ps:最近加入公司的设计与人工智能实验室 ,一系列图像和文字识别。
1.安装OCR
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。目前最新的tesseract项目已经全部迁移到了github上,我们可以从中获取所有主要的信息。地址: https://github.com/tesseract-ocr/tesseract
整个依赖安装过程如下:(Mac为例)
//先安装依赖库libpng, jpeg, libtiff, leptonica
brew install leptonica
//安装tesseract的同时安装训练工具(一定要安装后面训练使用)
brew install --with-training-tools tesseract
//安装tesseract的同时安装所有语言(不建议安装全部 中文简体和英文足以)
brew install --all-languages tesseract
//只安装tesseract,不安装训练工具
brew install tesseract
装好后需要安装一个中文语言库,默认都是英文的语言库。
下载地址:https://github.com/tesseract-ocr/tessdata
根据自己的需求选择所要的语言库,在这里我们选择的是简体中文所以选择的库是:chi_sim.traineddata、eng.traineddata
将文件拷贝到到:/usr/local/Cellar/tesseract/3.05.01/share/tessdata目录下。
2.安装python依赖包
需要一个封装好的基于OCR的第三方库:pytesseract
需要一个读取图像识别的库:opencv或者pillow(建议)
sudo pip install pytesseract
sudo pip install PILLOW
3.使用OCR(2种方式)
-
第一种方式:命令行。
// 默认读取图片是使用英文 image图片地址 result 识别结果result.txt
tesseract image result
// 使用语言包 -l (language缩写)
tesseract -l chi_sim image result
百度上可以找到很多文字图片,这里拿一张举例子。(这里需要的是tiff格式的图片) 有地址可以进行转换:https://cn.office-converter.com/Convert-to-TIF

现在来是识别这张图片中的内容:
新建了个文件夹OCR 下面只有一张train的图片:train.tif

运行命令:
// 记得用中文不然一堆乱码
tesseract -l chi_sim train.tif result
查看结果:
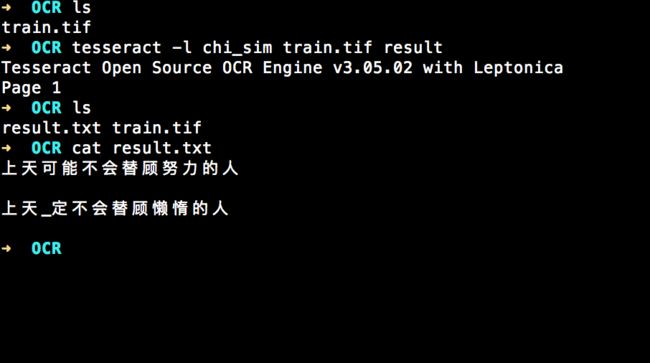
准确率还可以但是因为文字比较简单,"眷顾"的"眷"被认成了"替",人工智障还不认识"一"。 以上方式为命令行操作。
-
第二种方式:python代码实现。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 基础包:OCR
from PIL import Image
import pytesseract
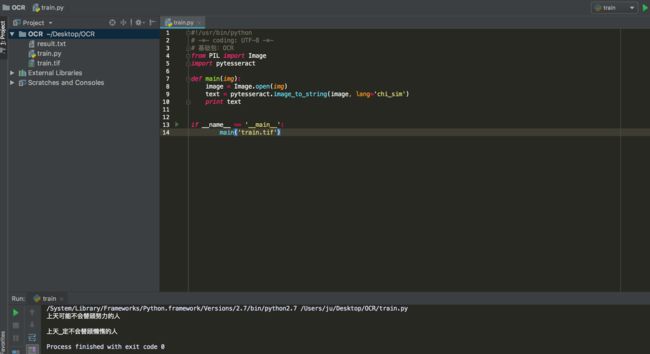
def main(img):
image = Image.open(img)
text = pytesseract.image_to_string(image, lang='chi_sim')
print text
if __name__ == '__main__':
main('train.tif')
需要导入PIL读取图片,然后通过pytesseract读取图片中的字符,语言必须选择中文简体(和命令行一样)
4.训练自己的字体库
上面的文字怎么样让OCR都认识呢?前面安装过训练工具。
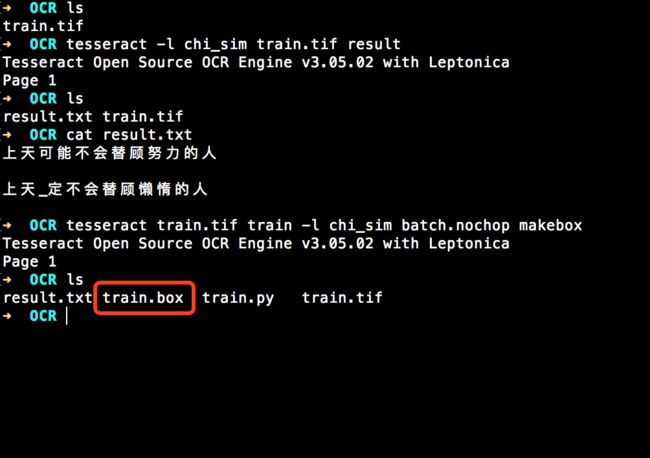
需要先生成一个.box文件查看识别内容。命令如下:
// 制作box文件
tesseract train.tif train -l chi_sim batch.nochop makebox
可以查看到生成了一个train.box的文件。
下载工具:jTessBoxEditor http://vietocr.sourceforge.net/training.html
打开train.tif 只有生成了train.box才能查看他的识别过程。
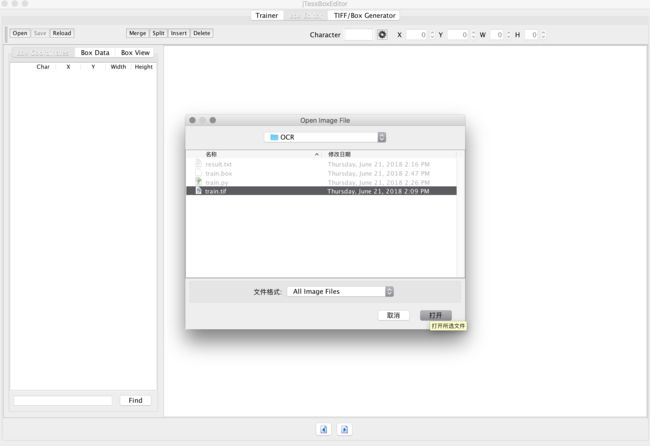
打开train.tif可以明显看到识别的每一个字的正确。
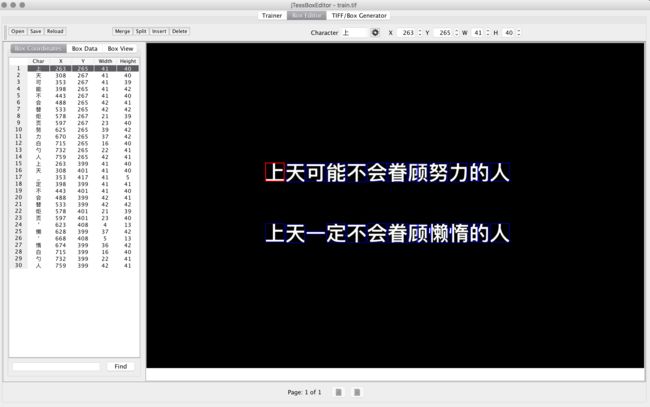
把错误的字修改一下,更改成正确的字。然后保存。
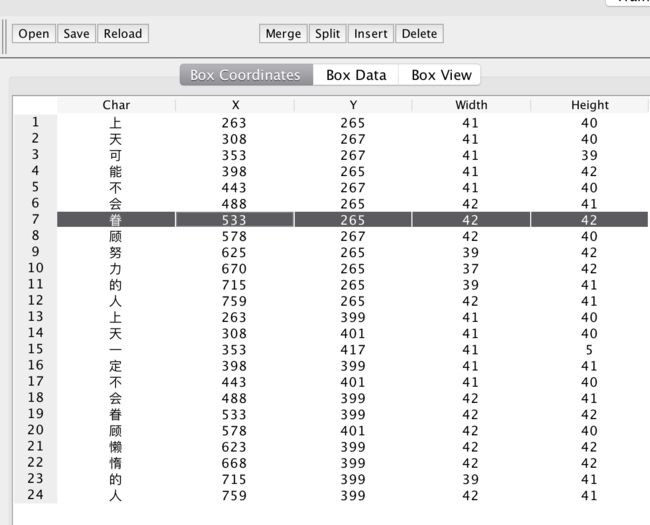
5.制作自己的字体库文件
需要几个命令:
// 制作文字属性文件
echo font 0 0 0 0 0 >font_properties
// 生成训练文件 train.tr 这个文件非常重要之后训练用的
