一、什么是伪共享
CPU缓存系统中是以缓存行(cache line)为单位存储的。目前主流的CPU Cache的Cache Line大小都是64Bytes。在多线程情况下,如果需要修改“共享同一个缓存行的变量”,就会无意中影响彼此的性能,这就是伪共享(False Sharing)。我们先看下面几个例子, 来看一下现有的伪共享解决方案
二、如何解决伪共享
uid-generator中实现
在做false sharing的解释之前, 我们先来看一段百度的uid-generator中的源码
/**
* Represents a padded {@link AtomicLong} to prevent the FalseSharing problem
*
* The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:
* 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)
*
* @author yutianbao
*/
public class PaddedAtomicLong extends AtomicLong {
private static final long serialVersionUID = -3415778863941386253L;
/** Padded 6 long (48 bytes) */
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
/**
* Constructors from {@link AtomicLong}
*/
public PaddedAtomicLong() {
super();
}
public PaddedAtomicLong(long initialValue) {
super(initialValue);
}
/**
* To prevent GC optimizations for cleaning unused padded references
*/
public long sumPaddingToPreventOptimization() {
return p1 + p2 + p3 + p4 + p5 + p6;
}
}
在这里开源程序实现了一个PaddedAtomicLong的类用来规避伪共享。它试图在这个类中将整个缓存行占满, 防止别的线程操作同一缓存行数据, 那么它能达到希望实现的结果么? 我们来做一下验证
首先我们采用JOL来看一下PaddedAtomicLong实例的内存大小是怎么样的,
JOL的maven
org.openjdk.jol
jol-core
0.9
测试程序如下:
static void print(String message) {
System.out.println(message);
System.out.println("-------------------------");
}
public static void main(String[] args) throws InterruptedException {
print(ClassLayout.parseInstance(new PaddedAtomicLong()).toPrintable());
}
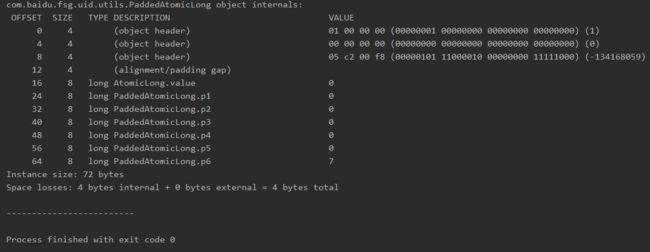
可以看到该类的实例占了72byte, 原来JVM给对象头分配了16byte, 而一个long类型占据了8byte, 显然该对象超过一个缓存行了。
第二步, 我们来测试一下, 该类当中的AtomicLong对象是否和p1-p6在同一个内存行, 这个就比较难办了, 没什么办法可以直接查看L1 cache, 我们可以采用一种查看结论的办法, 也就是说如果两个线程同时操作对象中的变量, 如果他们在不同的缓存行, 相互直接是不受影响的, 反之就会造成性能降低。 代码如下:
public class test{
public static void main(String[] args) throws InterruptedException {
testPointer(new PaddedAtomicLong());
}
private static void testPointer(PaddedAtomicLong pointer) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (long i = 0; i < 100000000; i++) {
pointer.incrementAndGet();
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 100000000; i++) {
pointer.p6++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer.get());
System.out.println(pointer.p1);
System.out.println(pointer.p2);
System.out.println(pointer.p3);
System.out.println(pointer.p4);
System.out.println(pointer.p5);
