linux启动过程
BIOS->MBR->引导加载程序->内核文件RIAD
raid0,同一份数据交替写入两个磁盘
raid1,同一份数据同时写入两个磁盘
raid5,三个磁盘,数据写入两个磁盘,往另外一个盘写入paritytcp报文头节点多少字节?
tcp报文头20字节,ip报文头20字节
MTU一般是1500字节
因此MSS一般最大1460字节k8s的 pod, deployment, 通过YAML文件 create 一个 pod ,中间发生了什么。 当我们提交一个YAML文件,k8s怎么处理
k8s有哪些核心组件
master上的组件:
API Server
Controller Manager
Scheduler
Node上的组件:
networking
kubelet
container runtime
volume plugin
device plugin
元数据存储:
Etcd
- schedule 的作用
第一个控制循环:informer path
启动一系列informer,用来监听etcd中的pod,node,service等与调度相关的API对象的变化
将pod放入priorityQueue
第二个循环:scheduling path
不断的从调度队列中出队一个pod,然后调用predicates算法进行过滤
再按照priorities算法对列表中的node打分
更新scheduler cache中的pod和node的信息,这种基于乐观假设API对象更新方式,在kubernetes中被称作Assume
Assume之后,调度器会创建一个Goroutine来异步地向APIServer发起更新pod的请求,来完成真正的Bind操作
当新的pod在某个节点上运行起来之前,该节点上的kubelet还会通过一个叫做Admit的操作来验证改pod是否确实能够运行在该节点上
抢占调度:
第一个队列,叫作 activeQ。凡是在 activeQ 里的 Pod,都是下一个调度周期需要调度的对象。
第二个队列,叫作 unschedulableQ,专门用来存放调度失败的 Pod。
- kublet的作用是?
设置listers,注册它所关心的各种事件的Informer,这些Informer,就是sync Loop需要处理的数据的来源
子控制循环:Volume Manager,Image Manager,Node Status Manager
通过控制器模式,完成kublet的某项具体职责
kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。
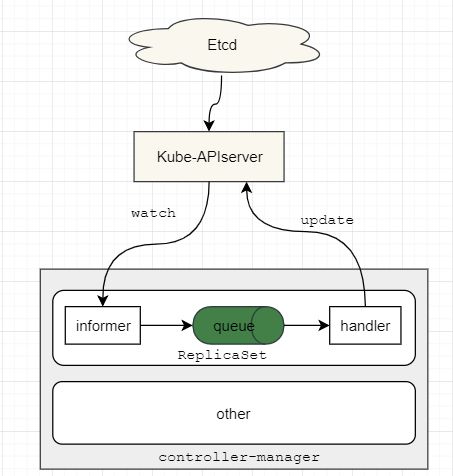
- controller-manager内部结构图
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
- https://www.jianshu.com/p/ac9179007fe2
- docker 的 namesapce 和 cgroup
pid
mount
network
ipc
uts
user
pids
cpu
cpuacct
cpuset
memory
net_cls
blkio
devices
- cgroup哪些参数可以对CPU做隔离
cpuacct.usage
cpuacct.usage_percpu
cpu.cfs_period_us
cpu.cfs_quota_us
k8s是平台层能力的变革?为什么
k8s怎么做水平拓展的
HPA简介
HPA全称Horizontal Pod Autoscaling,即pod的水平自动扩展。
自动扩展主要分为两种,其一为水平扩展,针对于实例数目的增减;其二为垂直扩展,即单个实例可以使用的资源的增减。HPA属于前者。
云计算具有水平弹性的特性,这个是云计算区别于传统IT技术架构的主要特性。对于Kubernetes中的POD集群来说,HPA可以实现很多自动化功能,比如当POD中业务负载上升的时候,可以创建新的POD来保证业务系统稳定运行,当POD中业务负载下降的时候,可以销毁POD来提高资源利用率。
工作方式
HPA的操作对象是RC、RS或Deployment对应的Pod
根据观察到的CPU等实际使用量与用户的期望值进行比对,做出是否需要增减实例数量的决策。
Horizontal Pod Autoscaling可以根据CPU使用率或应用自定义metrics自动扩展Pod数量(支持replication controller、deployment和replica set)。
控制管理器每隔30s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况
支持三种metrics类型
预定义metrics(比如Pod的CPU)以利用率的方式计算
自定义的Pod metrics,以原始值(raw value)的方式计算
自定义的object metrics
支持两种metrics查询方式:Heapster和自定义的REST API(Heapster 1.13版本开始废弃)
支持多metrics (建议metrics server)
客户端;
通过kubectl创建一个horizontalPodAutoscaler对象,并存储到etcd中
服务端:
api server:负责接受创建hpa对象,然后存入etcd
hpa controler和其他的controler类似,每30s同步一次,将已经创建的hpa进行一次管理(从heapster获取监控数据,查看是否需要scale, controler的store中就保存着从始至终创建出来的hpa,当做一个缓存),watch hpa有变化也会运行。
从heapster中获取scale数据,和hpa对比,计算cup利用率等信息,然后重新调整scale。
