Render Pipeline
2.1渲染管线架构

2.2 Application Stage
Application阶段都是在CPU上面。加速算法,几何处理都是在这个上面。
CPU经常需要采用多线程来进行处理。
碰撞检测就经常需要在这个阶段进行执行。
加速算法等(在19章)也会在这个阶段实现。
2.3 Geomerty Processing
几何阶段,大部分的三角以及顶点处理都在这个地方。

有下面几个阶段:
顶点Shader,投影,裁剪,屏幕映射
2.3.1 顶点Shading
顶点Shader的主要作用是计算顶点的位置,也会输出程序想要输出的数据,类似于法线以及贴图坐标。
传统的很多shader经常对每个顶点位置计算光线,以及法线,而且在顶点上储存颜色。这些颜色通过顶点进行插值。利用当代GPU的优点有更多shader是每像素计算的,就要看程序员是的判断了。现在的顶点shader更多致力于计算每个顶点相关的数据,例如顶点动画。
我们在讨论如何计算顶点位置的时候坐标系是我们所需要的。模型需要经过多个空间坐标系。一开始模型在自己的模型坐标系,多个实例可以共享一个模型。
然后模型转换到世界坐标系,世界坐标是唯一的,所有的模型在这同一个空间。
之前提到的,摄像机把所看到的全部渲染出来,摄像机在世界坐标中有一个位置,为了更好裁剪视口,摄像机有视口坐标系。

接下去我们看第二种顶点shader的输出结果。为了产生真实场景,光有形状是不够的,我们还得有材质,灯光和材质能够被任意形式表现,从简单的颜色到物理属性度可以描述。
这种灯光对材质的表现称作shading。渲染方程对一个物体的不同点进行渲染,有些渲染在顶点上而另外一些则在想租上。很多材质数据可以存在顶点上,比如:点位置、发现、颜色或者其他的数学属性需要被渲染方程所用到的。顶点渲染结果发送到光栅化以及片元处理阶段,顶点渲染在GPU顶点shader中的形式更深层次的在第三以及第五章。
作为顶点渲染的一部分,投影以及裁剪,将视口缩放到一个cube中,目前有两种形式,一种是正交(orthographic)另一种是透视视图。

正交只是一种平行投影的类型。其他领域也可以看到使用的领域。
投影被描述成一个矩阵(Section 4.7)所以有时候会和剩余的集合变换连载一起。
将正交视口缩放到视觉空间只是一个缩放过程。
透视投影更加复杂一点,在这种类型的投影中,远离摄像机的东西看起来更小。平行线会汇聚于一点,这个视觉体积被称作平截头。最后也会变成一个单位cube。正交和透视能被4×4矩阵描述。在这样的变换之后,就会进入裁剪坐标系,顶点shader必须输出坐标以确保后续裁剪得以进行。
然而这些举证变化一个体积到另一个还叫投影是因为,z坐标在图片中不储存但是还是会存在z-buffer中,所以模型被投影到了二维空间。
2.3.2 可选顶点处理
刚刚提到的顶点处理在每个管线中都有,上述管线执行完之后又一些可选阶段在GPU上,顺序是这样的:tessellation, geometry shading, 以及 stream output。他们的使用依赖于硬件的实现,并不是所有GPU都有他们的。他们之间无依赖,而且一般用得也比较少,在第三章会每个都讲一下
第一个可选阶段是tessellation。想想你有一个弹性球物体,如果你用一组三角形进行描述,你会陷入性能以及表现的问题。如果你的球5米远的时候看起来不错,但是接近的时候三角轮廓就能看出来了,但是如果你添加面的话那么你的性能就会有问题。曲面细分就可以帮助你实时细化面。
我们聊了一些三角形的,不光是三角形,还能处理点、线、或者其他物体。曲面细分包含了一组shader。Hull shader、tessellator以及domain shader。摄像机距离决定了多细致。
接下去是几何shader。这个shader出现早于曲面细分shader,而且在GPU上更多可以找到。这个shader更加简单不过限制也更多。集合shder有很多用途,其中一个就是粒子生成。想象模拟一个烟花爆炸。每个烟花可以被一个点替代,单顶点。几何shader可以把每个店转换成一个方形,转换成更复杂的几何体让我们来渲染。
最后一个阶段叫做stream output,流输出,这个阶段使得GPU作为一个几何引擎,并不是将我们的几何顶点输出用于渲染而是用于计算。这些数据会被用于CPU,或者GPU自身。这个阶段一般用于例子模拟,例如我们的烟花例子。
这三个阶段的顺序是曲面细分、几何shader、流输出,每一个都是可选的。接下去我们已经有了顶点数据。到下一步了。
2.3.3 裁剪
只有那些整个火部分在视口体的集合体会被渲染到屏幕上。到下一个阶段,而在视口外的集合体就不会被渲染,一部分在视口里面的几何体会被裁剪。几何体总是被单位cube裁剪。

