Kettle 是一款基于Java开发的开源(Apache许可)的ETL工具,因其友好的许可、可视化的设计器、可扩展的插件机制,而被广泛使用
Elasticsearch是一款基于Apache Lucene 开发的开源(混合型许可Apache许可+ Elastic License)的搜索服务+存储引擎,对文本型大数据量的搜索的亮眼性能而被广泛使用
使用版本:
ElasticSearch 6.6.2+xpack 6.6.2(定制版)
Kettle 8.3.0.1 + Elasticsearch bulk insert (版本适配)
DB:mysql 5.6+
为什么选择Kettle
可视:代码不仅仅只是是用来执行的,还必须考虑可维护性,看着一坨一坨的代码,即使跑的很正常、注释写的再好,也不一定有人耐下心看,Kettle插件的天生模块化,把关注点进行了很好的分离
统一:所有人、所有实现是一致的,便于知识沉淀、便于知识的流淌
功能实现
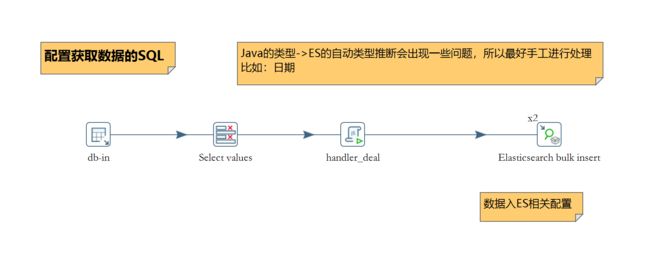
① 创建ES Mapping【可选】
Tips:使用手工创建Mapping,能够更好的兼容实际的数据、定制分词引擎或通过指定Keyword等来降低不必要的索引存储,Elasticsearch bulk insert 可以根据index名称进行检测,如果指定的名称不存在,则会创建Index
put http://es-ip:9200/zqcust-ges-party-test
{
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
}
},
"mappings": {
"doc": {
"properties": {
"RegistCapi": {
"type": "text"
},
"Status": {
"type": "keyword", "null_value": "NULL"
},
"BelongOrg": {
"type": "text"
},
"CreditCode": {
"type": "text"
},
"No": {
"type": "text"
},
"OperName": {
"type": "text"
},
"Address": {
"type": "text"
},
"EconKind": {
"type": "text"
},
"RegistCapiUnit": {
"type": "text"
},
"Province": {
"type": "text"
},
"TermStart": {
"type": "date"
},
"StartDate": {
"type": "date"
},
"TeamEnd": {
"type": "date"
},
"Scope": {
"type": "text","analyzer": "ik_max_word"
},
"company_name": {
"type": "text"
},
"PhoneNumber": {
"type": "text"
},
"CheckDate": {
"type": "date"
},
"ProvinceCode": {
"type": "text"
}
}
}
}
}
② 源数据获取
文档使用“Table input”通过JDBC从数据库获取源数据(Kettle支持几乎能想到的所有数据源类型)
需加载的数据表:
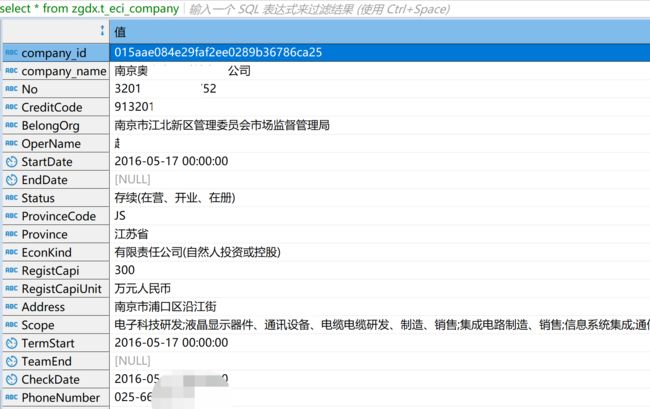
来条数据预览:
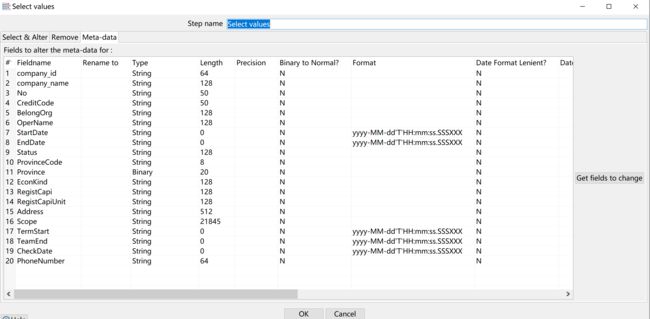
③ 字段类型处理
通过设置字段类型可以减少因类型转换而导致的异常
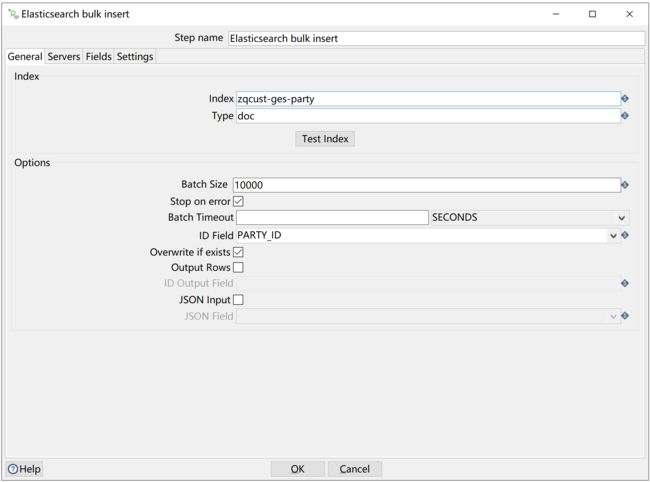
④ Elasticsearch bulk insert配置
配置index相关信息,如果指定的index不存在,则会新建:
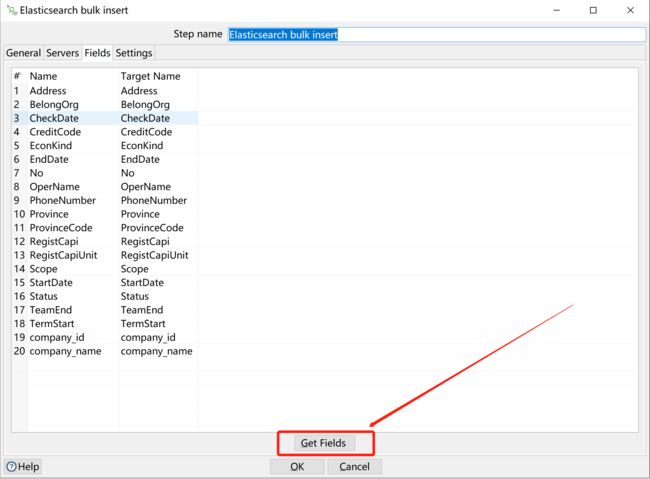
字段映射:
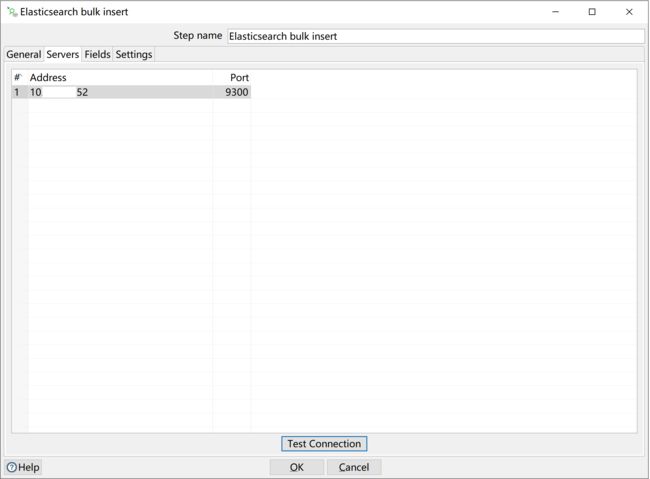
配置ES服务信息:
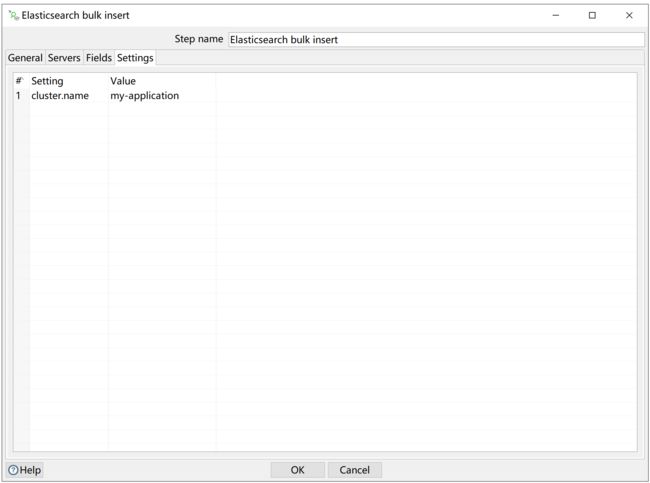
配置cluster.name:
使用证书验证的配置:
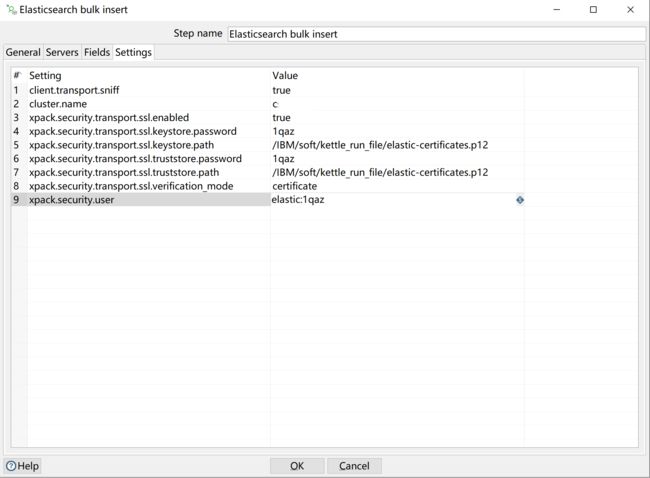
性能调整
JDBC性能参数
fetchSize 参数调整,参数效用参考附录
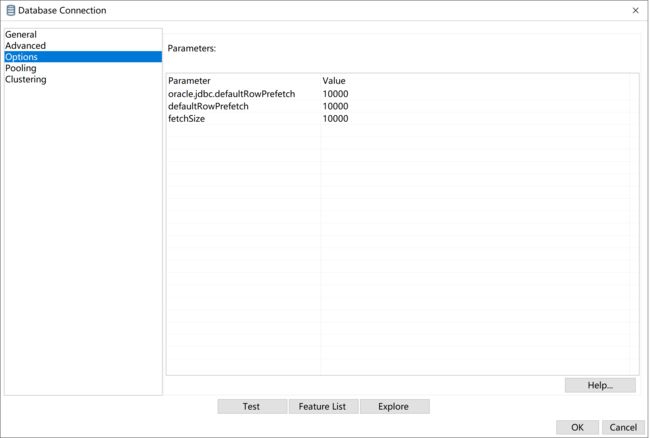
对于大批量的数据读,使用fetchSize、defaultRowPrefetch 会带来比较好的性能,关于参数详细说明,可参考附录内容。
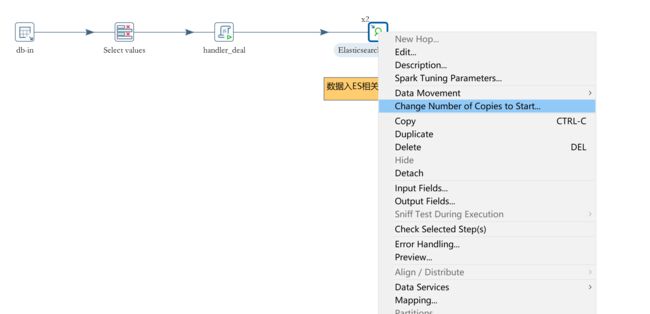
ES批量插入参数
使用Kettle本身的线程配置机制,右键修改插件运行线程数:
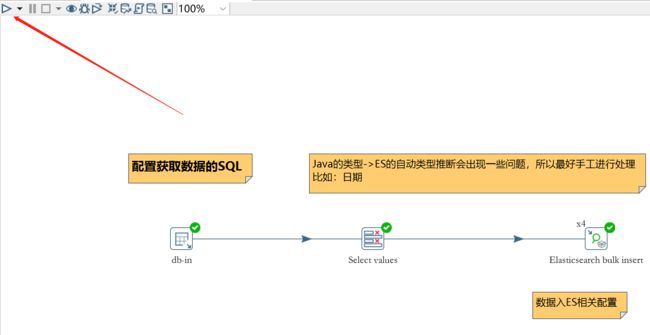
运行
直接在Spoon中运行
