2019.01.25
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
Thomas N. Kipf, et al.
发表于ICLR2017,似乎从这篇paper开始很多人开始改进和应用GCN,GCN相关的课题也变得很火爆,目前引用量已经400多了。
主要思想:优化图卷积,通过切比雪夫多项式近似,不需要做特征分解和矩阵乘法,降低复杂度。

2019.01.26
Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs
Xiaolong Wang, et al.
发表于CVPR2018,作者Xiaolong Wang
主要思想:通过GCN学出每一类(category)的分类器参数向量,在pretrained CNN features上进行二分类的预测。
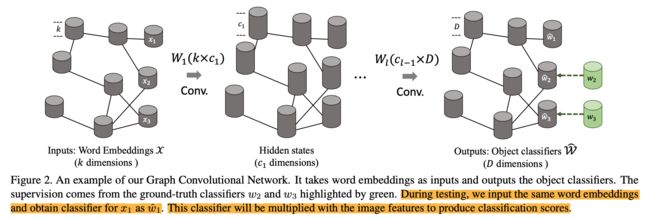
GCN中每个node代表一个category,node对应的特征向量为一个二分类分类器的参数向量,相当于逻辑回归,基于pretrained CNN features分类输入图片是否属于该category。训练GCN时,输入的node特征是每个category的semantic embedding vector,即使某些类没有训练样本,也能得到semantic embedding vector。之后经过6层GCN layer的学习,将semantic embedding vector转换为classifier weight vector,与有ground-truth的某些类的classifier weight vector算loss,经过反传不断优化后,学出没有训练样本的category的classifier weight vector,从而进行zero-shot recognition。
2019.01.27
Densely Connected Convolutional Networks
Gao Huang, et al.
CVPR2017 Best Paper,很厉害了。
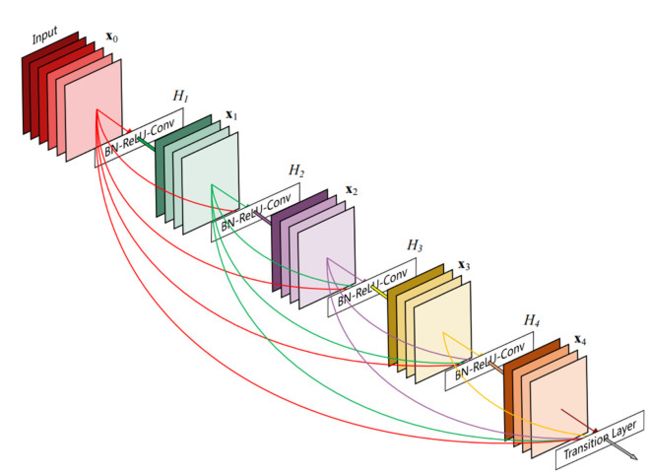
主要思想:每两层之间都有连接,同时每层的通道数都变少,相连接的层的通道数concat起来,中间还用了bottleneck降低计算量。因为每两层间都有连接,因此深层的监督信息可以比较好地反传到浅层去;同时深层特征也融合了所有浅层特征,表达能力得到增强。
作者的解释:在设计DenseNet时,我们让网络中的每一层都直接与其前面的层相连,实现特征的重复利用;同时把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是 DenseNet 与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象,即使 ResNet 也是如此。
2019.01.27
Non-local Neural Networks
Xiaolong Wang, et al.
发表于CVPR2018,Xiaolong Wang的另一篇。
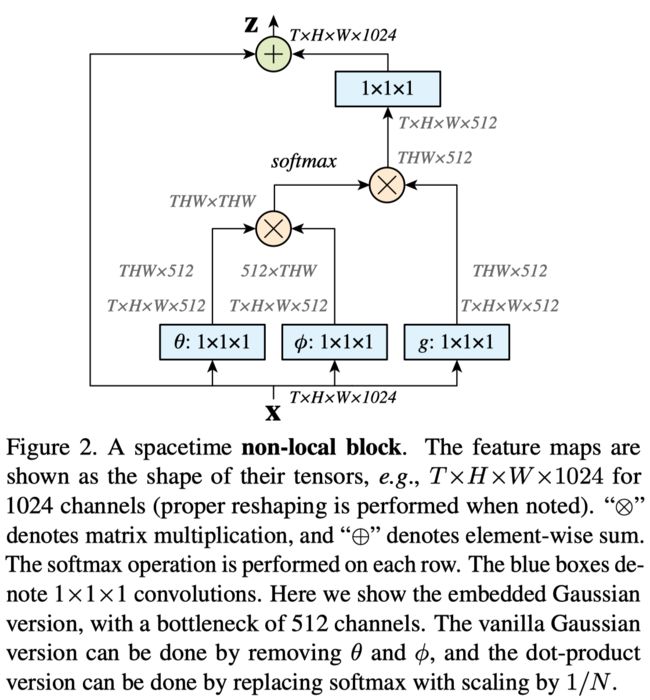
主要思想:普通CNN堆叠卷积层不能够很好地捕捉长程依赖(long range dependency),因此本文提出一种self-attention的方法,对于特征图中每个像素点,都用其他所有像素点的变换结果做加权求和,归一化后作为该像素点的新特征,相当于利用同一张图片中的其他像素点来增强当前像素点。
像素点之间的权重用函数f来衡量,函数g用来对原先的特征做线性变换。f和g的具体实现可以做很多文章,好几篇论文的思路其实都是利用self-attention机制,用图片中其他区域来增强当前区域,只不过用哪些区域,区域间的权重如何计算,如何对区域特征做变换,就有很多可以创新的地方。比如某几篇论文中就将CNN特征图变换成Graph特征,也就是把CNN特征图中的区域变成了Graph中的node,使用GCN对每个node都利用其他node做增强。区域之间的权重(即node之间的edge)可以是外部knowledge graph的edge,也可以是学出来的edge (以邻接矩阵的形式表示)。

2019.01.29
Videos as Space-Time Region Graphs
Xiaolong Wang, et al.
发表于ECCV2018,作者还是Xiaolong Wang,把GCN用在视频动作识别上。
主要思想:将视频表示为graph数据,具体操作是将T帧视频数据输入3D CNN中,输出T x H x W x d的特征图,在每一帧的特征图上使用RPN生成RoI,再进行RoI Align和Average Pooling,将每个RoI表示为d维vector。将T帧所有的N个RoI表示为graph的node,node feature即为d维vector。至于node之间的edge,有两种表示方式:
1. Similarity Graph
计算T帧全部N个RoI中两两之间的相似度,该相似度值经归一化后即为用来表示Similarity Graph的邻接矩阵(可看成node间edge的权重);
此图能够表示所有帧中所有物体间的关系,外形相似或语义相关的物体即使相隔很多帧,也能连上置信度高的边,就可以建模long range dependency和object state change。原文中对此图的解释如下:
(i) Similarity Relations: regions which have similar appearance or semantically related are connected together. With similarity relations, we can model how the states of the same object change and the long range dependencies between any two objects in any frames.
2. Spatial-Temporal Graph
(1)forward graph:计算第t帧中第i个RoI和第t+1帧中所有RoI(用j来索引)的IoU,若IoU大于0,则建立node i到node j的有向边;
(2)backward graph:计算第t+1帧中第j个RoI和第t帧中所有RoI(用i来索引)的IoU,若IoU大于0,则建立node j到node i的有向边。
所谓Spatial-Temporal Graph(时空图),就是把相邻帧中在空间和时间上都相邻的物体连上边,从而一定程度上建模human-object relation和object-object relation。原文中对此图的解释如下:
(ii) Spatial-Temporal Relations: objects which overlap in space and close in time are connected together via these edges. With spatial-temporal relations, we can capture the interactions between nearby objects as well as the temporal ordering of object state changes.
将视频数据表示为Graph后,就可以执行Graph Convolution,不过本文方法中有多个graph,因此在组合多个图上还有一些修改,最后是采用了两个分支各L层graph convolution,在最后的feature map上相加。
方法的整体框架图如下:
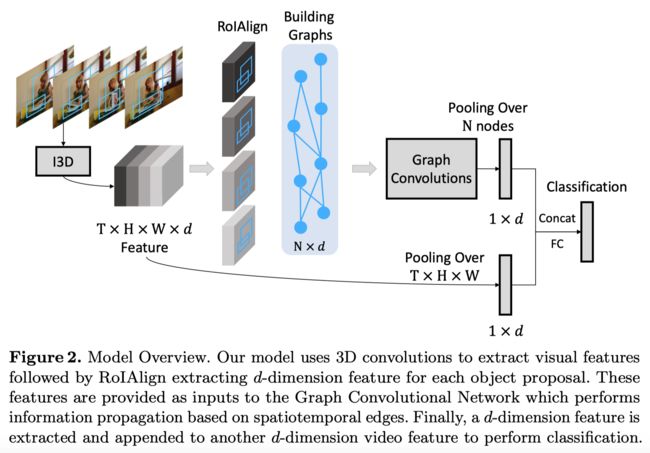
Connecting GCN and Non-local Net
文中在此节推出GCN的传播公式和Non-local的公式很像,因此在GCN的第一层也对node feature做了一次卷积来模仿Non-local,并说GCN和Non-local是互补的。
个人理解:
GCN和Non-local实际上是在不同的空间中做了同样的事情。
Non-local在Grid数据上对每个pixel,都用其他pixel特征的加权求和来增强该pixel的特征,所谓权重就可以看成是pixel之间的edge或者relation;
而GCN是在Graph数据上对每个node,都用其他与之相连的node特征的加权求和来增强该node的特征,所谓权重就是node间edge的权重,也可以看成node之间的relation。
总的来说,都是一种self-attention的机制,用某个数据的其他部分来增强当前部分,从而捕捉相隔较远的区域之间的关系。
How to construct graph
想要把GCN应用在CV任务上,一个重要的创新点就是如何把Image或Video表示成Graph。有些文章直接把CNN提取的特征图通过矩阵变换表示成Graph,比较暴力,而本文利用RoI来作为Graph的node,比较新颖,相当于是把object作为graph node。
本文作者Xiaolong Wang的另一篇paper 《Zero-shot recognition》是将图片的类别(category)作为graph node,node feature是分类器的weight vector,进而实现没有训练样本的类别的分类,这种构建graph的方式也比较机智。
而Xiaolong大佬的Non-local Net,个人觉得相当于把CNN特征图上每个pixel当成graph node,在grid数据上做类似GCN的操作。
2019.01.30
Learning Human-Object Interactions by Graph Parsing Neural Networks
Siyuan Qi, et al.
发表于ECCV 2018,来自UCLA朱松纯教授课题组,使用图神经网络来做HOI。
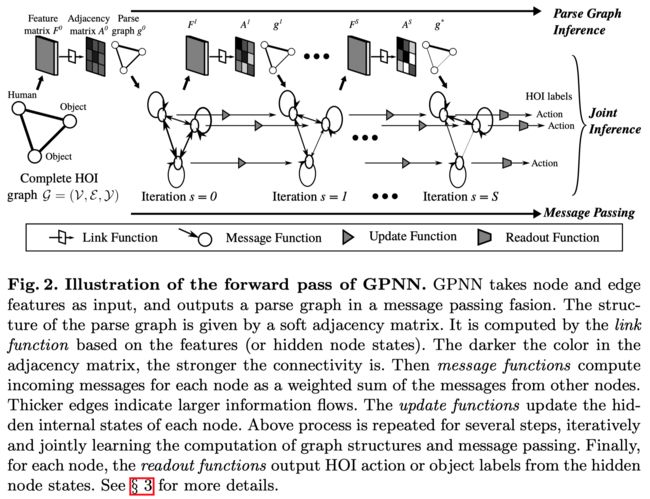
主要思想:使用预训练的detector检测出human和objects作为node,构成一个完整的(Complete)HOI Graph,即任意两个node之间都有edge,edge表示human-object interaction。此时的graph显然不是最优的,需要删掉某些没有意义的edge,并预测出每个node的label(即人物关系对应的action)才能得到最优的HOI Graph。这个从初始图获取最优图的过程显然可以通过迭代的方法实现。
文中定义了四种函数来执行迭代过程,预测最终的action label。
Link Function
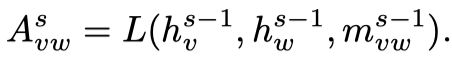
Link Function输入本结点 的hidden state (s表示迭代次数)和邻接结点 的hidden state 和edge feature 来计算邻接矩阵的值 ,学习一个soft adjacency matrix,相当于学习graph的结构。
具体实现时采用了一个或多个1x1 Conv, 为卷积的参数, 是node和edge的feature matrix,并加入了loss来监督graph结构的学习,实验证明学习graph的结构比固定graph的结构效果要好很多。
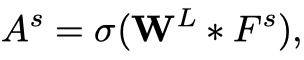
Message and Update Function
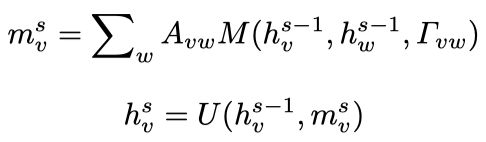
函数M聚合本结点和其邻接结点的hidden state以及edge feature,再以邻接矩阵中的值(表示连通性)作加权求和得到结点 的输入信息 ,该加权求和表示把所有邻接点的信息都聚合过来。
函数U利用结点 的输入信息 和上一次迭代的hidden state
来更新结点 的当前状态 。
具体实现时,Message Function采用全连接层FC+Concat+Sum,Update Function采用GRU。
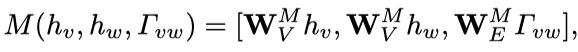
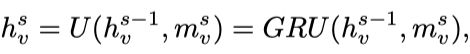
Readout Function
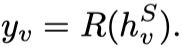
结点v的hidden state迭代至收敛后为 ,将其输入Readout Function,输出预测的action label ,具体实现时使用了全连接层FC,参数为 。
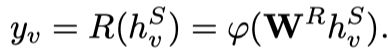
Framework
Comments
Human-Object Interaction的问题主要就是如何预测出人与物之间的关系,因为人和物通过detector就可以检测出,而预测关系其实就是预测一个动作(action)。本文所采用的方法就是检测出所有的人和物后,先构造一个全连接的graph,然后通过迭代优化,更新edge和node的feature,相当于不断学习人与物之间的关系,迭代至收敛后给每个node预测一个action label,获得HOI关系。
作者说本文的idea借鉴了Message Passing Neural Network,其实换成Graph Convolutional Network来实现是不是也可以呢?