2.3.4 屏幕映射
只有裁剪后的几何体会到达这个阶段,刚刚进入这个阶段的时候还是三维的,x以及y坐标会转换到几何坐标。
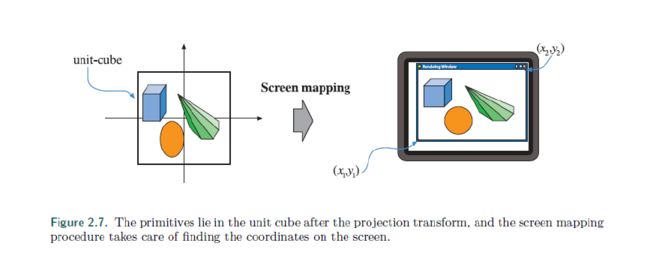
DX和OpenGL中的坐标系不太一样,z坐标的话,OpenGL是(-1+1),DX是(0,1)。视口坐标以及z值被传到了栅格化阶段。
OpenGL把左下角作为坐标系,而DX则是右上角,所以需要注意。
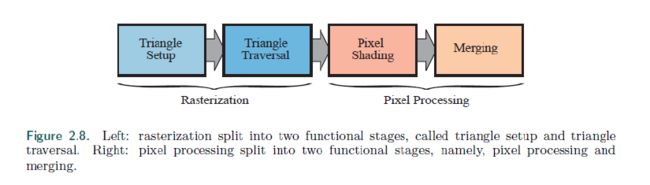
2.4 栅格化
将变化以及投影的顶点将shading数据联系在一起,下面的目标就是找到所有的像素。这个将面片内所有像素找到的过程叫做栅格化。可以分成两个步骤:片元组装以及遍历三角形。

如何覆盖面片有几种方法,最简单的方法,就是对每个像素中心取样看看在不在面片内。你也许用过更多超采样和反走样的方法。另外一个方式就是只要一部分像素覆盖就算进去。
2.4.1 三角形组装
这个阶段帮你把所有三角形数据组合在一起,这个过程是硬件所固定的。
2.4.2 遍历三角形
每个中心被片元覆盖的像素是一个片元。在Section5.4可以找到更简单的方法。每个像素的数据通过三个顶点的差值可以得到,包括了片元深度,以及任何几何阶段得到的数据。McCormack et al. 提供了更多信息。
McCormack, Joel, and Robert McNamara, “Tiled Polygon Traversal Using Half-Plane Edge Functions,” in Graphics Hardware 2000, Eurographics Association, pp. 15–22, Aug. 2000. Cited on p. 22, 996, 997
以及修正远景三角形差值。
Heckbert, Paul S., and Henry P. Moreton, “Interpolation for Polygon Texture Mapping and Shading,” State of the Art in Computer Graphics: Visualization and Modeling, Springer- Verlag, pp. 101–111, 1991. Cited on p. 22, 999
所有的取样到的像素都被送到了下一个阶段。
2.5 像素阶段
所有像素都被认为包含在三角 面片或者其他的集合体中。这个阶段氛围片元shading以及merging。
这个阶段是逐像素逐采样进行计算。
2.5.1 像素渲染
任何逐像素渲染都在这里进行,使用插值shading数据。结果是一个或多个颜色传递到下一个阶段,不像片元组装以及遍历三角形,GPU核心大部分都用来做这个事情了。程序员编写像素着色器,然后用于计算。非常多的技术被用在了这个阶段,其中最重要的要算texturing,贴图了。贴图更多信息在第六章。简单说就是把一张或者多张图片放到物体上,用于多种用途。一个简单的例子就是如下图。

