这是一本关于正则表达式的实验性书籍。与我在学习过程中发现的大多数regex资源相比,它主要是基于实例的可视化的。我还尝试选择一些突出一些常见陷阱的测试用例。我想你的时间是值得的。
本书的目标读者是正则表达式初学者。 有一定的编程经验。 它不涉及诸如引擎回溯和递归正则表达式等高级正则表达式概念,至少目前不涉及。
开源地址(英文)
前言
正则表达式(“ regexes”)允许定义模式并针对字符串执行它。 与模式匹配的子字符串称为“匹配项”。
A regular expression is a sequence of characters that define a search pattern.
正则表达式在以下方面发现了实用性:
: 输入验证
: 查找替换操作
: 高级字符串操作
: 文件搜索或重命名
: 白名单和黑名单
: ...
同时,正则表达式不适用于其他类型的问题:
: 解析 XML 或 HTML
: 完全吻合的日期
: ...
有几种正则表达式实现(正则表达式引擎),每个引擎都有自己的特性。本书将避免讨论这些特性之间的差异,而只讨论在大多数情况下跨引擎常见的特性。
本书中的示例块在底层使用JavaScript。因此,本书可能稍微偏向于JavaScript的正则引擎。
基本知识
正则表达式的格式通常为/ 。 为了简洁,人们通常会省略斜杠和标识。 在下一章中,我们将详细介绍标志。
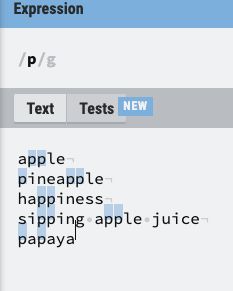
让我们从正则表达式/ p / g开始。 现在,请把g标志视为理所当然。
==注意:正则表达式默认是区分大小写的。==
/p /g 匹配所有小写的 p 字符。
字符类
可以从一组字符中匹配一个字符。
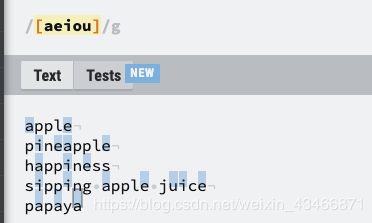
[aeiou]/g匹配输入字符串中的所有元音。
下面是另一个实际应用的例子:
/p[aeiou]t/g

在一个连续的范围内匹配一个字符有一个直观的快捷方式:
/[a-z]/g

==警告:Regex /[ a-z ]/g 只匹配一个字符。 在上面的示例中,每个字符串有几个匹配项,每个匹配项有一个字符长。不是一个长匹配==
我们可以在正则表达式中组合范围和单个字符:
/[A-Za-z0-9_-]/g

我们还可以“否定”这些规则:

本章的第一个正则表达式和
/[^aitou ]/g之间的唯一区别是紧接在开括号后的 ^ 。 其目的是否定括号内定义的规则。 我们现在说的是:匹配任何不属于 a,e,i,o 和 u 的字符
Examples
禁止用户名字符
[图片上传失败...(image-84fd74-1589002105674)]
明确的字符
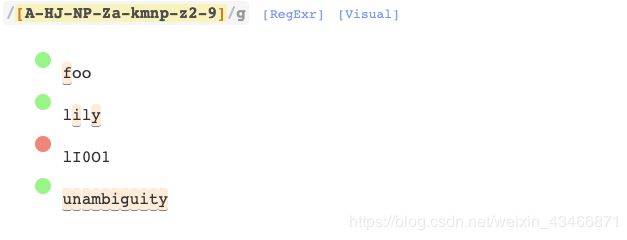
字符转义
字符转义作为一些常用字符类的短字符
数字字符ー\d
字符转义 d 匹配从0到9的数字字符。它等效于字符类[0-9]。

\D是\D的否定,等于[^0-9]。
单词字符— \w
转义\w匹配被视为单词的字符。这些包括小写字母表ーa–z 大写字母ーA–Z 数字ー0–9 下划线ー_
因此它等价于字符类[ a-zA-Z0-9]。

