本文作为学习笔记,文章内容来自“极客时间”专栏《Redis核心技术与实战》,如有侵权,请告知,必即时删除。
1、String类型的一个优化案例
要开发一个图片存储系统,要求这个系统能快速地记录图片 ID 和图片在存储系统中保存时的 ID(可以直接叫作图片存储对象 ID)。同时,还要能够根据图片 ID 快速查找到图片存储对象 ID。因为图片数量巨大,所以我们就用 10 位数来表示图片 ID 和图片存储对象 ID,例如,图片 ID 为 1101000051,它在存储系统中对应的 ID 号是 3301000051。保存 1 亿张图片,大约用了 6.4GB 的内存。
photo_id: 1101000051
photo_obj_id: 3301000051
图片 ID 和图片存储对象 ID 都是 10 位数,我们可以用两个 8 字节的 Long 类型表示这两个 ID。因为 8 字节的 Long 类型最大可以表示 2 的 64 次方的数值,所以肯定可以表示 10 位数。但是,为什么 String 类型却用了 64 字节呢?其实,除了记录实际数据,String 类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了,有点“喧宾夺主”的意思。
当你保存 64 位有符号整数时,String 类型会把它保存为一个 8 字节的 Long 类型整数,这种保存方式通常也叫作 int 编码方式。但是,当你保存的数据中包含字符时,String 类型就会用简单动态字符串(Simple Dynamic String,SDS)结构体来保存,如下图所示:
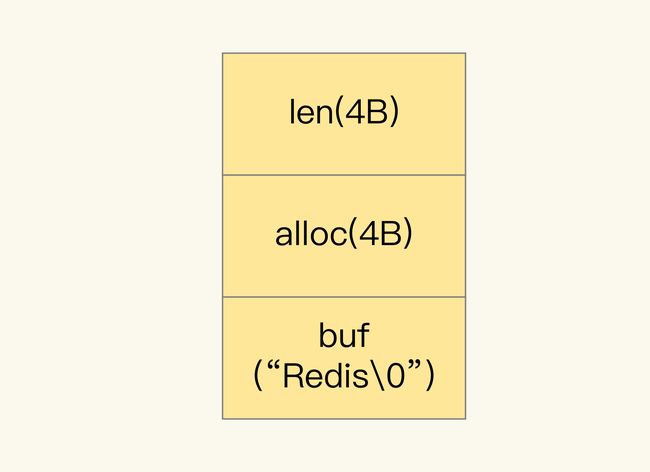
- buf:字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个“\0”,这就会额外占用 1 个字节的开销。
- len:占 4 个字节,表示 buf 的已用长度。
- alloc:也占个 4 字节,表示 buf 的实际分配长度,一般大于 len。
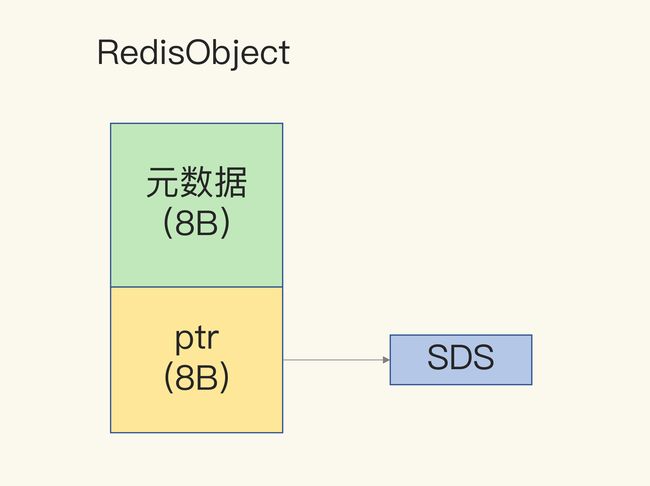
另外,对于 String 类型来说,除了 SDS 的额外开销,还有一个来自于 RedisObject 结构体的开销。因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,同时指向实际数据。
一个 RedisObject 包含了 8 字节的元数据和一个 8 字节指针,这个指针再进一步指向具体数据类型的实际数据所在,例如指向 String 类型的 SDS 结构所在的内存地址,可以看一下下面的示意图。
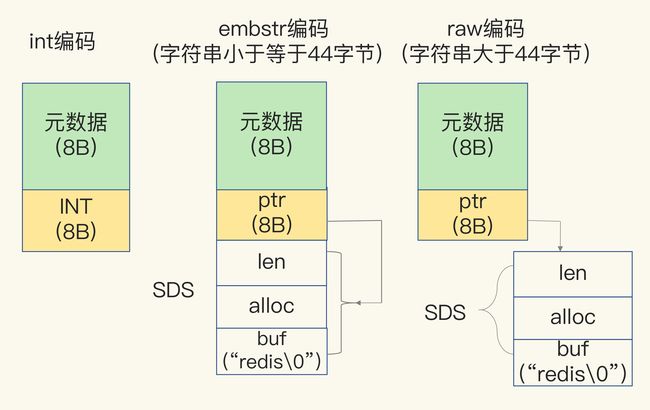
为了节省内存空间,Redis 还对 Long 类型整数和 SDS 的内存布局做了专门的设计。
- 当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
- 当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。
- 当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。
 13.jpg
13.jpg
Redis 会使用一个全局哈希表保存所有键值对,哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。dictEntry 结构中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节,如下图所示:

Redis 使用的内存分配库 jemalloc ,jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数,因此dictEntry 会占用32字节。
因为 10 位数的图片 ID 和图片存储对象 ID 是 Long 类型整数,所以可以直接用 int 编码的 RedisObject 保存。每个 int 编码的 RedisObject 元数据部分占 8 字节,指针部分被直接赋值为 8 字节的整数了。此时,每个 ID 会使用 16 字节,加起来一共是 32 字节。
使用String类型保存图片ID时,有效信息只占16字节,但是元数据信息却占用了48个字节。
优化方案
Redis 有一种底层数据结构,叫压缩列表(ziplist),这是一种非常节省内存的结构。表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量,以及列表中的 entry 个数。压缩列表尾还有一个 zlend,表示列表结束。

压缩列表之所以能节省内存,就在于它是用一系列连续的 entry 保存数据。每个 entry 的元数据包括下面几部分。
- prev_len,表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节,否则,就取值为5字节。
- len:表示自身长度,4 字节。
- encoding:表示编码方式,1 字节。
- content:保存实际数据。
一个图片的存储对象 ID 所占用的内存大小是 14 字节(1+4+1+8=14),实际分配 16 字节。
在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。二级编码方法中采用的 ID 长度是有讲究的。
Redis Hash 类型的两种底层实现结构,分别是压缩列表和哈希表。Hash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。这两个阈值分别对应以下两个配置项:
- hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
- hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
如果我们往 Hash 集合中写入的元素个数超过了 hash-max-ziplist-entries,或者写入的单个元素大小超过了 hash-max-ziplist-value,Redis 就会自动把 Hash 类型的实现结构由压缩列表转为哈希表。一旦从压缩列表转为了哈希表,Hash 类型就会一直用哈希表进行保存,而不会再转回压缩列表了。在节省内存空间方面,哈希表就没有压缩列表那么高效了。
如果想知道键值对采用不同类型保存时的内存开销,可以在http://www.redis.cn/redis_memory/里输入你的键值对长度和使用的数据类型,这样就能知道实际消耗的内存大小了。
2、聚合统计
统计手机 App 每天的新增用户数和第二天的留存用户数。要完成这个统计任务,我们可以用一个集合记录所有登录过 App 的用户 ID,同时,用另一个集合记录每一天登录过 App 的用户 ID。然后,再对这两个集合做聚合统计。我们来看下具体的操作。
记录所有登录过 App 的用户 ID 还是比较简单的,我们可以直接使用 Set 类型,把 key 设置为 user:id,表示记录的是用户 ID,value 就是一个 Set 集合,里面是所有登录过 App 的用户 ID,我们可以把这个 Set 叫作累计用户 Set。
累计用户 Set 中没有日期信息,我们是不能直接统计每天的新增用户的。所以,我们还需要把每一天登录的用户 ID,记录到一个新集合中,我们把这个集合叫作每日用户 Set。它有两个特点:key 是 user:id 以及当天日期,例如 user:id:20210503;value 是 Set 集合,记录当天登录的用户 ID。
2021年5月3日新增用户,就是累计用户Set和5月3日登录用户Set的差集。
SDIFFSTORE user:new user:id:20210503 user:id
在5月3日的时候,把当日登录用户Set并入到累计用户Set中。
UNIONSTORE user:id user:id user:id:20210503
5月4日留存用户数,即5月3日登录用户Set和5月4日登录用户Set的交集。
SINTERSTORE user:id:rem user:id:20210503 user:id:20210504
3、二值状态统计
这里的二值状态就是指集合元素的取值就只有 0 和 1 两种。在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态,这个时候,我们就可以选择 Bitmap,这是 Redis 提供的扩展数据类型。
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态。可以把 Bitmap 看作是一个 bit 数组。Bitmap 提供了 GETBIT/SETBIT 操作,使用一个偏移值 offset 对 bit 数组的某一个 bit 位进行读和写。
假设我们要统计 ID 3000 的用户在 2021 年 5 月份的签到情况,就可以按照下面的步骤进行操作。
//记录该用户5月3号已签到。
SETBIT uid:sign:3000:202105 2 1
//统计该用户在 5 月份的签到次数。
BITCOUNT uid:sign:3000:202105