hikari简介以及相关的概念
"Simplicity is prerequisite for reliability."
- Edsger Dijkstra

hikari,日语中“光”的意思,作者为这个数据库连接池命名为光,寓意是像光一样快。在分析hikariCP之前简单介绍下JDBC和数据库连接池。
JDBC
全称Java Database Connectivity,java入门课本中基本都会介绍到的部分。
以常见的MySQL数据库为例,JDBC可以简单概括为就是一个jar包,这个jar包中提供了相应的interface与class,封装好了与MySQL服务端连接的协议,通过Java代码就可以实现mysql client上的select、update、delete等功能。

原始的JDBC使用姿势是这样的(爷青回):
try {
// 初始化驱动类com.mysql.jdbc.Driver
Class.forName("com.mysql.jdbc.Driver");
// 获取connection连接
conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=UTF-8","root", "admin");
// 查询
sql = "select * from test"
pstmt = (PreparedStatement) conn.prepareStatement(sql);
rs = (ResultSet) pstmt.executeQuery();
// 后续将ResultSet转化为对象返回...
} catch (ClassNotFoundException e) {
e.printStackTrace();
}catch (SQLException e) {
e.printStackTrace();
}
数据库连接池(Connection Pool)
以上DriverManager.getConnection建立jdbc连接的过程是很昂贵的,需要经历 TCP握手+MySQL认证,如果服务在不断并发处理多个请求的时候每次都重新建立JDBC连接并且在请求结束后关闭JDBC连接,那么将会导致:
- 网络IO多,因为不断的TCP握手和TCP关闭,大量新建后立刻关闭的TIME_WAIT状态的TCP连接占用系统资源
- 数据库负载高,数据库也要重新为连接建立各种数据结构,并且在短暂的查询结束后又要销毁
- 查询耗时长,多了TCP握手和MySQL认证的耗时。同时,不断产生又回收掉JDBC连接资源会频繁触发GC
为了能够 复用已经辛辛苦苦建立好的JDBC连接,就有了数据库连接池的概念,同理线程池、redis连接池、HBase连接池等等都同理。
数据库连接池应该具有的功能
- 在连接应用启动的时候建立连接,并且保存到Java的容器或自定义的容器中维护
- 在应用运行的过程中,间歇性测试连接的可用性(
select 1),踢出不可用的连接,加入新的连接 - 在应用结束后关闭JDBC连接
Spring-JDBC
基于以上原JDBC的使用方式可以看出,JDBC在使用上存在大量可以封装起来的功能(connection的获取、构造PreparedStatement、connection的回收等)。总之,Spring-JDBC通过对JDBC的封装,简化了SQL的执行步骤,我们只需要输入sql语句,框架会输出sql的执行结果(类似于mysql-client控制台的效果)。
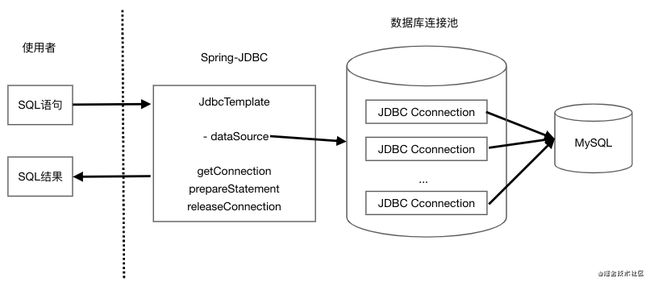
如上图,有了Spring-JDBC等框架封装JDBC连接获取,prepareStatement赋值,JDBC连接的释放,使用者就只需要写好sql,调用Spring-JDBC提供的JdbcTemplate类封装的方法,等待获取结果即可。
JdbcTemplate类会通过Spring依赖注入等方式设置好它的dataSource属性,而这个dataSource就是一个数据连接池(Connection Pool,CP),CP通过选择合适的数据结构来动态维护着与MySQL的Jdbc连接。整个封装起来对使用者来说无需感知,只需要知道输入SQL语句和输出结果就好。
hikari核心功能
