word2vec原理及其Hierarchical Softmax优化
文章目录
-
- 一、什么是word2vec?
-
- 1.1 词嵌入(word embedding)介绍
- 1.2 word2vec概述
- 二、CBOW模型
-
- 2.1 Context滑动窗口
- 2.2 模型结构
- 三、Hierarchical Softmax优化
-
- 3.1 从输入输出的降维到哈夫曼编码
- 3.2 哈夫曼编码(Huffman Coding)
- 3.3 从哈夫曼编码到Hierarchical Softmax
- 3.3 模型的训练
-
- 3.3.1 损失函数(Loss Function)
- 3.3.2 模型的初始化
- 3.3.3 模型的迭代
- 四、准确率评估
- 【附】
-
- 参考资料
- gensim
前言:
本文在介绍word2vec原理的基础上,着重介绍了其所采用的一种非常有启发性的优化技巧,即基于哈夫曼树的hierarchical softmax。这也是这里从数种word embedding算法中选择word2vec进行介绍的原因。因此,本文重心会放在对这部分的介绍上,不会对word2vec在NLP领域的应用以及其他优化方法做过多展开。如果你想了解的更深入,可以跳过本文直接看一下参考资料中的文章。
一、什么是word2vec?
word2vec是一种词嵌入(word embedding)算法,由Google提出并于2013年发表(见Paper)。要介绍word2vec就不得不先介绍一下什么是word embedding。
1.1 词嵌入(word embedding)介绍
在NLP建模中,常常面临的一个难题是如何表示单词以便对文本进行建模。对于神经网络等基于数学模型的机器学习模型而言,直接用ASCII码(或GBK编码)表示词作为模型输入显然是不可行的,因为ASCII码和其词语义之间是没什么关联的,两个词的ASCII码之间是非语义连续的、不可比的(或者其差值是没有意义的),而对于需要训练得到一个平滑的数学函数的数学模型而言,这一点是致命的(直接用ASCII码去训练一个数学模型,比如神经网络,有点类似于用神经网络建模一个跳跃函数,比如目标函数对有理数取值是1,无理数取值是0,显然是几乎不可能得到一个令人满意的训练结果的)。
word embedding即词嵌入正是为了解决这一难题而生,其意在为每个词生成一个连续的、包含语义的、可比较的n维数学向量:
v w o r d = ( x 1 , x 2 , ⋯ , x n ) v_{word} = (x_1,x_2,{\cdots},x_n) vword=(x1,x2,⋯,xn)
所谓的可比较是指,可以用两个词向量的距离度量两个词的语义相似度(距离可以用欧式距离或向量夹角表示,通常选择向量夹角巨多,此时向量的方向即代表了词的含义)。例如dog、cat、today、tomorrow等4个词的词向量分别为 v d o g v_{dog} vdog、 v c a t v_{cat} vcat、 v t o d a y v_{today} vtoday、 v t o m o r r o w v_{tomorrow} vtomorrow。对于这4个词显然有,dog和cat相比其他词含义更接近,因此 v d o g v_{dog} vdog和KaTeX parse error: Expected '}', got 'EOF' at end of input: {v_{cat}之间的距离应该比其他向量更小,同样地对于 v t o d a y v_{today} vtoday和 v t o m o r r o w v_{tomorrow} vtomorrow亦是如此。假设选择二维向量表示词向量,则一种可能的词向量表示如下图:

当然,维度n的选择通常不会这么小,因为如果维度太小通常不足以表征词之间立体的相似性关系。例如,假设有3个词:白猫、黑猫、黄猫,其含义两两相似,这意味着其词向量两两间的距离也应该是相近的,但是二维向量显然无法表征出这种多个向量两两相似的关系,所以维度一般会选择一个较大的值(需要和性能做好平衡,因为维度越大通常意味着计算过程的时空复杂度也越大)。