tesseract train.tif train -l chi_sim nobatch box.train
// 生成字符集
unicharset_extractor train.box
// 生成shape
shapeclustering -F font_properties -U unicharset -O unicharset train.tr
// 聚合字符特征文件
mftraining -F font_properties -U unicharset -O unicharset train.tr
//正常化文件
cntraining train.tr
查看结果:

然后多出了很多文件:
unicharset、inttemp、pffmtable、shapetable、normproto
需要全部重命名成train.前缀:
train.unicharset、train.inttemp、train.pffmtable、train.shapetable、train.normproto
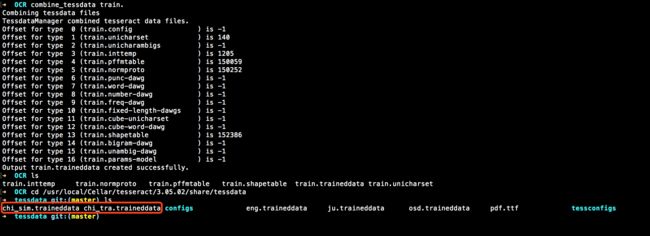
然后通过命令合并制作成.traineddata文件:
// 合并训练好的文件
combine_tessdata train.
合并结果如下并且去查看OCR本身安装的语取文件就是这个.traineddata格式的官方训练好的,其实我们是自己制作了一个定制化适用自己的字体库了。
将训练好的.traineddata移动到系统安装tesseract的文件夹下
命令如下:
mv train.traineddata /usr/local/Cellar/tesseract/3.05.02/share/tessdata
6.测试自己的字体库
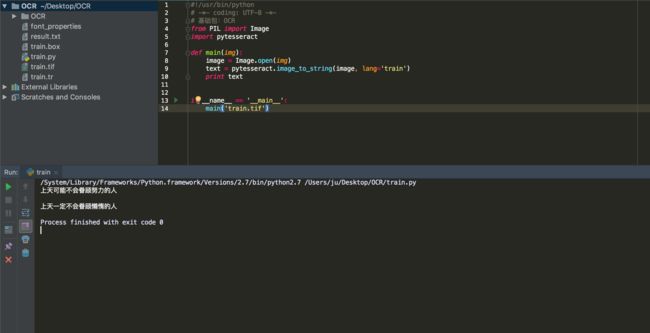
代码不用修改太多只用把语言库改为自己的库,即lang='chi_sim' 改为我们训练的lang='train'。代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 基础包:OCR
from PIL import Image
import pytesseract
def main(img):
image = Image.open(img)
text = pytesseract.image_to_string(image, lang='train')
print text
if __name__ == '__main__':
main('train.tif')
这次结果非常完美100%正确。但是这个库现在还是个幼小的智障库,只能识别这个图其他还需要训练,文末彩蛋给出如何训练大量字体库。
彩蛋
制作大型字体训练库:中文有3500个汉字 一一 先制作一个list所有的常用汉字集合。

用Opencv制作一张白底背景100x100像素的图片。
import cv2
a = cv2.imread('1.png')
b = cv2.resize(a,(100,100))
cv2.imwrite('train.png',b)
分别把3500个汉字拼接到图片中,需要下载一个你要训练的字体类型这里苹方为例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 基础包:模型训练
from PIL import Image, ImageFont, ImageDraw
import constants as cs
def draw_text(img, type, text, index):
image = Image.open(img)
draw = ImageDraw.Draw(image)
font = ImageFont.truetype(type, 80)
draw.text((10, 0), unicode(text.encode('UTF-8'), 'UTF-8'), font=font, fill='#000000')
image.save('train/%s.tif' % index)
if __name__ == '__main__':
for text in cs.CHINESE_COMMON:
index = cs.CHINESE_COMMON.index(text)
draw_text('train.png', '苹方 PingFang.ttc', text, index)
拼接完的图片如下:
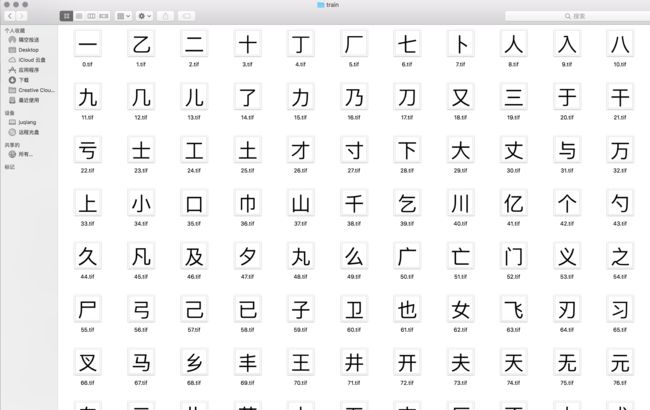
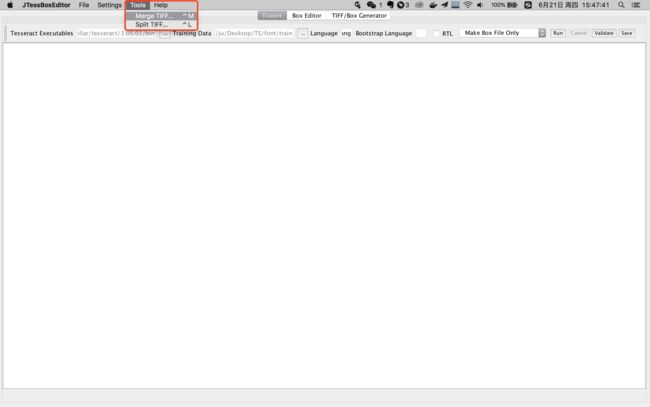
打开jTessBoxEditor工具>tools>merge tiff
merge这些图片做成一个大的tif文件
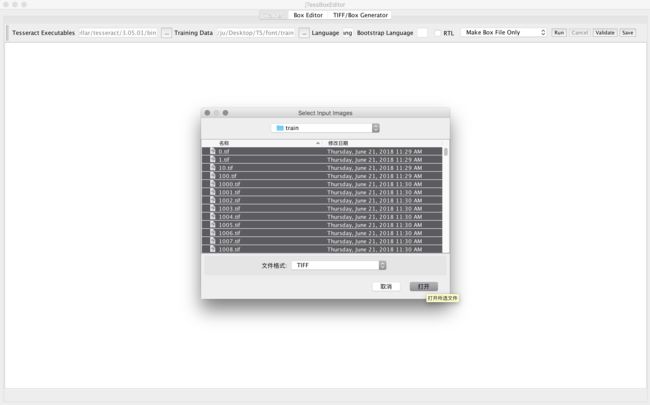
全选保存为heben.tif文件进行训练。
剩下前文一样训练成heben.box heben.tr... 最后修改完毕后生成一个heben.traineddata的文件就是一个大型字体库代码修改下去识别一些苹方字体试试。
到这里一个半人工智能的人工智障就结束了。