根据hpa.Spec.ScaleTargetRef.Kind(例如Deployment,然后deployment控制器在调整pod数量),调整其值,发送到apiserver存储到etcd,然后更新hpa到etcd.
- k8s的控制器模式和 普通的轮询有什么区别?
控制器模式:控制器通过 apiserver监控集群的公共状态,并致力于将当前状态转变为期望的状态。
一个控制器至少追踪一种类型的 Kubernetes 资源。这些 对象 有一个代表期望状态的 spec 字段。 该资源的控制器负责确保其当前状态接近期望状态。
- docker的文件系统是怎么做的
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
$ docker run -v /test ...
$ docker run -v /home:/test ...
只不过,在第一种情况下,由于你并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上。
而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
而这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
其实,如果你了解 Linux 内核的话,就会明白,绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。

正如上图所示,mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
所以,在一个正确的时机,进行一次绑定挂载,Docker 就可以成功地将一个宿主机上的目录或文件,不动声色地挂载到容器中。这样,进程在容器里对这个 /test 目录进行的所有操作,都实际发生在宿主机的对应目录(比如,/home,或者 /var/lib/docker/volumes/[VOLUME_ID]/_data)里,而不会影响容器镜像的内容。那么,这个 /test 目录里的内容,既然挂载在容器 rootfs 的可读写层,它会不会被 docker commit 提交掉呢?
也不会。
这个原因其实我们前面已经提到过。容器的镜像操作,比如 docker commit,都是发生在宿主机空间的。而由于 Mount Namespace 的隔离作用,宿主机并不知道这个绑定挂载的存在。所以,在宿主机看来,容器中可读写层的 /test 目录(/var/lib/docker/aufs/mnt/[可读写层 ID]/test),始终是空的。
不过,由于 Docker 一开始还是要创建 /test 这个目录作为挂载点,所以执行了 docker commit 之后,你会发现新产生的镜像里,会多出来一个空的 /test 目录。毕竟,新建目录操作,又不是挂载操作,Mount Namespace 对它可起不到“障眼法”的作用。
- docker的exec -ti , 底层是怎么做的
$ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d25686
$ ls -l /proc/25686/ns
total 0
lrwxrwxrwx 1 root root 0 Aug 13 14:05 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 net -> net:[4026532281]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid_for_children -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 uts -> uts:[4026532277]
可以看到,一个进程的每种 Linux Namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。有了这样一个可以“hold 住”所有 Linux Namespace 的文件,我们就可以对 Namespace 做一些很有意义事情了,比如:加入到一个已经存在的 Namespace 当中。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
而这个操作所依赖的,乃是一个名叫 setns() 的 Linux 系统调用。
这段代码的核心操作,则是通过 open() 系统调用打开了指定的 Namespace 文件,并把这个文件的描述符 fd 交给 setns() 使用。在 setns() 执行后,当前进程就加入了这个文件对应的 Linux Namespace 当中了。
$ ls -l /proc/28499/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:18 /proc/28499/ns/net -> net:[4026532281]
$ ls -l /proc/25686/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:05 /proc/25686/ns/net -> net:[4026532281]
在 /proc/[PID]/ns/net 目录下,这个 PID=28499 进程,与我们前面的 Docker 容器进程(PID=25686)指向的 Network Namespace 文件完全一样。这说明这两个进程,共享了这个名叫 net:[4026532281]的 Network Namespace。
MySQL事务隔离级别
MySQL如何解决慢查询,实际项目中怎么去优化,具体的问题,实际效果提升了多少,有做过测试吗?
后面有继续分析问题的瓶颈在哪里吗,最后压力测试的QPS
Redis和MySQL相比,为什么更快
Redis单线程为什么性能好
Redis的数据结构
Redis和数据库的使用场景上的区别
Redis和MySQL 性能差多少?
为什么MySQL的QPS很低
https://www.nowcoder.com/discuss/536707
k8s有哪些组件?
bloom filter实现原理
如果每天早上7点想ping一下美团的网站,整个ping过程持续三分钟,如果延迟超过100ms就发出警告给运维人员,并把所有ping的结果写入到日志中,设计一个脚本方案
如果想把ping的时间记录进去,怎么做
如果发生了100ms以上的延迟,怎么查找问题出在哪
OSPF与RIP的区别
Mysql高可用怎么做的
Mysql主从的原理,如果主库写了bin-log但是还没来得及发给从库就宕机了,怎么避免数据的丢失(我说了双主架构,所以就有下面的问题)
为什么要双主架构、双主架构的优势和劣势
RST标志位是什么?为什么需要这个标志位?什么时候需要
端口不可达linux内存:buffer cache swap讲下
Buffer cache 也叫块缓冲,是对物理磁盘上的一个磁盘块进行的缓冲,其大小为通常为1k,磁盘块也是磁盘的组织单位。
设立buffer cache的目的是为在程序多次访问同一磁盘块时,减少访问时间。
系统将磁盘块首先读入buffer cache,如果cache空间不够时,会通过一定的策略将一些过时或多次未被访问的buffer cache清空。
程序在下一次访问磁盘时首先查看是否在buffer cache找到所需块,命中可减少访问磁盘时间。不命中时需重新读入buffer cache。
对buffer cache的写分为两种,一是直接写,这是程序在写buffer cache后也写磁盘,要读时从buffer cache上读,二是后台写,程序在写完buffer cache后并不立即写磁盘,因为有可能程序在很短时间内又需要写文件,如果直接写,就需多次写磁盘了。
这样效率很低,而是过一段时间后由后台写,减少了多次访磁盘的时间。
Buffer cache是由物理内存分配,Linux系统为提高内存使用率,会将空闲内存全分给buffer cache ,当其他程序需要更多内存时,系统会减少cache大小。
Page cache 也叫页缓冲或文件缓冲,是由好几个磁盘块构成,大小通常为4k,在64位系统上为8k,构成的几个磁盘块在物理磁盘上不一定连续,文件的组织单位为一页, 也就是一个page cache大小,文件读取是由外存上不连续的几个磁盘块,到buffer cache,然后组成page cache,然后供给应用程序。
Page cache在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。
具体说是加速对文件内容的访问,buffer cache缓存文件的具体内容——物理磁盘上的磁盘块,这是加速对磁盘的访问。
- swap 作用, swap是在哪,在磁盘还是在内存上
Swap space交换空间,是虚拟内存的表现形式。
系统为了应付一些需要大量内存的应用,而将磁盘上的空间做内存使用,当物理内存不够用时,将其中一些暂时不需的数据交换到交换空间,也叫交换文件或页面文件中。
做虚拟内存的好处是让进程以为好像可以访问整个系统物理内存。
因为在一个进程访问数据时,其他进程的数据会被交换到交换空间中。