对于任意两个词,可以通过计算其词向量之间的距离来衡量其语义相似性,而且这些向量之间可以做各类包含语义的运算(Google的word2vec团队研究发现,其训练的词向量,vector(”King”) - vector(”Man") + vector(“Woman”) ≈ vector(“Queen”)[2]),而这正是我们在NLP建模中所需要的。生成词向量的算法有很多种,除了最简单的one-hot之外,还有word2vec、GloVe、以及较新的ELMo和BERT等等(其中ELMo和BERT之后会有专题介绍)。有了这些词向量后,就可以基于它们进行复杂模型的建模,比如计算两个文档间的相似度,或者用于训练各类高阶语言模型等等。
1.2 word2vec概述
word2vec采用无监督学习的方式,利用词之间的上下文共现关系来学习词之间的语义关系,并采用神经网络建模训练得到每个词的词向量。什么是上下文共现?看下边的例子(随便想的,轻拍-_-!!):
- 美人鱼 是
周星驰拍 的 星爷拍过 美人鱼- 功夫 的 主演 是
周星驰 星爷主演 过 功夫- …
假设我们有很多这样的语料,统计发现周星驰和星爷经常出现在相似的上下文(Context)语境里,这会不会就意味着这两个词大概率就表示一个意思或者至少意思是相近的?从语言学角度来讲,答案是肯定的。各类词向量训练算法也大多是基于这一现象来设计的,包括word2vec。因此,word2vec实际上就是利用了统计语言模型的思想(感兴趣的可以看一下吴军的《数学之美》第三章,对此有一些通俗易懂的介绍),基于统计信息对词和上下文之间的预测关系进行建模,并借助对这个模型的训练得到词向量。也就是说,word2vec建模的实际上是上下文词和中心词之间的预测关系,而词向量可以说是这个预测过程的副产物(当然,这个副产物正是word2vec要求解的东西)。
根据word2vec建模的预测方向的不同,word2vec可以分为两种:
- CBOW:即Continuous Bag-of-Word Model的简写,根据上下文的词预测中心词(表示为C → W)
- 例如:【今天__不错,适合出游】,根据上下文预测空白处的词
- Skip-gram:根据中心词预测上下文的词(表示为W → C)
- 例如:【__
天气__,适合出游】,根据中心词天气预测上下文的词
- 例如:【__

本文仅介绍CBOW模型,skip-gram本质上是类似的,本文不再赘述,想深入了解的可以看一下参考资料中的文章。
二、CBOW模型
如前所述,CBOW(Continuous Bag-of-Word)实际上是对由上下文词(Context)预测中心词进行建模。
2.1 Context滑动窗口
为了便于计算,对于句子中心词的上下文,无论是CBOW还是skip-gram都是设置一个固定大小的滑动窗口,预测过程仅观察窗口内出现的词,而非所有的词。假设滑动窗口大小设定为C=4,则对于句子中每个词,将只观察前后的各2个词共4个词。例如对于句子【小度/智能/音箱/给你/最好/陪伴】,其滑动观察过程为:
- 【
小度/智能/音箱】/给/你/最佳/陪伴 - 【小度/
智能/音箱/给】/你/最佳/陪伴 - 【小度/智能/
音箱/给/你】/最佳/陪伴 - 小度/【智能/音箱/
给/你/最佳】/陪伴 - 小度/智能/【音箱/给/
你/最佳/陪伴】 - 小度/智能/音箱/【给/你/
最佳/陪伴】 - 小度/智能/音箱/给/【你/最佳/
陪伴】
其中【】表示Context的滑动窗口,飘红词表示中心词,飘蓝词表示Context词。此外,由首尾词的窗口位置可以看到,滑动窗口同时还限定了最大观察距离。
了解了这些,接下来我们就可以利用神经网络对其进行建模了。
2.2 模型结构
CBOW的神经网络结构如下:
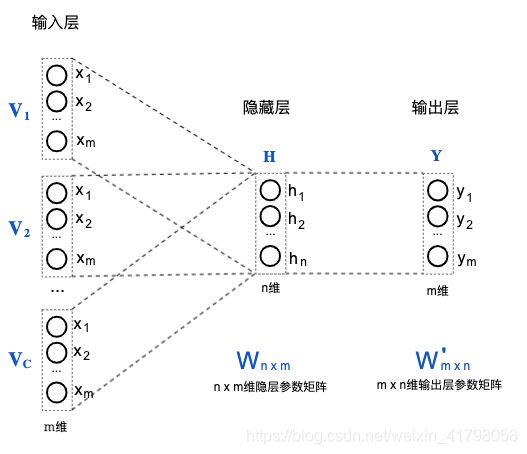
这是一个具有一个隐藏层的全连接神经网络,输入层是上下文窗口内各个词的M维one-hot向量(给每个词编个号,向量中对应维度取值为1,其他维度维0)的线性叠加,输出层是一个m维向量Y。其中m为词的数量,n为设定的欲训练的词向量的维度。隐藏层和输出层的计算公式如下(矩阵表示):