在Spoon的GUI窗口直接执行,一般在开发阶段
命令行执行
在Linux上将命令存为.sh文件,并设置文件可执行:
/soft/data-integration-8.3.0.1/pan.sh -file="/soft/kettle_run_file/zq-ges-party-oracle-to-es.ktr" -level=Minimal >> /soft/kettle_run_file/run_to_es.log
在windows将命令存亡.cmd文件,执行文件:
C:\data-integration-8.3.0.1\data-integration\Pan.bat /file:C:\kettle_App\zq-ges-party-oracle-to-es.ktr >> C:\kettle_App\log.txt
使用Pentaho Server执行
将Transformations(转换)发布到Pentaho Server上执行
其他事项
依赖包放到Kettle的classpath下
将依赖的数据库驱动放置 ${Kettle_home}/lib目录下,重启Kettle加载
Kettle本地版本编译
从github下载源码进行本地编译,注意 Maven的远程仓库一定要参考官方的 setting.xml进行配置:
官方提供地址:https://raw.githubusercontent.com/pentaho/maven-parent-poms/master/maven-support-files/settings.xml
D:\dev_tools\maven-repository
pentaho
true
pentaho-public
Pentaho Public
http://nexus.pentaho.org/content/groups/omni
true
always
true
always
pentaho-public
Pentaho Public
http://nexus.pentaho.org/content/groups/omni
true
always
true
always
org.pentaho.maven.plugins
com.pentaho.maven.plugins
com.github.spotbugs
执行构建:
mvn clean install -DskipTests
插件依赖的ES版本调整
因Kettle默认版本所使用的ES客户端版本为 6.6.2并不支持xpack-transport的连接,需要对依赖库进行添加:
org.elasticsearch.client
x-pack-transport
6.6.2
org.elasticsearch.plugin
x-pack-core
6.6.2
com.unboundid
unboundid-ldapsdk
4.0.8
将原代码中使用的TransportClient进行替换:
ElasticSearchBulk.java的481行:
//PreBuiltTransportClient tClient = new PreBuiltTransportClient( settingsBuilder.build() );
PreBuiltXPackTransportClient tClient = new PreBuiltXPackTransportClient( settingsBuilder.build() );
ElasticSearchBulkDialog.java的907行:
try ( PreBuiltXPackTransportClient client = new PreBuiltXPackTransportClient( settingsBuilder.build() ) ){
……
}
注意:不同版本的插件有可能会有差异,当前使用的是8.3.0.1源码;
插件的远程调试
首先配置启动参数,使用远程调试,将参数添加到 spoon.sh或spoon.bat中:
"-Xdebug" "-Xnoagent" "-Djava.compiler=NONE" "-Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8080"
在Eclipse中配置远程调试:
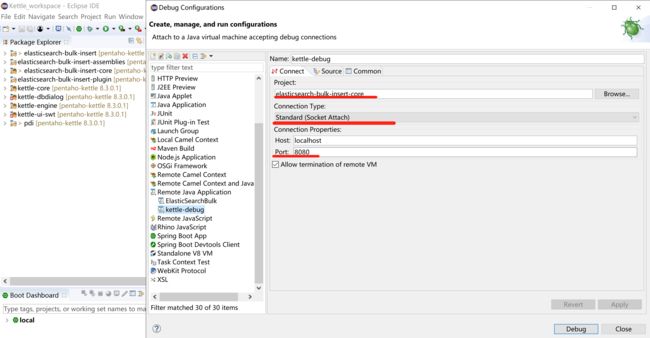
打上断点,可以进行代码调试了
附录:
JDBC fetchsize 参数说明:https://blog.csdn.net/bisal/article/details/82735614
JDBC fetchsize 对比:http://makejavafaster.blogspot.com/2015/06/jdbc-fetch-size-performance.html
Kettle插件开发说明:https://help.pentaho.com/Documentation/8.2/Developer_Center/PDI/Extend
阿里巴巴 数据迁移中间件: https://github.com/alibaba/canal