HikariDataSource
HikariDataSource的继承结构
正如上图所示,dataSource代表着一个数据库连接池,而hikari的数据库连接池就是HikariDataSource,这个类是hikari的核心类。
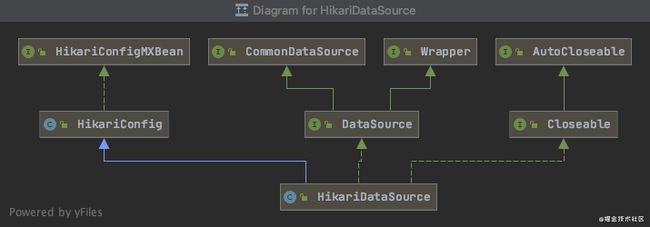
HikariDataSource的继承关系如上图,重点关注HikariConfig和DataSource。
-
DataSource,是一个接口,就是数据库连接池在Java类中的体现,对JDBC框架来说不需要关注Connection怎么来的,只需要调这个接口的方法获取即可
 DataSource
DataSource - HikariConfig,hikari配置类,有着jdbcUrl、用户名密码、超时时间、数据库连接池连接数等成员变量属性
HikariDataSource的成员结构
HikariDataSource的主要成员结构如下图:
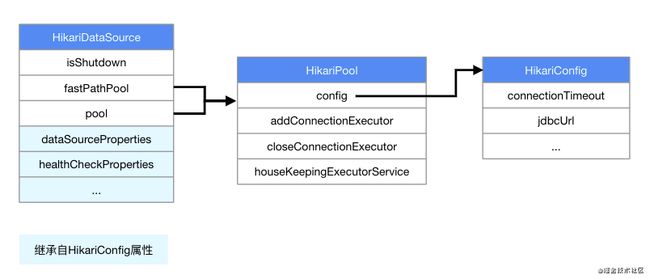
- isShutdown,一个AtomicBoolean(cas乐观锁)用来标识该dataSource是否已经关闭
- fastPathPool 和 pool,都是指向HikariPool结构的引用(Hikari优化用来提升性能的手段)
- 若干继承自HikariConfig的数据库连接池配置属性
HikariPool
HouseKeeper管家
HikariPool的主要属性如上图所示,主要通过30s执行一次的定时任务HouseKeeper来维护管理连接池中的连接。
HouseKeeper任务执行流程的伪代码如下:
def run():
# hikari的连接池维护机制大量依赖时间戳,如果发现系统时间倒退了,则会将连接池清空重来
if detect_retrograde_time():
softEvictConnections()
return
if detect_forward_time(): # 如果发现时间推前了,打日志,警告维持的连接会提前退休
log()
if idleTimeout > 0L && config.getMinimumIdle() < config.getMaximumPoolSize():
# 清理过期连接
for connection in connectionBag_NotInUse:
if is_timeout(connection):
closeConnection(connection)
# 初始化或清理过后
fillPool() # 填充连接池,保证最小的连接数量(idleConnections),同时保证不超过最大连接数量(maximumPoolSize)
从伪代码中可以看出,HouseKeeper主要的工作分为:
- 检测系统时间的准确性,系统时间被用户篡改过,则处理清空连接池
- 对空闲的连接,根据idleTimeout属性清理过期连接
- 在初始化或清理过后,填充新的连接到连接池中
关闭连接的过程(closeConnection)和填充的过程(fillPool)则分别是通过向上图中的closeConnectionExecutor和addConnectionExecutor连接池提交异步任务的方式,分别执行JDBC连接关闭和异步的建立JDBC连接的。
hikari优化的连接池存储容器 - ConcurrentBag
通过上面的分析,我们知道了hikari是通过在HikariPool这样的数据结构中执行30s一次的定时任务动态关闭/新增连接到连接池的。维护连接池中的连接就需要用到一种 容器,由于新增和关闭连接都是通过线程池异步执行的,而且getConnection()的操作大多数情况下是并发的,必然涉及到支持 并发。在Hikari中是通过自定义的容器类ConcurrentBag来维护JDBC连接的。
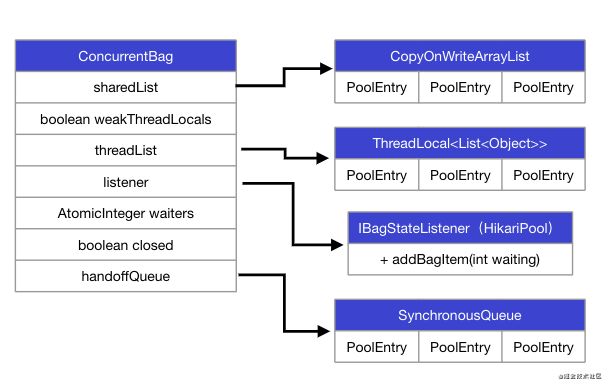
ConcurrentBag的结构
ConcurrentBag的结构如下图,重点关注
- sharedList和threadList,是两个关于PoolEntry(JdbcConnection的封装)的列表,用来实际存储连接池中维护的Jdbc连接
- listener,是指向HikariPool的引用,当ConcurrentBag获取连接时发现用完了,则通过listener的回调接口请求HikariPool多扩充点Jdbc连接入池
- handoffQueue,和listener相关,HikariPool扩充连接池后将新的连接通过该队列提供给正在等待的线程,正在
getConnection的线程会在queue的另一端阻塞住,等待扩充连接后喂给它们
PoolEntry,可以简单理解为Hikari对JdbcConnection的一层封装,有四种状态
- int STATE_NOT_IN_USE = 0; 没在用
- int STATE_IN_USE = 1; 使用中
- int STATE_REMOVED = -1; 已移除
- int STATE_RESERVED = -2; 预定
ConcurrentBag#add
新增的接口很简单,这里直接贴出源码。
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring add()");
}
sharedList.add(bagEntry);
// spin until a thread takes it or none are waiting
while (waiters.get() > 0 && !handoffQueue.offer(bagEntry)) {
yield();
}
}
从代码中可以看出主要的工作分为两步:
- sharedList.add()
- 如果有等待中的线程(正在getConnection),则尝试将新加入的JDBC连接通过队列handoffQueue喂给它
ConcurrentBag#remove
- 通过cas确保当前这个connection在使用中或被预定,使用中是在getConnection的时候通过探活(select 1)发现连接已经已经失效时,将其关闭;被预定是在HouseKeeper管家第2步对空闲的连接清理的时候,提前将要清理的连接锁住,并且执行close操作时。
- sharedList.remove(bagEntry); -- 从list中移除
ConcurrentBag#borrow
borrow方法的伪代码如下。
def borrow():
if (bagEntry = find_from_threadList()) != null: # 1.优先从threadList中找
return bagEntry
waiters++
try:
for bagEntry in sharedList: # 2. 从sharedList中找
if not_in_use(bagEntry):
if waiters > 1:
# 2.1 如果从sharedList中找到了,但是有waiting的,大概率是在并发情况下抢到了别人的,那就帮他再申请一个JDBC连接
listener.addBagItem(waiters - 1);
return bagEntry
# 3. sharedList中没找到,则申请新的JDBC连接
listener.addBagItem(waiting);
# 4. 申请了新的JDBC连接后,站在handoffQueue的一边,等待JDBC连接创建好的结果
while(not_timeout()):
bagEntry = handoffQueue.poll()
if not_in_use(bagEntry):
return bagEntry
finally:
waiters--
ConcurrentBag、hikari与Spring-JDBC
上面的解释可能太过底层和抽象,基于上面对ConcurrentBag主要方法的源码分析,我们这里可以将hikari的ConcurrentBag与Spring-JDBC整个串起来,分析一条sql语句执行的整个过程。
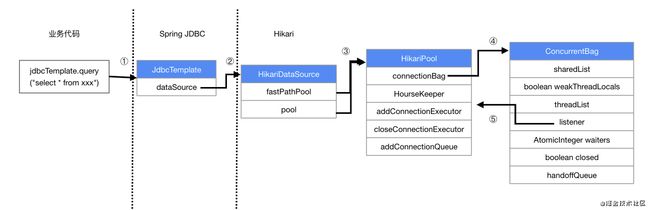
以语句select * from xxx为例,
- 在业务代码层面通过调用Spring-JDBC提供的
JdbcTemplate的query方法,获取查询结果 - JdbcTemplate调用内部的execute方法时,调用了