H = 1 C W × V i = W × 1 C V i H=\frac{1}{C}W \times V_i = W \times \frac{1}{C}V_i H=C1W×Vi=W×C1Vi Y = S o f t m a x ( W ′ × H ) Y = Softmax(W' \times H) Y=Softmax(W′×H)
其中:
- H表示隐藏层的输出列向量,Y表示输出层的输出列向量。
- C表示滑动窗口大小,即Context中的词个数(不含中心词)。表示C个上下文词中第i个词的one-hot向量。
- W为隐藏层的n x m维参数矩阵,W’为输出层的m x n维参数矩阵。
- Softmax()表示对计算结果做softmax归一化;
由以上可以看到,word2vec的神经网络隐藏层的计算是线性的(激活函数是线性的f(x)=x),因此网络的隐藏层也就只需要1层(多了没用,因为线性意味着由矩阵乘的结合律可以将多个隐藏层化简为1层)。另外,从上边的计算公式也可以看出为什么叫Continuous Bag-of-Word了,因为计算过程没有考虑上下文各个词之间的相对顺序,对它们是平等对待的。
关于word2vec为什么选择线性建模,我个人的理解是(不一定对,欢迎探讨指正)词向量要支持带语义的加减线性运算,而线性建模才能比较好的训练得到这样的词向量(因为训练过程都是线性运算,得到的词向量自然也就支持线性运算了)。
为做说明,我们可以把上述计算H向量的式子变换一下:
H = 1 C ∑ i = 1 C W × V i = 1 C ∑ i = 1 C ( W × V i ) H = \frac{1}{C}\sum_{i=1}^CW \times V_i = \frac{1}{C}\sum_{i=1}^C(W \times V_i) H=C1i=1∑CW×Vi=C1i=1∑C(W×Vi)令:
V i ′ = W × V i V'_i=W \times V_i Vi′=W×Vi则有(由于是个one-hot向量,上式实际上相当于提取出了W矩阵中的一列,从而得到): H = 1 C ∑ i = 1 C V i ′ H=\frac{1}{C}\sum_{i=1}^CV'_i H=C1i=1∑CVi′由此可见,由上下文词预测中心词实际上就是对上下文的各个词向量求和取均值(输出层可以看作由 V i ′ V'_i Vi′到one-hot的变换)。
这是个非常简单的FNN(全连接神经网络),其训练方法不再赘述(缺少神经网络知识背景的读者可以参考深度学习零基础入门(一):一文读懂神经网络)。上述模型训练完成后,参数矩阵W的每一列向量即可作为词向量。
三、Hierarchical Softmax优化
由于待训练的词汇量往往是个非常大的数字(百万量级),这意味着对于前文所述的基础FNN网络,其输入向量、参数矩阵和输出向量的尺度都是巨大的,因而训练过程的计算量显然也是巨大的。因此训练速度必然会是非常慢的,这显然难以让人接受。要优化模型的计算量,直观的思考可以有两种方向:要么从模型结构的角度着手,要么从样本的角度着手。Google团队正是这样做的。Mikolov在论文中提出了两种优化方法,即 Hierarchical Softmax 和 negative sampling,分别对应于这两个优化方向。
这里介绍Hierarchical Softmax。
3.1 从输入输出的降维到哈夫曼编码
为了对模型结构进行优化,我们先回到问题的本质。前文提到,word2vec建模利用的是上下文中各个词因共现而产生的隐含关联性。为利用这一关联性,CBOW模型的对由上下文词预测中心词做了建模。也就是说,只要我们能做到这一点,模型就能work。而前文所述的FNN之所以计算量大,是因为模型的输入输出向量规模太大了,那是否可以从模型中消去这个东西呢?
我们知道,在计算机程序中,对于单字(字母或汉字)我们是用ASCII码或UTF-8等编码表示的,这实际上就是用一个整数表示。对于词,我们显然也可以做类似的表示,只需要给每个词一个编号,用这个编号作为编码值来表示这个词。那是否可以直接拿这个编码值作为模型的输入输出呢?输入肯定不行,因为它的值是语义不连续不可比的。输入不行,那输出呢?答案是肯定的,这正是Google团队开的脑洞之一,由预测one-hot向量变为预测词编码的每个二进制位!
