2、底层探索开篇alloc流程
一、准备阶段
1.创建非objc源码工程、iOS - App项目、
2.创建HSPerson类、并且声明几个属性
@interface HSPerson : NSObject
@property (nonatomic,copy)NSString *name;
@property (nonatomic,copy)NSString *hobby;
@property (nonatomic,assign)int age;
@property (nonatomic,assign)BOOL isBoy;
@end
3.获取一份编译好的objc-818源码备用、编译试错可参考
4.在ViewController中引入HSPerson类、并且alloc一个对象、

- 此时我们开启上帝视角、连下三个断点之前程序运行必走的符号断点、
libSystem_initializer
libdispatch_init
_objc_init

- 圈住部分为dyld加载流程当看过dyld加载流程之后、发现漏掉几个加载过程、之前笔记漏掉了这块。是从ImageLoader::recursiveInitialization 函数切入的、
void ImageLoader::recursiveInitialization(const LinkContext& context, mach_port_t this_thread, const char* pathToInitialize,
InitializerTimingList& timingInfo, UninitedUpwards& uninitUps)
{
......
// 初始化镜像
bool hasInitializers = this->doInitialization(context);
// 做标记让程序知道加载了完成镜像、下边会发通知
fState = dyld_image_state_initialized;
oldState = fState;
context.notifySingle(dyld_image_state_initialized, this, NULL);
if ( hasInitializers ) {
uint64_t t2 = mach_absolute_time();
timingInfo.addTime(this->getShortName(), t2-t1);
}
}
......
}
- 在上边函数内部进入 this->doInitialization(context) 做当前程序镜像的初始化操作
bool ImageLoaderMachO::doInitialization(const LinkContext& context)
{
CRSetCrashLogMessage2(this->getPath());
// mach-o 具有 -init 和静态初始值设定项
doImageInit(context);
doModInitFunctions(context);
CRSetCrashLogMessage2(NULL);
return (fHasDashInit || fHasInitializers);
}
5.libSystem_initializer断点函数的由来
- 找了良久没有发现libSystem_initializer的跳转加载、但是反向推断、感觉是从dyld_priv.h文件中_dyld_initializer 定义推断上层调用函数为 libSystem_initializer
// called by libSystem_initializer only
extern void _dyld_initializer(void);
- 根据libSystem_initializer符号断点处、可以看到我们其中接下来调用的初始化函数有如下这些:
- 也就是dyld加载之后、main函数之前走的一些加载函数、如果断点断不住、那么可能因为系统有断点白名单、需要打开白名单才能段住系统的一些函数。暂不提供方法。
__libkernel_init
__init_libsystem_sim_kernel
__libplatform_init
__init_libsystem_sim_platform
libSystem_initializer.libpthread_funcs
__init_libsystem_sim_pthread
libSystem_initializer.libc_funcs
_libc_initializer
_dyld_initializer
libdispatch_init
_libxpc_initializer
_container_init
__libdarwin_init
libSystem_initializer.malloc_funcs
__stack_logging_early_finished
6._objc_init: 根据 dyld-750 加载流程的探索、
- 通过下dyld::registerObjCNotifiers(mapped, init, unmapped);下符号断点、在_dyld_objc_notify_register上、溯源得到 _objc_init 调用。
二、非源码工程探索阶段
1.编写探索案例
- (void)viewDidLoad {
[super viewDidLoad];
HSPerson *p = [HSPerson alloc];
HSPerson *p1 = [p init];
HSPerson *p2 = [p init];
NSLog(@"%@ %p",p,p);
NSLog(@"%@ %p",p1,p1);
NSLog(@"%@ %p",p2,p2);
}
2.此时此刻、我们想知道的是操作了同一个p对象、p、p1、p2三者的关系如何?
- 结果是一模模一样样
2021-06-06 17:27:56.313308+0800 HSAlloc[11278:1718697] <HSPerson: 0x600002260800> 0x600002260800
2021-06-06 17:27:56.313663+0800 HSAlloc[11278:1718697] <HSPerson: 0x600002260800> 0x600002260800
2021-06-06 17:27:56.313995+0800 HSAlloc[11278:1718697] <HSPerson: 0x600002260800> 0x600002260800
- 当前通过alloc创建对象时、已经开辟了内存、有了指针指向
- 经过init之后、p1、p2对象所指向的内存空间是 一样的。说明init没有对他们进行指针操作。
3.当对他们取地址时、他们的地址是否时一样的呢?
2021-06-06 17:47:16.451717+0800 HSAlloc[11721:1819862] <HSPerson: 0x600002714a00> 0x600002714a00 0x7ffee553a118
2021-06-06 17:47:16.452099+0800 HSAlloc[11721:1819862] <HSPerson: 0x600002714a00> 0x600002714a00 0x7ffee553a110
2021-06-06 17:47:16.452548+0800 HSAlloc[11721:1819862] <HSPerson: 0x600002714a00> 0x600002714a00 0x7ffee553a108
- 此时看到、他们地址并不相同、这是因为
- 当 alloc出来后、他们有了一片相同的内存空间、三个指针地址都指向了这一片内存空间、但是他们之间的差值为8字节、可以看出指向的这片内存空间是连续的
(lldb) ho address 0x7ffee553a108
address : 0x7ffee553a108, stack address (SP:0x7ffee553a100 FP: 0x7ffee553a140) -[ViewController viewDidLoad]
(lldb)
- 并且可以看出他们这片空间存在于栈区
当我们想要看一看 alloc底层到底操作了什么时、我们点击系统函数、并不能看到实现部分。接下来我们来引入多种探索底层调用符号的方式。
三、三种探索方式
我们想要探索alloc 的调用流程、需要先在创建处打上断点

1.在断点处、通过 Ctrl + Step into的方式、让其跳入内部实现的汇编部分、如下
HSAlloc`objc_alloc:
-> 0x106268326 <+0>: jmpq *0x1d14(%rip) ; (void *)0x0000000106268380
- 再次如上方式操作可以看到汇编部分函数跳转指令的代码
-> 0x106268380: pushq $0x3f
0x106268385: jmp 0x10626835c
0x10626838a: pushq $0x51
0x10626838f: jmp 0x10626835c
0x106268394: pushq $0x70
0x106268399: jmp 0x10626835c
- 此时我们通过下符号断点 objc_alloc

- 得到系统内部调用的函数为
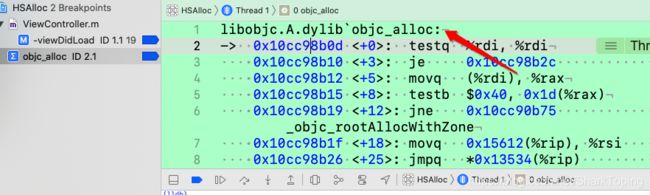
2.通过汇编的callq函数调用来看调用的符号 - Debug — Debug Workflow – Always Show Disassembly

- 此时调试运行、可以看到汇编符号

- 当通过Ctrl + Step into后、会看到在callq处跳转进入汇编函数内部

3.来到断点处时、我们只能模糊的知道我们想要的符号与alloc有关 - 所以我们直接通过符号断点下 alloc符号、此时此刻我们看到依然可以调入调用处

总结三种探索方式: - 1: 符号断点 libobjc.A.dylib`objc_alloc:
- 2: 通过汇编跟流程符号断点: objc_alloc
- 3: 断点处调用符号未知 、通过符号断点下模糊断点得到: libobjc.A.dylib`+[NSObject alloc]:
四、alloc创建流程图
- 通过源码objc4-818、调试运行的到alloc底层的创建流程图
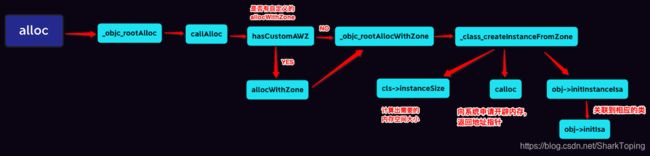
- 具体流程可参见 OC创建对象alloc流程
五、编译器优化
-
关于编译器优化、总结的是
-
None[-O0] 不优化:
在这种设置下, 编译器的目标是降低编译消耗,保证调试时输出期望的结果。
程序的语句之间是独立的:如果在程序的停在某一行的断点出,我们可以给任何变量赋新值抑或是将程序计数器指向方法中的任何一个语句,并且能得到一个和源码完全一致的运行结果。 -
Fast[-O1]大函数所需的编译时间和内存消耗都会稍微增加:
在这种设置下,编译器会尝试减小代码文件的大小,减少执行时间,但并不执行需要大量编译时间的优化。
在苹果的编译器中,在优化过程中,严格别名,块重排和块间的调度都会被默认禁止掉。此优化级别提供了良好的调试体验,堆栈使用率也提高,并且代码质量优于None[-O0]。 -
Faster[-O2]编译器执行所有不涉及时间空间交换的所有的支持的优化选项:
是更高的性能优化Fast[-O1]。在这种设置下,编译器不会进行循环展开、函数内联或寄存器重命名。
和Fast[-O1]项相比,此设置会增加编译时间,降低调试体验,并可能导致代码大小增加,但是会提高生成代码的性能。 -
Fastest[-O3] 在开启
Fast[-O1]项支持的所有优化项的同时,开启函数内联和寄存器重命名选项:
是更高的性能优化Faster[-O2],指示编译器优化所生成代码的性能,而忽略所生成代码的大小,有可能会导致二进制文件变大。还会降低调试体验。 -
Fastest, Smallest[-Os] 在不显着增加代码大小的情况下尽量提供高性能:
这个设置开启了Fast[-O1]项中的所有不增加代码大小的优化选项,并会进一步的执行可以减小代码大小的优化。
增加的代码大小小于Fastest[-O3]。与Fast[-O1]相比,它还会降低调试体验。 -
Fastest, Aggressive, Optimizations[-Ofast]
与Fastest, Smallest[-Os]`相比该级别还执行其他更激进的优化:
这个设置开启了Fastest[-O3]中的所有优化选项,同时也开启了可能会打破严格编译标准的积极优化,但并不会影响运行良好的代码。
该级别会降低调试体验,并可能导致代码大小增加。 -
Smallest, Aggressive Size Optimizations [-Oz] 不使用
LTO的情况下减小代码大小:
与-Os相似,指示编译器仅针对代码大小进行优化,而忽略性能优化,这可能会导致代码变慢。
六、内存对齐原则
参见内存对齐原则