空白字符— \s
转义\s匹配空白字符。匹配的确切字符集取决于regex引擎,但大多数至少包括空格 Tab ー\t 回车ー\r 换行\n 跳页\f 很多还包括垂直制表符( v)。

任意字符— .
虽然不是典型的字符转义,但. 匹配任何[1]字符。

转义符
在正则表达式中,一些字符具有特殊的意义,我们将在下面的章节中探讨:
| {, } (, ) [, ] ^, $ +,*, ? \ . -仅在字符类中使用文字[2] - —有时是字符类中的特殊字符。
当我们希望逐字匹配这些字符时,我们需要“逃避”它们。
这是通过在字符前面加上\来实现的。


例子
JavaScript在线评论

星号包围的字符串

第一个星号和最后一个星号都是字面意义上的星号,因为它们是转义的*
字符类中的星号不一定需要逃避 [2],但为了清晰起见,我还是对它进行了逃避。
字符类后面的星号表示字符类的重复,我们将在后面的章节中对此进行探讨
分组
顾名思义,组意味着用于对正则表达式的组件进行“分组”。 这些群体可以用来:
- 提取匹配的子集
- 重复组任意次数
- 引用以前匹配的子字符串
- 提高可读性
- 允许复杂的变更
捕获组
捕获组用(...)表示。下面是一个说明性的例子:

捕获组允许提取匹配部分。

使用语言的regex函数,可以提取每个字符串的匹配大括号之间的文本。
捕获组也可用于对正则表达式部件进行分组,以减少所述组的重复。 我们将在接下来的章节中详细介绍重复,这里有一个示例演示组的用途。

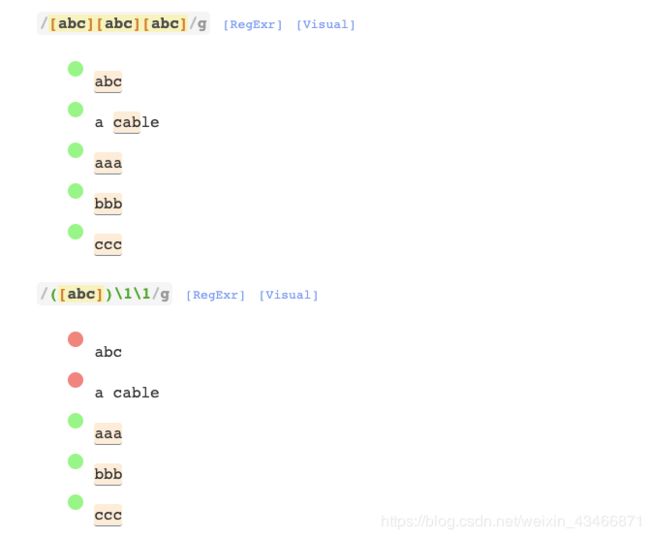
反向引用
反向引用允许引用以前捕获的子字符串。
第一组的匹配是\1,第二组的匹配是\2,以此类推..。