输出的降维问题解决了,那输入呢?我们可以先做这样一个假设,如果我已经有词的向量了,我要做的就是根据上下文词预测中心词,那这个模型结构我可以怎样做计算量最小的设计?由此,Google团队的另一个脑洞是,直接用训练中词向量作为模型的输入。也就是说,训练中的词向量既作为模型的待训练参数,又同时做为模型的输入。
至此,我们其实已经可以尝试更新一下我们的网络结构了:

这里,模型的输入变成了我们要训练的词向量(在训练过程中和参数一起迭代更新),模型的输出变成了对中心词编码的各个比特位的0-1二分类预测。
到这里是不是就万事大吉了呢?Google团队并没有满足于此。既然涉及到了编码这个在信息论领域发展非常成熟的问题,那这里是不是可以找到一些可以借鉴的东西来进一步优化呢?答案是肯定的,这就引出了哈夫曼编码了。
3.2 哈夫曼编码(Huffman Coding)
学过哈夫曼编码的读者应该都了解,它被证明是一种对信息的最优编码方法,即平均编码长度最短(加权均值)。也就是说,如果我们根据每个词的出现频次作为权值用哈夫曼编码的方式对每个词进行编码,那么就可以保证频次越高的词的编码比特长度越短,且整体的平均编码比特长度是最小的!(按频次的加权均值)。由此,我们可以得到形如下图的编码树,其中叶子节点代表每个词,根节点到叶子结点的路径即代表了每个词的编码值。

其中,m是unique的单词个数,Wi表示第i个词。
我们以一个实际的例子来看一下哈夫曼编码树的构造。假设语料库包含6个词,其词频分别为:
| 词 | 词频 |
|---|---|
| 小度 | 2 |
| 智能 | 3 |
| 音箱 | 3 |
| 创造 | 4 |
| 美好 | 4 |
| 生活 | 5 |
则,按照哈夫曼编码规则,可以构造出如下哈夫曼编码树:

可以看到,词频较高的『生活』和『美好』两个词的编码比特位宽度是2,小于其他低频次的词。
3.3 从哈夫曼编码到Hierarchical Softmax
有了哈夫曼编码,我们就可以对模型结构做再一次调整了:

此时,模型连接的是哈夫曼编码树上的各个非叶子节点。其自根节点自上而下地对每个节点都做一个0-1的二分类预测,并根据预测结果决定出path,进而得到预测的中心词。对于上下文C,预测得到词W(C→W)的概率计算公式为(我们规定哈夫曼编码树走左边是0,走右边是1):
P ( w = w o ∣ V 1 , V 2 , … , V C ) = ∏ i = 1 L ( w o ) ( σ ( [ [ b ( w o , i ) = 0 ] ] ( W i ∗ H ) ) ) P(w = w_o|V_1,V_2, \dots ,V_C) = \prod_{i=1}^{L(w_o)}(\sigma([[b(w_o, i) = 0]](W_i * H))) P(w=wo∣V1,V2,…,VC)=i=1∏L(wo)(σ([[b(wo,i)=0]](Wi∗H)))
其中:
- L ( w o ) L(w_o) L(wo)表示词 w o w_o wo在哈夫曼树上的路径长度;
- [ [ b ( w o , i ) = 0 ] ] [[b(w_o,i)=0]] [[b(wo,i)=0]]是个特殊函数, b ( w o , i ) = 0 b(w_o,i)=0 b(wo,i)=0表示 w o w_o wo的二进制编码第i个比特为0;函数 [ [ x ] ] [[x]] [[x]]的定义为: [ [ x ] ] = { 1 , i f x = t r u e − 1 , o t h e r w i s e [[x]]=\begin{cases} \ \ \ 1, \ \ \ \ \ if\ x = true\\ -1, \ \ \ \ \ otherwise\\ \end{cases} [[x]]={ 1, if x=true−1, otherwise
- 当 b ( w o , i ) b(w_o,i) b(wo,i)为1时,函数 [ [ x ] ] [[x]] [[x]]取值为-1,因此有: σ ( [ [ b ( w o , i ) = 0 ] ] ( W i ∗ H ) ) = σ ( − W i ∗ H ) = 1 − σ ( W i ∗ H ) \sigma([[b(w_o, i) = 0]](W_i * H)) = \sigma(-W_i * H) = 1-\sigma(W_i * H) σ([[b(wo,i)=0]](Wi∗H))=σ(−Wi∗H)=1−σ(Wi∗H)
- w i w_i wi表示路径上第i个非叶子节点的参数向量。H表示对C个上下文词的词向量的均值: H = 1 C ( V 1 + V 2 + ⋯ + V C ) H = \frac{1}{C}(V_1 + V_2 + \dots + V_C) H=C1(V1+V2+⋯+VC)