}
我们开启两个线程对PaddedAtomicLong中的元素进行累加100000000次,显然如果发生了伪共享同一条缓存行, 性能会和不同缓存行有差距, 为了防止编译器会将没用到的变量优化掉, 最后要将所有变量打印, 经过测试(随机器不同),t2线程中改变累加的变量, 最终的执行时间不同:
| t2线程累加变量 | 程序消耗时间 |
|---|---|
| p1 | 2700 |
| p2 | 2760 |
| p3 | 2605 |
| p4 | 860 |
| p5 | 825 |
| p6 | 820 |
我们可以得出一个不太精确的结论, 貌似AtomicLong中的value和p1,p2,p3在同一个缓存行, 而p4,p5,p6在不同的缓存行。 该对象显然占据了不止同一个缓存行, 如果我们把类中的p6去掉, 那对象应该正好64byte了, 理论上说应该正好占据同一个缓存行了, 我们再次测试一下:
| t2线程累加变量 | 程序消耗时间 |
|---|---|
| p1 | 2674 |
| p2 | 813 |
| p3 | 822 |
| p4 | 837 |
| p5 | 828 |
这下懵逼了, 显然依然没有在同一缓存行, 显然计算机并没有因为它正好是64byte就直接给他一条缓存行, 我的jdk是1.8的, 可以肯定的是在这个环境下通过补全无法达到消除伪共享。
@Contended
在Java 8中,可以采用@Contended在类级别上的注释,来进行缓存行填充。
Contended可以用于类级别的修饰,同时也可以用于字段级别的修饰,当应用于字段级别时,被注释的字段将和其他字段隔离开来,会被加载在独立的缓存行上。 我们拿JOL试一下, 看看是怎么实现隔离的。
@Contended
public volatile long usefulVal;
public volatile long anotherVal;
static void print(String message) {
System.out.println(message);
System.out.println("-------------------------");
}
public static void main(String[] args) throws InterruptedException {
print(ClassLayout.parseInstance( new tt()).toPrintable());
}
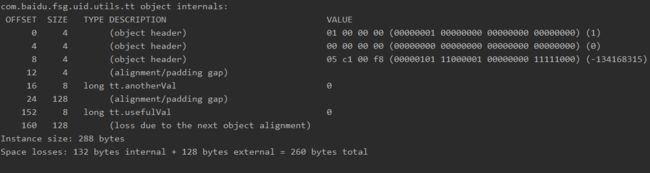
可以看到在usefulVal前后各插入了一个128byte的padding gap, 为什么要插入这么大呢? 参考
https://medium.com/@rukavitsya/what-is-false-sharing-and-how-jvm-prevents-it-82a4ed27da84

可见至少在JDK1.8以上环境下, 只有@Contended注解才能解决伪共享问题, 但是消耗也很大, 占用了宝贵的缓存, 用的时候要谨慎。
三、伪共享所需基础知识
CPU三级缓存
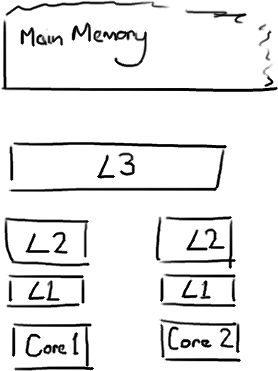
由于CPU的速度远远大于内存速度,所以CPU设计者们就给CPU加上了缓存(CPU Cache)。 以免运算被内存速度拖累。(就像我们写代码把共享数据做Cache不想被DB存取速度拖累一样),CPU Cache分成了三个级别:L1,L2,L3。越靠近CPU的缓存越快也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
缓存关联性
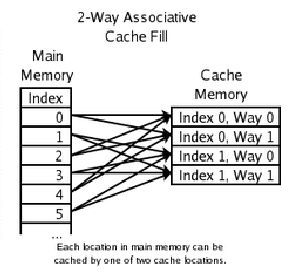
目前常用的缓存设计是N路组关联(N-Way Set Associative Cache),他的原理是把一个缓存按照N个Cache Line作为一组(Set),缓存按组划为等分。每个内存块能够被映射到相对应的set中的任意一个缓存行中。比如一个16路缓存,16个Cache Line作为一个Set,每个内存块能够被映射到相对应的Set
中的16个CacheLine中的任意一个。一般地,具有一定相同低bit位地址的内存块将共享同一个Set。
下图为一个2-Way的Cache。由图中可以看到Main Memory中的Index0,2,4都映射在Way0的不同CacheLine中,Index1,3,5都映射在Way1的不同CacheLine中。
MESI协议
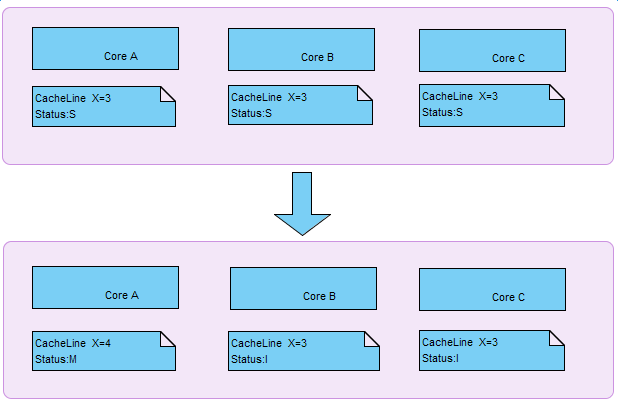
多核CPU都有自己的专有缓存(一般为L1,L2),以及同一个CPU插槽之间的核共享的缓存(一般为L3)。不同核心的CPU缓存中难免会加载同样的数据,那么如何保证数据的一致性呢,就是MESI协议了。
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
I(Invalid):这行数据无效。
那么,假设有一个变量i=3(应该是包括变量i的缓存块,块大小为缓存行大小);已经加载到多核(a,b,c)的缓存中,此时该缓存行的状态为S;此时其中的一个核a改变了变量i的值,那么在核a中的当前缓存行的状态将变为M,b,c核中的当前缓存行状态将变为I。如下图: