MAB的全称是 Multi-armed bandit problem(多臂老虎机问题)。它的背景是当赌场中有一排老虎机,每一台老虎机中奖的概率不同,有没有一种最优的策略来在各个老虎机之间分配自己的资金以实现收益的最大化。
我们可以把这个问题翻译成一个典型的推荐问题,有若干个item,每个item的曝光点击率不同,有没有一种最优的策略来分配item的曝光,从而让总体点击率最高。下面叙述中,我会统一采用推荐问题的术语,而不在用老虎机的术语。
当我们面对没有先验知识的item时,只能每个都去尝试一下,但很快我们就会遇到 Exploitation-Exploration(E&E) 两难的问题:
- 只把流量花在历史点击率高的item上,会错过其他可能会有更好的点击率表现的item,这个方法推到极端就是 winner gets all;
- 把流量花在到处探索上,就难免有较高的机会成本,不能积累到可观的收益,这个方法推到极端就是随机推荐。
bandit 算法是一类解决Exploitation-Exploration 问题的方法,根据是否考虑上下文特征,算法分为 context-free bandit 和 contextual bandit 两大类。
本篇主要介绍 context-free bandit 算法,这类算法可以认为是推荐系统中“千人一面”的算法,不考虑不同用户的差异性。
1、基本原理
(1)Epsilon-Greedy算法
首先,介绍一种最简单的算法。
选一个(0,1)之间较小的数epsilon,生成一个随机数,如果小于epsilon,则在所有item中选一个推荐,如果大于epsilon,则返回目前为止点击率最高的item。
这里epsilon的值可以控制对exploit和explore的偏好程度。
(2)Thompson sampling算法
想了解 Thompson sampling,就绕不开beta分布。知乎帖子(https://www.zhihu.com/question/30269898) 对beta分布有比较详细的介绍,这里会参照它进行介绍。
用一句话来说,beta分布可以看作一个二项分布期望值的概率分布。
举一个简单的例子,是用一个棒球运动员击中的球数除以击球的总数,就是击球率,我们一般认为0.266是正常水平的击球率,而如果击球率高达0.3就被认为是非常优秀的。
如果有一个棒球运动员,他的过往历史击球率是0.27,新赛季的第一场比赛,他击球10次,命中5次,我们可以说他现在的击球率是0.5吗?好像不太合理,那么用过往的0.27呢?好像也不太合理。
实际上,“他现在的击球率”这个概率值,也服从某个概率分布,对于二项分布来说,这个概率值的概率分布就是beta分布。
beta分布有 和 两个参数,可以表示成 ,这两个参数分别代表在历史击球中,成功次数和失败次数。
我们可以取 = 81, = 219,beta分布的概率密度图是这样的,可以看到期望为0.27
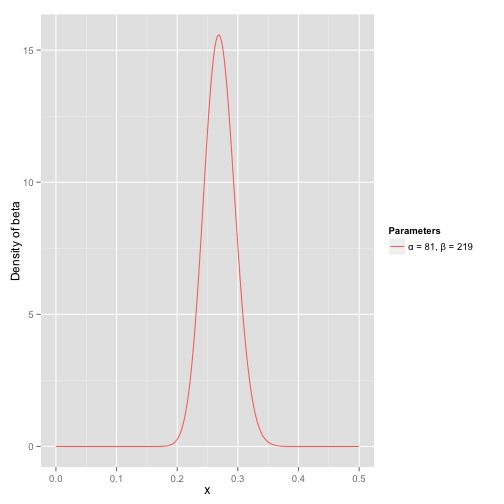
这位球员在新赛季击球10次中5次,那么我们就可以更新Beta分布的参数了 Beta(81+5, 219+10),期望变成了0.273。
如果这位球员继续延续高水平的表现,击球200次中100次,那么他的击球率的分布就变成了 Beta(81+100, 219+200),期望变成了0.303,并且我们可以从概率密度图看到,新的击球率分布变窄了,这也和我们直观上的感觉是一致的。
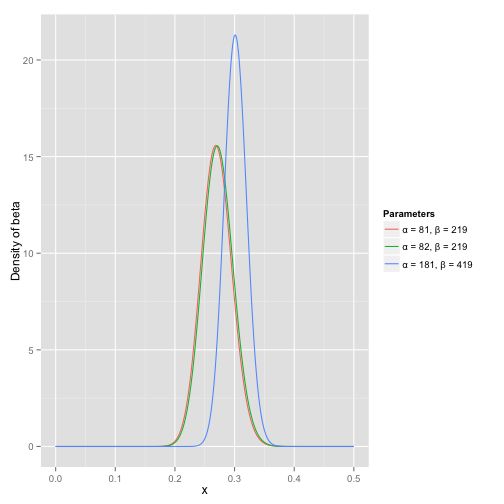
那么Thompson sampling算法的基本原理就是,每一个item的点击率都服从一个Beta分布,Beta(alpha, beta),这个是点击次数, 是曝光未点击的次数。
每个item都根据自己的Beta分布生成一个随机数,选择随机数最大的那个item。
(3)UCB算法
UCB是 Upper Confidence Bound 的简称。对于每个item的点击率p来说,假设历史观测的点击率是p’,那么我们可以认为,p实际是在p‘的邻域内的,我们可以假设
UCB算法就是使用真实值的上界 p‘+ 来进行乐观预估。
我们会有一些观察:
- 如果曝光的次数越多,应该越小,p'会越趋向于真实值p
- 如果一个item在多次曝光中总是不被选中,那么它的delta应该逐渐增大,以保证它后面有机会曝光
UCB算法中选择
其中,T是总实验次数,n是选中该item的次数。这么选择的数学原理可以参考这篇知乎帖子(https://zhuanlan.zhihu.com/p/32356077) ,这里直接略过。
2、代码
代码结构:
- item.py
- mab_algo.py
- mab_simulator.py
首先,我们抽象一个Item的类,它代表了推荐问题中的一个item,它会有一个自己真实的点击率(click_rate),会记录在实验中自己的曝光次数和点击次数,以及实验中观测到的点击率。
# item.py
import random
'''
定义被曝光的item
item有一个属性是点击率
每次被调用exposure函数时,都会随机返回1和0,返回1的概率是点击率
'''
class Item(object):
def __init__(self, click_rate):
self.click_rate = click_rate
self.click_cnt = 0
self.exposure_cnt = 0
def exposure(self):
rnd = random.random()
self.exposure_cnt = self.exposure_cnt + 1
if rnd <= self.click_rate:
self.click_cnt = self.click_cnt + 1
return 1
else:
return 0
def get_ctr(self):
if self.exposure_cnt == 0:
return 0.0
else:
return self.click_cnt / self.exposure_cnt
if __name__ == "__main__":
item = Item(0.1)
exposure_cnt = 10000
click_cnt = 0
for i in range(exposure_cnt):
item.exposure()
print('exposure: %d click: %d click_rate: %4.2f'
%(item.exposure_cnt, item.click_cnt, 1.0*item.click_cnt/item.exposure_cnt) )
然后,我们根据上面的介绍,分别实现三种 bandit 算法,并实现了一个随机算法作为对比:
# mab_algo.py
import random
import numpy as np
# UCB算法
# p = p' + np.sqrt(2*np.log(T) / N)
# T是总实验次数,n是选中该item的次数
def ucb_algo(item_list):
total_exposure_cnt = 0
for item in item_list:
total_exposure_cnt = total_exposure_cnt + item.exposure_cnt
upper_bound_probs = [item.get_ctr() + np.sqrt(2*np.log(1+total_exposure_cnt) / max(1, item.exposure_cnt)) \
for item in item_list]
return np.argmax(upper_bound_probs)
# Thompson sampling算法
def thompson_sampling_algo(item_list):
max_item_idx = 0
max_rand = -1
for idx, item in enumerate(item_list):
# beta(a, b), a should be larger than 0
rand = np.random.beta(1+item.click_cnt, 1+item.exposure_cnt - item.click_cnt)
if rand > max_rand:
max_item_idx = idx
max_rand = rand
return max_item_idx
# epsilon的概率是随机返回
# 1-epsilon的概率是选择当前效果最好的一个
def epsilon_greedy_algo(item_list):
epsilon = 0.2
rnd = random.random()
if rnd < epsilon:
# explore
return random.randint(0, len(item_list) - 1)
else:
# exploit
max_item_idx = 0
max_ctr = -1
for idx, item in enumerate(item_list):
if item.get_ctr() > max_ctr:
max_ctr = item.get_ctr()
max_item_idx = idx
return max_item_idx
# 随机返回
def random_algo(item_list):
return random.randint(0, len(item_list) - 1)
最后,我们写一个模拟器,来看一下不同算法的实际分配曝光的表现情况。
# mab_simulator.py
import random
from item import Item
from mab_algo import *
def get_exposure_item_idx(item_list, algo):
return algo(item_list)
def demo():
algo_list = [random_algo, epsilon_greedy_algo, thompson_sampling_algo, ucb_algo]
click_rate_list = [0.05, 0.06, 0.1, 0.12, 0.2]
exposure_cnt = 100000
for algo in algo_list:
print(algo)
item_list = []
for click_rate in click_rate_list:
item = Item(click_rate)
item_list.append(item)
for i in range(exposure_cnt):
idx = get_exposure_item_idx(item_list, algo)
item_list[idx].exposure()
for i in range(len(item_list)):
print('item #%d click_rate=%4.2f%%\texpo=%d click=%d real_click_rate=%4.2f%%'
%(I,
100*item_list[i].click_rate,
item_list[i].exposure_cnt,
item_list[i].click_cnt,
100.0*item_list[i].click_cnt/item_list[i].exposure_cnt))
if __name__ == "__main__":
demo()
3、实验
(1)实验设置
我们设定5个item,#0到#4,它们的真实点击率分别是5%、6%、10%、12%和20%。
共进行10万次实验(也就是10万次曝光机会),记录在不同算法下,每个item的曝光次数。
(2)实验结果
先看随机算法的结果,不出意外,每个item的曝光次数差不多。
item #0 click_rate=5.00% expo=20041 click=980 real_click_rate=4.89%
item #1 click_rate=6.00% expo=19813 click=1231 real_click_rate=6.21%
item #2 click_rate=10.00% expo=19946 click=1988 real_click_rate=9.97%
item #3 click_rate=12.00% expo=20193 click=2358 real_click_rate=11.68%
item #4 click_rate=20.00% expo=20007 click=3924 real_click_rate=19.61%
epsilon_greedy算法,实验中设置epsilon=0.2,也就是会有20%的曝光(2万次)会作为探索分配到各个item,实验结果也符合预期。
item #0 click_rate=5.00% expo=3995 click=180 real_click_rate=4.51%
item #1 click_rate=6.00% expo=3984 click=240 real_click_rate=6.02%
item #2 click_rate=10.00% expo=3995 click=396 real_click_rate=9.91%
item #3 click_rate=12.00% expo=3889 click=455 real_click_rate=11.70%
item #4 click_rate=20.00% expo=84137 click=16898 real_click_rate=20.08%
thompson_sampling算法将几乎全部的曝光机会都给了点击率最高的 item #4。这是因为实验设置的item之间的点击率差异还是很大的,在beta分布中体现了很明显的差距。
item #0 click_rate=5.00% expo=81 click=4 real_click_rate=4.94%
item #1 click_rate=6.00% expo=167 click=16 real_click_rate=9.58%
item #2 click_rate=10.00% expo=202 click=21 real_click_rate=10.40%
item #3 click_rate=12.00% expo=313 click=40 real_click_rate=12.78%
item #4 click_rate=20.00% expo=99237 click=19934 real_click_rate=20.09%
UCB算法也将大部分的曝光都给了 item #4,但没有thompson_sampling算法那么极端。
item #0 click_rate=5.00% expo=730 click=29 real_click_rate=3.97%
item #1 click_rate=6.00% expo=918 click=54 real_click_rate=5.88%
item #2 click_rate=10.00% expo=1773 click=183 real_click_rate=10.32%
item #3 click_rate=12.00% expo=1946 click=211 real_click_rate=10.84%
item #4 click_rate=20.00% expo=94633 click=19115 real_click_rate=20.20%
4、总结
context-free bandit 算法是一类非常简单的算法,它可以有效解决E&E问题,并且计算过程非常简单,在实际应用中,因为它天生应对冷启动,容易做到实时反馈的特点,在很多场景中依然是很有用的工具。
为了解决 context-free 无法做到千人千面的问题,有很多可以结合上下文的 bandit 算法,其中LinUCB,就是比较有代表性的一种,它来自于雅虎的新闻推荐算法:https://arxiv.org/pdf/1003.0146.pdf。
参考
- :https://www.jianshu.com/p/e7825a9596ef
- 知乎:https://www.zhihu.com/question/30269898
- 知乎:https://zhuanlan.zhihu.com/p/32356077