一存在的,那么就可以对uuid进行hash操作,映射到对应的服务器上。
假设现在存在3台服务器,有10条数据分别是uuid1,uuid2…uuid10;那分别对这个10个数据进行hash得到的分别为{ 111641558,111641559,111641560,111641561,111641562,111641563,111641564,111641565,111641566,-834078950}
取模之后对应的数据:
Server1:uuid2,uuid5,uuid8
Server2:uuid1,uuid4,uuid7,uuid10
Server3:uuid3,uuid6,uuid9
当集群节点扩展到4个的时候对应的数据为:
Server1:uuid3,uuit7
Server2:uuid4,uuid8
Server3:uuid1,uuid5,uuid9,uuid10
Server4:uuid2,uuid6
上面存在的问题就是在进行节点伸缩操作的时候数据的改动比较大,数据出现大面积的迁移,成本太高。
3.2 一致性hash算法
一致性hash算法的根本思想就是对所有的数据进行一次hash运算,然后将映射到对应节点上去,映射条件为距离最近的节点,这样就可以保证集群再进行伸缩操作的时候影响的数据最小。
一致性hash还引入了一致性hash环的概念,如图7所示将hash节点分为2^32-1个区间的数据进行划分,我们按照顺时针的方向对数据进行映射,落在区域A中的数据映射到服务1,落到B区域的数据映射到服务2,落到C位置的数据映射到服务3。

图7中的数据映射方式存在这样一个问题:由于hash换的位置是固定的,那么A区域的范围明显比其他两个区域的范围要大,那么Server1的数据就有可能比其他的服务的数据量大得多,这个时候就会出现数据偏移。因此在一致性hash算法中还可以引入一种虚拟的节点,如图8所示,将hash环分为8个节点(假设业务是可以这样去切分,具体分区根据业务划分),分别为s1-s8,每个节之间的间隔是一样的,集群中有三台服务器节点,分别用node1-node3表示,落在s1-s3的数据规划到node1,落在s4-s6的数据规划到node2上,落在s7-s9的数规划到node3上。这样数据就可以相对均衡地落在的node1-3的节点上。

采用一致性hash算法之后的好处就是,单集群中需要添加新的节点,需要移动的数据就会变少,成本降低,另外在引入虚拟节点之后也解决了数据倾斜问题。
当然这种使用对hash算法得要求会比较高,要求hash之后的值尽可能离散,保证在实际的项目中不出现数据hash之后聚集的状态,例如1.3.1中我使用的是字符串的hsahcode出现了一个负值,我只是简答的对负值进行的取绝对值操作,这样导致一个节点会出现4个值。