比如,对于词 w 2 w_2 w2,其在上下文 V 1 , V 2 , … , V C V_1,V_2, \dots , V_C V1,V2,…,VC下的预测概率为:
P ( w = w 2 ∣ V 1 , V 2 , … , V C ) = ∏ i = 1 L ( w 2 ) ( σ ( [ [ b ( w 2 , i ) = 0 ] ] ( W i ∗ H ) ) ) = σ ( W 1 ∗ H ) ∗ σ ( W 2 ∗ H ) ∗ σ ( − W 3 ∗ H ) P(w = w_2|V_1,V_2, \dots ,V_C) = \prod_{i=1}^{L(w_2)}(\sigma([[b(w_2, i) = 0]](W_i * H))) = \sigma(W1*H) * \sigma(W2*H) * \sigma(-W3*H) P(w=w2∣V1,V2,…,VC)=i=1∏L(w2)(σ([[b(w2,i)=0]](Wi∗H)))=σ(W1∗H)∗σ(W2∗H)∗σ(−W3∗H)
3.3 模型的训练
要使得模型可训练,最重要的一步首先就是要找到一个合适的目标函数。确定了目标函数,之后只要利用反向传播算法+梯度下降法进行迭代即可,就是标准套路了。
3.3.1 损失函数(Loss Function)
在这个模型下,显然我们需要使得对所有语料数据求得的中心词的预测概率值整体最大化,即最大化: ∏ i = 1 T P ( w = w o ∣ C ) \prod_{i=1}^TP(w=w_o|C) i=1∏TP(w=wo∣C)
- 其中:T表示对所有的样本做计算;C表示 w o w_o wo的上下文词向量;
为了便于计算,我们给它加个对数,把乘法变成加法(log(x)是单调递增函数,因此其极值点与原函数是一致的): l o g ( ∏ i = 1 T P ( w = w o ∣ C ) ) = ∑ i = 1 T l o g ( P ( w = w o ∣ C ) ) log(\prod_{i=1}^TP(w=w_o|C)) = \sum_{i=1}^Tlog(P(w=w_o|C)) log(i=1∏TP(w=wo∣C))=i=1∑Tlog(P(w=wo∣C))
对上述式子再加个负号,就可以得到损失函数(为什么?因为损失函数找的是最小值,而它越小,上边式子的值就越大嘛~): E = ∑ i = 1 T − l o g ( P ( w = w o ∣ C ) ) = ∑ i = 1 T − l o g ( σ ( [ [ b ( w 2 , i ) = 0 ] ] ( W i ∗ H ) ) ) E = \sum_{i=1}^T-log(P(w=w_o|C)) = \sum_{i=1}^T-log(\sigma([[b(w_2, i) = 0]](W_i * H))) E=i=1∑T−log(P(w=wo∣C))=i=1∑T−log(σ([[b(w2,i)=0]](Wi∗H)))
有了上述函数,我们就可以利用它结合反向传播算法来推导出各个参数的梯度计算公式了,这里不再赘述。缺少相关知识背景的读者可以参考:深度学习零基础入门(一):一文读懂神经网络
3.3.2 模型的初始化
- STEP1:统计词频,为每个词生成哈夫曼编码,从而构成哈夫曼编码树;
- STEP2:为每个词生成一个随机初始词向量;
- STEP3:为每个非叶子节点生成一个随机初始参数向量;
- STEP4:设定超参数C的值,即滑动窗口的大小;
3.3.3 模型的迭代
- 遍历语料数据中所有的句子,并对每个句子以滑动窗口方式遍历所有中心词,对每个中心词:
- 计算中心词在当前上下文下的预测概率;
- 运用SGD(或其他梯度下降算法),计算每个参数的梯度值(包括词向量),并根据梯度值更新参数得值
梯度下降法的具体推到与迭代过程不再赘述。
四、准确率评估
摘自Mikolov’s Paper [2]:
【附】
参考资料
- Mikolov:Distributed Representations of Sentences and Documents
- Mikolov:Efficient Estimation of Word Representations in Vector Space
- word2vec Parameter Learning Explained
gensim
- 介绍:
- 一个实现了word2vec的Python库,可以直接用来训练word2vec词向量,详见:https://radimrehurek.com/gensim/models/word2vec.html
- 安装:
# 命令行执行: pip3 install gensim -i https://pypi.tuna.tsinghua.edu.cn/simple/ - 用法:
- 参考:gensim使用方法以及例子
- help doc: