tensorflow之feature_column+DeepFM
tensorflow2提供的feature_column工具为MLer/DLer处理数据提供了很大的方便,feature_column更是可以直接和 estimator 融合,实现无缝操作。
但是 estimator 是预定义的模型,结构固定,有时候MLer想实现自己的模型,还需要借助keras提供的接口工具Model,但是Model类不能很好的和feature_column融合,需要经过一层转化,如下:
original_feature \rightarrow feature_column \rigtarrow input_tensor
需要借助tensorflow.compat.v1.feature_column.input_layer这个兼容性接口来实现。
转换后的input_tensor是一个Tensor,并非是占位符,而是填充了数据的tensor,会把所有样本全部读进来内存,多以这方法的缺点是不适合大规模样本的处理。
处理数据
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
from matplotlib import pyplot as plt
# 读取训练数据
df = pd.read_csv("./deep_fm_data.csv")
labels = pd.read_csv("./deep_fm_label.csv")
print(df.info())
print(labels.info())
features = df.to_dict('list')
labels = labels
# test_features = df[split_point+1:].to_dict('list')
# test_labels = labels[split_point+1:]
RangeIndex: 60000 entries, 0 to 59999
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 I1 60000 non-null float64
1 I3 60000 non-null float64
2 I4 60000 non-null float64
3 I5 60000 non-null float64
4 I6 60000 non-null float64
5 I7 60000 non-null float64
6 I2 60000 non-null int64
7 C1 60000 non-null object
8 C2 60000 non-null object
9 C4 60000 non-null object
10 C5 60000 non-null object
dtypes: float64(6), int64(1), object(4)
memory usage: 5.0+ MB
None
RangeIndex: 60000 entries, 0 to 59999
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 label 60000 non-null int64
dtypes: int64(1)
memory usage: 468.9 KB
None
选取一部分特征,防止OOM
# 对不同的特征列做不同的处理
numeric_columns = ['I1', 'I3', 'I4', 'I5', 'I6', 'I7']
categorical_columns = ['I2', 'C1', 'C2', 'C4', 'C5']
DeepFM部分的输入样本
deepfm有两部分构成,一部分是fm,一部分是deep NN , 我们需要构造的输入数据有:
1.FM一阶部分的输入数据
2.FM 二阶部分和 deep 部分公用的 连续类型特征的 embedding数据
3.FM 二阶部分和 deep 部分公用的 离散类型特征的 embedding数据
以上训练是模型训练数据的组成部分,在训练模型的时候需要分成3个不同的输入路径喂给模型。训练样本的构造我们通过feature_column + input_layer来构造,省去了我们再模型内部自己实现embedding的代码,这点事比较省事的。
另:关于feature_column + input_layer能否在大规模数据集上适用,我目前还不太清楚,继续学习。
FM一阶部分的训练数据
# fm 一阶部分需要one-hot类型的特征,r如果是连续类型的特征,可以直接输入到一阶部分;如果是离散类型的,可以做one-hot编码后再输入模型
# 所以,不管是连续类型的还是离散类型的,都可以做one-hot编码
# 为方便对离散特征做one-hot编码,我们需要构造离散特征做one-hot编码用到的 feature2int 字典
# 够造categorical特征做embedding or indicator用到的特征字典
categorical_columns_dict = {
}
for col in categorical_columns[0:]:
tmp = df.groupby([col]).size().sort_values(ascending=False).cumsum() / 600000
feature_list = tmp[tmp<=0.95]
categorical_columns_dict[col] = feature_list.index.tolist()
# 构造feature_column
fm_first_order_fc = []
for col in numeric_columns:
fc = tf.feature_column.numeric_column(col)
fm_first_order_fc.append(fc)
for col in categorical_columns:
fc = tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list(
col,
categorical_columns_dict[col]
)
)
fm_first_order_fc.append(fc)
#print(fm_first_order_fc)
# 由于deepFM不是预定义模型,所以我们不能直接把feature_column作为参数输入到模型里,
# 必须通过input_layer接口转化成tensor,构造出feature_column对应的训练样本
fm_first_order_ip = tf.compat.v1.feature_column.input_layer(features, fm_first_order_fc)
print(fm_first_order_ip[0:2])
# fm_first_order_ip.shape=[1000. 1095],这表明连续特征+离散特征one-hot编码后,拼接在一块,一共有1095维度的特征
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column.py:206: IndicatorColumn._get_dense_tensor (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column.py:2167: IndicatorColumn._transform_feature (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column_v2.py:4410: VocabularyListCategoricalColumn._get_sparse_tensors (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column.py:2167: VocabularyListCategoricalColumn._transform_feature (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column_v2.py:4412: IndicatorColumn._variable_shape (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column_v2.py:4437: VocabularyListCategoricalColumn._num_buckets (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column.py:206: NumericColumn._get_dense_tensor (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column.py:2167: NumericColumn._transform_feature (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
WARNING:tensorflow:From C:\Users\admin\anaconda3\envs\tf2.2\lib\site-packages\tensorflow\python\feature_column\feature_column.py:207: NumericColumn._variable_shape (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
The old _FeatureColumn APIs are being deprecated. Please use the new FeatureColumn APIs instead.
tf.Tensor(
[[1. 0. 0. ... 7.645876 3.5263605 0. ]
[1. 0. 0. ... 4.4886365 1.9459101 0.6931472]], shape=(2, 19320), dtype=float32)
FM 二阶部分和deep部分公用的embedding特征
因为连续特征也需要embedding,这里对这类特征的处理方法是通过一个Dense网络,得到embedding_dim维的输出,但是具体实现放在Model里面完成。所以对于连续的特征做embedding的输入问题,我们直接把连续特征输入给模型就行。离散特征的embedding输入通过feature_column来实现即可。
# 一阶部分的输入数据构造完成后,需要构造fm二阶部分和deep部分需要的embedding输入,二者公用一份embedding数据
# 连续特征的embedding和离散型数据的embedding有一些区别,连续性特征做embedding后需要乘以自身的值,离散型one-hot编码本身默认是1,embedding后
# 不要再乘以自身的值
# 连续特征先做Numeric转化,然后通过一个Dense网络来embedding
fm_second_order_numric_fc = []
for col in numeric_columns:
fc = tf.feature_column.numeric_column(col)
fm_second_order_numric_fc.append(fc)
embedding_dim = 16
fm_second_order_cate_fc = []
for col in categorical_columns:
fc = tf.feature_column.embedding_column(
tf.feature_column.categorical_column_with_vocabulary_list(col
, categorical_columns_dict[col])
, embedding_dim
)
fm_second_order_cate_fc.append(fc)
# 通过input_layer转化成 tensor
fm_second_order_numric_ip = tf.compat.v1.feature_column.input_layer(features, fm_second_order_numric_fc)
fm_second_order_numric_ip = tf.reshape(fm_second_order_numric_ip,(-1,1,len(numeric_columns)))
fm_second_order_cate_ip = tf.compat.v1.feature_column.input_layer(features, fm_second_order_cate_fc)
# print(fm_second_order_numric_ip[0:2])
# print(fm_second_order_cate_ip[0:2])
构造DeepFM 模型
接下来,我们就要构造deepFM 模型了,你可以认为以上的工作和下面的工作是两个相对独立的部分。上面的工作就是为了下面定义的模型构造训练数据,我们可以使用feature_column+input_layer来构造训练数据也可以通过其他API来构造。但是,有一定要注意:一定要确保模型定义的输入数据格式与我们构造的训练数据的格式一致。
关于Model的定义,我这里不再赘述了。
# 构造deepfm模型
# 一阶部分
fm_first_order_dim = fm_first_order_ip.shape[1]
fm_first_order_input = tf.keras.Input(shape=(fm_first_order_dim), name='fm_first_oder_Input')
fm_first_order_output = tf.keras.layers.Dense(1, activation=tf.nn.relu, name='fm_first_oder_Output')(fm_first_order_input)
print(fm_first_order_input)
print(fm_first_order_output)
Tensor("fm_first_oder_Input:0", shape=(None, 19320), dtype=float32)
Tensor("fm_first_oder_Output/Identity:0", shape=(None, 1), dtype=float32)
# 由于fm二阶部分和deep部分都需要并且共用embedding部分,我们先定义embedding部分
# numeric的embedding
embedding_numeric_Input = tf.keras.Input(shape=(1,len(numeric_columns)), name='embedding_numeric_Input')
print(embedding_numeric_Input)
input_tmp = []
for sli in range(embedding_numeric_Input.shape[2]): # 输入的连续特征中每一个特征通过有个Dense网络得到一个dim维度的嵌入表示
tmp_tensor = embedding_numeric_Input[:,:,sli]
name=("sli_%d"%sli)
tmp_tensor = tf.keras.layers.Dense(embedding_dim, activation=tf.nn.relu, name=name)(tmp_tensor)
input_tmp.append(tmp_tensor)
embedding_numeric_Input_concatenate = tf.keras.layers.concatenate(input_tmp, axis=1, name='numeric_embedding_concatenate')
print(embedding_numeric_Input_concatenate)
embedding_cate_Input = tf.keras.Input(shape=(len(categorical_columns)* embedding_dim), name='cat_embedding_Input')
# embedding_cate_Input = tf.reshape(embedding_cate_Input,(-1, len(categorical_columns),embedding_dim))
print(embedding_cate_Input)
embedding_Input = tf.keras.layers.concatenate([embedding_numeric_Input_concatenate, embedding_cate_Input], 1)
print(embedding_Input)
embedding_Input = tf.reshape(embedding_Input,(-1, 11, embedding_dim))
Tensor("embedding_numeric_Input:0", shape=(None, 1, 6), dtype=float32)
Tensor("numeric_embedding_concatenate/Identity:0", shape=(None, 96), dtype=float32)
Tensor("cat_embedding_Input:0", shape=(None, 80), dtype=float32)
Tensor("concatenate/Identity:0", shape=(None, 176), dtype=float32)
# fm二阶部分
sum_then_square = tf.square(tf.reduce_sum(embedding_Input, 1))
print(sum_then_square)
square_then_sum = tf.reduce_sum(tf.square(embedding_Input) , 1)
print(square_then_sum)
fm_second_order_output = tf.subtract(sum_then_square, square_then_sum)
Tensor("Square:0", shape=(None, 16), dtype=float32)
Tensor("Sum_1:0", shape=(None, 16), dtype=float32)
# deep部分
deep_input = tf.reshape(embedding_Input
, (-1, (len(numeric_columns)+len(categorical_columns))*embedding_dim)
, name='deep_input'
)
print(deep_input)
deep_x1 = tf.keras.layers.Dense(64, activation=tf.nn.relu, name='deep_x1')(deep_input)
deep_output = tf.keras.layers.Dense(16, activation=tf.nn.relu, name='deep_x2')(deep_x1)
print(deep_output)
Tensor("deep_input:0", shape=(None, 176), dtype=float32)
Tensor("deep_x2/Identity:0", shape=(None, 16), dtype=float32)
# concat output
deep_fm_out = tf.concat([fm_first_order_output, fm_second_order_output, deep_output], axis=1, name='caoncate_output')
print(deep_fm_out)
deep_fm_out = tf.keras.layers.Dense(1, activation=tf.nn.sigmoid, name='final_output')(deep_fm_out)
print(deep_fm_out)
Tensor("caoncate_output:0", shape=(None, 33), dtype=float32)
Tensor("final_output/Identity:0", shape=(None, 1), dtype=float32)
# 建立模型,注意这是一个多输入单数输出的模型
model = tf.keras.Model(inputs=[fm_first_order_input, embedding_numeric_Input, embedding_cate_Input], outputs=deep_fm_out)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','AUC'])
model.summary()
tf.keras.utils.plot_model(model,to_file='DeepFM_V2.png', show_shapes=True)
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
embedding_numeric_Input (InputL [(None, 1, 6)] 0
__________________________________________________________________________________________________
tf_op_layer_strided_slice (Tens [(None, 1)] 0 embedding_numeric_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_strided_slice_1 (Te [(None, 1)] 0 embedding_numeric_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_strided_slice_2 (Te [(None, 1)] 0 embedding_numeric_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_strided_slice_3 (Te [(None, 1)] 0 embedding_numeric_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_strided_slice_4 (Te [(None, 1)] 0 embedding_numeric_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_strided_slice_5 (Te [(None, 1)] 0 embedding_numeric_Input[0][0]
__________________________________________________________________________________________________
sli_0 (Dense) (None, 16) 32 tf_op_layer_strided_slice[0][0]
__________________________________________________________________________________________________
sli_1 (Dense) (None, 16) 32 tf_op_layer_strided_slice_1[0][0]
__________________________________________________________________________________________________
sli_2 (Dense) (None, 16) 32 tf_op_layer_strided_slice_2[0][0]
__________________________________________________________________________________________________
sli_3 (Dense) (None, 16) 32 tf_op_layer_strided_slice_3[0][0]
__________________________________________________________________________________________________
sli_4 (Dense) (None, 16) 32 tf_op_layer_strided_slice_4[0][0]
__________________________________________________________________________________________________
sli_5 (Dense) (None, 16) 32 tf_op_layer_strided_slice_5[0][0]
__________________________________________________________________________________________________
numeric_embedding_concatenate ( (None, 96) 0 sli_0[0][0]
sli_1[0][0]
sli_2[0][0]
sli_3[0][0]
sli_4[0][0]
sli_5[0][0]
__________________________________________________________________________________________________
cat_embedding_Input (InputLayer [(None, 80)] 0
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 176) 0 numeric_embedding_concatenate[0][
cat_embedding_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_Reshape (TensorFlow [(None, 11, 16)] 0 concatenate[0][0]
__________________________________________________________________________________________________
tf_op_layer_Sum (TensorFlowOpLa [(None, 16)] 0 tf_op_layer_Reshape[0][0]
__________________________________________________________________________________________________
tf_op_layer_Square_1 (TensorFlo [(None, 11, 16)] 0 tf_op_layer_Reshape[0][0]
__________________________________________________________________________________________________
tf_op_layer_deep_input (TensorF [(None, 176)] 0 tf_op_layer_Reshape[0][0]
__________________________________________________________________________________________________
fm_first_oder_Input (InputLayer [(None, 19320)] 0
__________________________________________________________________________________________________
tf_op_layer_Square (TensorFlowO [(None, 16)] 0 tf_op_layer_Sum[0][0]
__________________________________________________________________________________________________
tf_op_layer_Sum_1 (TensorFlowOp [(None, 16)] 0 tf_op_layer_Square_1[0][0]
__________________________________________________________________________________________________
deep_x1 (Dense) (None, 64) 11328 tf_op_layer_deep_input[0][0]
__________________________________________________________________________________________________
fm_first_oder_Output (Dense) (None, 1) 19321 fm_first_oder_Input[0][0]
__________________________________________________________________________________________________
tf_op_layer_Sub (TensorFlowOpLa [(None, 16)] 0 tf_op_layer_Square[0][0]
tf_op_layer_Sum_1[0][0]
__________________________________________________________________________________________________
deep_x2 (Dense) (None, 16) 1040 deep_x1[0][0]
__________________________________________________________________________________________________
tf_op_layer_caoncate_output (Te [(None, 33)] 0 fm_first_oder_Output[0][0]
tf_op_layer_Sub[0][0]
deep_x2[0][0]
__________________________________________________________________________________________________
final_output (Dense) (None, 1) 34 tf_op_layer_caoncate_output[0][0]
==================================================================================================
Total params: 31,915
Trainable params: 31,915
Non-trainable params: 0
__________________________________________________________________________________________________
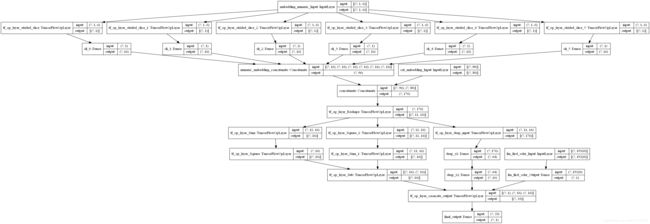
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z7UKIubw-1591016078697)(output_16_1.png)]
构造dataset
以上我们定义了一个完整的 DeepFM 模型,接下来需要我们定义训练数据集。我们上面定义了三个输入,这是三个输入对应三个数据集(注意,这些数据集的顺序是一致的,也和label一致),他们分别是:fm_first_order_ip,fm_second_order_numric_ip,fm_second_order_cate_ip。这也是我们刚开始通过feature_column+input_layer构造出来的tensor。
keras.Model的多输入和多输出参考官方文档。
# 构造dataset
input_tensor_dict = {
'fm_first_oder_Input':fm_first_order_ip
,'embedding_numeric_Input':fm_second_order_numric_ip
,'cat_embedding_Input': fm_second_order_cate_ip}
input_tensor_lable = {
'final_output':labels}
ds = tf.data.Dataset.from_tensor_slices((input_tensor_dict, input_tensor_lable)).shuffle(buffer_size=1024).batch(256).repeat(1)
history = model.fit(ds, epochs=20, verbose=2)
Epoch 1/20
235/235 - 8s - loss: 0.5202 - accuracy: 0.7588 - auc: 0.7159
Epoch 2/20
235/235 - 9s - loss: 0.5105 - accuracy: 0.7638 - auc: 0.7275
Epoch 3/20
235/235 - 9s - loss: 0.4974 - accuracy: 0.7694 - auc: 0.7435
Epoch 4/20
235/235 - 9s - loss: 0.4895 - accuracy: 0.7726 - auc: 0.7547
Epoch 5/20
235/235 - 9s - loss: 0.4812 - accuracy: 0.7775 - auc: 0.7655
Epoch 6/20
235/235 - 9s - loss: 0.4768 - accuracy: 0.7805 - auc: 0.7705
Epoch 7/20
235/235 - 9s - loss: 0.4694 - accuracy: 0.7841 - auc: 0.7798
Epoch 8/20
235/235 - 9s - loss: 0.4605 - accuracy: 0.7879 - auc: 0.7917
Epoch 9/20
235/235 - 9s - loss: 0.4528 - accuracy: 0.7939 - auc: 0.8013
Epoch 10/20
235/235 - 9s - loss: 0.4483 - accuracy: 0.7958 - auc: 0.8065
Epoch 11/20
235/235 - 9s - loss: 0.4407 - accuracy: 0.7997 - auc: 0.8151
Epoch 12/20
235/235 - 8s - loss: 0.4329 - accuracy: 0.8044 - auc: 0.8239
Epoch 13/20
235/235 - 9s - loss: 0.4290 - accuracy: 0.8068 - auc: 0.8280
Epoch 14/20
235/235 - 9s - loss: 0.4232 - accuracy: 0.8090 - auc: 0.8335
Epoch 15/20
235/235 - 9s - loss: 0.4154 - accuracy: 0.8135 - auc: 0.8420
Epoch 16/20
235/235 - 9s - loss: 0.4100 - accuracy: 0.8177 - auc: 0.8466
Epoch 17/20
235/235 - 9s - loss: 0.4071 - accuracy: 0.8181 - auc: 0.8489
Epoch 18/20
235/235 - 9s - loss: 0.3993 - accuracy: 0.8232 - auc: 0.8566
Epoch 19/20
235/235 - 9s - loss: 0.3950 - accuracy: 0.8255 - auc: 0.8596
Epoch 20/20
235/235 - 9s - loss: 0.3911 - accuracy: 0.8281 - auc: 0.8625
plot一下训练的结果
# plot auc
print(history.history)
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['auc'], label='auc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
{'loss': [0.5201764702796936, 0.5104863047599792, 0.49738621711730957, 0.48952317237854004, 0.4812459349632263, 0.4767757058143616, 0.46936988830566406, 0.46052131056785583, 0.4528360366821289, 0.44828882813453674, 0.44070738554000854, 0.43294769525527954, 0.4290182590484619, 0.4231511652469635, 0.41542136669158936, 0.41002124547958374, 0.40710189938545227, 0.3992616832256317, 0.3950413167476654, 0.3911369740962982], 'accuracy': [0.758816659450531, 0.7637666463851929, 0.7693666815757751, 0.772599995136261, 0.777483344078064, 0.7804999947547913, 0.7840833067893982, 0.7878999710083008, 0.7938666939735413, 0.7958499789237976, 0.7997333407402039, 0.8044166564941406, 0.8068000078201294, 0.8090166449546814, 0.8134666681289673, 0.8177000284194946, 0.8180500268936157, 0.8231833577156067, 0.8254500031471252, 0.828083336353302], 'auc': [0.7159219980239868, 0.7274761199951172, 0.7435243129730225, 0.7547236680984497, 0.7654938101768494, 0.7704871296882629, 0.7798182964324951, 0.7916975021362305, 0.8013037443161011, 0.8065210580825806, 0.8151246905326843, 0.8239383697509766, 0.8279644250869751, 0.8334710597991943, 0.8419550657272339, 0.846577525138855, 0.8489000797271729, 0.8565868139266968, 0.8596328496932983, 0.8625138998031616]}
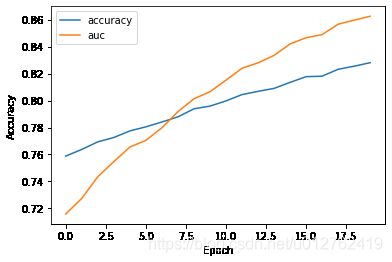 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a65GzYHd-1591016078699)(output_20_2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a65GzYHd-1591016078699)(output_20_2.png)]
结语
以上是本人在学习tensorflow2中做的一些探索,总的来说feature_column能一定程度上把开发人员从特征工程中解救出来,可以快速实现想要的特征embedding、cross等功能,可以和ectimator融合,但是对开发者自定义的Model兼容性比较差,如开发者想实现自己的Model,训练样本的构造不建议使用feature_column。