开篇一张图
Kafka
分布式日志系统
一、适用场景
消息队列 - 只能用于系统解偶
用户活动日志收集
应用程序监控数据汇总
大数据流式处理
二、优势
高吞吐量 : 单机每秒 100K 条消息传输
高性能 : 单机上千客户端,保证零停机、零数据丢失
时间复杂度O(1) 消息持久化
partition 内消息顺序传输
脱机 & 实时 数据处理
在线水平扩展
三、特点
只有消息拉取,没有推送
不支持 消息重试(消费端) 与 死信队列 - 只能自行透过 Redis 实现
使用主题对消息进行管理,一个主题有多个分区,一个分区有多个副本
1个分区 对 1个消费者,1个消费者 对 N个分区
四、基本概念
1. Producer 生产者
(1) 消息从主题发布到分区
指定
消息 Key Hash取模
轮循
(2) 批次发送条件 (任一条件满足)
缓冲区大小
消息等待时长
(3) Broker 元数据返回方式
阻塞
回调
(4) 组件
拦截器 : 修改消息内容
串行化器 : 将 key、value 从对象转换成字节数组
分区器 : 分配消息到哪个分区
2. Consumer 消费者
订阅一个或多个主题,并顺序读取
消费组偏移量区分已读取消息
消费组保证一个分区只能被一个消费者使用,避免重复消费
当消费者失效,触发再均衡,分区重新分配
若消费者数量超过主题分区数量,则一部份消费者闲置
向消费组添加消费者利于水平扩展消费能力
消费者分区分配策略 RangeAssignor【默认】: 先算出每个消费者需要分配的分区数量(尽量均分),再切段分配 - 字典序靠前消费者贪婪 RoundRobinAssignor : 所有(多个)主题分区,顺序分配 StickyAssignor : 尽量与上次分配结果尽量一致
3. Broker 独立的 Kafka 服务器
集群中会选出 1 个 Broker 作为集群控制器 - 使用 Zookeeper 的临时节点实现 将分区分配给 Broker 监控 Broker
4. Topic 主题
Producer 将消息发送到 Kafka,都需要指定该消息属于哪一个 Topic
5. Partition 分区
利于水平扩展存储能力
负责处理 读/写 的分区(首领分区)所在的 Broker,被称为分区首领
无法保证主题范围内消息有序,仅能保证分区范围内消息有序 - 严格保证 : 分区数量 1
6. Replicas 副本
制造数据冗余,提高容灾能力
Leader Replica 首领副本 - 生产、消费 请求都经过此副本
Follower Replica 跟随者副本 - 不处理任何请求,仅用于首领副本崩溃,提升为新首领
ISR ( In-Sync Replicas ) - 与 Leader Replica 保持一定程度同步的副本
OSR ( Out-Sync Relipcas ) - 滞后 Leader Replica 过多的副本
AR ( Assigned Repllicas ) = ISR + OSR
Leader副本当机 - 原 Leader 的 commit 数据清空,重新从新 Leader poll 数据
副本选举从 ISR 中选择 Leader,相较过半机制冗余度较低
unclean.leader.election.enable = true : 可从非 ISR 中选出 Leader
如果采用过半机制
容忍1台当机,则需3台服务器,
容忍2台当机,则需5台服务器。
使用ISR
容忍1台当机,需要2台服务器,
容忍2台当机,需要3台服务器。
复制代码
7. Offset 偏移量
推荐使用 Kafka 保存,因为 Zookeeper 不适合高并发
1. Partition
HW ( High Watermak ) 高水位 : 所有 ISR 已同步的偏移量,消费者最多只能拉取到此偏移量之前的消息
LEO ( Log End Offset ) 日志结尾 : 下条待写入消息的偏移量
2. Consumer
Consumer 需要向 Kafka 提交自己的消费offset,保存于 __consumer_offsets 主题(默认50个分区),Kafka 只负责保管
自动提交【默认】 调用 poll() 时,提交上次 poll 所有消息的偏移量 不会丢失消息,但会出现重复消费
手动提交 同步 - 影响 TPS - 解决 : 多次 poll 再一次提交 异步 - 提交失败不会自动重试
【推荐】同步 + 异步 结合使用
五、脚本
kafka-topics.sh : 管理主题 # 列出所有主题 kafka-topics.sh --list --zookeeper localhost:2181/myKafka # 创建主题,1个分区,1个副本(只有Leader,没有Follower),指定消息最大尺寸,指定LOG日志分块大小 kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic topic_1 --partitions 1 --replication-factor 1 --config max.message.bytes=1048576 --config segment.bytes=10485760 # 创建主题,并指定分区位置,3个分区,Leader的Broker:Follower的Broker:Follower的Broker... kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_demo_03 --replica-assignment "0:1,1:0,0:1" # 查看分区消息 kafka-topics.sh --zookeeper localhost:2181/myKafka --list # 查看指定主题消息 kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic topic_1 # 删除指定主题 kafka-topics.sh --zookeeper localhost:2181/myKafka --delete --topic topic_1 # 修改主题消息最大尺寸配置 kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic topic_test_01 --config max.message.bytes=1048576 # 删除主题消息最大尺寸配置 kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --delete-config max.message.bytes --topic topic_test_01 # 增加主题分区 kafka-topics.sh --zookeeper localhost/myKafka --alter --topic myTop1 --partitions 2 复制代码
kafka-console-producer.sh : 生产消息 # 开启生产者 kafka-console-producer.sh --topic topic_1 --broker-list localhost:9020 复制代码
kafka-console-consumer.sh : 消费消息 # 开启消费者 kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_1 # 开启消费者并从头消费 kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_1 --from-beginning 复制代码
kafka-consumer-groups.sh : 管理消费者偏移量 # 查看指定Group消费情况 kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group group 复制代码
kafka-reassignpartitions.sh : 主题分区重新分配 # topics-to-move.json { "topics": [ { "topic":"tp_re_01" # 要重新分区的 Topic } ], "version":1 } # 读取 topics-to-move.json 文档,产生针对 broker0、broker1 的运行计划 kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --topics-to-move-json-file topics-to-move.json --broker-list "0,1" --generate # topics-to-execute.json {"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas": [0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas": [0],"log_dirs":["any"]}]} # 运行 topics-to-execute.json 分区计划 kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file topics-to-execute.json --execute # 验证 topics-to-execute.json 的分区计划运行情况 kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file topics-to-execute.json --verify 复制代码 # increment-replication-factor.json { "version":1, "partitions":[ {"topic":"tp_re_02","partition":0,"replicas":[0,1]}, {"topic":"tp_re_02","partition":1,"replicas":[0,1]}, {"topic":"tp_re_02","partition":2,"replicas":[1,0]} ] } # 运行 increase-replicationfactor.json 副本分配计划 kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file increase-replicationfactor.json --execute 复制代码
kafka-run-class.sh : 运行工具类 - 查看日志、索引文档 # 打印 00000000000000000000.log 日志文档 kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log | head # 打印 00000000000000000000.index 索引文档 kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index --print-data-log | head 复制代码