HikariDataSource#getConnection方法(dataSource可以通过手动注入,或SpringIOC注入) - HikariDataSource通过向其内部维护的连接池对象
HikariPool请求getConnection获取连接(注意,这里有两个HikariPool,是hikari的一种优化手段,下文中会详细分析) - HikariPool通过向其内部维护的
connectionBag(即ConcurrentBag对象)借用(borrow)来获取连接,借用的过程就是从写时拷贝list sharedList或threadLocal threadList获取连接,最终再一层层返回给JdbcTemplate,由JdbcTemplate执行sql语句,并将最终结果返回给业务代码 - 在第4步中,可能存在ConcurrentBag中维护的连接不够用的情况,这时候会通过listener指向的HikariPool请求扩充连接池中的连接
综上,我们可以看出,最终一条sql是通过这样层层抽象封装来实现的,
- HikariDataSource只是为了对Spring-JDBC的
DataSource接口做适配而产生的 - HikariPool才是Hikari的核心功能,它像是一个专门负责管理DB连接的管家,背着一个名叫ConcurrentBag的重重的背包,在你(业务侧)需要JDBC连接的时候提供给你,同时管家自己会是不是检查和扩充背包里的连接(就像跟女神和高富帅一起爬山时跟在最后背包的工具人)泪目( Ĭ ^ Ĭ )

Hikari的优化点
通过上面的分析,读者应该已经清楚了Hikari的大致原理,有了大致的了解之后,Hikari的代码实现的很多细节通过阅读源码也可以细化了解。我们这里回到最关键的问题,Hikari为什么这么快,为什么敢用 光 来命名自己。
字节码精简
字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一
以上是从网上搜到的,确实可以体现出Hikari极致优化的特性,但是对性能影响可能微乎其微。
fastPathPool 和 pool
如上面关于HikariDataSource与HikariPool的关系时,我们可以看到HikariDataSource内部有两个指向HikariPool的引用。这里也是Hikari优化性能的一种手段。

HikariDataSource有两种初始化的方式:
- 一种是无参数的初始化方式,这种时候当执行到getConnection的时候,会通过 懒汉单例模式 懒加载初始化HikariPool,赋值给pool引用,懒汉模式涉及到并发情况,所以一般会考虑采用 Double-Check-Lock(DCL) 方式加锁,DCL方式中涉及到JVM的字节码指令重排优化的问题,所以需要将pool引用设置为volatile,废弃掉JVM的字节码指令优化。(【5】Java中DCL(Double-Check-Lock)对volatile必要性的疑惑)但是同时因为volatile关键字,导致pool相关的加载都会有性能问题。所以获取HikariPool时优先通过fastPathPool引用。
-
另一种是带参数的初始化,在构造函数中同时将初始化完的HikariPool赋值给pool和fastPathPool引用,在获取HikariPool引用的时候总是优先获取fastPathPool,以防止volatile关键字对性能的影响
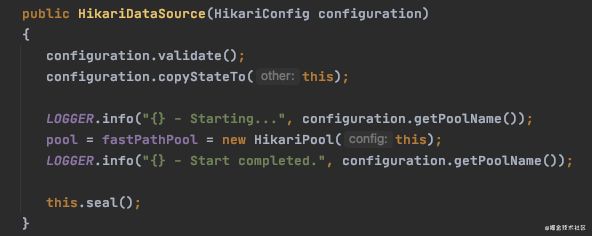 构造函数
构造函数
自定义的容器类型
1、 定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;【6】【追光者系列】HikariCP源码分析之FastList
2、 自定义集合类型(ConcurrentBag):提高并发读写的效率;
通过之前对ConcurrentBag的borrow方法的了解,我们知道,hikariPool是通过ConcurrentBag#borrow方法来获取连接的,而ConcurrentBag中的逻辑则是:优先从threadList(ThreadLocal)获取;获取不到时再从sharedList(CopyOnWriteArrayList)获取
ThreadLocal:例如业务代码执行了两次SQL,获取了两次JDBC连接,在第一次执行完毕之后ConcurrentBag会回收该连接,但是会回收到ThreadLocal中。当业务代码第二次执行SQl需要获取JDBC连接时,只要是同一个线程,则会从ThreadLocal中获取到连接。(关于ThreadLocal的原理,可以参考笔者的往期文章 【7】图解分析ThreadLocal的原理与应用场景)
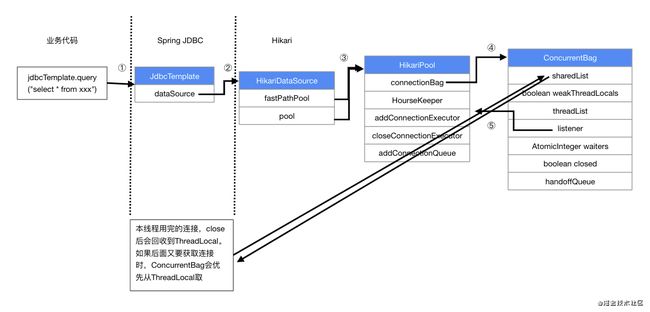
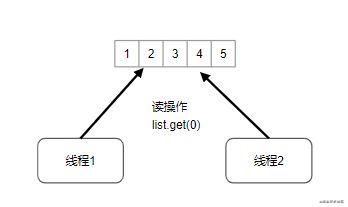
CopyOnWriteArrayList:写时拷贝技术,并发情况下线程安全版本的ArrayList,写时拷贝技术源自于unix系统的fork系统调用,指的是读操作时不加锁,只有当写操作执行的时候锁住整个list,然后执行替换(狸猫换太子)
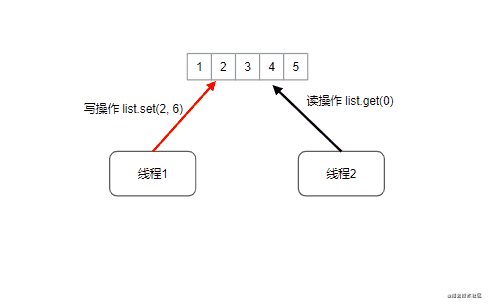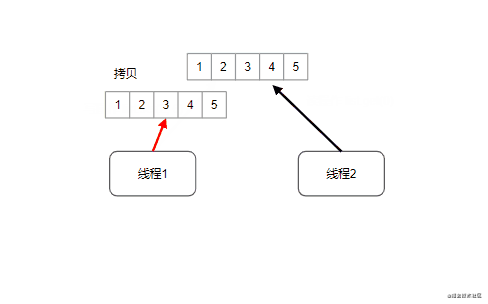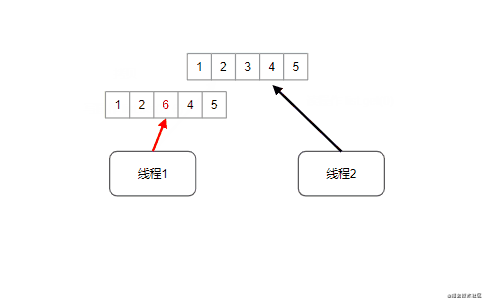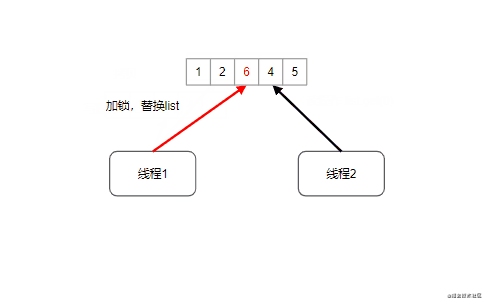
扩展知识
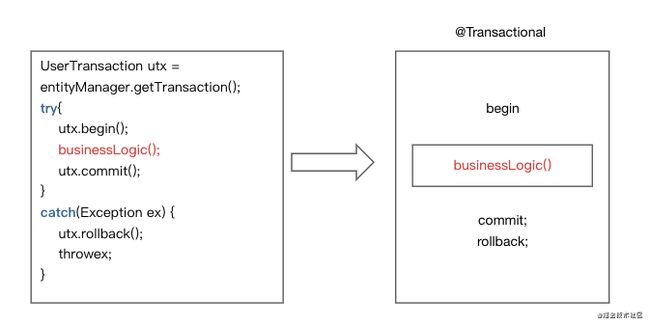
事务管理器transactionManager
在需要支持事务操作的方法上,我们通常会加上这样的注解, @Transactional(rollbackFor = Exception.class, value = "txManagerXXX"), 用来表示注解包裹住的方法内部是一个事务,需要符合事务的特性(如原子性)
在Spring中的实现是通过AOP切面技术生成了动态代理,封装了@Transactional注解的方法
JNDI
JNDI,全称是 Java Naming and Directory Interface,Java 命名与目录接口,也是跟原始的JDBC用法息息相关的概念。数据库的实现有很多种,Java服务是通过JDBC驱动类来获取JDBC连接的,那么原始的JDBC用法就会有几种问题:
- 数据库的地址、账户名、密码、连接池的参数发生改变,要修改代码
- 数据库可能从MySQL改为Oracle或者其它DB,需要修改底层代码,换JDBC驱动jar包,由此会引发一系列的相关功能的回归
基于以上问题,J2EE规范提出了JNDI的规范,对于业务代码来说只需要关心获取的DataSource是哪个(通过naming-名字),不需要知道这个DataSource背后的细节(url地址、账户名密码等),即findResouceByName,而resources的相关参数是配置在xml文件里的。
经常用Spring的读者可以看出,这就是SpringIOC容器提供的getBean(String beanName)方法,即Spring的xml文件,所以SpringIOC就是在J2EE的规范上实现的。(【8】Spring IOC 前世今生之 JDNI - binarylei - 博客园)
references
- ^ Introduction to HikariCP | Baeldung
- ^ GitHub - brettwooldridge/HikariCP: 光 HikariCP・A solid, high-performance, JDBC connection pool at last.
- ^ HikariCP连接池 -
- ^ 源码详解系列(八) ------ 全面讲解HikariCP的使用和源码 - 子月生 - 博客园
- ^ Java中DCL(Double-Check-Lock)对volatile必要性的疑惑_u010131029的博客-CSDN博客
- ^ 【追光者系列】HikariCP源码分析之FastList_weixin_34304013的博客-CSDN博客
- ^ 图解分析ThreadLocal的原理与应用场景
- ^ Spring IOC 前世今生之 JDNI - binarylei - 博客园