不能使用反向引用来减少正则表达式中的重复。它们指的是组的匹配,而不是模式。


非捕获匹配
非捕获组与捕获组非常相似,只是它们不创建“捕获”。 他们采取的形式是?: ... ).
非捕获组通常与捕获组一起使用。也许您正试图使用捕获组提取匹配的某些部分。您可能希望在不打乱捕获顺序的情况下使用一组。这就是非捕获组派上用场的地方。
例子
查询字符串参数
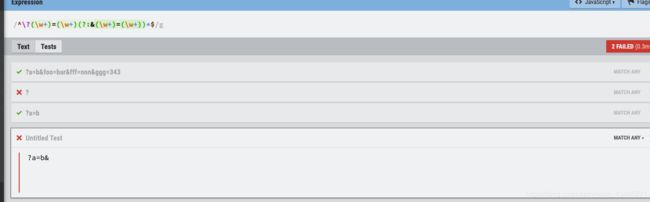
我们分别匹配第一个键值对,因为这允许我们使用&(分隔符)作为重复组的一部分。
(基本) HTML 标签
根据经验,不要使用正则表达式来匹配 xml / html.
尽管这样,这是一个相关的例子:
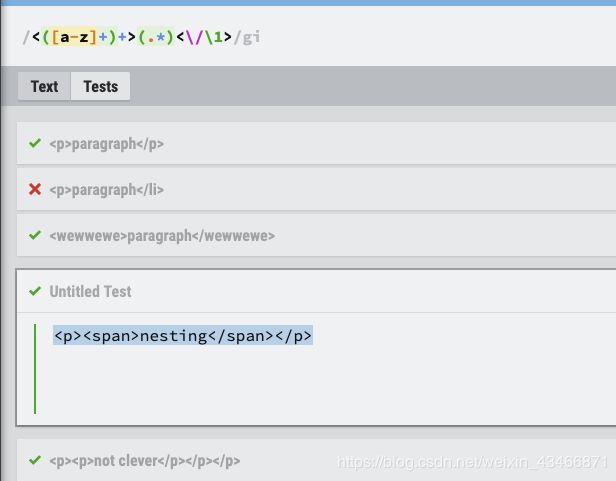
名字

反向引用和复数

重复
重复是一个强大且普遍存在的正则特性。在正则表达式中有几种表示重复的方法
让事情变得可选
我们可以使用? 操作符使正则表达式的部分可选

我们还可以将捕获组和非捕获组设为可选。

零个或多个子元素
如果我们希望匹配零个或多个令牌,可以使用 * 作为后缀。

我们的正则表达式甚至匹配一个空字符串“”。
一个或多个
如果我们希望匹配一个或多个令牌,可以使用 + 作为后缀。
正好是 x 次
如果我们希望匹配一个特定的标记正好 x 次,我们可以用{ x }作为后缀。 这在功能上等同于将令牌重复复制粘贴 x 次。

下面是一个匹配大写六字符十六进制颜色代码的示例。

在这里,标记{6}应用于字符类[0-9A-F ]。
在最小和最大时间之间
如果我们希望匹配 min 和 max (包含)时间之间的特定标记,可以使用{ min,max }作为后缀。

==在{ min,max }中逗号后面不能有空格。==
至少 x 次
如果我们希望匹配一个特定标记至少 x 次,我们可以使用{ x,}作为后缀。 把它想象成{ min,max } ,但是没有上界

关于贪婪的解释
默认情况下,正则表达式是贪婪的,它们试图尽可能地匹配。

将重复操作符(? ,* ,+ ,...)后缀为? ,可以使其变为“ 懒惰”。

这里,也可以通过使用[ ^ ”]代替. (这是最佳实践)来实现。

只要条件满足,懒惰就会停止,但贪婪意味着只有当条件不再满足时,它才会停止
---安德鲁在StackOverflow

例子
比特币地址

Youtube Video
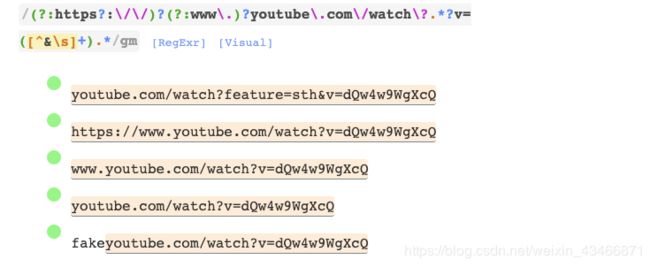
我们可以使用锚点进行调整,使其与最后一个断开的链接不匹配
未完待续。。。。。
-
除了换行字符\n。如果regex引擎支持,可以使用dotAll标志来更改它。 ↩
-
许多特殊字符在字符类中默认按字面处理,否则将具有特殊含义。 ↩ ↩