六、消息可靠性
1. 发送
acks 确认模式 0 : 不等待 Broker 确认,仅将消息放到缓冲区 - retries 失效 1 : 仅将消息放到 Leader Replica - 副本未同步则消息丢失 all【默认】: 所有 ISR 确认,消息不丢失
retries 重试次数 : 消息发送错误时的重试次数 异步消息确认,保证分区内严格有序 : MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1
七、再均衡
再均衡时期,Kafka 将处于不可用状态,可能长达数分钟到数小时,生产环境应尽量避免
1. 触发条件
消费组内成员变更
主题分区数变更 - Kafka 只支持增加分区
订阅主题变更 - 消费者使用正则表达式订阅主题
2. 避免方式
心跳超时 session.timout.ms - 6s
心跳频率 heartbeat.interval.ms - 2s
poll间隔 max.poll.interval.ms - 最长耗时 + 1分钟
3. 流程
JOIN : 请求消费组所有成员加入消费组,选择一个消费者担任 Leader
SYNC : Leader 制定消费方案,并将方案发给 Group Coordinator (消费组协调器,Leader副本所在的Broker),Group Coordinator将方案发给消费者
4. 分配策略
RangeAssignor【默认】
RoundRobinAssignor
StickyAssignor
八、日志
1. 文档
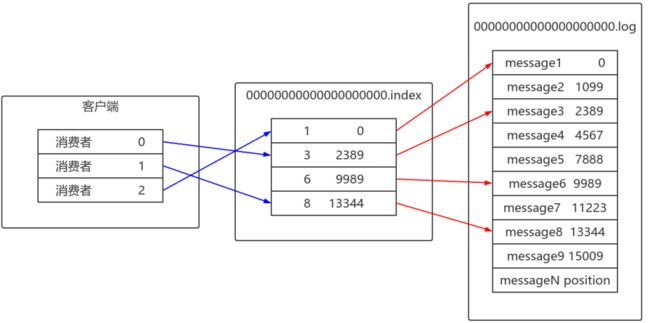
目的 : 保存消息内容
每个分区都有一份日志文档 - .index、.timestamp、.log ... - 文档名一致 : LogSegment
日志追加为顺序写入
LogSegment 目的 : 减少日志文档大小、快速定位
ActiveLogSegment 活跃日志分段 - 可以写入,其它只能读取
文档名为第一条消息偏移量
内容 offset : 消息偏移量 position : 消息物理位置 CreateTime : 时间戳 - 生产消息时不要手动指定,否则可能导致消息顺序混乱 magic : 消息类型 compresscodec : 压缩类型 crc : 校验后的crc值
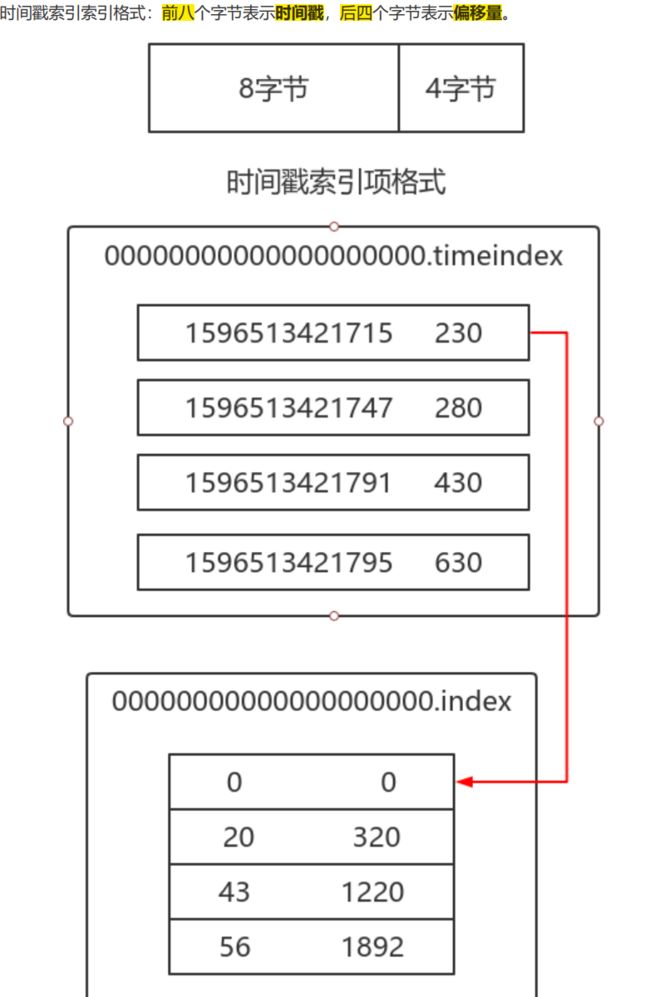
2. 索引文档内容
纪录 消息偏移量 与 在日志文档中日志纪录的物理地址 的映射关系
为稀疏索引,不会替每条日志都创建索引
3. 切分日志
触发条件
日志文档大小超过 log.segment.bytes : 默认 1G
索引文档大小超过 log.index.size.max.bytes : 默认 10M
保存时间超过 log.roll.ms 或 log.roll.hours : 默认 7天
运行流程
一开始先预留 log.index.size.max.bytes (默认 1G) 的空间,待需要切分时再裁剪成实际大小
目的 : 降低代码逻辑
4. 清除
删除【默认】 log.retention.ms 时间 : 默认 7天,依照 LogSement 中,时间戳最小来判断 log.segment.bytes 大小 偏移量
压缩 - Key 相同,Value 不同,保存最后一版 - 用于实时计算的容灾
5. 硬盘存储
零拷贝 : 减少内核态到用户态的转换,舍弃不必要的拷贝次数
页缓存 : 把硬盘数据写到内存中,减少磁盘IO
顺序写入 : 可以使用 预读(将磁盘块读入内存) & 后写(小的写操作合并) 做优化
九、事务
多条消息让 Consumer 同时可见或不可见
应用场景 : 消费一个 Topic ,做处理再发到另一个 Topic
__transaction_state 主题,保存事务状态
__transaction_state 主题所在的 Broker 为事务协调器,负责初始化、提交、回滚事务
使用 epoch 来保证一个 TransactionalID 只有一个活跃的 Producer
1. 配置
消费者
关闭自动提交 auto.commit,也不能使用手动提交 commitSync( )、commitAsync( )
设置 isolation.level : READ_COMMITTED 或 READ_UNCOMMITTED
生产者
配置 transactional.id
配置 enable.idempotence
2. 中止
Producer 发送 BeginTransaction(TxId) 时 超时 或 响应中包含异常,此时将进行重试,需注意幂等性
十、消息重复
1. 生产者阶段
原因 : 没有收到正确的 Broker 响应,导致重发消息
解决
启用幂等性 enable.idempotence = true ack = all retries > 1
不重试 ack = 0,可能丢消息 - 用于吞吐量指针重要性高于数据丢失 - 日志收集
2.消费者阶段
原因 : 消息消费完,没有及时提交 offset 到 Broker
解决
无法根本解决重复发送消息问题,只能透过消费端做幂等性处理
作者:Java劝退师
链接:https://juejin.im/post/6896640774205767688