问题
将GP与不同的似然函数结合可以构建非常灵活的模型,然而这会使得模型的推理变得不可解(intractable),因为似然函数不再是高斯过程的共轭。所以我们需要变分推理来近似f的后验分布或者MCMC方法从f后验分布来采样,从而预测在新的点的函数值。
GPflow.models.VGP就实现了变分推理方法。
模型
从完全的贝叶斯角度看,一般GP模型的数据生成过程可以表示为:
\theta \sim p(\theta)
f \sim \mathcal {GP}\Big(m(x; \theta), k(x, x'; \theta)\Big)
y_i \sim p\Big(y | g(f(x_i)\Big)
首先从\theta的先验分布采样一个\theta,然后从高斯分布得到一组隐函数f,然后再由一个连接函数g(\cdot)映射到观测函数y。
模型推理
首先明确我们要求的是f_\ast的后验分布
p(f_\ast | \bm{x}_\ast, \bm{X}, \bm{y}) = \int p(f_\ast | \bm{x}_\ast, \bm{X}, \bm{f}) p(\bm{f} | \bm{X}, \bm{y}) ~d{\bm{f}} (1)
而(1)中通常p(\bm{f} | \bm{X}, \bm{y})是个非高斯分布,因此不好求积分。我们的目的就是用一个高斯分布来近似p(\bm{f} | \bm{X}, \bm{y})。这个高斯分布Opper and Archambeau已经在论文中给出:
\hat q(\mathbf f) = \mathcal N\left(\mathbf m, [\mathbf K^{-1} + \textrm{diag}(\boldsymbol \lambda)]^{-1}\right) (2)
其中我们根据Opper and Archambeau的建议将\mathbf m写为\mathbf m = \mathbf K \boldsymbol \alpha, 同时为保证方差为正,将\lambda写为\lambda^2。于是有
\hat q(\mathbf f) = \mathcal N\left(\mathbf K \boldsymbol \alpha, [\mathbf K^{-1} + \textrm{diag}(\boldsymbol \lambda)^2]^{-1}\right) (3)
只要把\hat q(\mathbf f)中的参数都求出来,问题就解决了。如何求参数呢?最大化\log p(\mathbf X)的ELBO即可。
现在来求\log p(\mathbf X)的ELBO。参考Variational Inference: A Review for Statisticians,我们知道
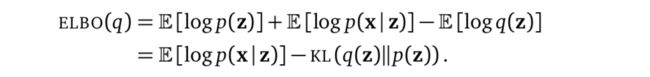
对应地,在这里有
\textrm{ELBO} = \sum_n\mathbb E_{q(f_n)}\left[ \log p(y_n\,|\,f_n)\right] - \textrm{KL}\left[q(\mathbf f)||p(\mathbf f)\right] (4)
Marginals of q(\mathbf f)
给定q(\mathbf f),如何快速稳定地求出这个高斯分布的边际分布q(f_1), q(f_2),...,q(f_n)?均值很好解,协方差矩阵则需要求两次矩阵逆运算。
令 \boldsymbol \Lambda = \textrm{diag}(\boldsymbol \lambda),\boldsymbol \Sigma 为协方差矩阵 \boldsymbol \Sigma = [\mathbf K^{-1} + \boldsymbol \Lambda^2]^{-1}。根据矩阵逆引理,有
\boldsymbol \Sigma = [\mathbf K^{-1} + \boldsymbol \Lambda^2]^{-1}
= \boldsymbol \Lambda^{-2} - \boldsymbol \Lambda^{-2}[\mathbf K + \boldsymbol \Lambda^{-2}]^{-1}\boldsymbol \Lambda^{-2}
= \boldsymbol \Lambda^{-2} - \boldsymbol \Lambda^{-1}\mathbf A^{-1}\boldsymbol \Lambda^{-1}
其中 \mathbf A = \boldsymbol \Lambda\mathbf K \boldsymbol \Lambda + \mathbf I
则我们只需求一次逆,且由于A的特征值上界是1(为什么?)故数值计算是稳定的。
KL divergence
通过与上面类似的处理,KL距离可以写为
\textrm{KL} = -0.5 \log |\boldsymbol \Sigma| + 0.5 \log |\mathbf K| +0.5\mathbf m^\top\mathbf K^{-1}\mathbf m + 0.5\textrm{tr}(\mathbf K^{-1} \boldsymbol \Sigma) - 0.5 N
又由于\textrm{tr}(\mathbf K^{-1} \boldsymbol \Sigma) = \textrm{tr}(\mathbf A^{-1}) |\mathbf K^{-1} \boldsymbol \Sigma| = |\mathbf A^{-1}|,所以有
\textrm{KL} = 0.5 (\log |\mathbf A| +\boldsymbol \alpha^\top\mathbf K\boldsymbol \alpha + \textrm{tr}(\mathbf A^{-1}) - N)\,.
不过这个表达式仍不十分完美,因为我们要求 \mathbf A^{-1}。理论上用extra backsubstitution (into the identity matrix)可以更快(为什么?),但在tensorflow中貌似不是这样的。
预测
现在再回到(1),我们有
q(f^\ast \,|\,\mathbf y) = \int \mathcal N(f^\ast \,|\, \mathbf K_{\ast}\mathbf K^{-1}\mathbf f,\, \mathbf K_{\ast\ast} - \mathbf K_{\ast}\mathbf K^{-1}\mathbf K_{\ast})\mathcal N (\mathbf f\,|\, \mathbf K \boldsymbol\alpha, \boldsymbol \Sigma)\,\textrm d \mathbf f
根据高斯条件边际概率规则,有
q(f^\ast \,|\,\mathbf y) = \mathcal N\left(f^\ast \,|\, \mathbf K_{\ast}\boldsymbol \alpha,\, \mathbf K_{\ast\ast} - \mathbf K_{\ast}(\mathbf K^{-1} - \mathbf K^{-1}\boldsymbol \Sigma\mathbf K^{-1})\mathbf K_{\ast}\right)
根据矩阵逆引理,有
q(f^\ast \,|\,\mathbf y) = \mathcal N\left(f^\ast \,|\, \mathbf K_{\ast}\boldsymbol \alpha,\, \mathbf K_{\ast} - \mathbf K_{\ast}[\mathbf K + \boldsymbol \Lambda^2]^{-1}\mathbf K_{\ast}\right)
参数优化
同GPR模型一样的问题,我们采用什么原则优化超参数呢?
答案是最大化模型超参数\theta的后验概率p(\theta|X, y)= \frac{p(y|X,\theta)p(\theta)}{p(y|X)}。同样由于分母无法计算且是关于\theta的常数,因此最大化分子部分。由于ELBO是p(y|X,\theta)的下界,因此分子部分的下界是ELBO和超参数先验分布p(\theta)的乘积。
代码解读
VGP_opper_archambeau._build_likelihood()实现的就是ELBO(4)。
然后再用优化算法,求出使p(y|X,\theta)p(\theta)最大化的隐函数和模型超参数。
参考文献
[1] GPflow notebook: /GPflow-master/doc/source/notebooks/vgp_notes.ipynb
[2] Opper, Manfred, and Cédric Archambeau. "The variational Gaussian approximation revisited." Neural computation 21.3 (2009): 786-792.
[3] Blei, David M., Alp Kucukelbir, and Jon D. McAuliffe. "Variational inference: A review for statisticians." Journal of the American Statistical Association 112.518 (2017): 859-877.