二维的图片映射到了模型的每一个片元上面,然后这会传递到下一个阶段。
2.5.2 Merging
像素储存的地方叫做ColorBuffer,实际上是一个颜色的阵列数组(红色,绿色,蓝色组合)。合并阶段就是把像素渲染的结果放到buffer里面,这个阶段也被称作ROP,代表的是“raster operations pipeline”或者“render output unit”取决于谁问你要的。不想渲染阶段,GPU这个阶段不是完全可编程的,而是可配的。
这个阶段也代表了如何处理可见性。也就是哪些东西要显示到屏幕中,大部分硬件都是使用了z-buffer的处理方式。zbuffer和colorbuffer一样大,然后每个像素都会储存目前最近物体的深度值。意味着这个最近的物体将会被渲染。这个算法很简单,有着O(n)的收敛。由于zbuffer只储存了蛋哥深度值,所以无法用于透明物体,而是用在所有的不透明物体上,然后透明物体从后往前进行渲染,或者使用顺序无关算法(Section5.5)半透明是zbuffer最大的软肋。
我们刚刚提到了color buffer用于储存颜色以及zbuffer储存z值,然而这里还有其他的通道和buffer可以储存片元信息。透明通道储存了每个像素的透明信息。Section5.5.。早更老的API中透明通道通过透明测试来进行裁剪。现在裁剪阶段可以插入到片元着色器,这个可以保证完全透明的片元不受到zbuffer的影响(Section6.6)。
Stencil Buffer是一个不再屏幕显示用于记录几何渲染位置信息的buffer。一般每像素包含8位。集合体可以用很多方法渲染到上面,然后buffer内容可以用于控制color buffer以及z buffer。举个例子,一个圆可以渲染到stencil buffer上,然后只渲染与这个圆相交部分的集合体。所有在管线末尾的函数称作raster oprations或者blend operations、这可以将不同的颜色混合起来,一般是半透明或者是颜色的累计,一般混合是API中可配的,但是不能完全可编程。然而一些API支持可编程混合,称作pixel shading ordering。
framebuffer 一般由系统中的所有buffer组成。
当集合体到达并且通过了光栅化阶段,这些可见点就会被显示在屏幕上,为了防止人眼能够看清楚绘制的过程,一般使用double buffering,也就是双缓冲。也就是一个buffer不显示,绘制,而另外一个显示,之后交换。
更多信息看Sections5.4.2,23.6以及23.7。
2.6 纵观管线(不赘述了……)
点、线、三角面是渲染模型的基础。
想想你在用CAD做一个华夫饼机器,这里需要经过这么多的阶段。
Application:
CAD应用程序允许用户选择并且移动模型。还有动画或者移动摄像机来显示不同角度的机器。初次之外还有灯光以及模型的几何图元。到了下一个阶段。
Geomerty Processing:
不想翻
光栅化:
不想翻
Pixel Processing:
不想翻
总结
渲染管线是几十年来图形硬件进化一达到实时渲染目的的结果。需要注意的是,这并不是唯一的渲染管线类型。离线渲染经历了不同的进化路线。电影渲染经常使用micropolygon piplines,但是ray tracing以及path traing也会被提到,在Section11.2.2 会被用于架构以及视觉设计中。
多年依赖,开发者只能用图形API的固定管线,最后一个使用固定管线的案例的任天堂的Wii。可编程GPU使得存在了更多的操作性。第四版中我们假设所有的开发都在可编程GPU上。