另一方面,感觉本文的方法和Scene Graph Generation这篇论文的方法比较相似,贴张图在下面以供对比。
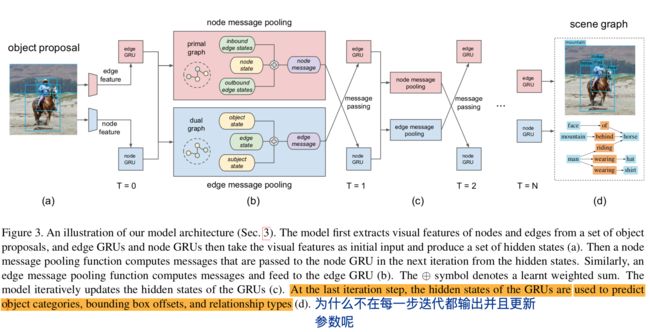
2019.01.31
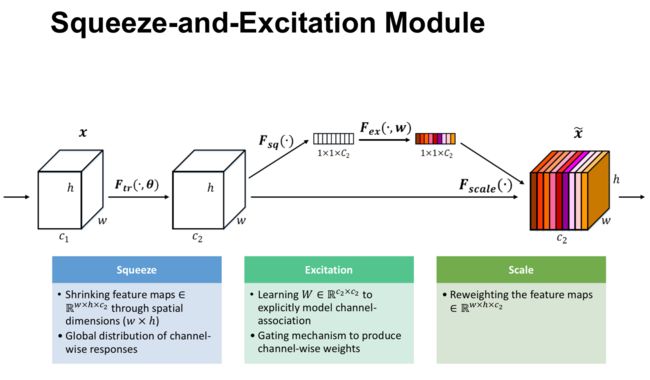
Squeeze-and-Excitation Networks
Jie Hu, et al.
好像是发表于CVPR2017,是Momenta公司ImageNet 2017 Image Classification竞赛的夺冠架构。
思想其实很简单,就是对特征图的每个channel学习一个权重再乘回去,表示该channel的重要性,是需要增强它还是抑制它。现在看来就是一个比较简单的channel-wise attention,但是两年前做出这个也是很厉害的~
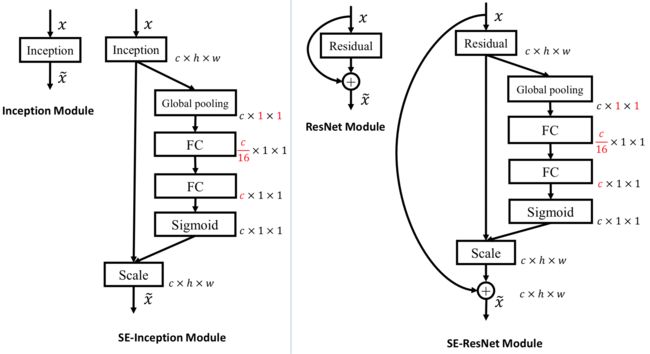
虽然方法比较简单,但是文中做了大量实验,将SE Module以各种方式插入到不同的网络中,证明了其泛化能力和有效性。
2019.02.05
Gather-Excite- Exploiting Feature Context in Convolutional Neural Networks
Jie Hu, et al.
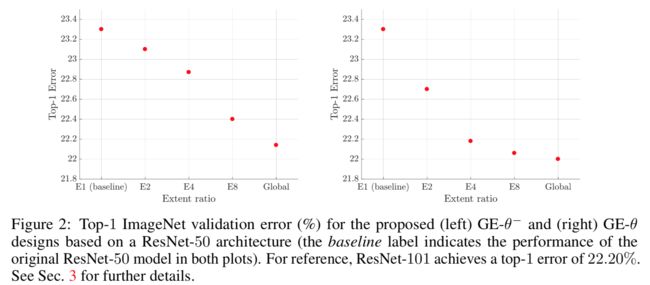
2019年的新Paper。SENet思想的泛化版。GE模块相比于SE模块,就是把一个channel一个权重(1 x 1 x C)变成了一个channel上有不同的权重(H x W x C)的feature map,然后再upsample成原来feature map的大小,乘回去做Attention。
相应的操作就从Global Average Pooling变成了不同size和stride的Pooling,这是无参数的方法,最后的结果还是Global Average Pooling的效果最好。
若是有参数的方法,就把pooling变成不同size和stride的Conv,结果也是当卷积为Global Conv时效果最好。对比无参数方法可以发现当增加模型可学习的参数数量时效果会有一定提升。